Interactive Training: Feedback-Driven Neural Network Optimization
Abstract: Traditional neural network training typically follows fixed, predefined optimization recipes, lacking the flexibility to dynamically respond to instabilities or emerging training issues. In this paper, we introduce Interactive Training, an open-source framework that enables real-time, feedback-driven intervention during neural network training by human experts or automated AI agents. At its core, Interactive Training uses a control server to mediate communication between users or agents and the ongoing training process, allowing users to dynamically adjust optimizer hyperparameters, training data, and model checkpoints. Through three case studies, we demonstrate that Interactive Training achieves superior training stability, reduced sensitivity to initial hyperparameters, and improved adaptability to evolving user needs, paving the way toward a future training paradigm where AI agents autonomously monitor training logs, proactively resolve instabilities, and optimize training dynamics.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
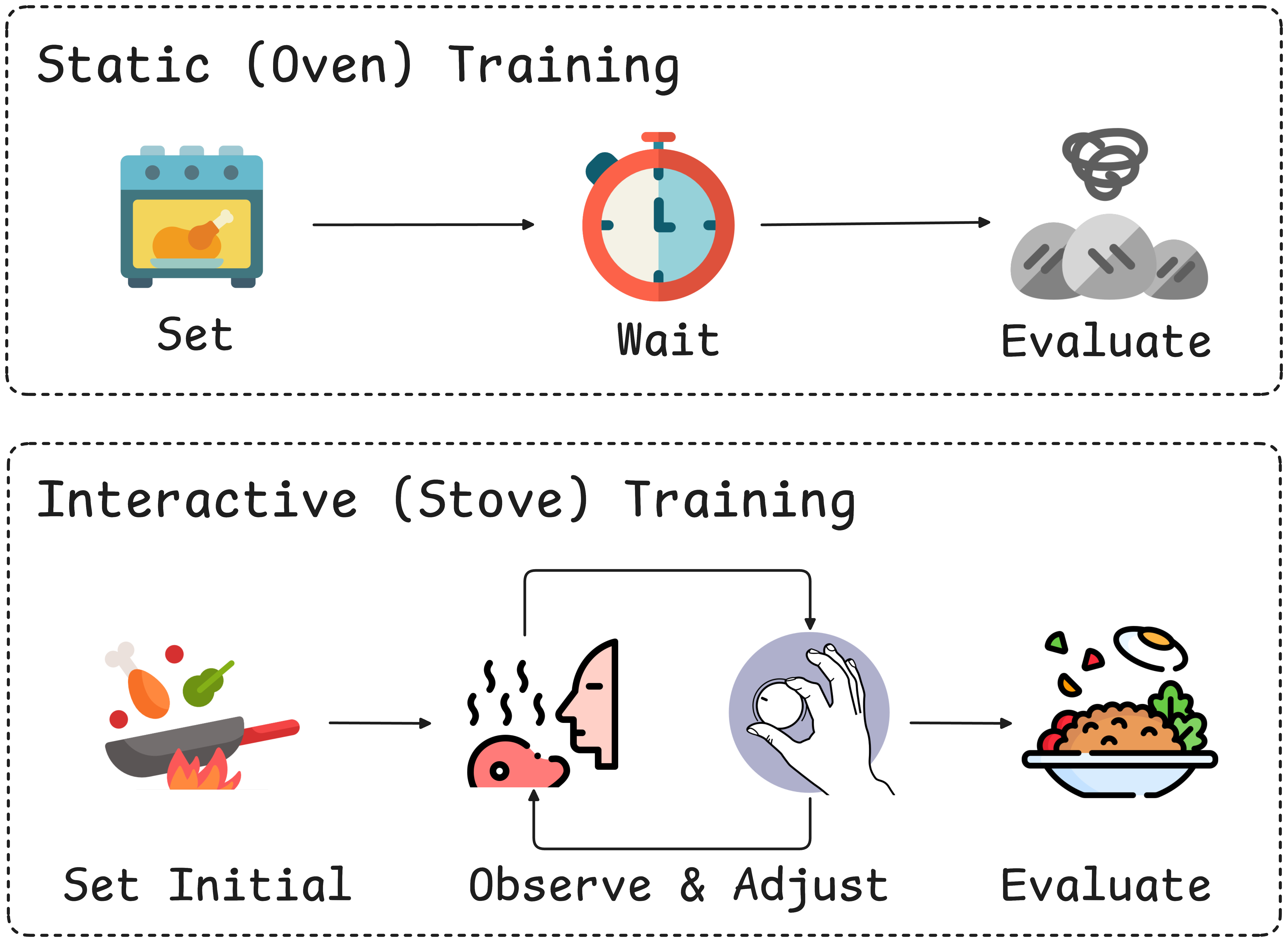
This paper introduces a new way to train AI models called “Interactive Training.” Instead of setting all the training settings at the start and hoping everything goes well (like baking with a closed oven), Interactive Training lets people or AI helpers watch the training in real time and make adjustments on the fly (like cooking on a stove and changing the heat as needed). The goal is to make training more stable, faster to fix when it goes wrong, and easier to adapt to new needs.
Key Questions
The paper asks simple but important questions:
- Can training work better if humans or AI agents adjust settings while the model is learning?
- Can this approach fix common problems during training without stopping and restarting?
- Can training automatically adapt to new data that shows up after the model is deployed?
How They Did It
The basic idea
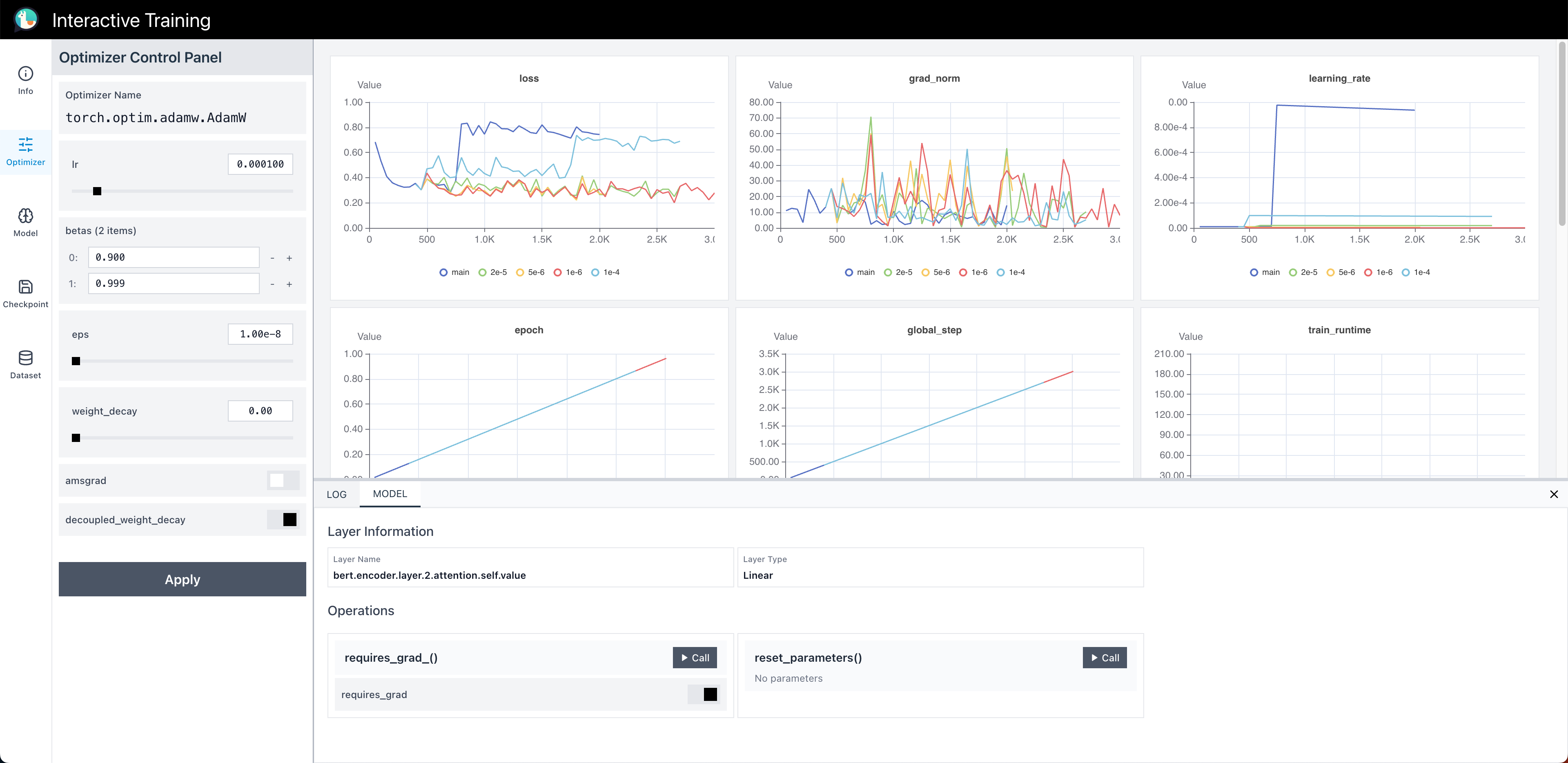
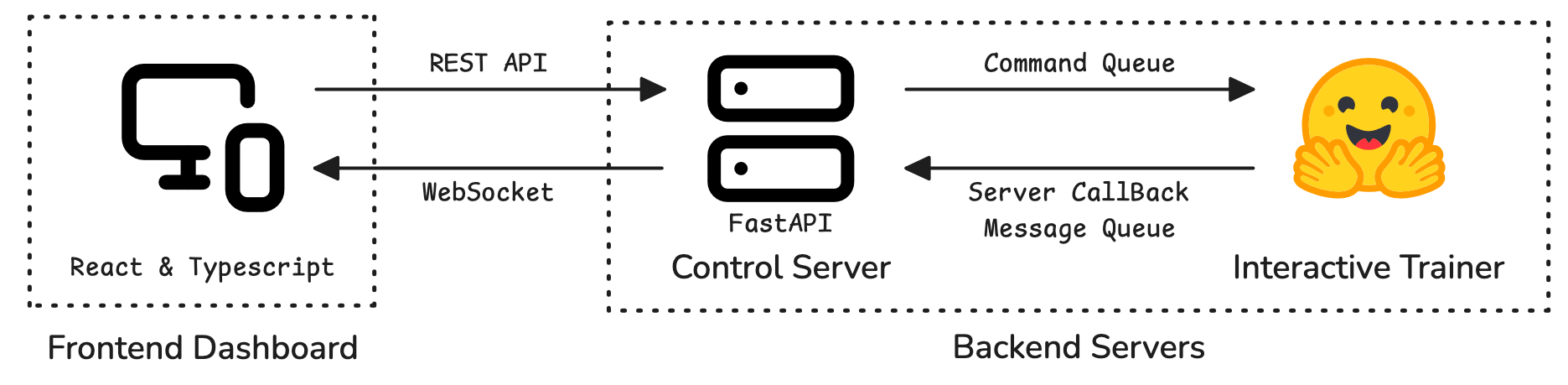
They built an open-source toolkit that connects a running training job to a dashboard and a small server. This setup lets a person (or an AI agent) change important training settings in real time—like the learning rate, the data being used, or which saved version of the model to go back to—without stopping the training run.
How the system works
There are three main parts working together:
- Control Server: A “traffic controller” that receives commands (like “lower the learning rate”) and sends back training updates (like current loss).
- Interactive Trainer: The actual training loop that listens for commands and applies them safely at the next step.
- Frontend Dashboard: A website that shows the training charts live and lets users click buttons or enter values to make changes.
This is built on popular tools:
- Hugging Face Transformers Trainer (for training models)
- FastAPI (for the server)
- React and WebSockets (for the live dashboard)
What can you change during training?
With Interactive Training, you can:
- Adjust the learning rate (how fast the model learns).
- Change gradient clipping (a safety limit that stops the model from making huge jumps).
- Load or revert to saved checkpoints (saved versions of the model).
- Update the training dataset on the fly (e.g., add new real-world examples as they arrive).
- Pause/resume or branch training (create “what if” paths from a prior checkpoint).
If any of these words feel new:
- Hyperparameters: Settings you choose before or during training, like the learning rate.
- Checkpoint: A saved snapshot of the model partway through training.
- Gradient: The direction/size of the change the model makes to improve; “clipping” sets a maximum size for safety.
Main Findings
The authors tested Interactive Training in three case studies:
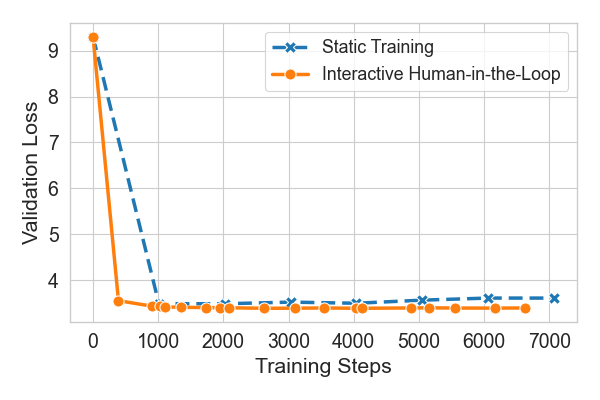
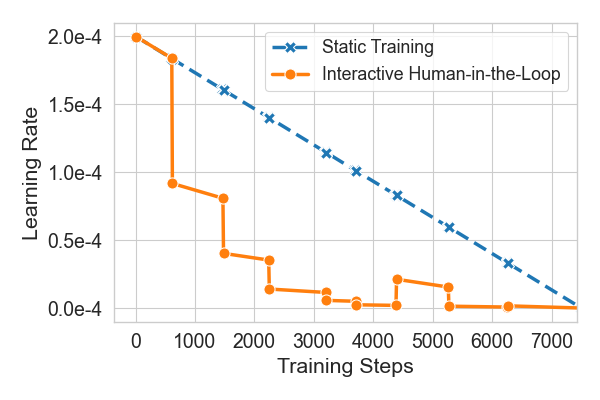
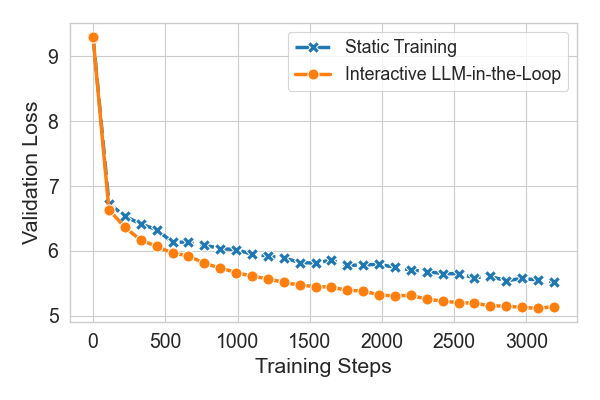
- Human-in-the-loop training beats a fixed schedule They fine-tuned a LLM and compared two ways:
- Fixed plan: a pre-set learning rate schedule.
- Interactive plan: a human watched the charts and adjusted the learning rate when things looked shaky. Result: The interactive approach led to lower (better) validation loss. When the loss started bouncing due to too-high learning rate, the human turned it down and the training stabilized and improved.
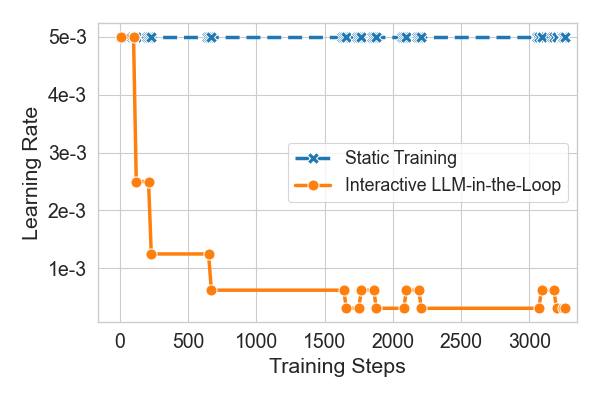
- An AI helper can fix bad settings mid-run They intentionally started training with a way-too-high learning rate to make it unstable. Then an LLM-based AI agent read the training logs and decided whether to halve, double, or keep the learning rate each step. Result: The AI agent quickly lowered the learning rate and stabilized training, recovering from the bad start without stopping the job.
- Models can learn from new user data in real time They trained a screen-simulator model (a diffusion model that predicts the next screen frame from user actions). After deploying it online, they collected real user interactions and fed them into the ongoing training without restarting. Result: The model improved on tasks users actually do (like using a web browser or creating folders), showing the system can adapt to real-world behavior as it happens.
Why this matters:
- It reduces wasted time and compute from stopping and restarting jobs.
- It makes training less fragile when initial settings are not perfect.
- It enables models to keep improving after deployment as new data arrives.
What It Means and Why It’s Important
Interactive Training turns model training from a fixed, one-way process into a flexible, two-way conversation. That has several big benefits:
- Better stability: You can fix problems the moment they show up.
- Less guesswork up front: Even if your starting settings aren’t perfect, you can adjust on the fly.
- Faster adaptation: Your model can learn from new, real-world data while it’s still training.
- Path to automation: AI agents can watch training and make smart changes automatically, like a co-pilot.
A few things to keep in mind:
- Different people or agents might make different choices, so results can vary; logging every change helps with reproducibility.
- Good interventions still require some expertise; in the future, specialized AI agents could learn these skills.
Overall, this work suggests a future where training isn’t “set it and forget it,” but interactive, adaptive, and potentially self-correcting—leading to more reliable AI systems that improve continuously. The authors released the code and a demo so others can try it and build on it.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper, directed at future researchers.
- Quantitative benchmarking across diverse settings: Establish standardized metrics (e.g., convergence speed, final test accuracy, stability under perturbations, compute cost) and run statistically powered studies across multiple tasks (LM, vision, speech, RL), datasets, and model scales (including modern LLMs and diffusion models), beyond the small GPT-2/Wikitext-2 and NeuralOS case studies.
- Comparative baselines: Perform controlled comparisons against adaptive training baselines (e.g., Population-Based Training, Bayesian/Hyperband AutoML, RL-discovered schedules, adaptive gradient clipping, mixed precision heuristics) to measure what interactive training adds beyond existing dynamic methods.
- Distributed and large-scale applicability: Validate correctness and performance under data/model/pipeline parallel training (DeepSpeed ZeRO/FSDP, Megatron-LM, TensorFlow/JAX, TPUs), including command propagation consistency across ranks, synchronization semantics, and impact on throughput at multi-node scale.
- Control-loop latency and stability: Measure end-to-end command-to-actuation latency and analyze how intervention frequency and magnitude affect training stability; develop and evaluate safe controller policies (e.g., bounds, rate limiters) to avoid oscillation or divergence.
- Runtime overhead: Quantify the per-step cost of logging, WebSocket updates, and callbacks on wall-clock time, GPU utilization, and training throughput for small vs. large models; provide profiling and optimization guidance.
- Robustness and guardrails: Define and evaluate guardrails (range validation, policy checks, atomic rollbacks) against erroneous or adversarial commands; characterize failure modes (e.g., NaNs, exploding gradients) and recovery strategies triggered by the framework.
- Security and privacy of the control channel: Specify authentication/authorization, encryption, audit trails, and role-based permissions; assess risks of prompt injection via training logs to LLM agents and propose mitigations; validate compliance for multi-tenant/HPC deployments.
- Reproducibility under interactivity: Beyond logging, develop deterministic replay protocols that capture timing/asynchrony, random seeds, dataset versions, and multi-client command ordering; empirically validate replay fidelity on representative runs.
- Real-time data governance: Establish procedures for data quality control, deduplication, labeling/metadata, and privacy for user-collected data; measure risks of catastrophic forgetting and concept drift when injecting new data; study weighting/mixing strategies between new and existing data.
- Safe deployment updates: Define criteria and pipelines for promoting checkpoints to production (A/B testing, canary releases, automated rollback, regression monitoring) when models are updated continuously during training.
- Agent action space and competence: Expand beyond simple learning-rate halving/doubling to richer interventions (optimizer changes, gradient clipping, layer freezing, loss shaping, data mixing); create benchmarks and evaluation protocols for intervention agents, including sample efficiency and out-of-distribution generalization.
- Agent efficiency and cost: Quantify the inference latency and monetary cost of LLM-in-the-loop decisions, their impact on training throughput, and explore on-device/lightweight agents, batching decisions, or periodic vs. continuous control to reduce cost.
- Training health diagnostics: Define, instrument, and validate “health” indicators (e.g., hidden-state variance, gradient noise scale, activation saturation, dead neuron detection) and evaluate their predictive value for when and how to intervene.
- Human factors and UX: Conduct user studies on cognitive load, error rates, intervention timing/quality across expertise levels; derive best-practice playbooks and UI defaults that improve outcomes and reduce risky actions.
- Framework and hardware coverage: Document, implement, and test support for non-Transformer tasks (vision, speech, RL), other training frameworks (PyTorch Lightning, TensorFlow/Keras, JAX/Flax), and specialized hardware (TPUs), detailing API and semantics differences.
- Theoretical foundations: Formalize interactive training as a closed-loop control or online-learning problem; derive stability guarantees, safety constraints, and regret bounds for intervention policies under noisy, delayed feedback.
- Multi-agent coordination: Design arbitration policies and conflict-resolution mechanisms when multiple experts/agents issue concurrent commands; log provenance of decisions, priorities, and branch origins.
- Branching and provenance at scale: Specify storage lifecycle, merging/comparison tooling, and cost models for branched checkpoints and histories; evaluate I/O overhead and usability in long-running experiments.
- Large-scale evaluation and significance: Replicate and extend results on state-of-the-art models/datasets with test-set reporting and statistical significance (e.g., multiple seeds), including ablations isolating the effect of each intervention type.
- Ethical and legal considerations: Address consent, anonymization, and governance for real-user interaction data (e.g., NeuralOS), including data minimization and regulatory compliance; publish data-sharing protocols enabling reproducible research without compromising privacy.
- Automated failure detection and recovery: Implement and benchmark detectors for instability (NaNs, exploding/vanishing gradients, loss spikes) and compare automated recovery recipes to existing best practices (e.g., loss scaling, gradient clipping) under controlled stress tests.
- Scheduler and cluster compatibility: Evaluate operation under SLURM/Kubernetes and restricted networking environments; design alternative control channels (e.g., file- or message-queue–based) and quantify reductions in queue/restart overhead.
- Command API specification: Provide a formal, versioned JSON schema with type-safety, validation, and backward compatibility guarantees; include conformance tests across model types and training setups.
- Bias and fairness impacts: Study whether interactive adjustments (human or agent) concentrate improvements on frequent or profitable tasks at the expense of rare or sensitive cases; propose fairness-aware data mixing and intervention constraints.
- Long-term maintenance of agents/controllers: Develop processes to monitor, evaluate, and update intervention agents and controller policies as training practices and model architectures evolve; define lifecycle and drift management strategies.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with the paper’s open-source framework today, leveraging its control server (FastAPI), Interactive Trainer (HF Transformers wrapper), and React dashboard for two-way, real-time training control.
- Live hyperparameter rescue for unstable training — Software/AI, Cloud/HPC
- Use case: Intervene mid-run to fix exploding/vanishing loss by adjusting learning rate, momentum, weight decay, or gradient clipping without killing the job.
- Tools/products/workflows: “Training Ops Console” that connects to running jobs; HF Trainer + make_interactive wrapper; alerting on loss spikes; one-click LR/clip updates; pause/resume.
- Assumptions/dependencies: Training uses PyTorch/HF Transformers; accessible control port; RBAC/network rules allow secure access; staff knows intervention best practices.
- Branching experiments and checkpoint time-travel — Academia, Enterprise ML, MLOps
- Use case: Revert to a stable checkpoint, branch with different schedules or data mixtures, and compare runs with preserved histories.
- Tools/products/workflows: Branch-aware experiment tracker; integrated checkpoint registry; differential metrics dashboard across branches.
- Assumptions/dependencies: Sufficient storage/IO for frequent checkpoints; consistent seeding/logging for replay; governance of “which branch becomes prod.”
- Real-time data ingestion for continuous finetuning — Software/AI, Media/Creative, E-commerce
- Use case: Continuously pull user interaction data (e.g., app telemetry, prompts, clicks) into the training dataloader via make_interactive_dataset to rapidly adapt models post-deployment (as shown with NeuralOS).
- Tools/products/workflows: Continuous finetuning loop; live data queue with validation filters; rolling checkpoint promotion to staging/prod.
- Assumptions/dependencies: Data rights and privacy controls; online/offline eval gates before promotion; drift and bias monitoring; rate limits to avoid catastrophic forgetting.
- Human-in-the-loop curriculum steering — Software/AI, Education, Healthcare R&D
- Use case: Manually up/down-weight datasets or inject targeted examples when diagnostics reveal weaknesses (e.g., specific categories, rare entities).
- Tools/products/workflows: Data mixture sliders in the dashboard; on-demand validation tasks; scripted data weight changes via REST API.
- Assumptions/dependencies: Labeled or diagnosable subsets; approval workflows for sensitive domains; monitoring of overfitting and distribution shift.
- LLM “Training Copilot” for basic interventions — Software/AI, MLOps
- Use case: Deploy a lightweight LLM agent to monitor logs and adjust learning rate (halve/hold/double) or toggle schedulers to recover from poor initial settings (replicating the case study).
- Tools/products/workflows: Log summarization stream to agent; policy-configured action set; auto-generated intervention rationale logs.
- Assumptions/dependencies: Reliable prompt design; human override; cost/latency budgets for LLM calls; guardrails to prevent oscillatory or unsafe changes.
- Safety and compliance console during training — Finance, Healthcare, Regulated AI
- Use case: Pause/resume on anomaly detection (gradient overflow, NaNs), enforce stricter clipping, or revert to last good checkpoint; archive immutable intervention logs for audits.
- Tools/products/workflows: “Safe Switch” controls; anomaly detectors; immutable append-only intervention ledger for governance.
- Assumptions/dependencies: Domain-specific safety policies; audit storage; incident response playbooks; change-approval routing.
- Cluster efficiency and cost control — Cloud/HPC, Enterprise IT
- Use case: Avoid job restarts and queue delays by fixing issues mid-run; dynamically shorten or extend training based on real-time validation.
- Tools/products/workflows: Cost-aware training SLOs; early-stopping toggles; per-job “rescue window” policy.
- Assumptions/dependencies: Scheduler/network policies allow interactive sessions; cost tracking; SLAs for shared clusters.
- Collaborative remote debugging of training runs — Enterprise ML, Academia
- Use case: Multiple experts or agents connect to a single run, view identical metrics, and apply coordinated, logged interventions.
- Tools/products/workflows: Multi-user dashboard sessions; role-based permissions; conflict resolution for concurrent commands.
- Assumptions/dependencies: Access control and audit; latency tolerance; clear ownership of runs.
- Teaching and demonstrations of optimization dynamics — Education
- Use case: Classroom labs where students visualize loss/gradients and change LR/clipping to observe effects in real time.
- Tools/products/workflows: “Interactive Training Lab” course modules; sandbox datasets/models; graded intervention tasks.
- Assumptions/dependencies: Safe compute environments; small models/datasets for quick feedback; faculty training materials.
- Rapid post-deployment patching for generative models — Media/Creative, Productivity Software
- Use case: Hot-fix behavior regressions or style drifts by ingesting curated examples and nudging hyperparameters without a full retrain.
- Tools/products/workflows: Canary checkpoints; rollback buttons; targeted prompt/asset curation pipelines.
- Assumptions/dependencies: Human QA gate before promotion; IP checks on curated data; rollback guarantees.
Long-Term Applications
These opportunities require further research, scaling, safety frameworks, or infrastructure integration beyond the current library.
- Autonomous “Training Operator” agents — Software/AI, Cloud
- Use case: Specialized agents continuously diagnose training health, adjust hyperparameters/data, run ablations, and promote checkpoints with minimal human input.
- Tools/products/workflows: AutoTrainer/TrainingOps agent; policy engine; closed-loop A/B validation and rollback.
- Assumptions/dependencies: Robust benchmarks for intervention agents; safe action spaces; formal verification of policies; strong observability.
- Training health diagnostics and KPIs — Cross-sector
- Use case: Standardized “training health” indicators (e.g., hidden-state variance, saturation, gradient pathologies) that trigger interventions.
- Tools/products/workflows: Model Health Dashboard; learned anomaly detectors; health-to-action playbooks.
- Assumptions/dependencies: Research to validate predictive value of metrics; domain-specific thresholds; low-overhead instrumentation.
- Closed-loop continuous learning with guardrails — Recommenders, Ads, Productivity, Gaming
- Use case: Stream data from production, adapt models in near real-time, and gate deployment via online/offline tests and safety checks.
- Tools/products/workflows: Continuous Delivery for Models (CD4ML) with interactive controls; shadow deployments; metric-driven promotion.
- Assumptions/dependencies: Strong eval suites; bias/fairness and safety monitors; data contracts; rollback/snapshot infrastructure.
- Clinician-in-the-loop adaptive training — Healthcare
- Use case: Incorporate new clinical patterns or rare cases via curated finetuning sessions overseen by clinicians; adjust data weights for emerging conditions.
- Tools/products/workflows: Clinical oversight console; PHI-safe data pipelines; intervention auditing aligned with ISO/IEC/FDI guidelines.
- Assumptions/dependencies: Regulatory approvals; privacy compliance (HIPAA/GDPR); rigorous validation; conservative promotion policies.
- Interactive on-robot learning and safety tuning — Robotics, Autonomous Systems
- Use case: Adjust learning rates/clipping, freeze/unfreeze subsystems, and revert checkpoints during on-robot learning to prevent unsafe policy updates.
- Tools/products/workflows: Safety-rated training controls; sim-to-real interactive sessions; fail-safe checkpointing on-device.
- Assumptions/dependencies: Real-time constraints; formal safety envelopes; hardware acceleration; reliable telemetry.
- Federated interactive training — Edge/IoT, Mobile
- Use case: Central coordinator issues dynamic data weight/hyperparameter changes across clients based on aggregated health metrics and drift.
- Tools/products/workflows: Federated control plane; privacy-preserving metrics; branch-aware global models.
- Assumptions/dependencies: Communication-efficient, secure aggregation; heterogeneity handling; consent and on-device resource limits.
- Energy/carbon-aware adaptive training — Energy, Sustainability, Cloud
- Use case: Adjust batch size/LR/precision dynamically based on grid carbon intensity, energy price, or thermal limits to minimize footprint.
- Tools/products/workflows: Carbon-intensity or price oracles; energy-aware schedulers; training power telemetry.
- Assumptions/dependencies: Accurate real-time signals; stable convergence under dynamic resource policies; SLO trade-offs.
- Policy and certification for training traceability — Government, Regulated Industries
- Use case: Mandate intervention logs, branch histories, and reproducible replays as part of AI governance, audits, and incident investigations.
- Tools/products/workflows: Standardized intervention schemas; secure log notarization; compliance dashboards; third-party audit APIs.
- Assumptions/dependencies: Standards adoption; legal frameworks; tamper-evident storage.
- Automated data curation and targeted synthesis — Software/AI, Enterprise Data
- Use case: Agents detect capability gaps and inject or reweight specific examples (including synthetic data) mid-training to shape model competencies.
- Tools/products/workflows: Data flywheel orchestrator; synthetic data generators tied to diagnostics; automated curriculum schedulers.
- Assumptions/dependencies: Reliable gap detection; safeguards against data poisoning and bias; provenance tracking.
- Cloud-native Interactive Training services — Cloud/HPC
- Use case: Managed offerings (e.g., “Interactive Training on SageMaker/Vertex/Azure ML”) integrating dashboards, APIs, and agent hooks as first-class primitives.
- Tools/products/workflows: Turnkey service with VPC peering, RBAC, compliance packs, and integrations with W&B/MLflow.
- Assumptions/dependencies: Provider support; enterprise security models; multi-tenant isolation; SLA-backed uptime.
Cross-cutting assumptions and dependencies
- Technical: PyTorch/HF Transformers compatibility (or adapters for other stacks), stable network channels between trainer and control server, sufficient storage for frequent checkpoints, and observability for loss/gradients/metrics.
- Organizational: Clear ownership of interventions, policies for promotion/rollback, and change management in regulated settings.
- Safety/ethics: Guardrails for automated agents, bias/drift monitoring when ingesting live data, and human oversight for high-stakes domains.
- Security/compliance: Authentication/authorization for control endpoints, encrypted transport, audit logging, and adherence to data governance and privacy laws.
- Economics: LLM-agent costs/latencies, compute budget for longer interactive sessions, and ROI analysis for continuous finetuning versus periodic retrains.
Glossary
- Active learning: A paradigm where the model selectively queries humans for labels to improve learning efficiency. "In active learning, the learning algorithm remains in control but queries human annotators for labels on selected examples"
- AutoML: Methods that automate hyperparameter tuning and model optimization processes. "AutoML research has developed methods to automate hyperparameter tuning and training optimization."
- Bandit strategies: Algorithms that adaptively choose among options (e.g., hyperparameter configurations) to balance exploration and exploitation. "Traditional approaches include Bayesian optimization and bandit strategies that adaptively select hyperparameter configurations across trial runs"
- Bayesian optimization: A sample-efficient strategy for optimizing expensive functions, often used for hyperparameter tuning. "Traditional approaches include Bayesian optimization and bandit strategies that adaptively select hyperparameter configurations across trial runs"
- Branched training logs: Recorded histories of different intervention paths or experiment branches during training. "Additionally, the server maintains state information such as training checkpoints, command history, and branched training logs."
- Branching training trajectories: Creating diverging experiment paths from checkpoints to compare different training decisions. "our framework also supports branching training trajectories."
- Callback functions: Hooks that allow code to execute at specific points in the training loop for dynamic control. "via callback functions invoked after each gradient step."
- Checkpoint management: Operations to save, load, and revert model states during training. "action type (e.g., adjusting learning rates, checkpoint management)"
- Command queues: Asynchronous queues that hold user-issued intervention commands by type. "enqueues it into command queues categorized by command type for asynchronous processing."
- Control Server: The central service that mediates communication between users/agents and the training process. "At the core of our implementation is a control server acting as an intermediary between human experts (or AI agents) and the ongoing training process."
- Dataloaders: Components that handle batching and feeding data to the model during training. "updates to optimizer parameters, model components, dataloaders, or gradients via callback functions"
- Dead neurons: Units in a neural network that produce little to no activation, often indicating training issues. "detect “dead” neurons"
- Diffusion model: A generative model that iteratively denoises data to produce samples (e.g., images). "uses a diffusion model to simulate a real operating system"
- Event queues: Channels through which training metrics and status updates are reported back to clients. "reports metrics such as loss values, gradient norms, and training status updates back to the server via event queues."
- FastAPI: A Python framework for building APIs, used to serve intervention endpoints. "The control protocol exposes its API endpoints through FastAPI."
- Finetuning: Additional training of a pretrained model on a specific task or dataset to improve performance. "for finetuning GPT-2 on Wikitext-2."
- Frontend Dashboard: The user interface for visualizing metrics and issuing real-time interventions. "Users interact through a React-based Frontend Dashboard, which visualizes training metrics and sends control commands via REST API."
- Gradient clipping thresholds: Limits set on gradient magnitudes to prevent instability during optimization. "allowing users to dynamically set gradient clipping thresholds based on observed gradient norms"
- Gradient norms: Measures of gradient magnitude used to monitor and control training stability. "reports metrics such as loss values, gradient norms, and training status updates"
- Gradient overflow: A numerical instability where gradients exceed representable range, often in mixed precision. "“Gradient overflow detected”"
- Gradient step: A single update iteration in the optimization process. "invoked after each gradient step."
- GPT-2: A transformer-based LLM architecture commonly used for language modeling tasks. "finetuning GPT-2 on Wikitext-2."
- Hidden states: Intermediate activations within neural network layers used to analyze model behavior. "standard deviation of hidden states across training examples"
- Hugging Face Transformers: A widely used library providing model architectures and training utilities. "built on Hugging Face Transformers' widely adopted Trainer class"
- InteractiveCallback: A specific callback that applies runtime changes to training parameters and evaluations. "InteractiveCallback: Handles runtime adjustments to training parameters, including optimizer hyperparameters, gradient clipping thresholds, and triggering on-demand model evaluations."
- Interactive Training: A training paradigm enabling real-time, feedback-driven interventions during model optimization. "Interactive Training enables users (human experts or automated AI agents) to dynamically adjust optimizer parameters"
- IterableDataset: A PyTorch dataset type that yields samples via an iterator, suited for streaming data. "wrap PyTorch's Dataset and IterableDataset classes"
- JSON: A structured message format used to encode intervention commands. "Each command is represented as a JSON message"
- Learning rate annealing: Gradually decreasing the learning rate during training to aid convergence. "linearly annealing it to zero over the entire training duration."
- Learning rate schedule: A predefined or adaptive plan for changing the learning rate over training. "fixed learning rate schedule"
- Learning rate scheduler: A mechanism that adjusts the learning rate according to a policy during training. "disabling the learning rate scheduler."
- LLM-based AI agent: An automated controller powered by a LLM that issues training interventions. "a general-purpose LLM-based AI agent"
- Model-level interventions: Actions that modify the model state or parameters during training. "Users can perform model-level interventions, such as reverting to previous checkpoints upon encountering unstable loss dynamics"
- NeuralOS: A system that uses a diffusion model to emulate OS screen transitions given inputs. "We apply our framework to NeuralOS"
- Optimizer hyperparameters: Configuration values controlling the optimizer’s behavior (e.g., learning rate, momentum). "dynamically adjust optimizer hyperparameters"
- Population-Based Training (PBT): A technique that evolves a population of models and hyperparameters during training. "Population-Based Training (PBT) learns an automatic dynamic schedule of hyperparameters."
- Reinforcement learning: A learning paradigm where agents optimize actions based on rewards, here used to discover schedules. "researchers have even applied reinforcement learning to discover optimized scheduling policies automatically"
- REST API: An HTTP-based interface for sending control commands to the training system. "sends control commands via REST API"
- RunPauseCallback: A callback that enables pausing and resuming the training loop. "RunPauseCallback: Pauses/resumes training."
- Vanishing gradients: A training pathology where gradients become too small to update deep layers effectively. "vanishing gradients in certain network components"
- WebSockets: A protocol enabling real-time, bidirectional communication between server and client. "broadcasts them to the Frontend Dashboard through WebSockets."
- Wikitext-2: A text dataset commonly used for language modeling experiments. "for finetuning GPT-2 on Wikitext-2."
Collections
Sign up for free to add this paper to one or more collections.