- The paper introduces MM-Nav by leveraging multi-view RGB inputs and multi-expert RL distillation to enhance navigation in cluttered, dynamic environments.
- It employs a two-stage teacher-student pipeline where distinct RL experts are first trained and then aggregated to boost generalization and performance.
- Real-world deployment on a Unitree GO2 robot confirms improved collision avoidance, agility, and effective sim-to-real transfer with RGB-only input.
MM-Nav: Multi-View VLA Model for Robust Visual Navigation via Multi-Expert Learning
Introduction and Motivation
The MM-Nav framework addresses the challenge of robust visual navigation in cluttered and dynamic environments using only RGB observations. Traditional approaches relying on single-camera setups or depth sensors are limited by field-of-view constraints and hardware costs, while learning-based methods often struggle with generalization and sim-to-real transfer. MM-Nav proposes a multi-view Vision-Language-Action (VLA) model that leverages 360° RGB perception and multi-expert reinforcement learning (RL) distillation to achieve high-performance, generalizable navigation policies.
System Architecture and Training Pipeline
The MM-Nav system is built around a two-stage teacher-student pipeline. First, three RL experts are independently trained in simulation, each specializing in a distinct navigation capability: reaching, squeezing through narrow gaps, and dynamic obstacle avoidance. These experts utilize privileged depth information and are trained with tailored reward structures to maximize their respective competencies.
The VLA student model is then initialized via behavior cloning from the aggregated expert demonstrations. The architecture extends a video-based VLA model to support multi-view input, encoding a sliding window of four synchronized RGB camera streams (front, right, back, left) into visual tokens using a SigLIP-based visual encoder and a cross-modal projector. The navigation goal is formatted as a textual prompt and encoded as language tokens. These are concatenated and processed by a LLM (Qwen2-7B), followed by an MLP action head to predict continuous velocity commands.
A key innovation is the iterative online teacher-student training phase, where the VLA model is deployed in simulation and further refined using expert actions collected online. The data aggregation is dynamically balanced across capabilities using a performance gap metric based on weighted travel time (WTT), ensuring that the model focuses on its weakest skills during each iteration.
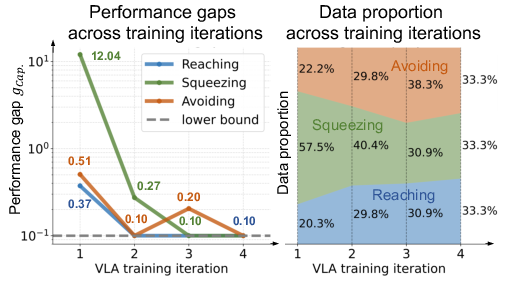
Figure 2: Plot of online training iteration. (Left): the performance gaps gCap. between the VLA model and the RL experts. (Right): the different proportions of online collected data per capability.
Experimental Evaluation
Simulation Benchmarks
MM-Nav is evaluated in IsaacLab across three capability-specific scenes and a mixed scenario containing all challenge types. The model achieves the highest success rates, lowest collision rates, and shortest weighted travel times compared to strong baselines such as NavDP, ViPlanner, and iPlanner. Notably, MM-Nav demonstrates robust performance in scenarios with thin obstacles, dynamic agents, and narrow passages, where single-view or discrete-action policies fail due to limited spatial awareness or insufficient agility.
Real-World Deployment
The model is deployed on a Unitree GO2 robot equipped with four fisheye cameras. In real-world tests, MM-Nav successfully navigates complex environments, including zigzag corridors, cluttered static scenes, and dynamic obstacles such as moving wheelchairs and thin rods. The system demonstrates strong sim-to-real transfer, outperforming both its RL teachers and traditional LiDAR-based avoidance systems, particularly in detecting and avoiding visually challenging obstacles.
Ablation and Analysis
Ablation studies confirm the necessity of both the multi-expert distillation and the capability-balanced data aggregation strategy. Training the VLA model on data from a single expert yields strong performance only in the corresponding scenario, with poor generalization to other tasks. In contrast, the mixed-expert VLA model achieves high success rates across all capabilities, indicating effective skill fusion and mutual reinforcement. The iterative, performance-gap-driven data aggregation accelerates convergence and prevents overfitting to any single capability.
Implementation Considerations
- Computational Requirements: RL expert training is performed with 128 parallel environments on an RTX 4090 GPU, while VLA model fine-tuning utilizes 8 H100 GPUs. Inference on the robot is performed at 7 Hz using a 7B-parameter LLM, which is sufficient for real-time navigation.
- Tokenization and Efficiency: The sliding window and grid-based pooling strategies maintain a manageable token sequence length, ensuring inference speed without sacrificing temporal or spatial context.
- Sim-to-Real Transfer: The use of multi-view RGB, randomized camera parameters during data collection, and co-tuning with open-world QA data contribute to the model's robustness in real-world deployment.
- Extensibility: The architecture is compatible with further acceleration via quantization and can be extended to additional navigation skills or sensor modalities.
Implications and Future Directions
MM-Nav demonstrates that multi-view VLA models, when distilled from specialized RL experts and trained with capability-aware data aggregation, can surpass the performance of their teachers and generalize across diverse navigation challenges. The approach provides a scalable template for synthesizing complex embodied skills from modular expert policies, with strong sim-to-real transfer using only RGB input.
Potential future directions include:
- Cross-embodiment transfer, enabling the same VLA policy to generalize across different robot platforms.
- Integration of additional skills (e.g., manipulation, social navigation) via further expert distillation.
- Exploration of more efficient model architectures or hardware-aware optimizations for deployment on resource-constrained platforms.
- Extension to open-vocabulary or instruction-driven navigation using richer language prompts.
Conclusion
MM-Nav establishes a robust framework for visual navigation by combining multi-view perception, VLA modeling, and multi-expert RL distillation. The system achieves high performance in both simulation and real-world environments, with strong evidence for the synergistic effect of integrating diverse navigation capabilities. The methodology sets a precedent for future research in scalable, generalizable, and efficient embodied AI systems.