CLUE: Non-parametric Verification from Experience via Hidden-State Clustering
Abstract: Assessing the quality of LLM outputs presents a critical challenge. Previous methods either rely on text-level information (e.g., reward models, majority voting), which can overfit to superficial cues, or on calibrated confidence from token probabilities, which would fail on less-calibrated models. Yet both of these signals are, in fact, partial projections of a richer source of information: the model's internal hidden states. Early layers, closer to token embeddings, preserve semantic and lexical features that underpin text-based judgments, while later layers increasingly align with output logits, embedding confidence-related information. This paper explores hidden states directly as a unified foundation for verification. We show that the correctness of a solution is encoded as a geometrically separable signature within the trajectory of hidden activations. To validate this, we present Clue (Clustering and Experience-based Verification), a deliberately minimalist, non-parametric verifier. With no trainable parameters, CLUE only summarizes each reasoning trace by an hidden state delta and classifies correctness via nearest-centroid distance to success'' andfailure'' clusters formed from past experience. The simplicity of this method highlights the strength of the underlying signal. Empirically, CLUE consistently outperforms LLM-as-a-judge baselines and matches or exceeds modern confidence-based methods in reranking candidates, improving both top-1 and majority-vote accuracy across AIME 24/25 and GPQA. As a highlight, on AIME 24 with a 1.5B model, CLUE boosts accuracy from 56.7% (majority@64) to 70.0% (top-maj@16).
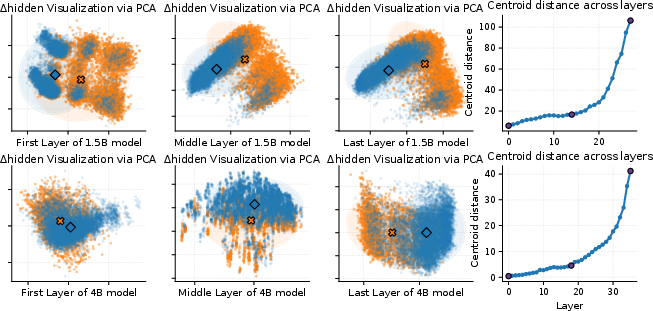
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clue: A simple way to check if an AI’s answer is correct by looking inside its “thoughts”
1) What is this paper about?
This paper is about a new way to verify whether a LLM—like the AIs that write answers or solve math problems—has given a correct answer. Instead of judging the final text or trusting how “confident” the AI sounds, the authors look at the AI’s internal activity while it’s thinking. They show that you can tell if an answer is right just by looking at how the AI’s hidden states (its internal “brain signals”) change during its reasoning.
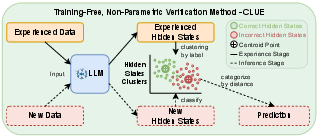
They introduce a very simple method called Clue that doesn’t need training. Clue groups past examples of “good thinking” and “bad thinking” and checks which group a new solution is closer to.
2) What questions did the researchers ask?
- Can we verify if an AI’s answer is correct by reading its internal hidden states, not just the final text?
- Is there a clear pattern in those hidden states that separates correct from incorrect solutions?
- Can a very simple, training-free method using those patterns beat or match fancier judges and confidence-based methods?
- Does this work across different models, tasks, and sizes (small to large AIs)?
3) How does their method work?
Think of an AI’s hidden states as a map of its “thoughts” while it reasons. The key idea: correct and incorrect solutions leave different “shapes” or “signatures” in this map.
Here’s the approach in everyday terms:
- The AI writes out its reasoning between special tags like > … .
- Clue records the AI’s hidden states at the start and at the end of that thinking.
- It computes the difference between these two moments. This “before vs. after” change is like measuring how far the AI’s thinking traveled—its reasoning “delta.”
- From past problems, Clue collects many correct and incorrect examples and finds the “center” of each group (called a centroid). You can think of this like finding the average location of all good paths and all bad paths on a map.
- For a new solution, Clue measures which center it’s closer to: the “success center” or the “failure center.” Closer to success = likely correct.
- If there are many candidate answers, Clue ranks them by how close they are to the success center and picks the best ones.
Important terms explained simply:
- Hidden states: the AI’s internal activity—like the signals in a brain while thinking.
- Activation delta (difference): the change in those signals from the start to the end of the thinking process.
- Centroid: the average “center point” of a group (like the middle of a cluster of dots).
- Non‑parametric: no training or weight-tuning—just compute and compare. It’s simple and fast.
Why using the “delta” helps: It focuses on what changed during reasoning and ignores distractions from the original prompt, like measuring the effect of thinking itself.
4) What did they find, and why does it matter?
Main findings:
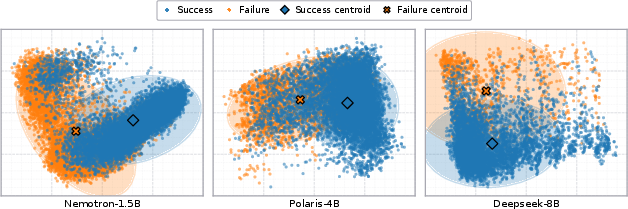
- Correct vs. incorrect solutions form separate clusters inside the AI’s hidden states. In other words, success and failure are geometrically separable—like two groups of footprints ending up in different areas.
- Clue, despite being extremely simple and training-free, often beats or matches strong baselines:
- It consistently outperforms LLM-as-a-judge (asking a big model like GPT-4o to judge answers).
- It matches or exceeds methods that rely on token confidence (which can be misleading when models are “confidently wrong,” especially smaller ones).
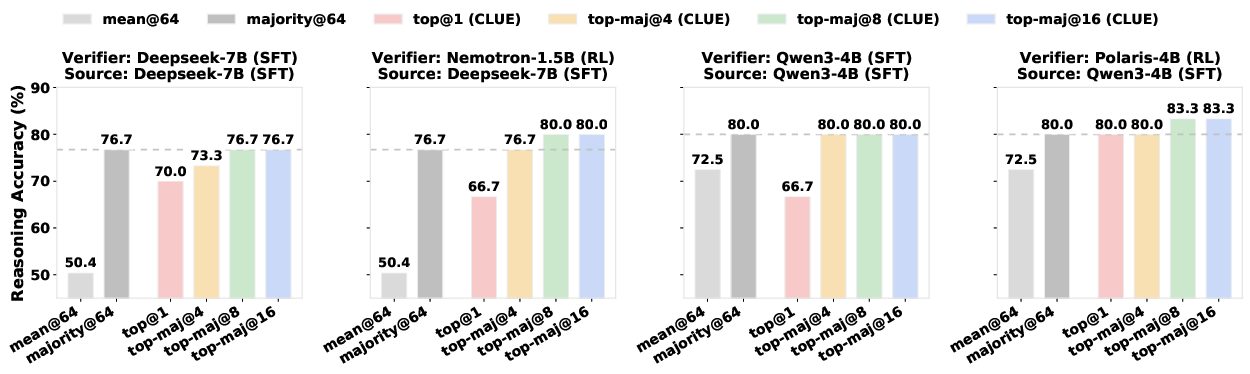
- It improves picking the right answer from many attempts. For example, on the AIME 2024 math benchmark with a small 1.5B model, using Clue to rerank boosted accuracy from 56.7% (majority vote over 64 samples) to 70.0% (majority over the top 16 chosen by Clue).
- It generalizes beyond math to mixed topics (like physics, law, finance, humanities), still outperforming an LLM judge.
- Deeper layers of the model hold stronger correctness signals. As the AI goes deeper in its computation, the separation between right and wrong gets clearer.
- Models trained with reinforcement learning (RL) tend to have cleaner, more separable “right vs. wrong” geometry than models trained only to imitate text (supervised fine‑tuning, SFT). RL-trained models are better at verifying both their own answers and even other models’ answers.
Why this matters:
- Better verification makes AI more trustworthy, especially when it generates many plausible but wrong answers.
- It helps smaller or less well-calibrated models, where confidence scores aren’t reliable.
- It suggests a new way to think about AI: don’t just read what it says—read how it thinks.
5) What’s the impact?
Clue shows that we can check AI correctness by reading its internal “thought trajectory,” not just the final text. Because it’s so simple (no training needed) and works across tasks and models, it could:
- Make AI systems more reliable in math, science, and other areas where correctness matters.
- Reduce the need for expensive judges or retraining.
- Guide future training: if RL makes “right vs. wrong” easier to separate inside the model, we can design training to shape that internal geometry on purpose.
Big picture: The paper hints at a shift from judging outputs to understanding and using the structure of reasoning inside the model. If correctness is “written” in the hidden states, then lightweight tools like Clue can make AI both smarter and safer by selecting better answers from what it already knows how to produce.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Access assumptions and practicality
- Quantify compute/memory overhead of extracting and storing all-layer hidden states for long traces (e.g., 16k–64k tokens) across 64 samples per problem; provide wall-clock profiling and cost trade-offs.
- Assess feasibility on closed-source APIs and production systems where hidden states are inaccessible; explore proxy features (e.g., selected layers, low-rank projections, probes) that approximate Clue’s signal with minimal instrumentation.
- Dependence on explicit reasoning delimiters
- Evaluate robustness when > … is absent, noisy, or ignored by the model; develop unsupervised or heuristic segmentation to approximate reasoning boundaries.
- Test sensitivity to the exact choice and formatting of delimiters and to prompt variants that change where “start” and “end” states are captured.
- Delta representation design
- Analyze how activation deltas scale with reasoning length and token count; compare length-normalized deltas (e.g., divide by number of reasoning tokens) vs raw deltas.
- Compare alternative trajectory summaries beyond a single start–end delta (e.g., cumulative sums, path integrals, temporal pooling, attention-head deltas, path signatures, or RNN over per-token deltas).
- Investigate whether intermediate checkpoints (multi-segment deltas) improve separability and early detection of failures.
- Distance metric and normalization choices
- Ablate Euclidean vs cosine, Mahalanobis, and whitened distances; examine per-layer variance normalization to mitigate high-variance layers dominating distances.
- Explore learned or data-driven layer weights (e.g., proportional to separability) vs uniform averaging; report gains and stability.
- Study robustness to hidden state scaling differences across architectures (e.g., RMSNorm vs LayerNorm) and to mixed-precision inference.
- Experience set construction and sample efficiency
- Quantify sample complexity: accuracy vs number of success/failure trajectories; minimal data needed per domain/model.
- Evaluate sensitivity to class imbalance in experience sets; test unbalanced centroids mirroring real-world distributions.
- Investigate online/continual updating of centroids under distribution shift; compare fixed vs adaptive centroids and drift detection.
- Label quality and verification sources
- Measure noise in the “rule-based verifier” for math and in GPT-4o-with-reference labels for general domains; run robustness experiments with controlled label noise and robust centroid estimators (e.g., trimmed means, medoids).
- Validate ground-truth labels on a human-audited subset to calibrate expected error due to labeling pipelines.
- Generalization and domain transfer
- Systematically test cross-domain transfer without rebuilding centroids (e.g., math-trained centroids applied to law/biology/finance and multilingual settings); identify when new centroids are necessary.
- Assess performance on conversational, multi-turn, program synthesis, and multimodal reasoning tasks; determine whether single, shared centroids suffice or domain-specific mixtures are required.
- Cross-model verification mechanics
- Clarify and evaluate how cross-model reranking is computed (re-forwarding text through the verifier model to obtain its hidden states vs sharing embeddings); test tokenization mismatches, positional encodings, and vocabulary differences.
- Benchmark transfer across more diverse architectures (e.g., Llama, Mistral, Mixtral) and larger scales (≥70B) to characterize portability limits.
- RL vs SFT causality
- Provide controlled studies isolating training paradigm effects (same data/compute with and without RL) to causally attribute separability gains to RL signals rather than confounds (data quality, scale, or decoding).
- Analyze which RL design choices (reward shaping, entropy regularization, verifier availability) most impact hidden-state separability.
- Robustness and security
- Test adversarial traces designed to “spoof” the success centroid (e.g., filler text, adversarial triggers, optimization in hidden space) and quantify vulnerability relative to LLM-as-a-judge attacks.
- Evaluate robustness to paraphrasing, stylistic perturbations, and prompt injections that alter hidden activations without changing correctness.
- Failure mode analysis
- Characterize cases where Clue prefers incorrect answers (e.g., arithmetic slips vs conceptual errors, long vs short traces); derive targeted remedies (e.g., error-type-specific centroids).
- Evaluate calibration of the distance scores (map distance to correctness probability); assess reliability diagrams and thresholding strategies.
- Integration with other signals
- Explore simple ensembles with logits/confidence scores, answer consistency, and lightweight text judges; report additive gains and scenarios where signals disagree.
- Investigate using Clue for early exit or dynamic compute allocation (e.g., halt/expand reasoning when delta signals saturate).
- Layer usage and selection
- Ablate which layers are most informative; test using only top-k discriminative layers or heads to reduce cost.
- Study whether later layers alone suffice or if early-layer semantic features boost OOD robustness.
- Ranking metrics and statistical validity
- Report statistical uncertainty (CIs, multiple random seeds) and significance tests for all tables; include correlation metrics for ranking quality (e.g., NDCG, AUC, Kendall’s tau).
- Compare against additional baselines (e.g., simple log-likelihood of final answer, tuned-lens probes, linear probes on hidden states) to contextualize gains.
- Scaling and efficiency
- Quantify end-to-end latency/throughput impact when used in best-of-N regimes; compare cost vs accuracy improvements across N.
- Test compressed representations (e.g., PCA/CCA, random projections, product quantization) to reduce hidden-state I/O while preserving performance.
- Applicability without CoT
- Evaluate settings where explicit CoT is disabled or redacted; study whether deltas computed over the answer-only segment still carry sufficient signal.
- Privacy and governance
- Assess whether centroid matrices can leak sensitive information about prompts or data (membership inference risk); consider differential privacy or aggregation safeguards.
- Theoretical underpinnings
- Formalize conditions under which correctness becomes linearly or geometrically separable in hidden space; relate to representation learning theory and dynamics across depth.
- Link observed separability to specific circuits/heads via causal interventions; test whether editing those components moves trajectories across class boundaries.
- Mixture and hierarchical centroids
- Evaluate mixture-of-centroids or task-conditioned centroids for heterogeneous datasets; compare to a single global centroid pair.
- Investigate per-problem adaptive centroids via few-shot bootstrap at test time.
- Reproducibility details
- Specify hidden-state extraction exactly (token indices, pre/post-layer normalization states, KV-cache usage), decoding parameters, and hardware; release code to minimize ambiguity.
These gaps suggest a roadmap: strengthen methodological rigor (ablations, calibration, significance), broaden domains and models (including larger, closed models), deepen understanding of training effects (RL vs SFT), and harden the method against practical and adversarial constraints while reducing cost.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s non-parametric verifier, Clue, which classifies and reranks reasoning traces by hidden-state clustering and activation deltas.
- Improved answer selection in multi-sample inference pipelines
- Sector: software, education, research (math/QA), enterprise AI platforms
- Workflow/product: wrap existing self-consistency or best-of-N generation with Clue reranking (
distance-to-success-centroid), then select top-1 or perform majority vote over top-k - Impact: boosts accuracy versus majority voting and confidence-based reranking, especially for smaller or less-calibrated models
- Assumptions/dependencies: access to hidden states for a verifier model; a labeled “experience set” in the target domain to compute centroids; explicit reasoning delimiters (e.g.,
> ...</think>), or a defined proxy for start/end of reasoning > > - Lightweight verifier-as-a-service for cross-model scoring > - Sector: MLOps, AI tooling, platform engineering > - Workflow/product: deploy a small RL-tuned open-source model as a passive verifier to score hidden-state deltas on candidate traces produced by any model; expose scoring via API > - Impact: mitigates need for an expensive LLM judge; robust across model scales and domains > - Assumptions/dependencies: the verifier model must expose hidden states; centroid construction must be done per verifier and per domain; approvals for processing text traces (privacy/compliance) > > - Synthetic data curation and bootstrapping for training > - Sector: AI/ML (data engineering, RLHF/SFT pipelines) > - Workflow/product: use Clue to filter and select high-quality synthetic samples (correct solutions) to build cleaner fine-tuning datasets or reward models > - Impact: reduces label noise and improves downstream model training without building a learned verifier > - Assumptions/dependencies: reliable rule-based or programmatic labels to build initial centroids; domain alignment between experience set and target tasks > > - Risk scoring and gating in high-stakes outputs > - Sector: finance, legal, compliance, enterprise decision support > - Workflow/product: attach a hidden-state quality score (distance to success centroid) to each output; gate escalation, human review, or additional computation based on score thresholds > - Impact: reduces confidently-wrong outputs where probability calibration is poor > - Assumptions/dependencies: domain-specific centroids; human-in-the-loop for critical decisions; regulatory acceptance of internal verification signals > > - Efficiency gains in test-time scaling > - Sector: cloud inference, energy/cost optimization > - Workflow/product: pre-filter low-quality candidates before expensive aggregation or long “thinking,” or prioritize evaluation for top-ranked candidates > - Impact: fewer samples needed to reach target accuracy; lower compute and latency > - Assumptions/dependencies: integration with generation orchestrators; measurement of end-to-end cost/benefit under workload constraints > > - Early-exit and adaptive compute control > - Sector: software, MLOps > - Workflow/product: use layer-wise or final hidden-state separability to decide when to truncate “thinking” or trigger additional refinement (e.g., only “think” more when distance suggests failure) > - Impact: balances accuracy and cost dynamically > - Assumptions/dependencies: model with accessible hidden states; defined thresholds tuned to task distributions; safe handling of border cases > > - Model health monitoring and drift detection > - Sector: operations, reliability engineering > - Workflow/product: track distributions of success/failure centroid distances over time across tasks; alert on degradation or domain shift > - Impact: proactive detection of performance regressions and calibration issues > - Assumptions/dependencies: telemetry pipeline for hidden-state summaries; stable centroids for baseline tasks; privacy controls for trace capture > > - Agent plan verification in complex workflows > - Sector: software agents, RPA, knowledge workers > - Workflow/product: score latent reasoning for intermediate steps (plans/subgoals) and suppress execution when hidden-state signals match failure centroids > - Impact: lowers error cascades in multi-step agents without training an external judge > - Assumptions/dependencies: ability to delimit and capture hidden states for intermediate steps; domain-specific experience sets > > - Educational tutoring and grading support (math and general reasoning) > - Sector: education (edtech, automated grading) > - Workflow/product: rerank student-solution candidates or self-generated solutions; flag explanations with failure-like trajectories for instructor review > - Impact: higher-quality assistance and fairer grading across diverse reasoning styles > - Assumptions/dependencies: labeled experience from aligned curricula; interpretability of scores for educators; guardrails against bias > > - General-purpose alternative to LLM-as-a-judge > - Sector: content platforms, QA services, search > - Workflow/product: replace or augment textual judges with hidden-state verification for correctness-sensitive tasks > - Impact: reduces stylistic bias and optimism seen in judges; more balanced TPR/TNR > - Assumptions/dependencies: model instrumentation; domain-appropriate centroid sets; governance for using internal activations > > ## Long-Term Applications > > These applications may require further research, standardization, scaling, or regulatory validation to be broadly feasible. > > - Verifiability-optimized training regimes > - Sector: AI/ML research and model training > - Product/workflow: RL or hybrid objectives to explicitly maximize geometric separability of success vs failure in hidden space; “verifiability” metrics as training targets > - Dependencies: access to training signals that contrast correct and incorrect reasoning (negative feedback); robust metrics across domains and models > > - Standardized hidden-state verification APIs for providers > - Sector: model platforms, cloud AI services > - Product/workflow: vendor-neutral APIs to expose safe, efficient hidden-state summaries (e.g., activation deltas at specified markers) for verification > - Dependencies: provider cooperation; privacy/security specifications; performance overhead controls; legal frameworks around internal activations > > - Multimodal latent verification (text, vision, audio, robotics) > - Sector: robotics, autonomous systems, healthcare imaging, multimedia analytics > - Product/workflow: extend Clue-style centroiding to multimodal encoders and planners to verify trajectories (e.g., motion plans, diagnostic reasoning) > - Dependencies: reliable delimiters for “reasoning segments” in multimodal models; labeled experience sets with trustworthy correctness signals; safety validation > > - Clinical and financial decision support with latent gating > - Sector: healthcare, finance > - Product/workflow: combine hidden-state verification with domain constraints to gate diagnoses, risk assessments, or transaction approvals > - Dependencies: rigorous clinical/financial validation; regulatory approval (e.g., FDA, Basel/SEC); human review; domain-specific centroid construction; bias auditing > > - Adaptive test-time compute budgets driven by hidden-state signals > - Sector: cloud/edge inference, energy management > - Product/workflow: decide compute allocation per query (think longer or stop early) based on distance-to-success centroid and layer-wise separability trends > - Dependencies: large-scale orchestration; reliable thresholds across heterogeneous workloads; cost–accuracy modeling > > - Safety and alignment controls via activation monitoring > - Sector: AI safety, platform integrity > - Product/workflow: detect and attenuate sycophancy/hallucination/persona drift with hidden-state monitors; integrate with persona vectors and policy engines > - Dependencies: validated mappings from hidden directions to behaviors; red-teaming; governance for intervention policies > > - IDE and software engineering tools with latent verification > - Sector: software development > - Product/workflow: code assistants that score internal reasoning before proposing edits; prioritize unit-test generation or static analysis for high-risk traces > - Dependencies: code-domain centroids; integration with CI/CD and test infrastructures; evaluation on real-world repositories > > - Auditing and certification of AI systems using internal signals > - Sector: policy, standards, certification bodies > - Product/workflow: standardized audits that include hidden-state separability metrics and logs; third-party verification services > - Dependencies: consensus on metrics; reproducibility across models; secure logging and privacy-preserving protocols > > - On-device verification for edge and mobile assistants > - Sector: edge AI, consumer devices > - Product/workflow: deploy compact RL-tuned verifier models to score local assistants’ reasoning, reducing cloud reliance > - Dependencies: efficient hidden-state capture; memory-friendly summaries; energy constraints; device privacy guarantees > > - Marketplace and benchmarking ecosystems incorporating latent verification > - Sector: model marketplaces, evaluation platforms > - Product/workflow: include centroid-based correctness scores as part of model rankings and challenge leaderboards; support cross-domain comparability > - Dependencies: shared benchmarks with experience sets; harmonized scoring policies; transparency to avoid gaming > > - Curriculum and pedagogy tools built on reasoning geometry > - Sector: education research > - Product/workflow: use layer-wise separability analyses to design curricula that elicit clearer reasoning trajectories; feedback tools for student cognition > - Dependencies: interdisciplinary validation; ethics for educational measurement; adaptation across languages and subjects > > Notes on feasibility common to many applications: > > - Hidden-state access: closed-source models may not expose activations; practical deployment favors open-source or provider-exposed APIs. > > - Experience sets: centroids must be built from labeled trajectories aligned with the target domain and model; cross-domain generalization is promising but not guaranteed. > > - Reasoning delimiters: performance assumes identifiable start/end of reasoning (e.g.,<think>...); alternative markers or heuristics may be needed when absent.
- Compute and memory: capturing layer-wise activations adds overhead; optimization (sampling fewer layers, compression) may be necessary at scale.
- Compliance and privacy: internal state logging must meet data protection standards, especially in regulated sectors.
Glossary
- Activation delta: Difference between hidden states at the start and end of a reasoning block, used as the core feature for verification. "The activation delta is the matrix"
- Activation editing: Technique that modifies internal activations to steer or analyze model behavior. "activation editing provide a general lens on hidden-state geometry"
- Activation geometry: The geometric structure and relationships within a model’s activation space. "Latent Reasoning and Activation Geometry"
- AIME: A benchmark of competition math problems (American Invitational Mathematics Examination) used to evaluate reasoning. "across AIME 24/25 and GPQA"
- Best-of-N: Test-time selection approach that samples N solutions and picks the best according to a criterion. "best-of-N sampling"
- Calibrated confidence: Probability estimates that accurately reflect true correctness likelihoods. "calibrated confidence from token probabilities"
- Calibration: The degree to which predicted probabilities match actual outcomes. "calibration of LLMs remains poor"
- Chain-of-Thought (CoT): Explicit step-by-step reasoning in generated text. "compress CoT"
- Centroid: The mean vector of a set of activation-delta representations used as a class prototype. "success and failure centroid matrices"
- Centroid-distance: A measure of separation between class centroids across layers. "The centroid-distance curve increases with \ell"
- Confidence-based methods: Approaches that estimate correctness using token probabilities or uncertainty. "confidence-based methods"
- Cross-model reranking: Using one model’s internal signals to reorder another model’s candidate solutions. "Cross-model reranking performance on AIME 24."
- DeepConf: A confidence-based reranking method that filters low-quality reasoning traces. "DeepConf filters low-quality reasoning traces"
- Early exit: Stopping generation or computation once sufficient confidence/evidence is reached. "enable early exit"
- Early-exit schemes: Methods that adaptively truncate the reasoning process to save compute while maintaining accuracy. "early-exit schemes"
- Entropy: A measure of uncertainty in the token probability distribution. "token probabilities, entropy, or derived uncertainty estimates"
- Euclidean distance: Standard L2 distance used to compare activation-delta matrices layer-wise. "layer-averaged Euclidean distance"
- Experience set: A labeled collection of past trajectories used to compute success/failure centroids. "experience set"
- Failure centroid: The centroid representing incorrect (failed) trajectories. "failure centroid"
- Geometric separation: Visible clustering that distinguishes correct and incorrect trajectories in activation space. "a geometric separation is visible"
- GPQA: Graduate-level question answering benchmark for general reasoning. "GPQA"
- Hidden-state clustering: Grouping trajectories by their internal activations to separate success and failure. "Hidden-State Clustering"
- Hidden-state probes: Lightweight models or diagnostics that read hidden states to predict properties like correctness. "Hidden-state probes can self-verify"
- Hidden state trajectories: The sequence of internal representations along the reasoning process. "hidden state trajectories"
- Hidden states: Internal layer representations of an LLM during processing/generation. "Hidden states naturally subsume both kinds of information"
- In-context activation vectors: Directional activation features that can be reused across tasks within context. "in-context activation vectors"
- Latent space: Continuous internal representation space where reasoning can occur without explicit tokens. "reason in latent space"
- Layer-averaged Euclidean distance: Distance metric averaging per-layer Euclidean distances between matrices. "layer-averaged Euclidean distance"
- Logit lens: Technique decoding intermediate activations into approximate output distributions. "logit lens"
- Logits: Pre-softmax scores over the vocabulary representing unnormalized probabilities. "output logits"
- LLM-as-a-judge: Using a LLM to evaluate and score other model outputs. "LLM-as-a-judge"
- Majority voting: Aggregation method selecting the most frequent answer among samples. "majority voting"
- Mechanistic interpretability: Studying internal circuits and representations to explain model behavior. "mechanistic interpretability"
- MATH: A dataset of math problems used to train/evaluate mathematical reasoning. "the MATH"
- Nearest-centroid distance: Classification by assigning to the class whose centroid is closest in activation space. "nearest-centroid distance"
- Non-parametric: Methods that do not learn additional parameters from data (training-free). "non-parametric verifier"
- Oracle upper bound: An idealized maximum achievable performance given sampled candidates. "pass@64 (Oracle)"
- Out-of-distribution (OOD): Data differing from the training distribution used to test generalization. "out-of-distribution (OOD) generalization"
- PCA (Principal Component Analysis): Dimensionality reduction technique for visualizing high-dimensional activations. "projected to 2D using PCA"
- Persona vectors: Activation directions capturing stylistic or behavioral traits that can be monitored/steered. "persona vectors"
- Principal components: Orthogonal directions capturing maximal variance in data after PCA. "two principal components"
- Reinforcement Learning (RL): Training paradigm optimizing behaviors via reward signals. "Reinforcement Learning (RL)"
- Representation engineering: Manipulating and analyzing internal representations to control or understand models. "representation engineering"
- Reranking: Reordering candidate solutions based on a quality score derived from hidden states. "reranking candidates"
- RLHF: Reinforcement Learning from Human Feedback for aligning models to human preferences. "RLHF and LLM-as-a-judge"
- Rule-based verifier: Deterministic programmatic checker used to label solutions as correct or incorrect. "rule-based verifier"
- Self-consistency: Test-time strategy sampling multiple rationales and aggregating answers. "self-consistency"
- Success centroid: The centroid representing correct (successful) trajectories. "the success centroid"
- Supervised aggregation: Label-guided averaging of representations to form class prototypes without training a classifier. "training-free, supervised aggregation framework"
- Supervised Fine-Tuning (SFT): Training a model on labeled examples to imitate desired outputs. "Supervised Fine-Tuning (SFT)"
- Test-time scaling: Improving performance by spending more compute during inference. "Test Time Scaling"
- Top-maj@k: Majority voting over the top-k reranked candidates. "top-maj@16"
- Top@1: Selecting the single highest-scoring candidate after reranking. "top@1"
- Tree-of-Thoughts: Search strategy structuring reasoning as a tree of intermediate steps. "Tree-of-Thoughts"
- True Negative Rate (TNR): Fraction of incorrect solutions correctly identified as such. "True Negative Rate (TNR)"
- True Positive Rate (TPR): Fraction of correct solutions correctly identified as such. "True Positive Rate (TPR)"
- Tuned lens: Variant of logit lens trained to better decode layer-wise activations. "tuned lens"
- Verification function: Mapping from a trajectory to a correctness prediction. "a verification function f"
- Weighted or semantic self-consistency: Variants of self-consistency that use weights or semantic similarity in aggregation. "weighted or semantic self-consistency"
- WebInstruct-verified: A benchmark of diverse domains with verification via provided references. "WebInstruct-verified"
Collections
Sign up for free to add this paper to one or more collections.