- The paper introduces Poolformer, a hybrid recurrent network with hierarchical pooling designed to reduce sequence lengths while effectively capturing both short- and long-range dependencies.
- It utilizes recursive SkipBlocks that combine residual blocks, down/up pooling, and gating mechanisms to ensure stable gradient flow and improved training efficiency.
- Empirical results on audio tasks show that Poolformer achieves faster training, lower negative log-likelihood, and enhanced perceptual metrics compared to transformer and state-space models.
Motivation and Background
The Poolformer architecture addresses the computational and modeling challenges inherent in long-sequence modeling, particularly in domains such as raw audio, where sequence lengths can reach hundreds of thousands of tokens. While transformer-based models with self-attention have achieved state-of-the-art results across modalities, their O(S2) complexity with respect to sequence length S renders them impractical for very long sequences. Recurrent neural networks (RNNs) and state-space models (SSMs) offer O(S) complexity but are limited by sequential computation and the need to compress context into a fixed-size state, which can hinder the modeling of long-range dependencies.
Poolformer proposes a hybrid approach: replacing self-attention with recurrent layers and introducing hierarchical pooling to reduce sequence length, thereby enabling efficient modeling of both short- and long-range dependencies. The architecture is defined recursively via SkipBlocks, which combine residual blocks, pooling operations, and skip connections to facilitate gradient flow and information exchange across different temporal resolutions.
Signal Processing and Preprocessing
A critical aspect of Poolformer's application to audio is the use of μ-law encoding for quantization, mapping 16-bit audio to 8-bit representations. This non-linear companding allocates more quantization levels to low amplitudes, aligning with human auditory sensitivity and reducing the effective vocabulary size for the model.
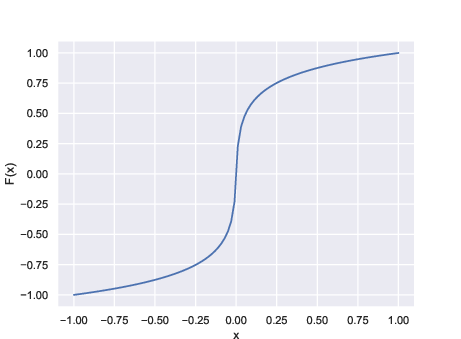
Figure 1: mu-law encoding function. The μ-law function expands small amplitudes and compresses large ones, optimizing quantization for perceptual relevance.
For input representation, sinusoidal embeddings are employed, mapping discrete quantized values to high-dimensional vectors. Empirical results demonstrate that sinusoidal embeddings outperform both linear scaling and learned embeddings, yielding superior model performance and generalization.
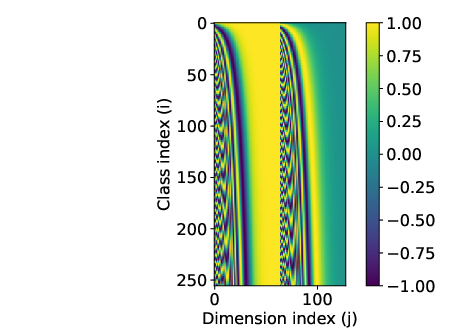
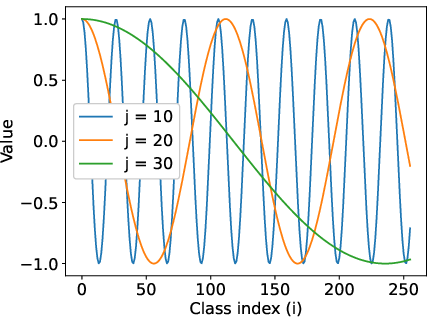
Figure 2: Sinusoidal embeddings. Each embedding dimension corresponds to a different frequency, providing a rich, structured input representation.
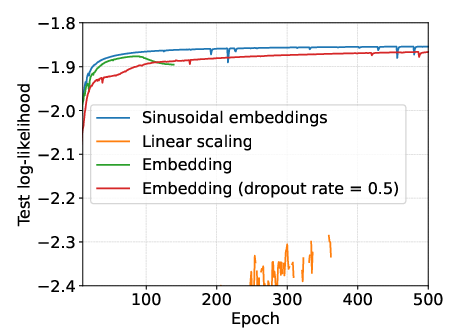
Figure 3: Pre-processing comparison (SC09). Sinusoidal embeddings yield the best performance, while linear scaling and learned embeddings are suboptimal.
Architecture: SkipBlocks, Pooling, and Residual Design
SkipBlocks and Hierarchical Pooling
The core architectural unit, the SkipBlock, is defined recursively. Each SkipBlock contains:
- Pre-pooling residual blocks (MLP and temporal mixing)
- Down-pooling layer (strided convolution)
- Nested SkipBlock (operating at reduced sequence length)
- Up-pooling layer (strided transposed convolution)
- Post-pooling residual blocks
Skip connections are introduced around pooling layers (short skip-connections), which empirical ablations show to be superior to long skip-connections for gradient flow and stability.
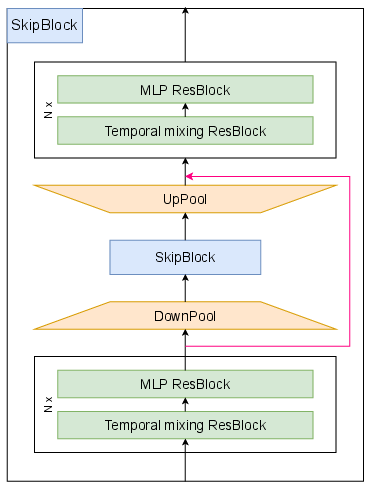
Figure 4: (short skip-connections). Skip connections around pooling layers facilitate effective gradient propagation.
Pooling is implemented via grouped 1D convolutions for down-sampling and grouped transposed convolutions for up-sampling. The group count G controls the expressivity and parameterization of the pooling layers; lower G increases expressivity but can destabilize training.
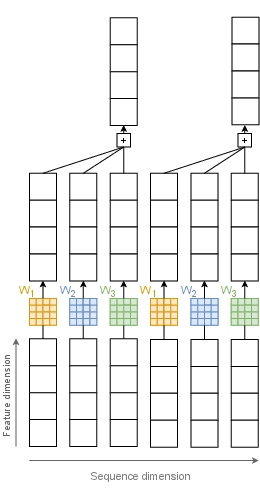
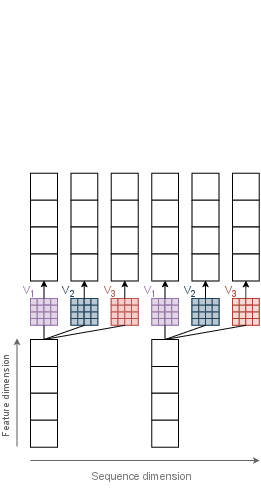
Figure 5: Down-pooling. Pooling reduces sequence length, enabling efficient hierarchical processing.
Residual Blocks and Gating
Residual blocks (ResBlocks) are used for both MLP and temporal mixing layers. Gated variants, inspired by recent advances in recurrent architectures, are found to significantly improve training stability, albeit with a modest increase in parameter count.
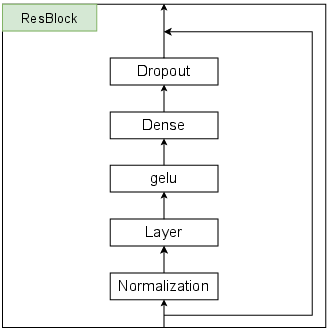
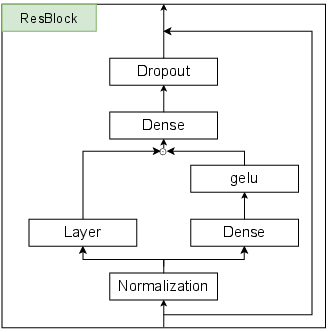
Figure 6: ResBlock without gating. Standard residual block structure for stable deep learning.
Ablations confirm that LayerNorm is essential for stable training, outperforming RMSNorm in this context, contrary to some prior findings in large-scale RNNs.
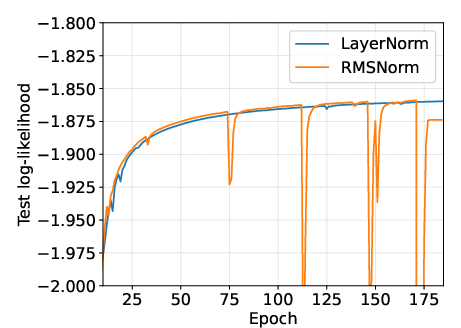
Figure 7: Comparison of LayerNorm and RMSNorm (SC09). LayerNorm provides superior training stability.
Initialization of layers feeding into the residual stream is critical; small initialization scales (scale≪1) are necessary to avoid instability and overfitting.
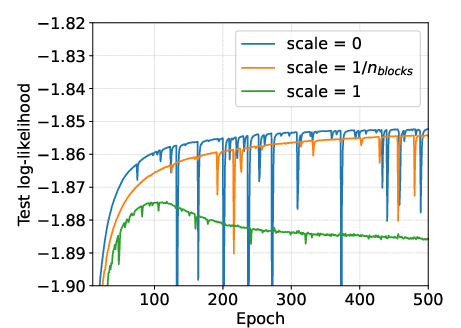
Figure 8: Effect of initialization scaling (SC09). Small initialization scales promote stability, while large scales lead to overfitting.
Gating in ResBlocks is also crucial for stability, as demonstrated by ablation studies.
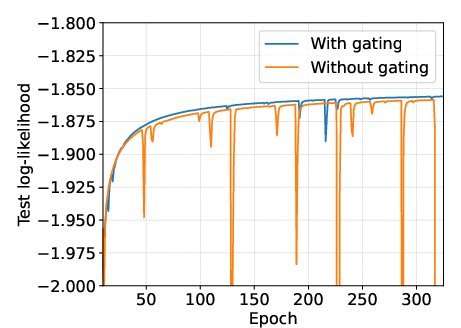
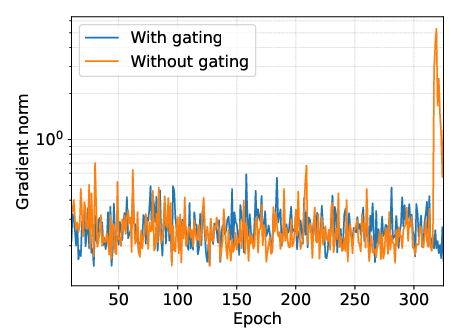
Figure 9: Effect of gating (SC09). Gating substantially improves training stability.
Temporal Mixing: RG-LRU and Complex State Dynamics
The temporal mixing layer in Poolformer is the RG-LRU (Real-Gated Linear Recurrent Unit), which supports both real and complex parameterizations. The complex variant, parameterized as a=σ(Λ)exp(iθ), allows for richer state dynamics and is found to slightly outperform the real variant in audio modeling tasks.
Depth-wise analysis of the magnitude ∣a∣ across layers reveals that deeper layers (operating at shorter sequence lengths due to pooling) maintain ∣a∣ values closer to 1, indicating a bias toward modeling long-range dependencies. Shallower layers, especially those near the output, exhibit smaller ∣a∣, focusing on short-term features.
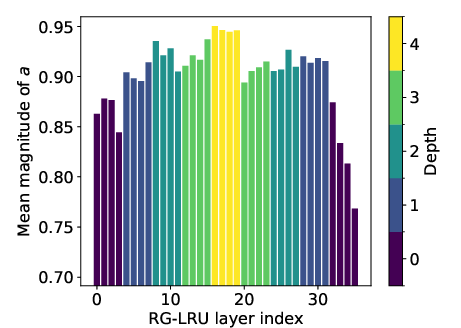
Figure 10: Mean magnitude of a across model depth (baseline model, SC09). Deeper layers capture long-range dependencies; shallower layers focus on short-term features.
Training, Evaluation, and Ablation Studies
Training Setup
Models are trained using JAX/Flax on TPU hardware, with AdamW optimization and exponential moving average (EMA) applied to weights for evaluation. EMA is shown to smooth and slightly improve test performance.
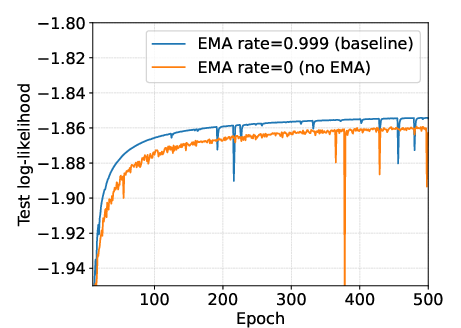
Figure 11: Effect of exponential moving average (EMA) (SC09). EMA leads to smoother and improved test curves.
Pooling is shown to be essential for both computational efficiency and generalization. Models with hierarchical pooling train faster, achieve better perceptual metrics (FID, IS), and are less prone to overfitting compared to models with limited or no pooling.
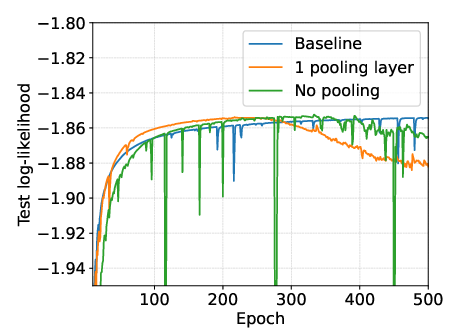
Figure 12: Effect of pooling on overfitting (SC09). Pooling reduces overfitting, as evidenced by improved test log-likelihood.
Ablations on the pooling group count G indicate that moderate grouping (e.g., G=4 or G=8) balances expressivity and stability, while G=1 (full expressivity) leads to instability.
Scaling and Model Capacity
Scaling studies demonstrate that increasing the recurrence (RG-LRU) dimension improves performance, as larger hidden states can better capture long-range dependencies. In contrast, increasing the model (channel) dimension leads to overfitting due to the rapid growth in parameter count.
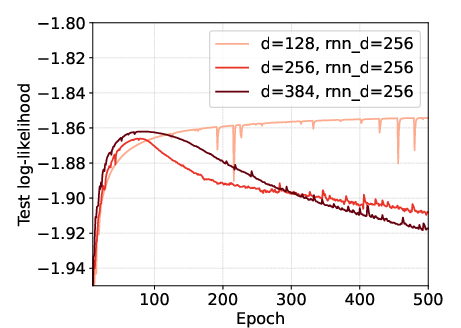
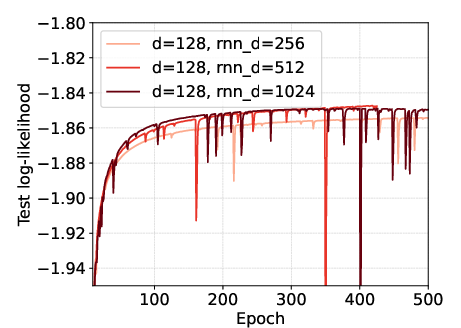
Figure 13: Effect of the model dimension. Larger model dimensions can lead to overfitting, while increasing recurrence dimension is beneficial.
Empirical Results and Comparison to State-of-the-Art
On the SC09 audio dataset, Poolformer achieves a test negative log-likelihood (NLL) of 1.854, outperforming SaShiMi and matching or exceeding Mamba, with notably superior FID and IS scores. On the Beethoven dataset, Poolformer achieves a test NLL of 0.915, surpassing SaShiMi despite fewer training steps. On YouTubeMix, Poolformer is competitive, though the comparison is complicated by differences in training regime and sequence length.
Key empirical findings:
- Pooling accelerates training (up to 2x speedup) and improves perceptual metrics.
- Poolformer achieves lower FID and higher IS than both SaShiMi and Mamba on SC09.
- Ablations confirm the necessity of normalization, gating, careful initialization, and hierarchical pooling for stable and performant training.
Theoretical and Practical Implications
The recursive, pooling-based design of Poolformer provides a scalable alternative to self-attention for long-sequence modeling. By leveraging hierarchical pooling, the model efficiently reduces sequence length, enabling deep layers to focus on global dependencies while shallow layers capture local structure. The use of RG-LRU with complex state dynamics further enhances the model's capacity to retain information over long contexts.
Practically, Poolformer is well-suited for domains with extremely long sequences, such as raw audio, high-resolution video, and dense patch-based image representations. Its design is compatible with both autoregressive inference and parallelized training (via associative scan), making it attractive for large-scale deployment.
Limitations and Future Directions
The current evaluation is limited to raw audio datasets. While the architecture is modality-agnostic, further work is needed to validate its effectiveness on text, vision, and multi-modal tasks. The model's reliance on careful initialization and normalization may require adaptation for other domains. Additionally, while overfitting was not a primary concern in these experiments, practical applications may benefit from data augmentation and regularization strategies.
A promising avenue is the application of Poolformer to multi-modal learning, where it could process dense, patch-level representations of images or videos in conjunction with language, potentially enabling more fine-grained and contextually aware models.
Conclusion
Poolformer introduces a principled, recurrent-pooling architecture for long-sequence modeling, combining the efficiency of RNNs with the hierarchical abstraction of pooling. Empirical results demonstrate its superiority over prior state-of-the-art models in audio modeling, particularly in terms of perceptual quality and training efficiency. The architecture's modularity and scalability position it as a strong candidate for future research in long-context and multi-modal AI systems.