Mathematical Theory of Collinearity Effects on Machine Learning Variable Importance Measures
Published 1 Oct 2025 in math.ST, stat.ML, and stat.TH | (2510.00557v1)
Abstract: In many machine learning problems, understanding variable importance is a central concern. Two common approaches are Permute-and-Predict (PaP), which randomly permutes a feature in a validation set, and Leave-One-Covariate-Out (LOCO), which retrains models after permuting a training feature. Both methods deem a variable important if predictions with the original data substantially outperform those with permutations. In linear regression, empirical studies have linked PaP to regression coefficients and LOCO to $t$-statistics, but a formal theory has been lacking. We derive closed-form expressions for both measures, expressed using square-root transformations. PaP is shown to be proportional to the coefficient and predictor variability: $\text{PaP}_i = \beta_i \sqrt{2\operatorname{Var}(\mathbf{x}v_i)}$, while LOCO is proportional to the coefficient but dampened by collinearity (captured by $\Delta$): $\text{LOCO}_i = \beta_i (1 -\Delta)\sqrt{1 + c}$. These derivations explain why PaP is largely unaffected by multicollinearity, whereas LOCO is highly sensitive to it. Monte Carlo simulations confirm these findings across varying levels of collinearity. Although derived for linear regression, we also show that these results provide reasonable approximations for models like Random Forests. Overall, this work establishes a theoretical basis for two widely used importance measures, helping analysts understand how they are affected by the true coefficients, dimension, and covariance structure. This work bridges empirical evidence and theory, enhancing the interpretability and application of variable importance measures.
The paper derives closed-form expressions for PaP and LOCO, clarifying their sensitivity to collinearity in linear models.
It validates theoretical predictions using Monte Carlo simulations, showing PaP’s stability and LOCO’s decline with increasing collinearity.
The study offers practical bias corrections for small samples and extends insights to nonparametric models like Random Forests.
Mathematical Analysis of Collinearity Effects on Variable Importance in Machine Learning
Introduction
This paper presents a rigorous mathematical framework for understanding how collinearity among predictors affects two widely used variable importance measures in machine learning: Permute-and-Predict (PaP) and Leave-One-Covariate-Out (LOCO). The authors derive closed-form expressions for both measures in the context of linear regression, elucidate their dependence on regression coefficients, predictor variance, and collinearity, and empirically validate these results through extensive simulations. The work also explores the generalizability of these findings to nonparametric models such as Random Forests, providing a theoretical foundation for interpreting variable importance in the presence of correlated features.
Theoretical Framework and Derivations
The analysis is grounded in a latent variable model where observed predictors X are generated as linear transformations of independent latent variables Z via a correlation-inducing matrix A parameterized by a collinearity parameter Δ∈[0,1). This construction allows precise control over the degree of collinearity among predictors and facilitates closed-form derivations.
Permute-and-Predict (PaP)
The PaP measure is defined as the square root of the increase in loss (typically MSE) when a variable is permuted in the validation set, holding the model fixed. The authors show that, under the linear model and assuming accurate coefficient estimation, PaP for variable i is given by:
PaPi=βi2Var(xiv)
where βi is the true regression coefficient and Var(xiv) is the variance of the ith predictor in the validation set. Notably, PaP is insensitive to collinearity except through its effect on marginal variance, and this insensitivity is exact when predictors are standardized.
Leave-One-Covariate-Out (LOCO)
LOCO measures the increase in loss when a variable is permuted (or dropped) in the training set and the model is retrained. The derivation reveals that LOCO is proportional to the coefficient but dampened by collinearity:
LOCOi=βi(1−Δ)1+c
where c is a function of Δ and the number of predictors p, capturing the absorption of the permuted variable's effect by correlated predictors. As Δ→1, LOCO approaches zero, reflecting the redundancy of perfectly collinear variables.
Relationship to t-Statistics
A key result is the formal connection between LOCO and the classical t-statistic:
ti=LOCOiVar(ϵ)n−1
This establishes that LOCO, like the t-statistic, is highly sensitive to collinearity, providing a theoretical explanation for empirical observations in both classical and modern machine learning contexts.
Empirical Validation
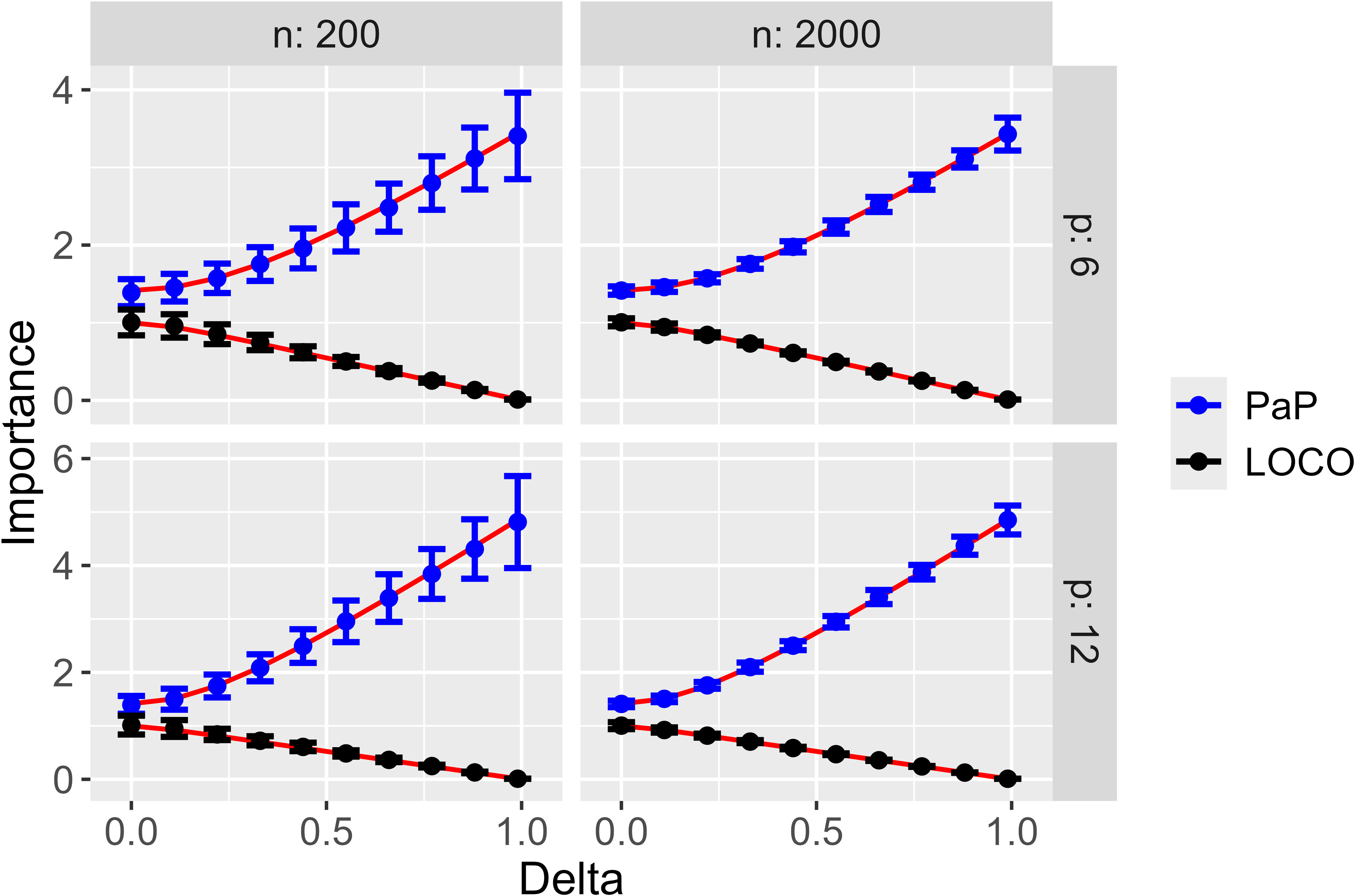
The theoretical results are validated through extensive Monte Carlo simulations varying collinearity (Δ), number of predictors (p), and sample size (n). The simulations confirm the predicted behaviors:
PaP increases with predictor variance and is largely unaffected by collinearity.
LOCO decreases nearly linearly with increasing collinearity, matching the theoretical form.
Figure 1: Mean and 2 Standard deviation error bars for assessing the relationship between importance values and Δ; PaP increases with Δ while LOCO decreases, in agreement with theoretical predictions.
The authors also extend the analysis to Random Forests, finding that while empirical variable importance measures in Random Forests deviate somewhat from the linear theory (especially at low collinearity), the overall trends persist. This suggests that the theoretical framework provides useful approximations even for nonparametric models.
Correction for Small Sample Bias
The study identifies and corrects for small-sample biases in both PaP and LOCO. For PaP, Bessel's correction is applied, and for LOCO, a degrees-of-freedom adjustment is used. These corrections eliminate systematic biases observed in simulations, particularly when n is small relative to p.
Implications and Extensions
The results have several important implications:
Interpretability: The closed-form expressions clarify what PaP and LOCO actually measure. PaP reflects predictive sensitivity (marginal importance), while LOCO reflects model necessity (conditional importance).
Collinearity Effects: The analysis quantifies the well-known phenomenon that collinearity inflates marginal importance but deflates conditional importance, providing precise mathematical relationships.
Generalization: While derived for linear models, the framework extends to block-correlated structures and provides reasonable approximations for Random Forests and potentially other machine learning models.
Practical Guidance: The results inform practitioners about the interpretation and limitations of variable importance measures, especially in the presence of correlated predictors.
The authors note that while the derivations are specific to linear models, the qualitative trends are expected to hold in more general settings, including nonlinear and high-dimensional models, though further work is needed to formalize these extensions.
Limitations and Future Directions
The primary limitation is the focus on linear models with specific collinearity structures. While the extension to Random Forests is empirically promising, the theoretical underpinnings for more complex models remain to be developed. The applicability of the finite-sample corrections to high-dimensional or regularized models also warrants further investigation. Future research directions include:
Extending the theory to nonlinear and high-dimensional settings.
Formalizing the behavior of variable importance measures in other model classes (e.g., neural networks, boosting).
Unifying the analysis with other interpretability frameworks such as SHAP and partial dependence.
Conclusion
This work provides a comprehensive mathematical theory for the effects of collinearity on two central variable importance measures in machine learning. By deriving and empirically validating closed-form relationships, the paper bridges the gap between empirical observations and theoretical understanding, offering both practical tools and conceptual clarity for the interpretation of variable importance in the presence of correlated predictors. The results have direct implications for the design, interpretation, and application of interpretable machine learning methods, and lay the groundwork for future theoretical and methodological advances in the field.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.