- The paper introduces ACF, which learns independently controllable latent variables from pixel data using contrastive objectives.
- ACF leverages action-effect sparsity to isolate state components influenced by specific actions for efficient reinforcement learning.
- Empirical tests in Taxi and Minigrid domains show ACF outperforms baselines by achieving higher R² metrics in disentanglement.
From Pixels to Factors: Learning Independently Controllable State Variables for Reinforcement Learning
This essay provides an in-depth analysis and authoritative summary of the paper "From Pixels to Factors: Learning Independently Controllable State Variables for Reinforcement Learning," which addresses a significant gap in reinforcement learning (RL) by focusing on learning factored representations from high-dimensional pixel data without predefined state-variable factors.
Introduction
Classical approaches in reinforcement learning (RL) have highlighted the benefits of factored Markov decision processes (FMDPs) for achieving sample efficiency. However, they require predefined state-variable factors, which is impractical in environments where agents only have high-dimensional sensory inputs. This paper introduces Action-Controllable Factorization (ACF), a contrastive learning-based method designed to discover independently controllable latent variables directly from pixels without the need for manual factorization.
Technical Approach
ACF utilizes contrastive learning to isolate state components influenced by actions. The crux of the methodology lies in leveraging the sparsity of action effects: typically, an action affects only a subset of variables, with others following the environment's natural dynamics. A contrastive objective compares predictions of next-state distributions under specific agent actions against natural transitions. The paper introduces a specific energy-based parameterization for learning state transitions, which allows for efficient learning of independently controllable factors.
The identification problem is formalized where a diffeomorphic mapping from high-dimensional observations to latent spaces needs to be learned. The dynamics of the underlying state space are modeled as:
T(s′∣s,a)=i∈Ψ(s,a)∏Ti(si′∣s,a)j∈Ψ(s,a)∏Tj(sj′∣s,a0),
where Ψ(s,a) denotes the variables affected by action a.
Learning Framework
The encoder fϕ and transition dynamics parameterized by energy functions Eθ ensure the learned factors are independently controllable. The losses designed for optimizing the encoder and energies include:
- Inverse Dynamics Loss: Cross-entropy loss to fit a softmax classifier for predicting actions given state transitions.
- Forward Dynamics Loss: InfoNCE to maximize mutual information between consecutive states.
- Ratio Loss: Binary cross-entropy loss using estimated logits ra(x′,x) to capture the discrepancy between action-induced and natural dynamics.
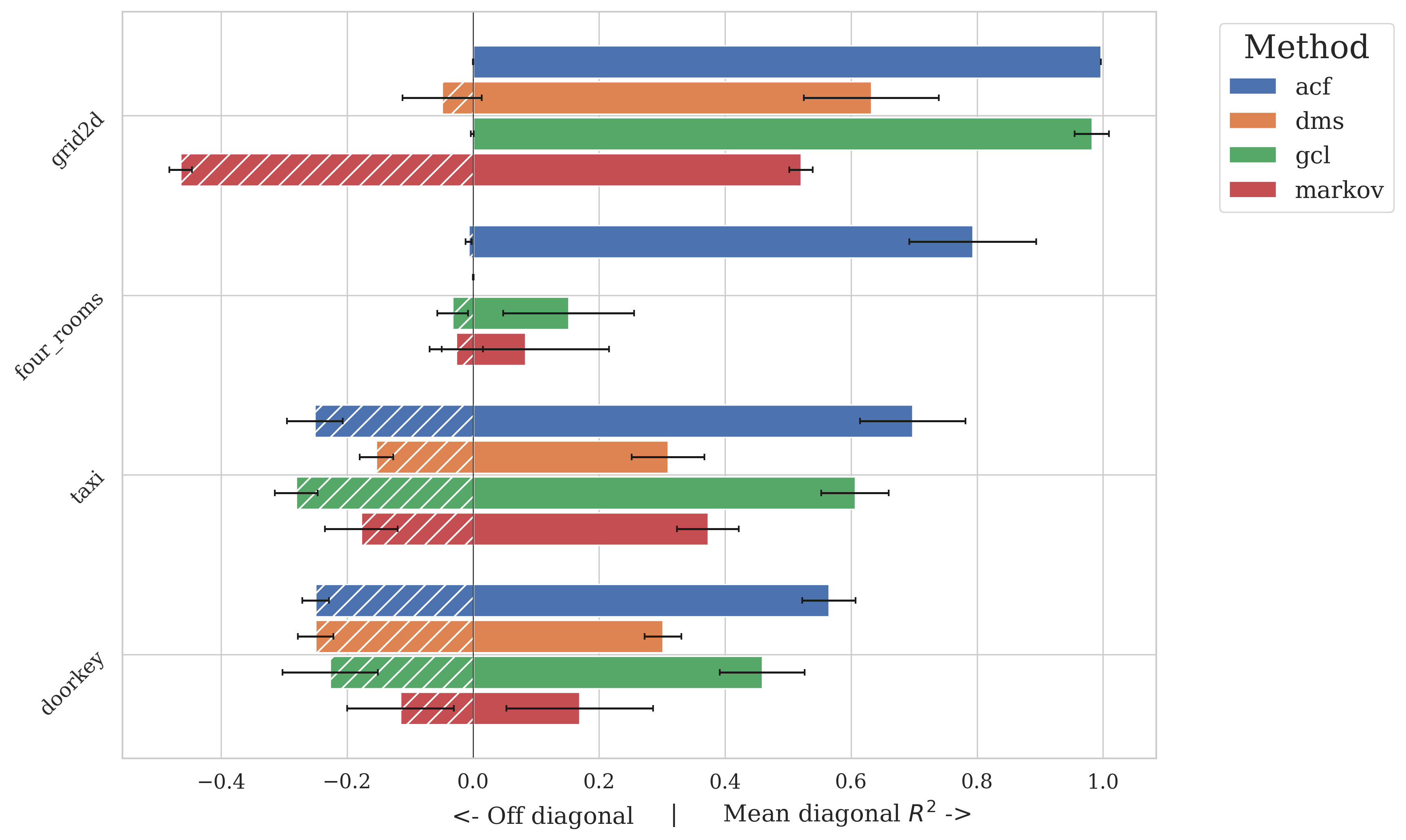
Figure 1: Factorization metrics. The left side bars show information represented off the diagonal, while the right bars represent mean diagonal values in R2 matrices.
Empirical Evaluation
The paper evaluates ACF across several benchmark environments, including visual variations of the Taxi domain and Minigrid environments like FourRooms and DoorKey. The results demonstrate that ACF consistently recovers controllable factors and performs superior to baseline disentanglement methods such as GCL and DMS.
Results Analysis
- Factorization Metrics: The R2 matrices (Figure 2) assessed the disentanglement quality, aiming for high diagonal and low off-diagonal values to signal successful isolation of underlying factors.
- Quantitative Performance: ACF demonstrated a significant improvement in identifying independently controllable factors, outperforming baselines by achieving higher mean diagonal R2 values.

Figure 2: Factorization matrices for DoorKey. Mean R2 matrices over 5 seeds.
Insights from Traversals
Latent space traversals in domains like Taxi and DoorKey revealed meaningful correspondence between latent variables and controllable state components (Figures 3 and 4), visualizing how variations in each latent dimension affect the environment's state.


Figure 3: Taxi latent traversals, highlighting passenger dynamics through varied latent variables.

Figure 4: DoorKey latent traversals, demonstrating controllable elements such as agent and key positions.
The study situates ACF within the broader RL literature, noting the historical focus on exploiting factored representations and recent advancements in latent space modeling. It contrasts ACF with previous efforts in disentangled representation learning and causal structure discovery, emphasizing its novel contribution to learning factored structures without explicit supervision or predefined factor graphs.
Conclusion
The research introduces a method that bridges the gap between pixel-based deep learning approaches and the efficiency of factored RL by automatically discovering independently controllable state variables. This advancement points towards potential future improvements in RL systems' ability to generalize across tasks by learning compact, interpretable representations directly from unstructured sensory data. Further exploration could enhance factor identification for both controllable and critical non-controllable state variables.

