- The paper proposes a unified, text-conditioned framework that jointly generates human motion and camera trajectories by leveraging on-screen framing as an auxiliary modality.
- It employs a multimodal autoencoder with a learnable linear transform and modality-specific decoders to improve framing quality and modality alignment.
- The introduction of the robust PulpMotion dataset and an auxiliary sampling scheme demonstrates state-of-the-art performance and adaptability to various latent diffusion pipelines.
Framing-Aware Multimodal Camera and Human Motion Generation: An Expert Analysis of "Pulp Motion"
The generation of human motion and camera trajectories has traditionally been addressed as two independent problems, neglecting the intrinsic coupling that defines cinematographic practice. The "Pulp Motion" paper introduces a unified, text-conditioned framework for the joint generation of human motion and camera trajectories, with a focus on maintaining consistent on-screen framing. The central insight is to leverage the on-screen projection of human joints (framing) as an auxiliary modality, which acts as a bridge to enforce coherence between the two heterogeneous but interdependent modalities.
Multimodal Latent Space and Autoencoder Architecture
The core of the proposed method is a multimodal autoencoder that learns a shared latent space for both human motion and camera trajectory. The architecture is depicted in (Figure 1):
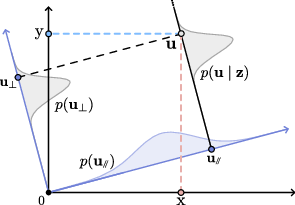
Figure 1: Architecture of the multimodal autoencoder. Human motion and camera trajectory are jointly encoded, linearly transformed into an auxiliary on-screen framing latent, and reconstructed by three decoders for each raw modality.
The autoencoder consists of:
- A joint encoder Eϕ that processes raw human motion and camera trajectory sequences.
- A learnable linear transform W that projects the concatenated latent representations into a lower-dimensional framing latent, representing the 2D on-screen projection of human joints.
- Three modality-specific decoders Dψc, Dψh, Dψp for reconstructing camera, human, and framing modalities, respectively.
The training objective is a sum of reconstruction losses for each modality, with the framing latent never directly encoded but only learned via the linear transform and its reconstruction loss. This design ensures that the auxiliary modality captures only the information shared between human and camera, enforcing a tight coupling in the latent space.
Auxiliary Sampling for Multimodal Coherence
To address the challenge of sampling from the joint distribution p(h,c∣t) (where h is human motion, c is camera trajectory, and t is text), the authors introduce an auxiliary sampling scheme. This approach leverages the linear relationship between the joint latent and the framing latent to decompose the latent space into two orthogonal components:
- A component parallel to the auxiliary modality (framing), which is used to steer the sampling toward coherent human-camera pairs.
- An orthogonal component that acts as an unconditional term.
This decomposition is illustrated in (Figure 1, right):
Figure 1: Decomposition of the joint latent into components parallel and orthogonal to the auxiliary modality, enabling targeted sampling for multimodal coherence.
During diffusion-based generation, the noise prediction is adjusted by a weighted sum of the unconditional, conditional (text), and auxiliary (framing) guidance terms. The auxiliary guidance weight wz controls the strength of the framing constraint, allowing for explicit trade-offs between per-modality fidelity and multimodal coherence.
Dataset: PulpMotion
A significant contribution is the introduction of the PulpMotion dataset, which provides high-quality, paired human motion and camera trajectory data with rich textual captions. The dataset is constructed via a multi-stage pipeline:
- Extraction of 3D human and camera poses from video using TRAM.
- Caption generation for human motion using a vision-LLM (Qwen2.5-VL) and for camera using LLM-based tagging.
- Refinement of human motion in occluded or out-of-frame regions using a diffusion-based inpainting method (RePaint), guided by HumanML3D-pretrained models.
The dataset is substantially larger and more diverse than previous resources, with improved motion quality and text-motion alignment, as shown by strong TMR-Score and Fréchet distance metrics.
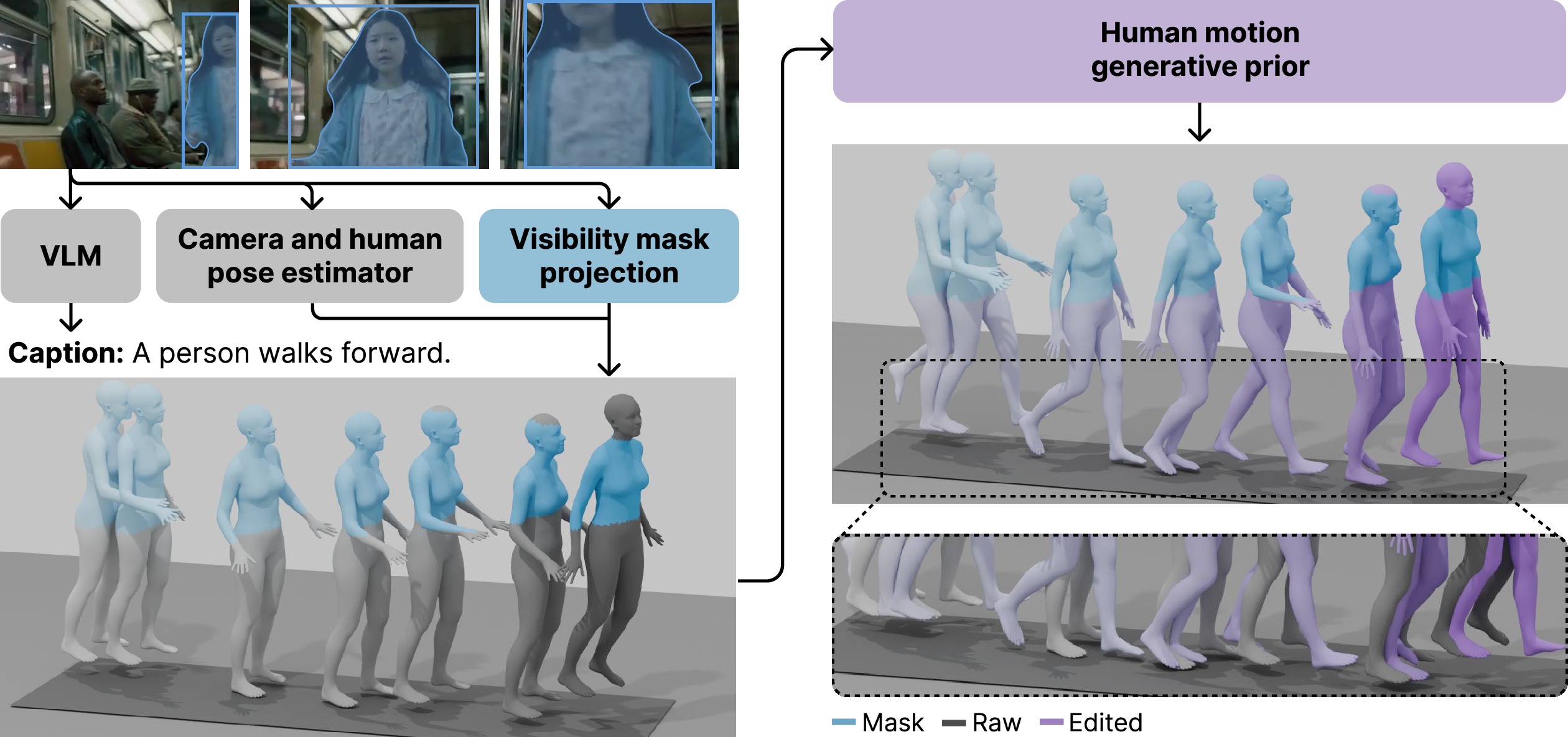
Figure 2: Dataset refinement pipeline: pose estimation, out-of-screen detection, and generative refinement of occluded body parts.
Experimental Results and Analysis
Quantitative Evaluation
The method is evaluated on both DiT-based and MAR-based architectures, demonstrating model-agnostic improvements. Key findings include:
- Framing quality (measured by Fréchet distance and out-of-frame rate) is significantly improved by auxiliary sampling, with FDframing reduced by up to 3x compared to baselines.
- Text-to-modality alignment (TMR-Score for human, CLaTr-Score for camera) is consistently higher with auxiliary guidance.
- Per-modality fidelity is largely preserved, with only minor trade-offs at high auxiliary guidance weights.
Ablation studies confirm that moderate auxiliary guidance yields optimal trade-offs, while excessive guidance can degrade per-modality fidelity.
Qualitative Evaluation
Generated sequences exhibit precise human motion and camera trajectories that maintain consistent on-screen framing, even for complex prompts. The method avoids empty frames and ensures that the subject remains visible and well-composed throughout the sequence.
Theoretical Implications
The auxiliary sampling framework is grounded in a rigorous decomposition of the joint latent space, leveraging properties of the Moore-Penrose pseudo-inverse and Gaussian projections. This enables independent control of multimodal coherence without requiring architectural changes or external pre-trained models, distinguishing it from prior multimodal diffusion approaches.
Practical Implications and Future Directions
The proposed framework is architecture-agnostic and can be integrated into any latent diffusion pipeline for multimodal generation. The use of an auxiliary modality as a bridge is generalizable to other domains (e.g., audio-visual, text-image) where a natural shared representation exists. The PulpMotion dataset sets a new standard for joint human-camera data, facilitating further research in cinematographic AI and virtual production.
Potential future directions include:
- Extension to finer-grained framing control, such as targeting specific body parts or dynamic regions of interest.
- Application to other multimodal generation tasks where auxiliary modalities can be defined.
- Exploration of interactive or real-time generation for virtual cinematography and robotics.
Conclusion
"Pulp Motion" presents a principled, effective approach for joint human motion and camera trajectory generation, enforcing multimodal coherence via an auxiliary on-screen framing modality. The combination of a shared latent space, linear auxiliary projection, and targeted sampling yields state-of-the-art results in both quantitative and qualitative metrics. The framework's generality, strong empirical performance, and theoretical grounding mark a significant advance in multimodal generative modeling for embodied AI and computational cinematography.