EditLens: Quantifying the Extent of AI Editing in Text
Abstract: A significant proportion of queries to LLMs ask them to edit user-provided text, rather than generate new text from scratch. While previous work focuses on detecting fully AI-generated text, we demonstrate that AI-edited text is distinguishable from human-written and AI-generated text. First, we propose using lightweight similarity metrics to quantify the magnitude of AI editing present in a text given the original human-written text and validate these metrics with human annotators. Using these similarity metrics as intermediate supervision, we then train EditLens, a regression model that predicts the amount of AI editing present within a text. Our model achieves state-of-the-art performance on both binary (F1=94.7%) and ternary (F1=90.4%) classification tasks in distinguishing human, AI, and mixed writing. Not only do we show that AI-edited text can be detected, but also that the degree of change made by AI to human writing can be detected, which has implications for authorship attribution, education, and policy. Finally, as a case study, we use our model to analyze the effects of AI-edits applied by Grammarly, a popular writing assistance tool. To encourage further research, we commit to publicly releasing our models and dataset.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces EditLens, a tool that tries to measure how much a piece of writing was edited by AI. Instead of just saying “this was written by a human” or “this was written by AI,” EditLens aims to tell you how strongly AI changed a human’s original text—like a slider from “barely touched” to “heavily rewritten.”
What questions are the researchers asking?
The researchers focus on simple, practical questions:
- Can we tell the difference between fully human writing, fully AI-generated writing, and human writing that was edited by AI?
- Can we estimate how much AI changed a piece of writing, not just whether AI was involved?
- Can this measurement work across many topics, writing styles, and different AI tools (like ChatGPT, Claude, or Gemini)?
- Will this help teachers, publishers, and platforms use fair rules, such as allowing light AI proofreading but not full AI-written essays?
How did they approach the problem?
Think of writing like a school essay you edit several times:
- A human writes the first draft (original text).
- An AI tool edits that draft (edited text).
The challenge: In real life we often only see the edited text, not the original. So the model must guess, based on the final text alone, how much AI changed it.
Here’s their approach in everyday terms:
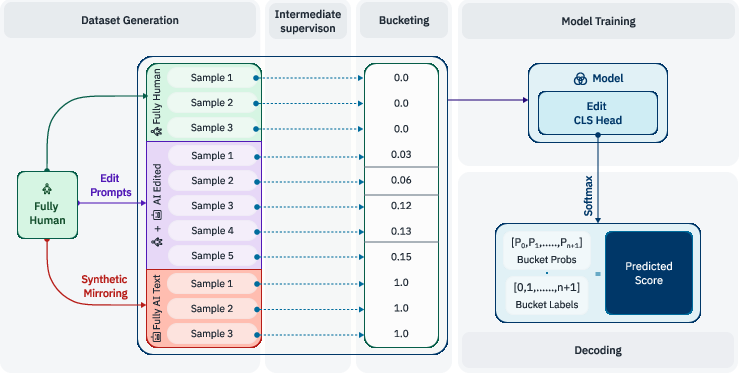
- Creating a dataset:
- They collected thousands of human-written texts (from before AI tools became common), such as reviews, stories, educational articles, news, and emails.
- For each human text, they asked several AI models (GPT-4.1, Claude, Gemini, and more) to create versions that were either completely AI-generated or AI-edited using 303 different editing prompts (like “fix grammar,” “make more descriptive,” “summarize this,” etc.). This gave them lots of examples with different levels of editing.
- Measuring “how much changed” with simple similarity checks:
- Embedding cosine distance: Imagine turning each text into a list of numbers (an “embedding”) that captures its meaning. If two texts point in similar directions in number-space, they're similar; if they point in different directions, they're different. The model uses “cosine distance” to score how far apart the original and edited texts are. Bigger distance = heavier editing.
- Soft n-grams: Break both texts into many small phrases, and count how many edited phrases have close matches (by meaning, not just exact words) in the original. More matches means lighter editing; fewer matches means heavier editing.
- Checking with humans:
- They asked expert annotators (people used to reading both human and AI writing) to judge which of two AI edits changed a text more. These human judgments agreed reasonably well with the two similarity measures above. That means their simple measures track what people think “heavy vs. light editing” looks like.
- Training the model (EditLens):
- They fine-tuned a LLM (Mistral 24B) using QLoRA (a memory-efficient training method).
- Goal: Given only the edited text, predict a score (from low to high) that reflects the magnitude of AI editing.
- They tested two ways: train it as a regression (predict a number directly), and train it as classification (predict buckets of editing levels) and then convert those outputs into a number.
What did they find?
Here are the main results and why they matter:
- EditLens can tell:
- Human vs. AI-written text very well (binary accuracy around 94%, F1 up to about 95%).
- Human vs. AI-edited vs. fully AI-generated (three-way classification) with high accuracy (around 90% macro-F1), beating other detectors that only do yes/no or simple categories.
- It’s nuanced, not just “AI or not”:
- Unlike many detectors that only spit out 0 or 1, EditLens scores reflect how much editing took place. For example, on a dataset where AI applied different levels of “polish” to writing, EditLens scores rise smoothly as edits get heavier, matching changes seen in text similarity (like Levenshtein/Jaccard).
- It generalizes:
- Works on texts from new topics (like emails) and new AI models it wasn’t trained on, with only a small drop in performance.
- When AI edits a text multiple times, the score steadily increases—just like you’d expect if editing keeps piling up.
- When humans fix AI-written text (BEEMO dataset), the scores usually go down, which makes sense: human edits often reduce AI “feel.”
- When AI re-edits AI text, the score barely changes—suggesting the tool is measuring “AI influence on human writing,” not just “any editing.”
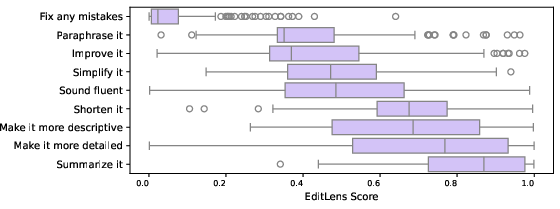
- Real-world case study (Grammarly):
- “Fix any mistakes” tends to be the lightest edit.
- “Summarize this” and “Make it more detailed” are among the heaviest edits because they change structure and content, not just grammar.
Why does this matter?
- Fairer rules in schools and workplaces:
- Instead of banning AI entirely or allowing everything, EditLens lets institutions set “policy caps.” For example, allow light proofreading but not major rewriting. That helps reduce false accusations and matches how people actually use AI.
- Better authorship insights:
- Mixed writing is becoming normal: people write, AI edits, then people tweak again. This tool accepts that reality and gives a sensible way to measure involvement.
- Encourages transparency and research:
- The team is publicly releasing their dataset and models, so others can build on this and improve AI detection responsibly.
Bottom line
EditLens shifts AI text detection from a simple yes/no to “how much editing happened.” It uses easy-to-understand similarity checks and a trained model to predict a smooth score from the final text alone. This makes AI detection more useful and fair in real-life settings, where light AI help may be okay but heavy AI rewriting is not.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is framed so future researchers can act on it.
- Ground-truth definition of “edit magnitude”: The study equates AI-edit extent with embedding-based similarity (cosine on Linq-Embed-Mistral) and “soft n-grams,” but does not establish a gold-standard, human-validated scale for edit intensity across diverse edit types (grammar fixes, paraphrase, summarization, restructuring). Develop a larger, multi-annotator, multi-domain benchmark with calibrated human judgments and psychometrics for edit magnitude.
- Limited human validation: The human agreement study uses only 3 expert annotators and 100 tasks, yielding moderate agreement. Scale up validation (more annotators, diverse backgrounds, languages, proficiency levels) and report inter-rater reliability across domains and edit types to test external validity.
- Metric choice and sensitivity: The paper does not provide a systematic sensitivity analysis for soft n-grams parameters (phrase length bounds a/b, similarity threshold τ) or the embedding model choice. Perform ablations across embedder families, parameter grids, and length normalization schemes; quantify robustness to shortening, reordering, and paraphrase intensity.
- Deletion and shortening invariance: Soft n-grams is “shortening-invariant,” potentially misclassifying heavy deletions (e.g., summaries) as minor edits. Design metrics that distinguish content-preserving from content-reducing edits and evaluate alignment with human perceptions of “invasiveness.”
- Style vs. semantics disentanglement: Embedding similarity conflates semantic preservation and stylistic drift. Build or learn metrics that separately capture style changes (lexical choice, register, rhythm) versus semantic changes (content addition/removal/reordering), then train multi-dimensional edit scores.
- Single-pass AI editing assumption in training: Although multi-edit trajectories are probed post hoc, the training setup focuses on single-pass AI edits. Develop training curricula for multi-pass, multi-agent (human+AI) coauthoring, including provenance-aware models that track edit sequences.
- Edited-text-only inference: The model predicts edit magnitude from the edited text y without conditioning on source x at inference. Explore dual-input models that optionally use x when available, and compare performance and failure modes across single-input vs. dual-input settings.
- Generalization beyond English and selected domains: Data is English-centric and limited to reviews, creative writing, educational web content, news, and emails. Evaluate cross-lingual performance (low- and high-resource languages), code/text hybrids, scientific writing, legal briefs, social media microtexts, and poetry; quantify domain-shift effects.
- Real-world prompt diversity: The 303 edit prompts are mostly collected via LLMs and authors, not real user logs. Collect and analyze anonymized, consented real-world edit prompts (e.g., from educational platforms) to capture natural prompt distributions and mixing patterns.
- LLM diversity and forward compatibility: Training/evaluation focuses on a fixed set of contemporary LLMs. Test EditLens against newer and smaller models, local fine-tunes, and purposeful “humanizer” paraphrasers; measure performance drift over time and propose calibration/update strategies.
- Adversarial robustness: No systematic evaluation of targeted attacks (e.g., paraphrasers tuned to minimize predicted edit scores while heavily altering text). Build adversarial suites and certify robustness (e.g., worst-case performance under attack constraints).
- Fairness and bias: The detector may behave differently for non-native writing, dialects, or atypical styles. Audit bias across writer demographics, proficiency levels, and genres; quantify false positives/negatives and propose fairness-aware thresholding.
- Confidence and calibration: The model outputs a score but does not report uncertainty or calibration quality. Add calibrated confidence intervals, reliability diagrams, and risk-aware decision rules for policy use.
- Threshold selection for deployment: Ternary/binary thresholds are tuned on a validation set, but operational guidance for policy caps (acceptable edit levels) is not established. Provide procedures for threshold setting under explicit cost constraints and stakeholder preferences.
- Explainability of edits: EditLens outputs a scalar score without explanations of what changed (e.g., grammar, style, structure). Develop interpretable components (per-edit-type contributions, edit heatmaps, style-change attributions) to aid educators and reviewers.
- Provenance and edit attribution: The homogeneous setting avoids segment-level attribution. Explore probabilistic provenance models that quantify fractional authorship, even if imprecise, and integrate them with edit magnitude.
- Alignment with policy constructs: The paper references policy caps but does not connect scores to normative rules (e.g., “≤10% style change allowed; no content addition”). Map score ranges to actionable policies and validate their social acceptability.
- Dataset representativeness and quality: Human-written sources are pre-2022, which may differ stylistically from current writing. Assess representativeness, temporal drift, and potential biases; release detailed sampling protocols and reweighting strategies.
- Open taxonomy claim: The dataset is said to span a “full taxonomy of AI-edits,” but the taxonomy is not formalized. Propose and validate a structured taxonomy (micro-edits: insertions, deletions, substitutions, reorderings; macro-edits: paraphrase, summarization, style transfer) with labeled exemplars.
- Ablations on model architecture and decoding: Best results rely on a 24B backbone and weighted-average decoding, but ablations are limited. Perform systematic size/architecture sweeps, compare regression vs. n-way classification with various decoding schemes, and investigate distillation to smaller models for deployability.
- Length and structure effects: The impact of document length, format (lists, tables), and discourse structure on scores is not fully characterized. Analyze scale effects and structural robustness; propose normalization or segment-wise aggregation.
- Mixed-source ambiguity (AI-edited AI and human-edited AI): Initial tests show average score shifts, but mechanisms are unclear. Expand evaluations across models and edit intents to distinguish “AI-on-AI” from “human-on-AI” edits reliably.
- Watermark and metadata integration: The approach is text-only. Explore combining EditLens with watermark detectors, provenance metadata, and edit logs to improve accuracy and reduce false positives.
- Calibration to real “percent-edit” ground truth: APT-Eval uses requested polish levels rather than actual measured edits. Construct controlled corpora with known edit percentages (token-level or semantic), and evaluate monotonicity and sensitivity.
- Robustness to noise and typos: Grammar fix operations can be trivial or substantial depending on initial error density. Quantify performance across varying noise levels and non-native error profiles; assess whether the model over-penalizes necessary corrections.
- Temporal stability and reproducibility: As embeddings and LLMs evolve, scores may drift. Track temporal stability, version pinning, and reproducibility under dependency changes; propose maintenance protocols.
- Privacy and data governance: Real-world coauthoring data would boost validity, but raises privacy concerns. Establish ethical data collection frameworks and anonymization methods to enable realistic training and evaluation.
- Evaluation metrics beyond macro-F1: Detection is evaluated primarily via correlations and F1. Introduce decision-theoretic metrics (AUROC, AUPRC under policy caps), utility-based measures, and calibration error to reflect practical risk trade-offs.
- Cross-task generalization: The method is evaluated on generic writing; applicability to tasks like translation, summarization, and technical editing is not established. Test transferability and tailor edit metrics per task type.
- Source reconstruction potential: Although the paper eschews reconstructing x at inference, it remains an open question whether partial source reconstruction (e.g., retrieval of candidate originals) could improve edit magnitude prediction; design and test hybrid approaches.
Practical Applications
Immediate Applications
The following applications can be deployed now using EditLens and the released dataset/models, with standard integration engineering and policy calibration. Each item notes sectors, potential tools/workflows, and feasibility assumptions.
- AI-use policy enforcement with adjustable thresholds
- Sectors: education, publishing/media, enterprises (comms/marketing), government
- What: Enforce “policy caps” on acceptable AI assistance (e.g., proofreading allowed; rewriting disallowed) by gating submissions based on an EditLens score threshold calibrated to local norms.
- Tools/workflows: LMS or CMS plugin; API in submission portals (assignments, RFPs, op-eds, compliance filings); dashboard for triage of borderline cases; configurable alerts.
- Assumptions/dependencies: Domain-specific threshold calibration on a held-out set; human-in-the-loop for high-stakes decisions; communicate uncertainty and error rates to users.
- Academic integrity triage and formative feedback
- Sectors: education (K–12, higher ed, testing and assessment)
- What: Use score-based triage to prioritize instructor review; provide learner-facing guidance when AI-use exceeds rubric limits; offer reflective prompts to encourage revision when editing is heavy.
- Tools/workflows: LMS integration (Canvas, Moodle, Google Classroom); grader dashboards with per-document EditLens score; student feedback widgets (“your AI-edit level is high relative to this assignment’s cap”).
- Assumptions/dependencies: Clear course-level policy; privacy controls (FERPA/GDPR); avoid punitive automation—use as signal with instructor review.
- Editorial transparency and labeling
- Sectors: journalism, academic publishing, marketing/PR
- What: Add standardized disclosure labels (e.g., “light AI editing” vs. “heavy AI rewriting”) based on score bands.
- Tools/workflows: CMS hook pre-publication; byline/badge generator tied to thresholds; audit logs for ombudspersons and reviewers.
- Assumptions/dependencies: Organization buys into disclosure standards; periodic recalibration by content type (investigative vs. listicles).
- Marketplace and platform trust & safety
- Sectors: e-commerce (reviews), freelance marketplaces, social platforms, app stores
- What: Flag likely AI-polished or mass-edited content for moderation, especially fake reviews and engagement spam; route to human moderation when scores exceed caps for authenticity-critical content.
- Tools/workflows: API in review ingestion pipelines; risk scoring layer; feedback loop with moderators.
- Assumptions/dependencies: Platform policies define “acceptable AI assistance”; supplement with other fraud signals (accounts, network patterns) to reduce false positives.
- Compliance pre-checks for regulated communications
- Sectors: finance (retail communications, research notes), healthcare (patient-facing materials), legal (consumer contracts), government
- What: Require human sign-off when AI-edit magnitude exceeds a threshold; log provenance for audits.
- Tools/workflows: Document composition gateways in MS Office/Google Workspace; approval workflows; audit trail export to GRC systems.
- Assumptions/dependencies: Sector-specific regulations and internal governance; privacy and data residency; internal calibration for each document class.
- Hiring/HR content screening
- Sectors: HR/recruiting, higher-education admissions
- What: Triage cover letters/essays for heavy AI involvement; enable disclosure or additional writing samples when scores are high.
- Tools/workflows: ATS plugin; recruiter dashboard showing EditLens score bands; candidate-facing disclosures.
- Assumptions/dependencies: Ethical use and transparency to candidates; not used as sole rejection criterion.
- Writing-assistant “transparency mode” and user feedback
- Sectors: software/SaaS (writing tools, IDE docs), productivity suites
- What: Surface an “edit magnitude meter” to users after applying AI suggestions; allow users to cap editing intensity (e.g., “keep edits light”).
- Tools/workflows: Plugin for Grammarly-like systems, Google Docs/Microsoft Word add-ons; SDK wrapper around EditLens for in-editor scoring; telemetry for model A/B testing.
- Assumptions/dependencies: Vendor adoption; latency budget for near-real-time scoring; UI/UX for meaningful user control.
- Vendor/responder fairness in RFPs and grant applications
- Sectors: government procurement, philanthropy, enterprise sourcing
- What: Enforce caps on AI usage in narrative responses; document transparent scoring; minimize unfair advantage via full AI rewrites.
- Tools/workflows: Submission portal gatekeeping; post-submission audit; notifications for rework if score exceeds cap.
- Assumptions/dependencies: Clear solicitation rules; appeal process for disputing scores.
- E-discovery and content forensics triage
- Sectors: legal, compliance, internal investigations
- What: Tag and prioritize documents by AI-edit involvement in e-discovery; identify clusters of machine-influenced drafts.
- Tools/workflows: Integration with e-discovery platforms; batch-scoring pipelines; reviewer dashboards.
- Assumptions/dependencies: Chain-of-custody and privacy controls; score interpreted as “extent of machine editing,” not authorship attribution.
- Quality assurance for LLM rewriting features
- Sectors: software/ML engineering, product teams
- What: Quantify how invasive an editing feature is across prompts; ensure “light proofreading” modes remain light; regression tests on release.
- Tools/workflows: CI pipelines with EditLens thresholds; experiment dashboards; guardrails for feature rollout.
- Assumptions/dependencies: Representative evaluation corpora; periodic OOD checks (new LLMs, domains).
- Content compensation and workflow analytics
- Sectors: localization/translation, content agencies, academic editorial services
- What: Audit proportion of AI-only vs. human-edited work to inform pricing, SLAs, and credits.
- Tools/workflows: Batch analytics; job-level EditLens reports; contracts referencing score bands.
- Assumptions/dependencies: Agreed-upon band definitions; acceptance by clients and providers; governance to avoid penalizing non-native writers unfairly.
- Research benchmarking and methodology
- Sectors: academia (NLP, HCI, education research)
- What: Use the dataset and model to study human-AI co-writing, evaluate paraphrasers/humanizers, and design experiments with continuous edit-intensity as a variable.
- Tools/workflows: Open models/dataset; experiment scripts; replication of paper’s correlation protocols.
- Assumptions/dependencies: Respect license terms (non-commercial for some releases); citation and provenance practices.
Long-Term Applications
These applications need further research, scaling, standardization, or robustness work before broad deployment.
- Per-segment localization of AI edit intensity
- Sectors: education, publishing, forensics
- What: Move from document-level scores to sentence/paragraph-level edit-intensity maps for targeted feedback and auditing.
- Dependencies: New training signals beyond global similarity; methods bridging homogeneous editing to local attribution; careful UI to avoid over-interpretation.
- Multilingual, domain-robust, and cross-register detection
- Sectors: global platforms, public sector, localization
- What: Reliable scoring across languages, specialized domains (clinical, legal), and varied registers (non-native writing, informal speech transcripts).
- Dependencies: Larger multilingual datasets; fairness audits; domain calibration; performance under OOD drift and adversarial paraphrasing.
- Standards for “AI Editing Index” and provenance labels
- Sectors: content platforms, journalism, regulators, standards bodies
- What: Create interoperable score bands and metadata (e.g., C2PA extensions) that travel with content and are recognized across tools.
- Dependencies: Industry and standards-body consensus; cryptographic provenance where possible; alignment with watermarking and disclosure policies.
- Regulatory and legal acceptance for audits and adjudication
- Sectors: courts, regulators, accreditation bodies
- What: Use score evidence in disputes (e.g., plagiarism cases, IP authorship claims, advertising disclosures) with agreed error bounds.
- Dependencies: Validation studies, external audits, expert testimony; guidelines on acceptable error rates; due-process safeguards.
- Platform-level AI involvement labeling at scale
- Sectors: search, social networks, marketplaces
- What: Systematically label or down-rank content exceeding AI-edit thresholds; enable user filters (“show mostly human-edited content”).
- Dependencies: Scalability and latency improvements; bias and fairness mitigation; continuous re-calibration as models evolve.
- Real-time “edit meter” in productivity suites
- Sectors: software/productivity, education
- What: Live feedback as users accept AI suggestions, showing cumulative edit intensity and nudges to stay within policy.
- Dependencies: Low-latency inference, partial-document scoring, privacy-preserving on-device variants.
- Insurance and risk products around content liability
- Sectors: insurance, enterprise risk
- What: Underwrite content risk based on AI-edit level (e.g., higher review for heavily rewritten health/finance advice).
- Dependencies: Actuarial evidence linking risk to edit levels; accepted standards for scoring and reporting.
- Compensation and rights frameworks tied to human contribution
- Sectors: creative industries, translation/localization, gig platforms
- What: Contracts and royalties that reference human contribution bands; audit trails to back claims.
- Dependencies: Negotiated norms; anti-gaming safeguards; alignment with evolving copyright policy.
- Robustness to adversarial paraphrasing and “humanizers”
- Sectors: all text platforms
- What: Maintain reliable scoring when texts are intentionally obfuscated to evade detection.
- Dependencies: Adversarial training; ensemble approaches (e.g., boundary detectors + EditLens + watermark signals); continuous red-teaming.
- Multi-version trajectory analytics
- Sectors: collaboration platforms, research
- What: Track edit trajectories across drafts to detect sudden machine-dominated rewrites or cumulative drift.
- Dependencies: Access to version history; privacy controls; models calibrated on multi-pass editing data.
- Cross-modal extensions (speech-to-text, code, multimodal docs)
- Sectors: customer service (ASR transcripts), developer tooling, accessibility
- What: Estimate AI edit magnitude for transcripts or code comments and technical docs combined with text.
- Dependencies: New datasets; modality-specific cues; careful scoping (current work focuses on natural language text).
- Public-sector comment integrity and civic processes
- Sectors: government, civic tech
- What: Detect mass AI-polishing in public comments to ensure authentic participation weightings.
- Dependencies: Transparent policies and civil liberties safeguards; balanced use to avoid chilling effects; appeal mechanisms.
Cross-cutting assumptions and considerations
- Calibration is essential: thresholds should be set per domain, document type, and risk tolerance (paper shows good OOD generalization with small but nonzero degradation).
- Use as decision support, not sole arbiter: especially in high-stakes contexts; pair with human review and complementary signals (provenance, stylometry, metadata).
- Fairness and bias: evaluate impacts on non-native speakers and domain-specific styles; monitor false positives/negatives and communicate uncertainty.
- Privacy and compliance: scoring user content implicates data protection; consider on-device or secure processing; adhere to FERPA/GDPR/sectoral rules.
- Licensing: the paper indicates non-commercial release and researcher/educator vetting; commercial deployment may require separate licensing or alternatives.
- Model drift and evolving LLMs: implement continuous evaluation and re-calibration as models, prompts, and usage patterns change.
Glossary
- APT-Eval: A benchmark for AI-polished text used to assess edit magnitude tracking. "On the AI Polish dataset (APT-Eval), EditLens achieves substantially stronger correlations with edit magnitude metrics compared to binary detectors (correlation 0.606), markedly outperforming the best binary baseline Pangram (correlation 0.491)."
- Argmax decoding: A decoding method that selects the class with the highest predicted probability. "using weighted-average decoding rather than traditional argmax decoding."
- Bayes-optimal predictor: The predictor that minimizes expected loss under the true data distribution; here it equals the conditional expectation of the target given the input. "The Bayes-optimal predictor for this objective is the conditional expectation"
- Boundary detection: Identifying boundaries between human- and AI-authored segments in heterogeneous mixed text. "has treated the task as either a boundary detection problem \citep{kushnareva2024aigenerated,lei2025pald}"
- Change magnitude functional: A function that quantifies the extent of editing between source and edited texts. "We define a change magnitude functional "
- Conditional expectation: The expected value of a random variable given another; used as the optimal prediction target. "The Bayes-optimal predictor for this objective is the conditional expectation"
- Cosine distance: A measure of dissimilarity defined as 1 minus cosine similarity between vectors. "The first is the cosine distance (1 - cosine similarity) between the Linq-Embed-Mistral \citep{Choi2024LinqEmbedMistral} embeddings of the source text and the AI-edited version."
- Cosine similarity: A measure of similarity based on the cosine of the angle between two vectors. "We compute the pairwise cosine similarity between phrases in the source and edited texts"
- Editing operator: A formal operator representing the transformation from source to edited text. "We model the edited text as the image of an editing operator applied to :"
- Embedding-based ROUGE: A ROUGE variant that uses word embeddings to compare semantic overlap. "a precision-based method similar to the embedding-based ROUGE proposed by \citet{ng-abrecht-2015-better}"
- Embeddings: Vector representations of text capturing semantic information. "between the Linq-Embed-Mistral \citep{Choi2024LinqEmbedMistral} embeddings of the source text and the AI-edited version."
- Heterogeneous mixed authorship: Mixed text where authorship of segments can be clearly attributed to human or AI. "Examples of heterogeneous and homogeneous mixed authorship texts."
- Homogeneous mixed authorship: Mixed text where human and AI contributions are entangled by editing and cannot be cleanly separated. "In the homogeneous case, authorship is entangled by the editing process."
- Inductive biases: Built-in assumptions that guide a model’s learning toward certain patterns. "absorbing the necessary inductive biases (e.g., lexical volatility, style drift, fluency/consistency cues)"
- Jaccard distance: A set-based dissimilarity metric measuring non-overlap. "and Jaccard distance (0.781) metrics"
- Krippendorff's α: An inter-annotator agreement coefficient for assessing reliability. "We report Krippendorff's \citep{Krippendorff1980Chapter12} for our 3 annotators"
- Latent: Unobserved variables or structures underlying observed data. "z denotes a (latent) sequence of micro-edits (insertions, deletions, substitutions, reorderings)"
- Levenshtein distance: The edit distance between two strings based on insertions, deletions, and substitutions. "Levenshtein distance (0.799)"
- Linq-Embed-Mistral: A specific text embedding model used for similarity measurement. "between the Linq-Embed-Mistral \citep{Choi2024LinqEmbedMistral} embeddings"
- Macro-F1: The unweighted average F1-score across classes. "macro-F1 on the ternary classification task decreases from 0.904 to 0.866 (-0.038)."
- Micro-edits: Small operations like insertions, deletions, substitutions, and reorderings applied during editing. "z denotes a (latent) sequence of micro-edits (insertions, deletions, substitutions, reorderings)"
- Monotone transformation: A function that preserves order, used to map similarity to change magnitude. "by a monotone transformation of similarity (or distance):"
- MSE loss: Mean squared error, a regression loss function. "We experiment with directly training a regression head using MSE loss"
- MTEB benchmark: The Massive Text Embedding Benchmark for evaluating embedding models. "its strong all-around performance on the MTEB benchmark \citep{muennighoff2023mtebmassivetextembedding}."
- N-way classification: Classification over n discrete categories. "training both a regression model and -way classification models"
- Out-of-distribution (OOD): Data that differs from the training distribution, used to test generalization. "As a holdout domain to measure out-of-distribution performance"
- Pearson correlation coefficient: A measure of linear correlation between two variables. "we measure the Pearson correlation coefficient () between the prediction scores"
- Precision-based metric: A metric that evaluates the proportion of predicted positives that are correct. "This count is divided by the total number of phrases in the edited text, making it a precision-based metric."
- QLoRA: A method for efficient finetuning of quantized LLMs. "Using QLoRA \citep{qlora2023}, we finetune models of between 3 and 24B parameters"
- Regression head: A model component that outputs a continuous value rather than a class label. "We experiment with directly training a regression head"
- Semantic similarity: The degree to which two texts have similar meaning. "assign higher scores as semantic similarity decreases"
- Sentence-wise classification: Classifying each sentence individually rather than entire documents. "a sentence-wise classification task \citep{wang-etal-2023-seqxgpt}"
- Similarity functional: A function mapping pairs of texts to a similarity score in [0,1]. "Let be a fixed similarity functional."
- Soft n-grams: A cosine-based phrase-overlap metric that captures semantic rather than exact matches. "We refer to this metric as the soft n-grams score throughout the paper."
- Synthetic mirroring procedure: A data-generation method that creates AI versions corresponding to human texts. "following the synthetic mirroring procedure introduced in \cite{emi2024technicalreportpangramaigenerated}."
- Taxonomy: A structured categorization of AI edits. "a full taxonomy of AI-edits to human-written texts."
- Ternary classification: Classification into three categories (e.g., human, AI-generated, AI-edited). "state-of-the-art performance on both binary (F1=94.7\%) and ternary (F1=90.4\%) classification tasks"
- Threshold calibration: Tuning decision thresholds on a validation set to optimize metrics. "Thresholds were calibrated using the val set."
- Token-level labels: Authorship or class labels assigned to individual tokens in text. "One can create token-level labels for heterogeneous mixed texts: every token was authored by either human or AI."
- Watermarking: Embedding detectable signals into generated text via modified decoding. "in contrast to work on watermarking~\citep{kirchenbauer2024watermarklargelanguagemodels}"
- Weighted-average decoding: Producing a numerical score via a weighted average over class outputs. "using weighted-average decoding rather than traditional argmax decoding."
Collections
Sign up for free to add this paper to one or more collections.

