Fine-tuning Behavioral Cloning Policies with Preference-Based Reinforcement Learning
Published 30 Sep 2025 in cs.AI and cs.LG | (2509.26605v1)
Abstract: Deploying reinforcement learning (RL) in robotics, industry, and health care is blocked by two obstacles: the difficulty of specifying accurate rewards and the risk of unsafe, data-hungry exploration. We address this by proposing a two-stage framework that first learns a safe initial policy from a reward-free dataset of expert demonstrations, then fine-tunes it online using preference-based human feedback. We provide the first principled analysis of this offline-to-online approach and introduce BRIDGE, a unified algorithm that integrates both signals via an uncertainty-weighted objective. We derive regret bounds that shrink with the number of offline demonstrations, explicitly connecting the quantity of offline data to online sample efficiency. We validate BRIDGE in discrete and continuous control MuJoCo environments, showing it achieves lower regret than both standalone behavioral cloning and online preference-based RL. Our work establishes a theoretical foundation for designing more sample-efficient interactive agents.
The paper presents the BRIDGE algorithm, which merges offline behavioral cloning with online preference-based RL to fine-tune policies safely.
It constructs a confidence set using Hellinger distance to constrain online exploration, yielding explicit regret bounds that scale with the quantity of offline data.
Empirical results across discrete and continuous control tasks demonstrate that increasing offline expert demonstrations significantly enhances online sample efficiency.
Fine-tuning Behavioral Cloning Policies with Preference-Based Reinforcement Learning
This paper presents a rigorous theoretical and algorithmic framework for combining offline behavioral cloning (BC) with online preference-based reinforcement learning (PbRL), addressing the challenges of reward specification and unsafe exploration in real-world RL deployments. The proposed BRIDGE algorithm leverages expert demonstrations to construct a confidence set over policies, which is then used to constrain and accelerate online preference learning. The work provides explicit regret bounds that quantify the trade-off between offline data quantity and online sample efficiency, and demonstrates empirical improvements over both standalone BC and PbRL baselines in discrete and continuous control environments.
Problem Setting and Motivation
The deployment of RL in domains such as robotics, industry, and healthcare is hindered by two primary obstacles: (1) the difficulty of specifying accurate reward functions, and (2) the risk and inefficiency of online exploration. The hybrid paradigm addressed in this work first learns a policy from reward-free expert demonstrations (offline BC), then fine-tunes it online using human preference feedback (PbRL). This approach is widely used in practice (e.g., RLHF for LLMs), but its theoretical properties have remained largely unexplored.
The paper formalizes the learning problem as a finite-horizon, reward-free MDP, with access to n expert trajectories and a trajectory embedding function ϕ. Preferences are modeled via a Bradley-Terry probabilistic model over trajectory embeddings, and the policy embedding is defined as the expected feature representation under the policy's trajectory distribution.
Offline Imitation: Learn a BC policy and transition model via MLE on the expert dataset.
Confidence Set Construction: Build a Hellinger ball in trajectory distribution space around the BC policy, with radius O(1/n) (where n is the number of offline demonstrations). This set is guaranteed to contain the expert policy with high probability.
Constrained Online Preference Learning: Restrict online exploration to policies within the confidence set, and iteratively refine the preference model using binary feedback on policy pairs.
The confidence set construction is grounded in concentration bounds for MLE estimators and a novel use of the Hellinger distance, which enables geometric interpretation and tractable analysis. The radius of the confidence set directly controls the trade-off between offline data and online exploration.
Figure 1: StarMDP environment structure, illustrating the discrete state-action transitions used in theoretical and empirical analysis.
Theoretical Analysis: Regret Bounds
The main theoretical contribution is a regret bound for BRIDGE that explicitly depends on both the number of offline demonstrations n and the online horizon T:
RT≤(T⋅log(1+nT)+n⋅γminT)
where γmin is the minimum visitation probability under the expert policy. As n→∞, the regret approaches zero for fixed T, formally validating the empirical observation that high-quality offline data dramatically improves preference learning efficiency.
The analysis leverages the connection between Hellinger distance and feature expectation differences, showing that constraining policy selection to the confidence set yields a variance term in the regret bound that scales as O(1/n). This is a significant improvement over prior PbRL bounds, which scale as O(T) independent of offline data.
Implementation Details and Practical Considerations
The BRIDGE algorithm is implemented for both discrete (tabular) and continuous control environments. In discrete settings, the policy space is exhaustively enumerated or sampled, and the Hellinger distance is efficiently computed via a recursive scheme. In continuous settings, the policy space is approximated by perturbations of the BC policy, and the confidence set is constructed using L2 distances in trajectory embedding space.
Key implementation aspects include:
Transition Model Estimation: Offline and online data are pooled for count-based MLE estimation, with exploration bonuses adapted from theoretical analysis.
Policy Selection: Online policy pairs are chosen to maximize a combined uncertainty objective, balancing preference model and transition model uncertainty.
Embedding Choice: The choice of trajectory embedding ϕ is critical; embeddings aligned with the true reward signal yield faster convergence and lower regret.
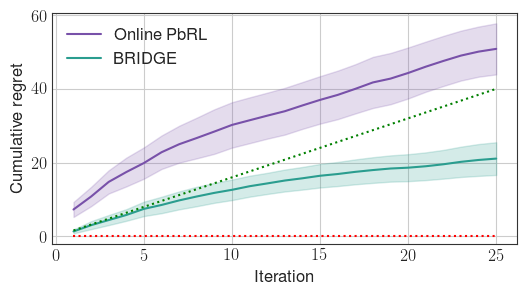
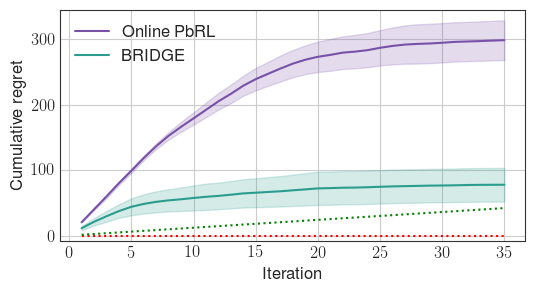
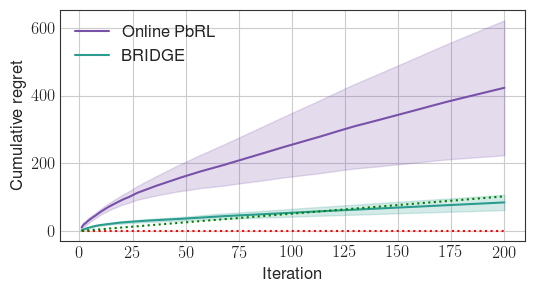
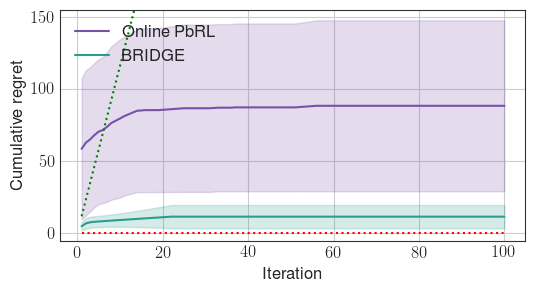
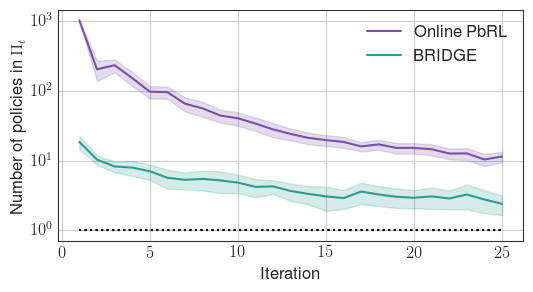
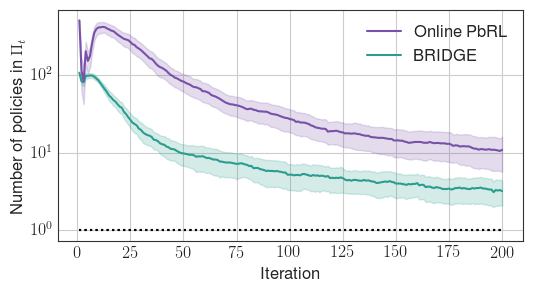
Figure 2: BRIDGE rapidly prunes the policy search space compared to the online PbRL baseline, in both discrete (StarMDP) and continuous (Reacher) environments.
Empirical Results
Experiments are conducted in four environments: StarMDP, Gridworld (discrete), Reacher, and Ant (continuous). BRIDGE consistently achieves lower cumulative regret than both offline BC and online PbRL baselines. Ablation studies demonstrate:
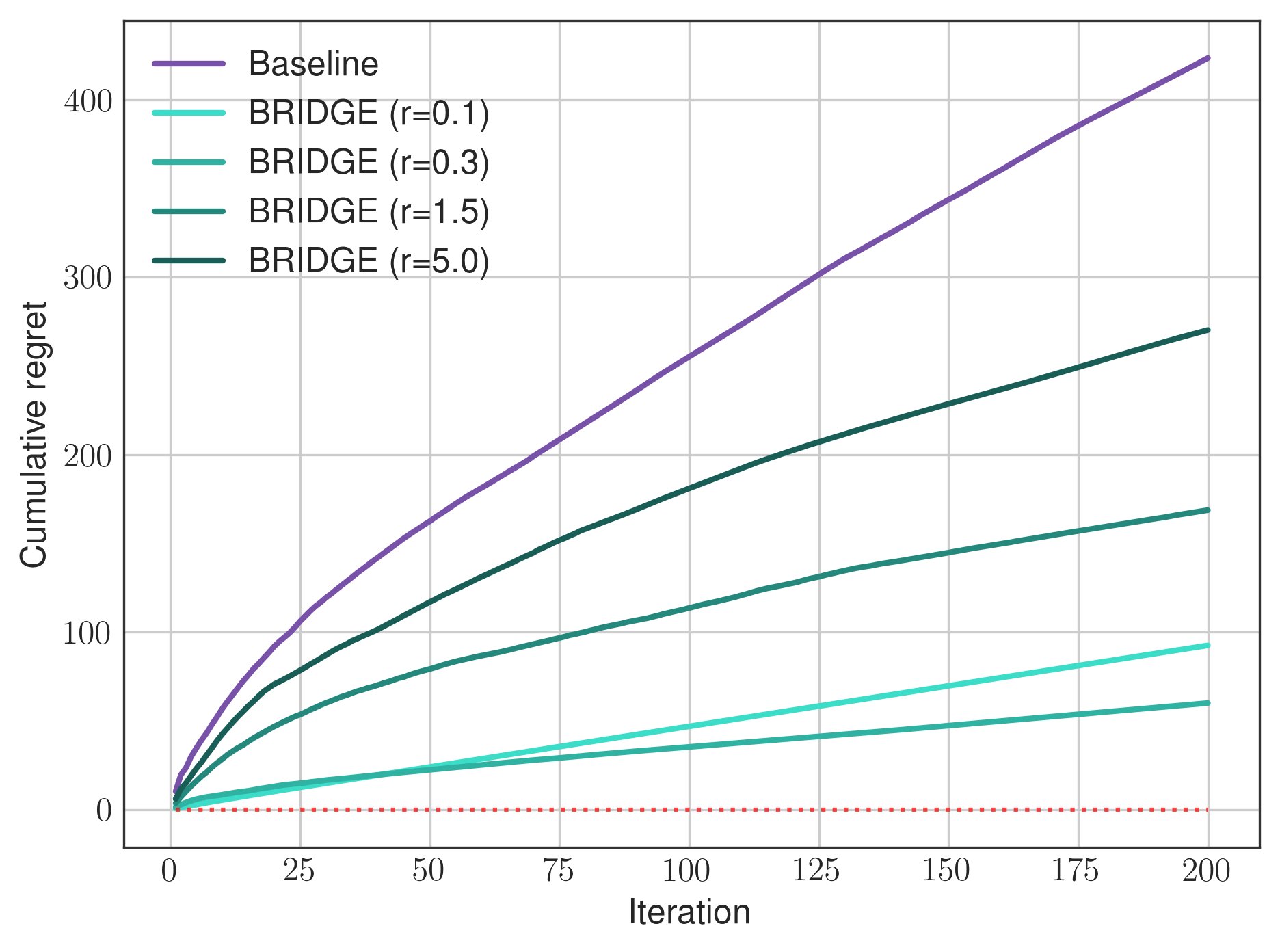
Confidence Set Radius: Performance is sensitive to the radius; too large yields poor constraint, too small may exclude the optimal policy.
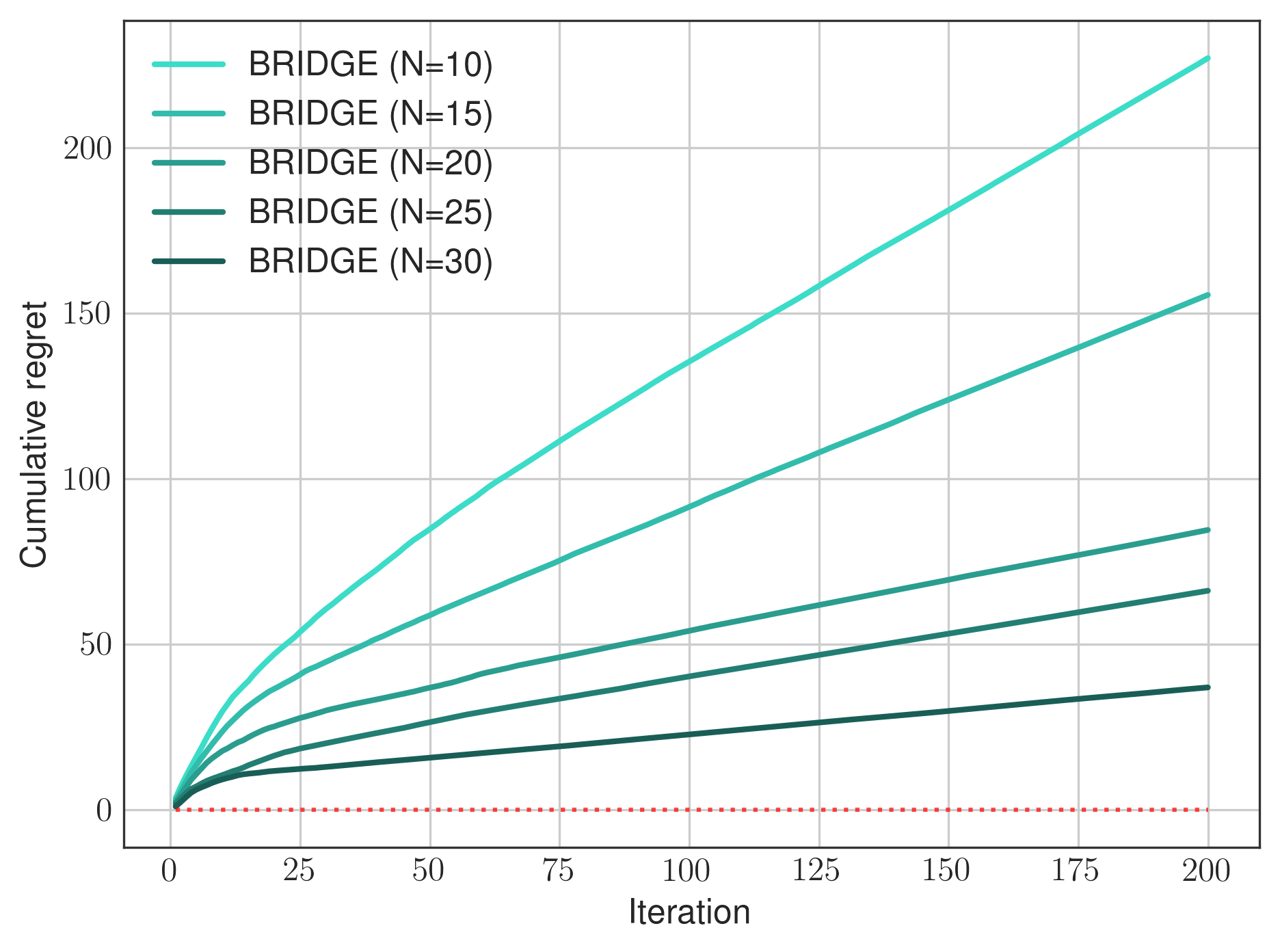
Offline Data Quantity: Increasing n shrinks the confidence set and improves regret, with empirical scaling matching theoretical predictions.
Embedding Quality: Embeddings closer to the true reward signal yield superior performance.
Figure 3: BRIDGE performance for different confidence set radii; overly small radii exclude optimal policies, increasing regret.
Figure 4: Regret decreases as the number of offline demonstration trajectories increases, validating the theoretical trade-off.
Figure 5: BRIDGE performance using different trajectory embeddings; reward-aligned embeddings yield faster convergence.
Implications and Future Directions
The results establish a formal connection between offline data quality and online sample efficiency in preference-based RL. The explicit regret bounds provide principled guidance for practitioners on the trade-offs between collecting expert demonstrations and allocating online preference queries. The framework is broadly applicable to domains where reward specification is infeasible and exploration is risky.
Potential future directions include:
Extending the analysis to non-stationary or partially observable environments.
Investigating alternative preference models and embedding functions.
Scaling BRIDGE to high-dimensional, real-world tasks with complex policy spaces.
Integrating uncertainty quantification for robust deployment in safety-critical applications.
Conclusion
The paper provides the first principled theoretical analysis of offline-to-online preference learning, introducing the BRIDGE algorithm and regret bounds that quantify the impact of offline expert data on online learning efficiency. Empirical results in both discrete and continuous control tasks validate the theory, demonstrating that BRIDGE achieves lower regret than both offline-only and online-only baselines. The work lays a foundation for designing interactive agents that can safely and efficiently improve from human input without explicit reward signals.