Do AI Models Perform Human-like Abstract Reasoning Across Modalities?
Abstract: OpenAI's o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark, but does that mean state-of-the-art models recognize and reason with the abstractions that the task creators intended? We investigate models' abstraction abilities on ConceptARC. We evaluate models under settings that vary the input modality (textual vs. visual), whether the model is permitted to use external Python tools, and, for reasoning models, the amount of reasoning effort. In addition to measuring output accuracy, we perform fine-grained evaluation of the natural-language rules that models generate to explain their solutions. This dual evaluation lets us assess whether models solve tasks using the abstractions ConceptARC was designed to elicit, rather than relying on surface-level patterns. Our results show that, while some models using text-based representations match human output accuracy, the best models' rules are often based on surface-level ``shortcuts'' and capture intended abstractions far less often than humans. Thus their capabilities for general abstract reasoning may be overestimated by evaluations based on accuracy alone. In the visual modality, AI models' output accuracy drops sharply, yet our rule-level analysis reveals that models might be underestimated, as they still exhibit a substantial share of rules that capture intended abstractions, but are often unable to correctly apply these rules. In short, our results show that models still lag humans in abstract reasoning, and that using accuracy alone to evaluate abstract reasoning on ARC-like tasks may overestimate abstract-reasoning capabilities in textual modalities and underestimate it in visual modalities. We believe that our evaluation framework offers a more faithful picture of multimodal models' abstract reasoning abilities and a more principled way to track progress toward human-like, abstraction-centered intelligence.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper asks a simple but important question: When AI models solve tricky pattern puzzles, are they truly understanding the big ideas (like “top vs. bottom,” “inside vs. outside”), or are they just spotting easy shortcuts in the examples?
To find out, the authors test several advanced AI models on a special set of puzzles called ConceptARC. These puzzles are designed to check whether a solver can discover and use simple, human-like abstract rules—much like how people reason about shapes and positions, not just colors and pixels.
The goals and questions in plain terms
The researchers wanted to answer three easy-to-understand questions:
- Do today’s AI models solve these puzzles as well as humans?
- When AIs give a correct answer, is it for the right reason (the intended big idea) or because they noticed a shallow pattern (a shortcut)?
- What changes how well AIs reason—using text vs. images, giving them more “thinking time,” or letting them use tools like Python code?
How they tested the models (and what the jargon means)
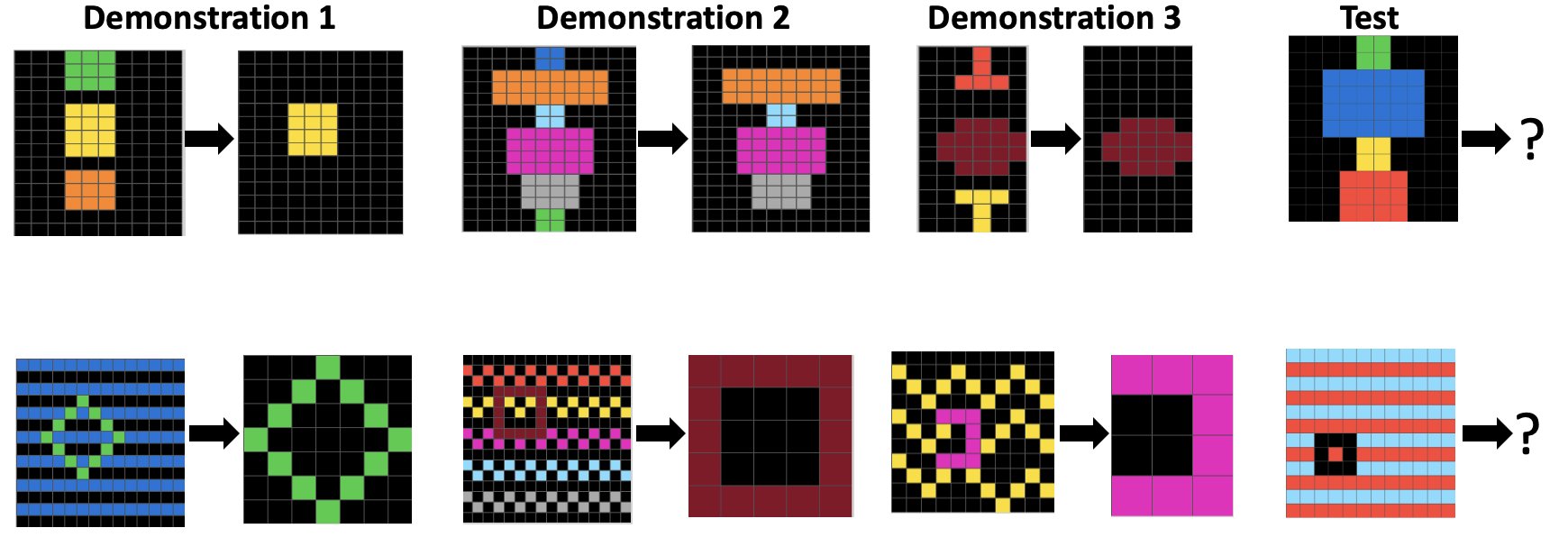
Think of each puzzle as a before-and-after pair of small colored grids plus a new test grid. The job is to figure out the rule (e.g., “remove the top and bottom shapes”) and apply it to the test grid to produce the correct output.
Here’s what they did:
- The puzzles (ConceptARC)
- 480 small grid puzzles grouped by 16 basic ideas, like “top vs. bottom,” “inside vs. outside,” or “same vs. different.”
- Each puzzle has a few examples showing a transformation, then a test to apply the same idea.
- These are designed to be easy for humans but still revealing about abstract thinking.
- Two ways of giving puzzles to AI (modalities)
- Text mode: The grid is given as numbers (each number represents a color). This is like handing the computer exact data.
- Visual mode: The grid is shown as an image. This is like showing the computer a picture to interpret.
- Tools and effort
- Tools: Some models were allowed to write and run small bits of Python code (helpful for image processing and checking).
- Reasoning effort: Some settings gave models more “thinking budget” (more tokens/time) to reason step-by-step.
- What the models had to produce
- An output grid (their final answer).
- A short rule in plain language explaining the transformation they used.
- How answers were judged
- Output accuracy: Does the model’s final grid exactly match the correct one?
- Rule quality: Humans read the model’s rule and labeled it as:
- Correct-intended: It captures the real, intended big idea.
- Correct-unintended: It works on the given examples but for the wrong reason (a shortcut).
- Incorrect: It doesn’t actually explain the examples.
- Human comparison
- They also used human results from a previous study where people solved the same puzzles and wrote rules. This gives a fair baseline.
What they found and why it matters
Here are the main takeaways, explained simply:
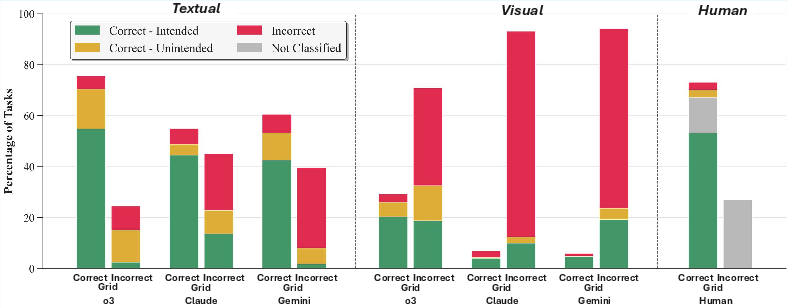
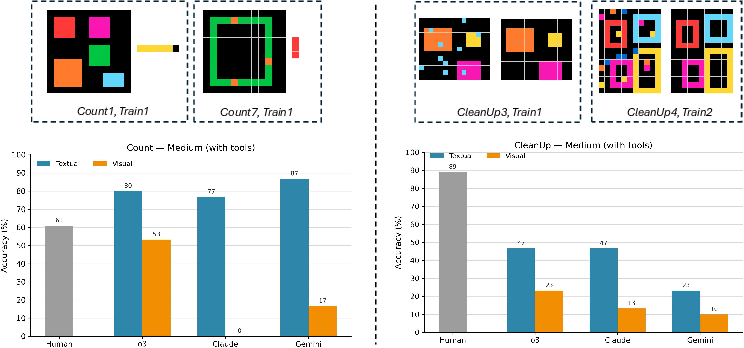
- Text mode makes AI look strong—but not always for the right reasons.
- In text mode, the best models (like OpenAI’s o3) matched or beat human accuracy on these puzzles.
- But when researchers read the models’ rules, they found that a sizable chunk of correct answers came from shortcuts—like relying on specific color numbers or pixel-level coincidences—rather than the intended abstract idea (e.g., “remove the top object”).
- Visual mode shows the struggle.
- In visual mode (using images), AI accuracy dropped a lot—far below humans.
- Interestingly, models often wrote good, intended rules in visual mode but still failed to correctly apply them to the test grid. In other words, they could describe the idea but struggled to execute it perfectly.
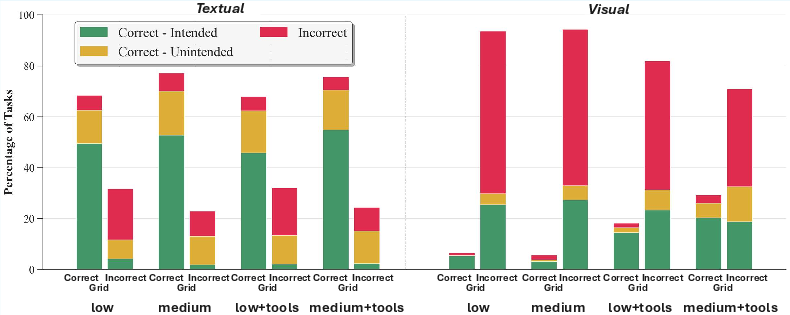
- Tools help visuals; extra “thinking” helps text.
- Letting models use Python tools boosted visual performance (they used code to better read the image size, find shapes, etc.).
- Giving models more “reasoning effort” helped more in text mode than in visual mode.
- Humans tend to use the right ideas.
- Humans also make mistakes, but when they’re right, they usually use the intended abstract concept rather than a shortcut.
- Compared to humans, models were more likely to rely on unintended shortcuts in text mode.
Why this matters: If we only look at accuracy, we can get the wrong impression. In text mode, accuracy can overestimate a model’s real understanding (because of shortcuts). In visual mode, accuracy can underestimate it (because models know the right rule but fail to apply it perfectly). This shows we need to check both answers and explanations to judge genuine abstract reasoning.
What this means going forward
- Don’t trust accuracy alone. To judge whether AI really “gets” abstract ideas, we should also evaluate the rules it claims to use.
- Visual reasoning needs work. Models can often state the right rule but fail to apply it reliably. Improving the “apply the rule” step—especially for images—could make a big difference.
- Better tests, better models. The evaluation approach here (checking both grids and rules) gives a clearer, more honest picture of AI reasoning. It can guide future research toward models that reason more like people—using general concepts that transfer to new situations, not just surface tricks.
In short: Today’s top AIs can be very good puzzle-solvers in text form, but they often lean on shortcuts instead of true abstraction, and they still lag behind humans in visual reasoning. A smarter way to measure progress is to score both the answers and the reasoning, so we reward genuine understanding and move closer to human-like thinking.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and its experiments.
- Generalization beyond ConceptARC is untested: no evaluation on the original ARC/ARC-AGI test sets or other abstraction benchmarks (e.g., Bongard, Raven) to determine whether shortcut use and abstraction capture replicate across datasets.
- Sensitivity to textual encoding is not probed: models may exploit numeric color indices; no ablations randomizing color-to-index mappings across tasks or runs to suppress digit-level shortcuts.
- Faithfulness of natural-language rules is unverified: no rigorous method to test whether generated rules causally reflect the model’s internal decision process (e.g., via counterfactual outputs conditioned on the stated rule, program extraction, or mechanistic probing).
- No executable-rule pipeline: rules are collected in natural language only; there is no requirement that rules be compiled to code and executed to produce outputs, which would directly test rule faithfulness and application fidelity.
- No counterfactual disambiguation of rules: tasks are not augmented with adversarial/counterfactual test cases designed to separate intended abstractions from plausible shortcuts inferred from demonstrations.
- Visual perception vs reasoning not disentangled: failures in visual settings often stem from grid-size and parsing errors; models are not tested with structured visual inputs (e.g., provided grid dimensions, object masks, or object lists) to isolate reasoning from perception.
- Tool-use instrumentation is absent: which Python/CV tools are used, how often, and for what subproblems (parsing vs reasoning) is not analyzed; no controlled tool ablation to quantify each tool’s causal contribution.
- High-effort/test-time scaling is unexplored: o3 high-effort (and larger token budgets for Claude/Gemini) are not evaluated; scaling laws for rule-intendedness vs accuracy remain unknown.
- Prompt sensitivity is unstudied: only one textual prompt (and a minor visual variant) is used; no systematic prompt ablations (e.g., object-centric scaffolds, rule-first prompting, self-critique, scratchpad variants) to test robustness.
- Decoding strategy effects are unknown: pass@1 only; no pass@k, self-consistency, or majority-vote sampling to measure whether multiple tries increase correct-intended rule rates vs shortcut reliance.
- Human baseline incompleteness: human rules were missing for incorrect outputs and some correct outputs; no matched textual-modality human baseline; time/effort budget and instruction alignment with models are not controlled.
- Inter-annotator reliability is not reported: manual rule classification lacks inter-rater agreement statistics and replication protocol; no scalable semi-automated rubric for consistent annotation.
- Automated rule evaluation remains an open problem: LLM-based judging was attempted but found insufficient; no proposed benchmark, rubric, or model for reliable automatic classification of rule intendedness.
- No per-concept error taxonomy for models: the paper does not systematically analyze which ConceptARC groups (e.g., object extraction, top/bottom, 3D stacking) most drive shortcut use or application failures.
- Application errors under visual input are under-characterized: models often form correct-intended rules but fail to apply them; no targeted interventions (e.g., execution-check loops, verifier-corrector modules) are evaluated.
- Cross-modality transfer is untested: whether a rule inferred in textual format transfers to the same task in visual form (and vice versa) is not assessed; no training-free or few-shot adaptation across modalities.
- Data contamination is unaddressed: potential pretraining exposure of proprietary models to ConceptARC or ARC-like tasks is not examined, leaving uncertainty about the originality of learned abstractions.
- Cost-performance tradeoffs are not measured: compute/time/token cost and tool-invocation costs vs accuracy and rule-intendedness are not quantified across models and settings.
- Limited model coverage: rule-level analysis is restricted to o3, Claude, and Gemini in medium-effort + tools; o4-mini and non-reasoning/open-weight models are not evaluated at the rule level.
- No compositionality tests: tasks combining multiple concepts or requiring multi-step abstraction are not specifically evaluated to probe compositional reasoning limits.
- No control for color/shape priors: beyond acknowledging objectness priors in ARC/ConceptARC, there is no study manipulating priors (e.g., randomized palettes, variable object densities) to measure robustness.
- Lack of formal abstraction-alignment metric: the study highlights that accuracy alone can over/underestimate reasoning, but does not propose a standardized metric that combines accuracy, rule intendedness, and robustness.
- Incomplete error analysis: aside from grid-size/format issues, there is no detailed failure taxonomy distinguishing perception, object segmentation, rule induction, rule selection, and rule execution errors.
- Unclear reproducibility of annotations: availability of the rule annotations and labeling guidelines is not stated, limiting external validation and follow-on work.
- No causal link between tool use and rule intendedness: the study shows tool use helps visually, but does not test whether tools improve intended-rule discovery vs just parsing/execution.
- Unresolved discrepancy in o3 variants: reported differences between o3-preview and released o3 on ARC-AGI (noted in related work) remain unexplained in this context; reproducibility across model versions is untested.
- No investigation of training-time interventions: how fine-tuning, instruction tuning, or curriculum learning on concept-labeled data affects intended abstraction capture is unexplored.
- No confidence calibration or abstention analysis: the relationship between rule quality, output correctness, and confidence/uncertainty is not measured; models are not evaluated on when they should abstain.
- No study of instance-level robustness: randomized re-renderings (e.g., resizing, jitter, noise) of the same concept/task are not used to evaluate rule stability and shortcut fragility.
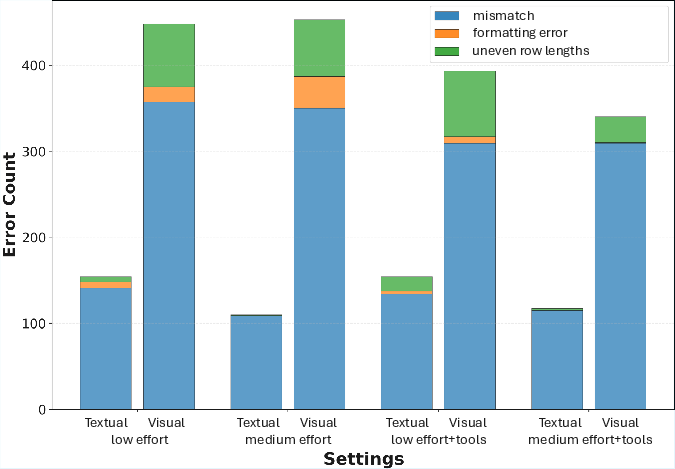
- Interface constraints for non-reasoning models are unclear: frequent invalid/empty outputs in visual settings are observed, but not disentangled from API/formatting issues vs underlying model limitations.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s evaluation framework, empirical findings, and recommended workflows. Each item notes relevant sectors and any key assumptions or dependencies.
- Abstraction-aware evaluation pipelines for AI model QA and selection (software, AI vendors, enterprise ML teams)
- Action: Integrate dual evaluation (output-grid accuracy + rule-level assessment) into model testing to detect shortcut use and abstraction failures.
- Tools/products: “Abstraction Alignment Score” dashboards; JSON-based rule + grid capture; reviewer interfaces for rule classification.
- Dependencies: Human annotators or rule judges; access to prompts like those in the paper; ConceptARC-style tasks; standardized reporting beyond accuracy.
- Visual reasoning agents with tool-augmented inference (robotics, manufacturing, process automation, document/intake workflows)
- Action: Enable Python tools (e.g., OpenCV/PIL) during inference to parse images, recover grid structure, and apply transformations more reliably.
- Tools/products: Secure code-execution sandboxes; CV libraries integrated into agent tool-use; multimodal agent orchestration.
- Dependencies: Tool-use permissions; robust sandboxing and logging; latency/cost budgets; image-to-structure conversion reliability.
- Prompt and data-capture practices to reduce superficial shortcuts (education platforms, software testing, synthetic data providers)
- Action: Randomize or obfuscate numeric encodings (e.g., color indices) and adopt object-centric representations to discourage reliance on spurious patterns.
- Tools/products: Data loaders with randomized encodings; schema enforcing object-level features; prompt templates that emphasize objects/relations.
- Dependencies: Dataset curation capacity; compatibility with existing model inputs; monitoring for unintended new shortcuts.
- Structured-explanation gating for safety-critical decisions (healthcare diagnostics, finance compliance, public-sector services)
- Action: Require rule-level rationales that align with intended abstractions before accepting model outputs; gate deployment based on “correct-intended” rule rates.
- Tools/products: Decision pipelines with explanation checks; human-in-the-loop verification; escalation protocols when rationales are incorrect/unintended.
- Dependencies: Trained reviewers; policy buy-in; clear definitions of “intended abstractions” per domain; trace capture from models.
- Model procurement and governance policies that go beyond accuracy (policy, enterprise risk, standards bodies)
- Action: Update internal/external evaluation criteria to include rule-level abstraction capture and modality-specific performance (text vs. vision).
- Tools/products: Extended model cards; third-party audit requirements; procurement RFPs specifying abstraction-centered metrics.
- Dependencies: Organizational adoption; evaluators; standardized metrics and test suites.
- Modality-aware deployment decisions (software, logistics, document understanding)
- Action: Prefer structured/textual representations for reasoning when visual reliability is low; pre-convert images to structured formats before reasoning.
- Tools/products: OCR/segmentation pipelines; grid/scene parsers; hybrid workflows that separate perception from reasoning.
- Dependencies: Quality of perception stack; domain fit for structured conversion; integration overhead.
- Education and training with ConceptARC-style tasks (education, workforce upskilling)
- Action: Use tasks that isolate abstract concepts to teach generalization and rule discovery in human learners and in AI tutoring systems.
- Tools/products: Curriculum modules; tutoring agents that require rule articulation; formative assessments emphasizing abstraction.
- Dependencies: Access to task banks; educator training; alignment with learning standards.
- Benchmark-based internal audits for research labs and product teams (academia, industry R&D)
- Action: Adopt ConceptARC or similar concept-isolating benchmarks to audit models for abstraction capture and tool-use effectiveness.
- Tools/products: Internal evaluation suites; reproducible prompts; performance tracking on “correct-intended” vs. “correct-unintended.”
- Dependencies: Compute access; model API permissions; annotation time.
Long-Term Applications
The following applications require further research, scaling, or development to reach robust, standardized deployment.
- Abstraction-centered certification standards for AI systems (policy, standards bodies, regulated industries)
- Vision: Create certifications that require demonstration of intended abstraction capture across modalities, not just high accuracy.
- Tools/products: Standardized “Abstraction Capture Score,” audit protocols, and sector-specific test suites.
- Dependencies: Cross-stakeholder consensus; benchmark generalization to domain tasks; accredited auditors.
- Automated rule evaluation (“RuleJudge”) to reduce human labor (software, evaluation tooling, research)
- Vision: Train specialized models to judge rule faithfulness and intendedness with high reliability, replacing or augmenting human raters.
- Tools/products: Rule-evaluation APIs; annotated corpora; calibration frameworks for judge agreement and bias control.
- Dependencies: Large, high-quality labeled datasets of rules; robust judge training; continual validation against human consensus.
- Object-centric and neuro-symbolic architectures that generalize abstractions (robotics, autonomous systems, medical imaging)
- Vision: Architectures that represent and manipulate objects and relations directly, improving visual abstraction capture and rule application.
- Tools/products: Object-focused latent spaces; symbolic reasoning layers; hybrid perception-reasoning pipelines.
- Dependencies: Advances in representation learning; reliable object/relationship extraction; integration with tool-use.
- Training curricula that explicitly reward abstraction capture over shortcuts (ML platform providers, academia)
- Vision: Curriculum learning and reinforcement signals that penalize correct-unintended solutions and reward intended abstraction generalization.
- Tools/products: Training objectives with abstraction-alignment rewards; synthetic data with controlled concept variations; hard-negative generation.
- Dependencies: Scalable data generation; measurable abstraction targets; alignment with model capabilities.
- Robust visual agents that can both infer and correctly apply rules (engineering design, CAD, quality inspection)
- Vision: Systems that translate recognized rules into precise transformations, closing the gap highlighted between rule recognition and application.
- Tools/products: Planning-and-execution modules; geometric reasoning libraries; constraint solvers integrated with perception.
- Dependencies: Reliable perception-to-action mapping; compositional planning; latency/cost optimization.
- Domain-specific abstraction stress tests (healthcare, finance, code intelligence, legal)
- Vision: ARC-like—yet domain-tailored—test suites that isolate core abstractions (e.g., temporal alignment in EMRs, invariants in code refactoring).
- Tools/products: Sector-specific benchmarks; compliance-grade evaluation kits; longitudinal tracking of abstraction mastery.
- Dependencies: Domain expert input; realistic task generation; secure data handling.
- Human–AI collaboration protocols for explanation-first workflows (legal, auditing, scientific analysis)
- Vision: Co-generation of rules before outputs, with human verification and corrections feeding back into the agent’s application stage.
- Tools/products: Collaborative IDEs for rule authoring; explanation validation UIs; feedback learning hooks.
- Dependencies: Usability research; governance frameworks; integration with existing review processes.
- Dataset design guidelines to minimize shortcut exploitation (data providers, benchmark designers)
- Vision: Systematic methods to detect and reduce unintended correlations (e.g., numeric encoding effects), ensuring generalization pressure.
- Tools/products: Generators that randomize spurious cues; diagnostic probes; continuous benchmark hardening.
- Dependencies: Tooling to detect shortcuts; agreement on intended abstraction definitions; update cycles.
- Open standards for abstraction-aware model reporting (policy, transparency initiatives)
- Vision: Model cards that report modality-specific performance, correct-intended vs. correct-unintended ratios, tool-use reliance, and reasoning budgets.
- Tools/products: Reporting schemas; audit-ready documentation templates; public leaderboards with abstraction metrics.
- Dependencies: Community adoption; platform support; consistent measurement methodologies.
- Cross-disciplinary research linking human abstraction to AI training (cognitive science, education)
- Vision: Use human studies (like ConceptARC’s) to inform AI curricula and evaluation, aligning machine abstractions with human conceptual priors.
- Tools/products: Joint datasets; experimental protocols; theory-informed model objectives.
- Dependencies: Sustained collaboration; funding; standardized interpretations of “intended abstractions.”
Glossary
- Abstraction and Reasoning Corpus (ARC): A benchmark of grid-based puzzles designed to test abstract reasoning via few-shot rule discovery and application. "Among the most prominent such benchmarks is the Abstraction and Reasoning Corpus (ARC)"
- analogical reasoning: The process of solving problems by mapping relationships from examples to new instances. "ARC consists of a set of idealized problems that require few-shot rule-induction and analogical reasoning."
- ARC-AGI: A competition and benchmark evaluating general intelligence on ARC-style tasks with strict rules and private tests. "OpenAI's o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark"
- bounding box: The smallest rectangle that contains a specified object or region in a grid or image. "Crop the minimal bounding box around the unique 1-cell-thick closed loop."
- computer vision libraries: Software tools for analyzing and processing images, used by models to extract visual features. "the models use computer vision libraries"
- ConceptARC: A curated ARC-style benchmark organized by specific abstract concepts to assess conceptual reasoning. "we investigate the abstraction abilities of AI models using the ConceptARC benchmark."
- context window: The portion of prior text or tokens available to the model during a single prompt or session. "with the context window reset (cleared) before a new task was given."
- core knowledge priors: Built-in assumptions (e.g., objectness) that guide models or benchmarks toward human-like reasoning. "ConceptARC, like ARC, is built on 'core knowledge' priors, including 'objectness'"
- data augmentation: Techniques for expanding training data via transformations to improve robustness and performance. "which employed a fine-tuned LLM and extensive data augmentation"
- density heuristic: An approximate method that relies on the concentration of elements (e.g., pixels) to infer a solution. "Claude Sonnet 4 uses a density heuristic to approximate the most overlapped figure"
- few-shot rule-induction: Inferring a general transformation rule from a small number of examples. "ARC consists of a set of idealized problems that require few-shot rule-induction and analogical reasoning."
- ground truth: The correct target outputs provided by the dataset for verifying solutions. "Evaluating output-grid accuracy in human and model responses is straightforward, since each task's ground-truth solution is given"
- high-effort setting: A configuration that allocates substantially more computation or reasoning tokens per task. "We did not test the high-effort setting."
- integer matrix: A grid representation where each cell is an integer encoding a color or value. "Each grid is represented as an integer matrix, with entries encoding colors indexed from 0 to 9."
- modality (textual vs.\ visual): The form of input presentation to the model, either as text (numbers) or images. "vary the input modality (textual vs.\ visual)"
- multimodal: Involving multiple input types (e.g., text and images) within the same model or task. "We evaluated four proprietary multimodal 'reasoning' models"
- objectness: The notion of treating sets of pixels as coherent objects rather than isolated features. "including 'objectness'"
- pass@1: The metric that counts a task as correct if the first attempt yields the exact ground-truth output. "give the pass@1 output-grid accuracies of the reasoning models"
- pass@2: The metric that considers two independent attempts and counts success if either is correct. "The ARC Prize competition reported pass@2 results"
- pass@3: The metric that evaluates success over three independent attempts. "Moskvichev et al.\ \citeyear{moskvichev2023conceptarc} reported pass@3 results"
- private test set: A hidden set of tasks reserved for evaluation to prevent training-time leakage. "a private test set of 100 tasks"
- reasoning effort: The amount of computational budget (e.g., tokens) dedicated to the model’s inference process. "and, for reasoning models, the amount of reasoning effort."
- reasoning token budget: The number of tokens allocated for the model’s intermediate reasoning or chain-of-thought. "OpenAI does not specify the token budget allocated to these settings."
- semi-private test set: A partially hidden evaluation set distinct from fully public and fully private sets. "a different 'semi-private' test set of 100 tasks"
- shortcuts: Superficial patterns that yield correct answers without capturing intended abstractions. "surface-level ``shortcuts''"
- spurious patterns: Unintended correlations in data that can mislead models into non-general solutions. "capable of discovering spurious patterns in data and using these patterns to arrive at correct answers"
- temperature: A sampling hyperparameter controlling output randomness during generation. "Temperature is set to 1 for all models."
- test-time scaling: Increasing computation or tokens at inference time to boost performance without retraining. "test-time scaling does not have the dramatic effects in visual modalities"
- tool access (Python tools): Allowing the model to write and execute code during inference to aid problem solving. "we evaluated two tool-access conditions: one in which Python tools were enabled and one in which they were not."
Collections
Sign up for free to add this paper to one or more collections.

