- The paper introduces a cost-controlled evaluation method that jointly optimizes computational expense and accuracy, reducing variable costs on benchmarks like HumanEval.
- It reveals that simple baseline strategies achieve Pareto efficiency over complex SOTA agents, challenging conventional accuracy-centric benchmarks.
- The research distinguishes between model evaluation and downstream deployment, advocating standardized holdout designs to ensure reproducible and practical AI performance.
AI Agents That Matter
Introduction
The paper "AI Agents That Matter" addresses critical challenges associated with AI agent benchmarks and evaluation practices. It identifies key shortcomings in current benchmarks: a predominant focus on accuracy, conflated benchmarking needs, inadequate holdout sets, and a lack of standardization, which hinder real-world application. The authors propose a novel focus on cost in addition to accuracy, aiming to jointly optimize these metrics, which could significantly reduce costs while maintaining performance levels.
Cost-Controlled Evaluation
The paper emphasizes that maximizing accuracy without considering computational cost can lead to inflated resource usage and misleading conclusions regarding advancements made by AI agents. By introducing cost-controlled evaluation methods, the research showcases how simple baseline agents (e.g., retry, warming strategies) outperform many state-of-the-art (SOTA) complex agents in terms of efficiency on HumanEval tasks.
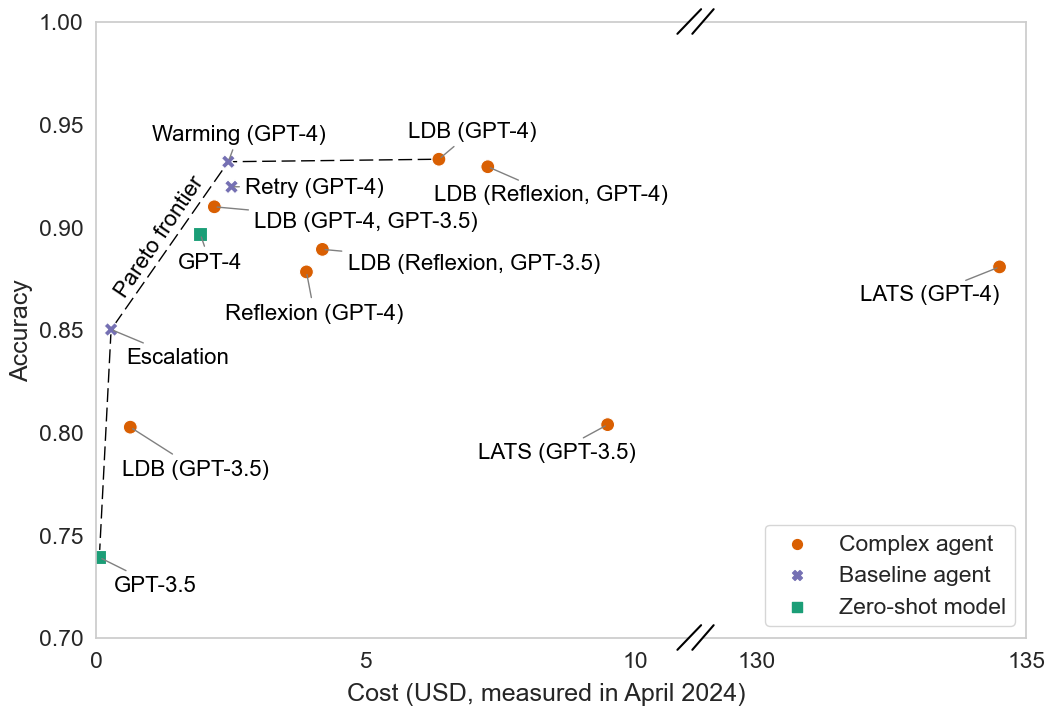
Figure 1: Our simple baselines offer Pareto improvements over SOTA agents.
By plotting accuracy against inference cost, SOTA agents do not display any significant advantage over simple baselines. Reflexion, LDB, and LATS designed as complex agents incur higher costs with negligible improvements in accuracy.
Joint Optimization of Cost and Accuracy
The research introduces joint optimization procedures, integrating cost evaluations directly into agent design frameworks. Through the modification of the DSPy framework, the authors demonstrate substantial reductions in variable costs while preserving accuracy on the HotPotQA benchmark.
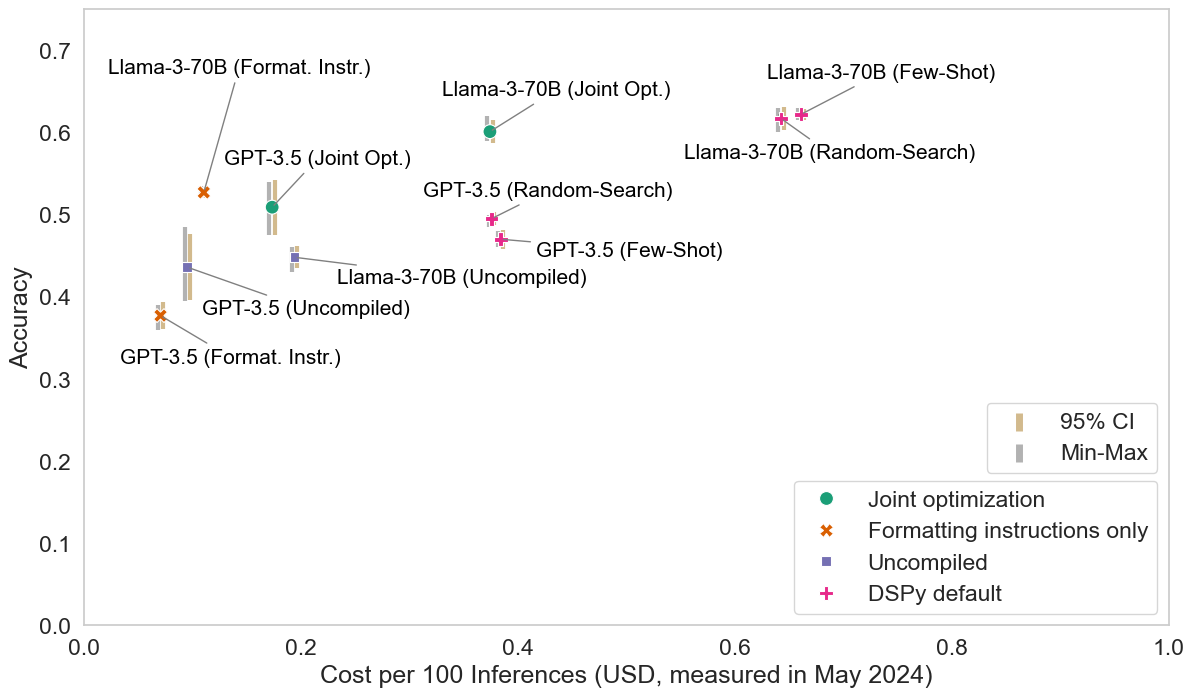
Figure 2: Error bars for our HotPotQA analysis.
Their method leverages Pareto efficiency in accuracy-cost tradeoffs, elucidating how upfront fixed costs can be managed to minimize variable costs across large-scale, frequent-use scenarios. They investigate the balance between fixed costs associated with model optimization and variable inference costs, illustrating tied improvements using frameworks like Optuna for hyperparameter tuning.
Distinct Needs of Model vs. Downstream Developers
An important distinction made within the paper is between model evaluation—aimed at scientific advancement—and downstream evaluation, which informs application deployment decisions. This differentiation is pivotal in understanding how benchmarks need to grasp actual computing costs rather than proxy metrics like the number of active parameters, misleading developers looking to embed AI systems.
The NovelQA case study exemplifies this differentiation, revealing how benchmarks optimized for scientific inquiry may mislead practical cost evaluations when used for downstream deployment strategies, particularly in evaluating models for real-world queries.
Addressing Benchmark Shortcuts and Robust holdouts
Benchmark design, according to the research, should avoid shortcuts that allow agents to overfit without genuine capability improvements. The paper proposes a systematic framework where holdout sample designs should correspond to desired agent generality levels—distribution-specific, task-specific, domain-general, or fully general—to ensure construct validity and reliable real-world performance evaluations.
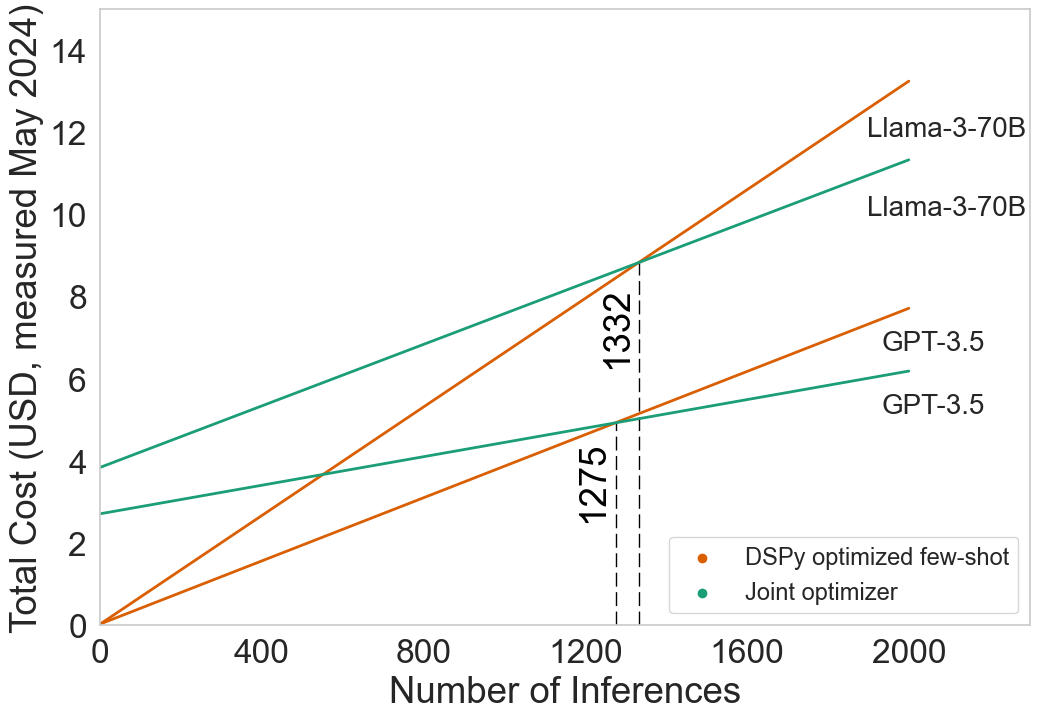
Figure 3: With increased use, the total cost of running an agent is dominated by the variable cost.
Standardization and Reproducibility Challenges
Current practices in agent evaluation exhibit deficiencies in reproducibility and evaluation standardization. The paper identifies several core issues, such as inconsistent agent task order and evaluation setup, evaluation cost constraints, and the lack of standardized evaluation scripts, which cause discrepancies in leaderboard performances for benchmarks like WebArena and HumanEval.
Conclusion
This research makes pivotal contributions towards a principled and rigorous framework for evaluating AI agents, bridging the gap between benchmark evaluation and real-world applicability. By advocating for cost-aware evaluations, distinct benchmarking needs for model versus downstream developers, robust shortcut prevention, and rigorous standardization, this paper affirms the future trajectory for developing practically useful AI agents.