Modeling Student Learning with 3.8 Million Program Traces
Abstract: As programmers write code, they often edit and retry multiple times, creating rich "interaction traces" that reveal how they approach coding tasks and provide clues about their level of skill development. For novice programmers in particular, these traces reflect the diverse reasoning processes they employ to code, such as exploratory behavior to understand how a programming concept works, re-strategizing in response to bugs, and personalizing stylistic choices. In this work, we explore what can be learned from training LLMs on such reasoning traces: not just about code, but about coders, and particularly students learning to program. We introduce a dataset of over 3.8 million programming reasoning traces from users of Pencil Code, a free online educational platform used by students to learn simple programming concepts. Compared to models trained only on final programs or synthetically-generated traces, we find that models trained on real traces are stronger at modeling diverse student behavior. Through both behavioral and probing analyses, we also find that many properties of code traces, such as goal backtracking or number of comments, can be predicted from learned representations of the students who write them. Building on this result, we show that we can help students recover from mistakes by steering code generation models to identify a sequence of edits that will results in more correct code while remaining close to the original student's style. Together, our results suggest that many properties of code are properties of individual students and that training on edit traces can lead to models that are more steerable, more predictive of student behavior while programming, and better at generating programs in their final states. Code and data is available at https://github.com/meghabyte/pencilcode-public

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how students learn to code by studying the way they edit and re-run their programs over time. Instead of only looking at the final code a student writes, the authors collect and analyze “program traces” — step-by-step records of a student’s attempts, changes, and retries. They train AI models on 3.8 million of these traces from Pencil Code (a beginner-friendly coding website) to better understand both the code and the students who write it.
Key Questions
The paper asks:
- Can AI models learn more about how students think and learn to code by training on their step-by-step edits, not just their finished programs?
- Do these models capture differences between students (like their style or common mistakes)?
- Can these models help students fix errors and improve their code while keeping each student’s personal style?
- How well do models trained on real traces compare to models trained on only final programs or fake/synthetic traces?
How Did They Do It?
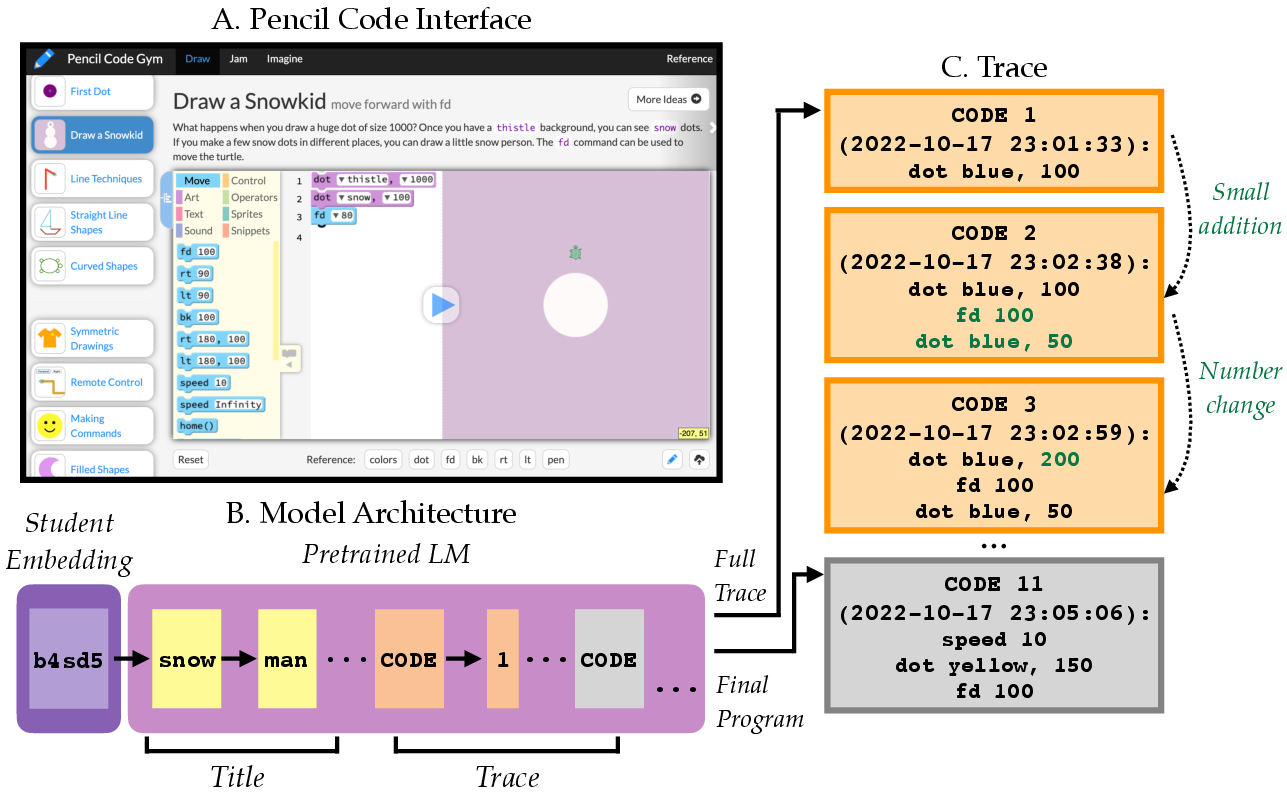
The data: program traces
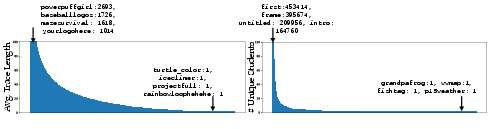
A “program trace” is the sequence of versions a student’s code goes through while they work on it, along with timestamps (when the student ran it), the project title (like “snowman”), and a hidden student ID. Think of a trace like a trail of footprints showing how someone got from a starting point to their destination.
The dataset has:
- 3.8 million traces from over 1 million students over 9 years (2015–2024).
- Many beginner projects (like drawing with turtle graphics), but also more complex tasks.
- For each trace: the student ID, the project title, and the ordered list of code versions with times.
The models: learning from steps, not just answers
The authors trained LLMs (the same kind of AI that writes text or code) in three different ways:
- Last: train only on the final program a student wrote (like grading only the final essay).
- Synthetic: use the final program, but automatically create fake “edit steps” to make a pretend trace (like imagining how a student might have gotten there).
- Trace: train on the real step-by-step traces (like watching the student work live).
They also gave the models a “student embedding,” which is a learned vector (a kind of soft profile) for each student ID. This helps the model remember patterns for individual students, like their typical edits or style (comments, colors, etc.).
How they tested the models
They used two kinds of checks:
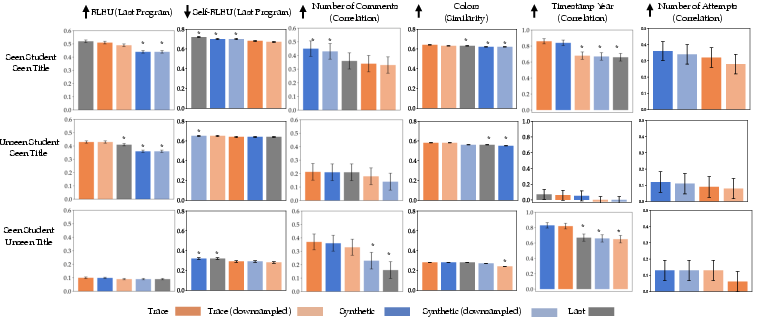
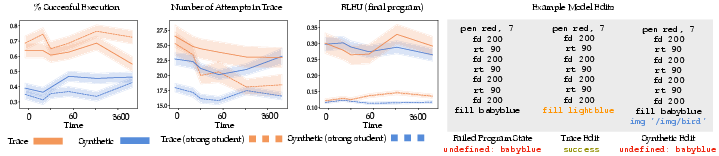
- Behavioral tests: Ask the models to generate code (and sometimes a whole edit sequence), then compare it to what real students did. For example, do the final programs look similar? Do the edits resemble how students actually change code? They use a “similarity score” (like BLEU) that measures how close the generated code is to the real code, and they look at diversity (how varied the models’ outputs are).
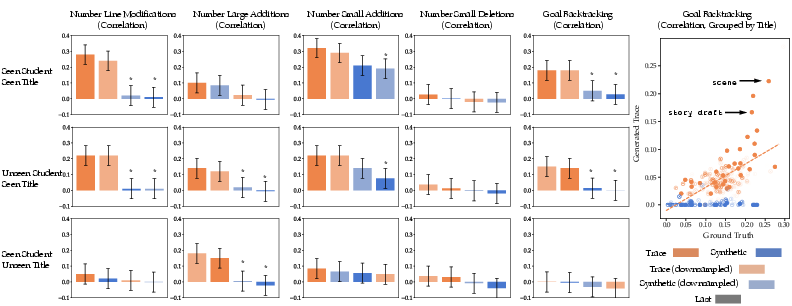
- Representation tests (“probes”): Look inside the model’s learned representations to see what it “knows.” For example, can a simple classifier predict from the model’s internal features whether a student is likely to backtrack (move away from the final goal temporarily), how many comments they tend to write, or if their final program will run?
They also tried:
- Adapting to new students by tuning only the student embedding with a few examples (like teaching the model a new student’s style quickly).
- Error recovery: Given a broken mid-trace program (one that doesn’t run), can the model suggest a sequence of edits that lead to a working solution while staying close to the student’s style?
Main Findings
Here are the big takeaways, explained simply:
- Training on real traces works best:
- Models trained on true edit histories produce final programs that are both more accurate (closer to what the student ended up with) and more diverse (not just repeating the same thing).
- These models better capture student behaviors, like backtracking, making small edits, changing colors or numbers, and adding comments.
- The model learns about the student, not just the code:
- The “student embedding” stores meaningful information about a student’s typical behaviors and style.
- Probes show the model can predict student-level patterns (e.g., how often they backtrack, how much time they spend, how many comments they write).
- Even with just a few examples, the model adapts to new students by updating only their embedding.
- Helping students fix errors:
- When given a broken program from mid-trace, the trace-trained model is better at suggesting edits that lead to working code than the synthetic model.
- The model can be “steered” by:
- Changing the timestamp (to control how many edits happen next).
- Swapping the student embedding with a “strong student” profile. This increases the chance of fixing errors but may make the result less like the original student’s style — showing the model understands personalization.
- Titles and students matter for generalization:
- Knowing the student ID helps match things like typical years (timestamps) and style.
- Knowing the title helps match expected content (e.g., color words in visual projects).
- Learning new titles is still hard, especially when the title doesn’t clearly describe the program (e.g., “myprogram”).
Why It Matters
- Better support for learning: By understanding how students edit and explore, not just what they submit at the end, AI tutors can give smarter, personalized hints. For example, they can spot when a student is likely to backtrack or get stuck and suggest a helpful next step.
- Personalization with control: Teachers or tools can steer the model to balance accuracy with staying close to a student’s style (so the help feels like the student’s own work, not a complete replacement).
- More human-like modeling: Training on real reasoning traces helps the AI reflect how people actually solve problems — exploring, making mistakes, revising, and refining.
- Responsible use: The authors anonymized IDs and filtered personal information, and they plan a gated release to protect student privacy. Any future educational tools built on this kind of data should prioritize ethical, safe use.
In short, this paper shows that many “properties of code” are really “properties of the coder,” and that training on edit histories makes AI models more accurate, more steerable, and more supportive of real student learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several concrete avenues for future work and clarification:
- External validity beyond Pencil Code: How well do trace-trained models generalize to other platforms, languages (e.g., Python, Java), IDE workflows, and non-block-based contexts, as well as to more advanced programmers? Systematic cross-platform and cross-language evaluations are missing.
- Goal inference from titles: The method assumes the trace title reflects the student’s goal, yet titles are often noisy (e.g., “first,” “myprogram”). There is no quantification of title–goal mismatch or methods to infer/segment latent goals within or across traces.
- Final program as “goal” proxy: Backtracking and edit distances are measured relative to the last program, which may not reflect the student’s true goal (e.g., goal changes mid-trace, partial abandonment, timeouts). Alternative goal models and robustness checks are not explored.
- Coverage of unexecuted edits: Data are derived from code execution requests; unexecuted edits (e.g., drafts, local edits not run) are absent. The impact of this sampling bias on learned edit distributions and inferred behaviors is unmeasured.
- Execution success metric validity: “Successful execution” is proxied via a headless browser with a custom HTML template. The false positive/negative rates (e.g., environment mismatches, external dependencies, asynchronous behaviors) are not validated against human judgments or ground-truth program semantics.
- Lack of semantic correctness metrics: Correctness is treated as execution success; no task-level grading, unit tests, or semantic/functional checks (e.g., “did the snowman match the assignment rubric?”). This limits claims about learning progress and pedagogical usefulness.
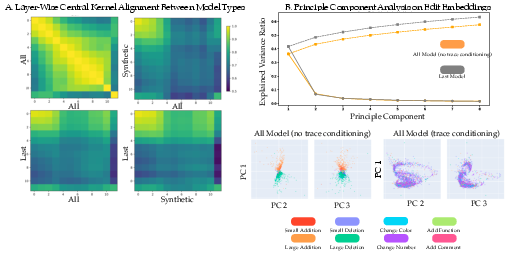
- Edit-type labeling reliability: The rules defining small/large additions/deletions, color/number changes, and function/comment additions aren’t validated for accuracy or inter-annotator agreement; no error analysis (e.g., sensitivity to tokenization, refactors).
- Synthetic traces baseline breadth: Only one synthetic strategy (incremental instruction addition) is considered; more realistic synthetic edit policies (e.g., learned simulators, bug-insertion, refactor patterns) and hybrids mixing real + synthetic data remain unexplored.
- Scaling behavior and architecture choices: Results are shown mainly for a 124M GPT-2 (with limited 1B OLMo-2 results). No scaling-law analysis, ablations on student embedding size/placement, or exploration of architectures tailored for temporal/structural edit modeling (e.g., hierarchical or pointer-based edit models).
- Representation disentanglement: Student embeddings likely entangle student-specific traits with assignment mix, time, and classroom effects (shared accounts). No causal disentanglement or controls (e.g., invariant risk minimization, counterfactual probes) are applied.
- Robustness to shared or reused IDs: Accounts with multiple users (classrooms) and ID reuse can corrupt personalization. Methods to detect/mitigate multi-user accounts and their effect on student embeddings are not proposed or evaluated.
- Probing methodology limitations: Probes show correlations but do not establish that the base model encodes causal knowledge (e.g., controls for confounders, contrastive tests, or probing against strong feature-only baselines like title/length/trace-length).
- Behavioral fidelity of generated traces: There is no human evaluation of trace realism (e.g., expert judgments on plausibility of edit sequences, planning vs tinkering patterns), nor comparison to hand-coded behavioral taxonomies from education research.
- Personalization vs accuracy trade-offs: Using a “strong student” embedding improves execution success but harms similarity to the original student’s style. Multi-objective control (accuracy vs personalization) and principled steering mechanisms remain open.
- Real-time intervention design: While backtracking and time-to-next-edit can be predicted, the paper does not test real-time, in-situ interventions with learners, nor measure effects on learning outcomes, engagement, or over-reliance.
- Temporal modeling and control: Time headers are used as soft control, but there is no explicit temporal modeling (e.g., continuous-time processes, dwell time distributions). How best to leverage real temporal dynamics in training and inference is unclear.
- Fairness and equity: No analysis of whether models encode or amplify disparities across classrooms, schools, or demographics (which are not available). Methods for fairness auditing under anonymization constraints and mitigation strategies are absent.
- Privacy and security guarantees: Although PII is filtered and access is gated, there are no formal privacy guarantees (e.g., differential privacy) or analysis of re-identification risk from student embeddings.
- Reproducibility gap due to PII filtering: All reported results use the original (less-filtered) dataset, but only a more heavily filtered dataset and a trained model are released. The performance delta between original and released datasets is not quantified.
- Error recovery generality: Error recovery is evaluated on specific failure cases and a narrow set of controls (time header, “strong student” embedding). Broader generalization, sensitivity to error types, and comparison to alternative repair strategies (e.g., program repair tools, retrieval-augmented fixes) are untested.
- Baseline diversity: Key baselines are limited to last-program-only and a simple synthetic trace generator. Retrieval-based methods, nearest-neighbor student/style conditioning, or supervised edit-prediction models (diff/patch-style) are not compared.
- Evaluation metrics: Heavy reliance on BLEU/self-BLEU and Pearson correlations may not capture structural or pedagogical relevance of edits. Structure-aware code metrics, semantic similarity, and learning-centric outcomes are needed.
- Language and domain bias: Much of the dataset appears to involve turtle graphics and color-heavy tasks in CoffeeScript/JS. The extent of bias toward graphics tasks and its impact on generalization to algorithmic/textual programming is not analyzed.
- Data leakage risk from pretraining: Potential overlap between public Pencil Code materials and LM pretraining corpora is not audited; contamination could inflate performance.
- Goal segmentation within traces: Students may switch goals mid-trace. Methods to detect goal shifts, segment traces, and evaluate models under goal-switching remain unaddressed.
- Theoretical understanding: There is no formal explanation of why training on edit traces improves steerability and personalization (e.g., information-theoretic analysis of sequence-level supervision vs last-state training).
Practical Applications
Immediate Applications
The following applications can be deployed with current methods and datasets described in the paper, especially within educational coding platforms and beginner-friendly IDEs.
- Education — Student-aware coding assistant for block-based editors
- Use case: Integrate a “trace-aware” assistant into Pencil Code, Scratch, Code.org, or dual block/text editors to suggest next edits, style-preserving fixes, and minimal change sequences when students hit errors.
- Tools/products/workflows:
- “Edit Recommender” that proposes a short sequence of edits (not just a single patch) aligned with the student’s existing style (comments, colors, structure).
- Configurable “granularity slider” using the time-header control to modulate how many edits are proposed (coarse vs. fine-grained help).
- Dependencies/assumptions: Access to per-student trace logging; PII-safe student ID embeddings; platform hooks for conditional generation; success execution checks via headless browser.
- Education — Early intervention via backtracking prediction
- Use case: Predict imminent “goal backtracking” during a coding session and surface supportive hints before the student drifts away from the goal (e.g., misconceptions about 2D coordinates).
- Tools/products/workflows: Inline notifications (“Backtrack Alert”), micro-hints tailored to trace context, TA nudges for students predicted to struggle.
- Dependencies/assumptions: Real-time model probing pipelines; reliable mapping of titles to goals; teacher/admin consent for monitoring.
- Education — Few-shot personalization for new learners
- Use case: Rapidly adapt a student embedding with 1–4 short traces to personalize hint style and solution pathways across sessions.
- Tools/products/workflows: Onboarding “personalization wizard” where students complete a few mini-tasks to initialize their embedding; persistent profile across courses.
- Dependencies/assumptions: Student ID persistence; lightweight finetuning infrastructure; IRB/parental consent for data use.
- Education — Teacher analytics dashboard (process-aware)
- Use case: Provide classroom-level insights into edit behaviors (e.g., backtracking ratios, comment frequency, time-to-success) to inform instruction and targeted support.
- Tools/products/workflows: Dashboard charts over trace metrics; assignment-specific common pitfalls (e.g., coordinate errors); cohort-level progress heatmaps.
- Dependencies/assumptions: Aggregated, anonymized trace exports; interpretability guardrails; teacher training on process analytics.
- Software/dev tools — Style-preserving bug fixer
- Use case: IDE plugin that proposes minimal, style-aligned fixes (colors, comments, idioms) rather than canonical solutions, improving trust and adoption for novices.
- Tools/products/workflows: “Preserve my style” toggle; sequence-of-edits generator; success execution verification.
- Dependencies/assumptions: Access to style signals in embeddings; runtime execution harness; user acceptance testing.
- Software/dev tools — Trace-aware completion mode
- Use case: Completion models that suggest short edit plans (sequence suggestions) instead of single completions, particularly valuable for teaching debugging and refactoring.
- Tools/products/workflows: “Sequence suggestion” mode in code editors; edit distance minimization to remain close to current state.
- Dependencies/assumptions: Context window support for multi-step edits; UI affordances for applying edit sequences safely.
- Academia — Probing-based research toolkit
- Use case: Use trained trace models to probe student or code embeddings and study learning trajectories, behavior prediction (e.g., time investment, future attempts), and process-driven outcomes.
- Tools/products/workflows: Open-source probes (ridge/MLP) for metrics; reproducible pipelines over sanitized data; benchmark suites for modeling human-like reasoning.
- Dependencies/assumptions: Continued access to the gated dataset/model; IRB approvals; acceptance of process-based metrics in evaluation.
- Policy/governance — PII-safe logging and gated release template
- Use case: Adopt the paper’s anonymization pipeline (URL replacement, name masking, title filtering) and gated access policy for student trace datasets.
- Tools/products/workflows: Institutional data governance playbook; consent language templates; audit trails for dataset use.
- Dependencies/assumptions: Institutional buy-in; tooling for automated PII detection; enforcement of gated access terms.
- Daily life — Home learning assistant for novice coders
- Use case: Lightweight web app/plugin that guides hobbyists through edit sequences, personalized hints, and error recovery workflows with adjustable granularity.
- Tools/products/workflows: Browser-based assistant integrated with beginner coding sites; “Try fewer edits” control; friendly explanations tied to observed trace patterns.
- Dependencies/assumptions: API access to platform traces; simplified privacy notices for non-institutional contexts.
Long-Term Applications
These applications require further research, scaling, generalization beyond Pencil Code, or broader institutional adoption.
- Education — Process-aware assessment and micro-credentialing
- Use case: Grade not only final code but also the learning process (e.g., reduction in backtracking, effective use of comments, time-on-task rationalization), issuing badges tied to process mastery (debugging, planning).
- Tools/products/workflows: Rubric frameworks for trace metrics; standards for mastery thresholds; LMS integrations.
- Dependencies/assumptions: Stakeholder acceptance of process-weighted assessment; fairness audits; robust cross-platform trace interoperability.
- Education — Adaptive curriculum and “digital twin” student modeling
- Use case: Build student models that track evolving behaviors and tailor assignments to address predicted misconceptions (e.g., coordinate geometry), sequencing micro-lessons dynamically.
- Tools/products/workflows: Curriculum recommender engines; per-student trajectory visualizations; teacher-in-the-loop overrides.
- Dependencies/assumptions: Longitudinal trace availability; reliable generalization to new concepts/languages; ethical review for adaptive interventions.
- Software/dev tools — Cross-language, cross-platform trace foundation models
- Use case: Train large “trace-aware” foundation models on IDE telemetry (Git diffs, run/debug logs) to support human-like reasoning in professional development environments.
- Tools/products/workflows: Unified trace ingestion from VS Code/JetBrains; generalized edit taxonomy; model APIs for sequence-of-edits reasoning.
- Dependencies/assumptions: Access to high-quality multi-language traces; enterprise privacy agreements; compute and storage scaling.
- Software/dev tools — Sequence-level code assistant for refactoring and onboarding
- Use case: Assist teams with stepwise refactorings and junior onboarding, recommending concise edit plans that maintain codebase style and minimize regression risk.
- Tools/products/workflows: “Refactor as sequence” workflows; style-preserving suggestions; CI hooks to validate staged edits.
- Dependencies/assumptions: Mature model control over edit granularity; robust testing harnesses; cultural acceptance of process-oriented assistants.
- Academia — Standardized benchmarks for human-like reasoning in code
- Use case: Establish community benchmarks that evaluate models on process fidelity (backtracking, exploration, edit diversity), not just final accuracy.
- Tools/products/workflows: Public leaderboards; shared trace datasets across domains (graphics, algorithms); unified metrics and probes.
- Dependencies/assumptions: Broad data contributions; consensus on metric definitions; sustainable governance.
- Policy/governance — Sector-wide standards for trace logging, consent, and portability
- Use case: Develop policies for collecting/editing traces with explicit student consent, data portability across platforms, and auditability of model personalization.
- Tools/products/workflows: Standard consent forms; trace schema standards; APIs for exporting/importing embeddings; compliance checklists.
- Dependencies/assumptions: Multi-stakeholder collaboration (schools, vendors, researchers); legal frameworks that balance utility and privacy.
- Education/workforce — Personalized bootcamps and reskilling programs
- Use case: Tailor coding bootcamps and workplace training using trace-level personalization, targeting common stumbling blocks with efficient sequences and scaffolded hints.
- Tools/products/workflows: Cohort-level analytics; adaptive lab exercises; progression dashboards.
- Dependencies/assumptions: Sufficient individual trace volume for modeling; employer-approved data collection; measures to prevent over-reliance.
- Research/industry — Improved synthetic trace generation aligned with real behavior
- Use case: Develop next-generation synthetic trace generators that mimic real novice behaviors (not just additive edits), to pretrain reasoning models at scale where real traces are scarce.
- Tools/products/workflows: Behavior-calibrated simulators; edit taxonomies beyond “small additions”; validation against real trace distributions.
- Dependencies/assumptions: Access to representative real traces for calibration; careful evaluation to avoid amplifying biases.
- Education — Assistive technologies for learners with diverse needs
- Use case: Use controllable edit sequences and personalization to support learners with different cognitive profiles, pacing needs, or accessibility requirements.
- Tools/products/workflows: Adjustable time/attempt constraints; multi-modal hints (voice, visuals); teacher-configurable scaffolding.
- Dependencies/assumptions: Collaboration with accessibility experts; robust control mechanisms; evidence of efficacy across populations.
Cross-cutting assumptions and dependencies
- Generalization beyond Pencil Code: While preliminary evidence suggests transfer to other languages/libraries is plausible, empirical validation is needed for Python/Java/real IDE workflows.
- Data quality and labeling: Many titles do not fully reflect program semantics; better goal-labeling or assignment metadata improves prediction quality.
- Identity fidelity: Shared accounts can dilute student embeddings; reliable identity provisioning is beneficial.
- Privacy and ethics: Gated releases, anonymization pipelines, and consent are critical; policies must evolve with deployment.
- Compute and infrastructure: Real-time probing, execution validation (headless browsers), and on-device personalization require engineering investments.
- Human factors: Teacher and student acceptance of process-aware tools; risk of over-reliance; need for pedagogy-aligned designs and guardrails.
Glossary
- Adam optimizer: A stochastic optimization method that adapts learning rates using estimates of first and second moments of gradients, commonly used to train neural networks. "We train with a learning rate of $5e-5$ with a linear learning rate scheduler and Adam optimizer."
- BLEU score: An n-gram overlap metric used to evaluate the similarity between generated text and reference text. "We additionally measure the BLEU score \citep{bleu} to directly compare the similarity of generated program traces against the ground truth trace for a given student ID and title, as well as the Self-BLEU \citep{selfbleu} across the final programs of repeated generated samples."
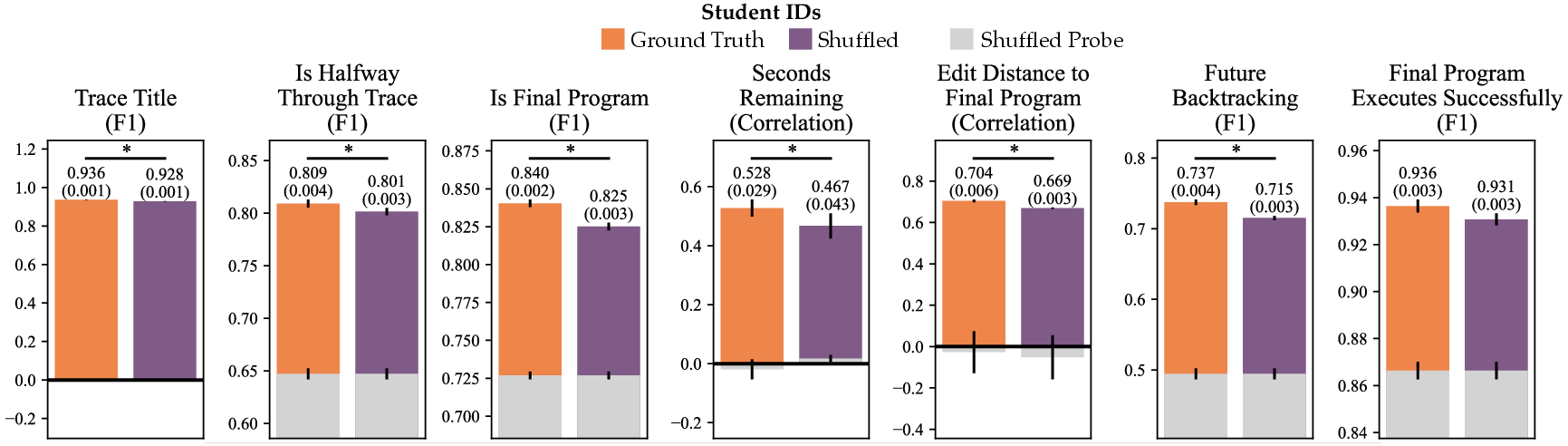
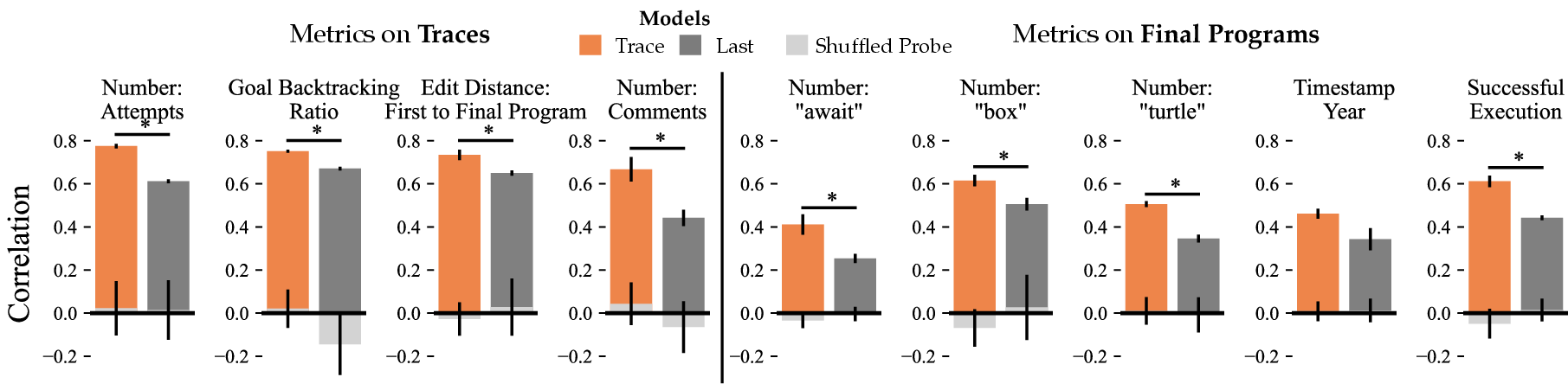
- Bonferroni correction: A statistical adjustment for multiple hypothesis testing to control the family-wise error rate. "* indicates a statistically significant difference with the trace model using a paired T-test between unique (student, title) pairs at with Bonferroni correction, and error bars indicate standard errors of the mean."
- CoffeeScript: A programming language that compiles into JavaScript, offering a more concise syntax. "or directly in web programming languages like CoffeeScript, JavaScript, HTML, and CSS."
- continued pretraining: Further training of a pretrained LLM on additional domain-specific data to adapt it to a new task or corpus. "We train 5 models on Pencil Code data by continued pretraining of LMs."
- cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "The Colors metric compares the cosine similarity of between program color embeddings."
- Droplet: A dual-modality code editor supporting both block-based and text-based programming. "It utilizes Droplet, a dual-modality code editor that allows users to write code through either a visual block-based interface (similar to Scratch) or directly in web programming languages like CoffeeScript, JavaScript, HTML, and CSS."
- edit distance: The minimum number of edit operations (insertions, deletions, substitutions) required to transform one string into another. "the edit distance between the current program state and the final program state"
- end-of-sequence token: A special token used by LLMs to signify the end of a generated sequence. "the trace models occasionally do not generate the end of sequence token;"
- gated release: A controlled-access data release mechanism where usage is monitored and restricted. "to the broader research community through a gated release."
- goal backtracking ratio: The fraction of edits in a trace that increase the distance from the current program to the final goal program. "We measure the goal backtracking ratio of a trace, which is the average fraction of times in a trace that a student's edit results in a an increase in edit distance between the current program and goal program state."
- GPT-2: A transformer-based LLM architecture developed by OpenAI. "Experiments reported in the main paper are conducted with a base 124M parameter GPT-2 model \citep{gpt2}."
- headless browser: A web browser without a graphical user interface, used for automated testing or programmatic execution. "We measure whether a program successfully executes by using a headless browser to attempt to execute the student-written code."
- in-distribution: Refers to data drawn from the same distribution as the training set. "generalization in-distribution to new (student, title) pairs (where each has been seen before separately), as well as out-of-distribution generalization to unseen students and titles."
- IRB (Institutional Review Board): A committee that oversees research ethics involving human subjects. "We first obtained permission from our institution that usage of the data for research purposes is exempt under our institution's IRB."
- linear learning rate scheduler: A method that adjusts the learning rate linearly over training steps or epochs. "We train with a learning rate of $5e-5$ with a linear learning rate scheduler and Adam optimizer."
- MLP (multilayer perceptron): A feedforward neural network composed of multiple layers of perceptrons (fully connected layers). "We train MLP probes on 5 random train/test splits of ."
- Monte Carlo sampling: A stochastic sampling technique used to generate random samples for estimation or analysis. "we generate Monte Carlo samples with a model and analyze properties of the generated programs"
- n-gram: A contiguous sequence of n items (tokens) from a given text or speech sample. "we average across ngram scores."
- nucleus sampling: A probabilistic decoding method that samples tokens from the smallest set whose cumulative probability exceeds a threshold p. "using nucleus sampling with \citep{holtzman2019curious}."
- OLMo-2: A family of open LLMs; here, a 1B-parameter variant used for comparison. "a 1B parameter OLMo-2 model \citep{olmo20242olmo2furious}"
- out-of-distribution generalization: The ability of a model to perform well on data that differ from the training distribution. "generalization in-distribution to new (student, title) pairs (where each has been seen before separately), as well as out-of-distribution generalization to unseen students and titles."
- paired T-test: A statistical test comparing the means of two related samples to determine if they differ significantly. "* indicates a statistically significant difference with the trace model using a paired T-test between unique (student, title) pairs at with Bonferroni correction, and error bars indicate standard errors of the mean."
- Pearson correlation coefficient: A measure of linear correlation between two variables, ranging from -1 to 1. "Correlation denotes Pearson's correlation coefficient."
- PII (Personally Identifiable Information): Information that can be used to identify an individual. "to prevent leakage of PII about school-age children."
- ridge regression: A linear regression technique with L2 regularization to prevent overfitting. "We train ridge regression/classification probes to predict the trace title,\footnote{For this metric, we mask program titles in constructing inputs, i.e., we set to the mask token}"
- Self-BLEU: A diversity metric measuring similarity among multiple generated samples from the same model; lower is more diverse. "as well as the Self-BLEU \citep{selfbleu} across the final programs of repeated generated samples."
- soft token: A learned embedding inserted into the input sequence to condition model behavior. "which is introduced as a ``soft token'' at the start of all program sequences"
- student embedding: A vector representation learned for each student ID to personalize or condition the model. "with a student embedding layer that maps a student ID to a 768-dimension embedding"
- turtle graphics: A graphics programming paradigm using movement commands for a “turtle” cursor to draw, often used in education. "turtle graphics, music composition, speech synthesis, networking, and interactive storytelling."
Collections
Sign up for free to add this paper to one or more collections.

