- The paper introduces Density-Ratio Weighted Behavioral Cloning, a method leveraging trajectory-level density ratios to filter corrupted data and enhance policy learning.
- It employs a binary discriminator for density-ratio estimation, ensuring robustness even under high contamination levels across diverse environments.
- Empirical results reveal that the approach maintains over 80% performance retention at up to 60% contamination with minimal computational overhead.
Density-Ratio Weighted Behavioral Cloning for Robust Offline RL
Introduction
Offline reinforcement learning (RL) represents a compelling model for optimizing policies using static data, which is crucial for safety-critical applications where direct interaction with the environment poses significant risks. The paper "Density-Ratio Weighted Behavioral Cloning: Learning Control Policies from Corrupted Datasets" (2510.01479) introduces a novel approach designed to handle the challenges posed by contaminated datasets, frequently arising from adversarial interference, sensor errors, or low-quality sampling. The paper proposes Density-Ratio Weighted Behavioral Cloning (Weighted BC) as a robust methodology to counteract these issues in imitation learning by utilizing trajectory-level density ratios. This method prioritizes expert-like trajectories while disregarding corrupted data, enhancing policy stability and performance without the need for explicit knowledge of the contamination mechanism.
Methodology
The framework is built upon a Markov decision process (MDP), incorporating the elements typical of RL: states, actions, transitions, rewards, and discount factors. The focus is on deriving a policy from an offline dataset potentially compromised by contamination, characterized by the mixture model: $p(\tau) = (1-\alpha)p_{\text{clean}(\tau) + \alpha p_{\text{bad}(\tau)$
where α represents the contamination fraction. Access to a small, trusted reference set is assumed, providing clean trajectories to guide the weighting in the BC objective.
Weighted Behavioral Cloning Objective
The approach modifies the classical BC objective using importance weighting to approximate the ideal clean distribution. The empirical loss involves weights derived from density ratios, estimated via a binary discriminator distinguishing between clean reference trajectories and the main dataset.
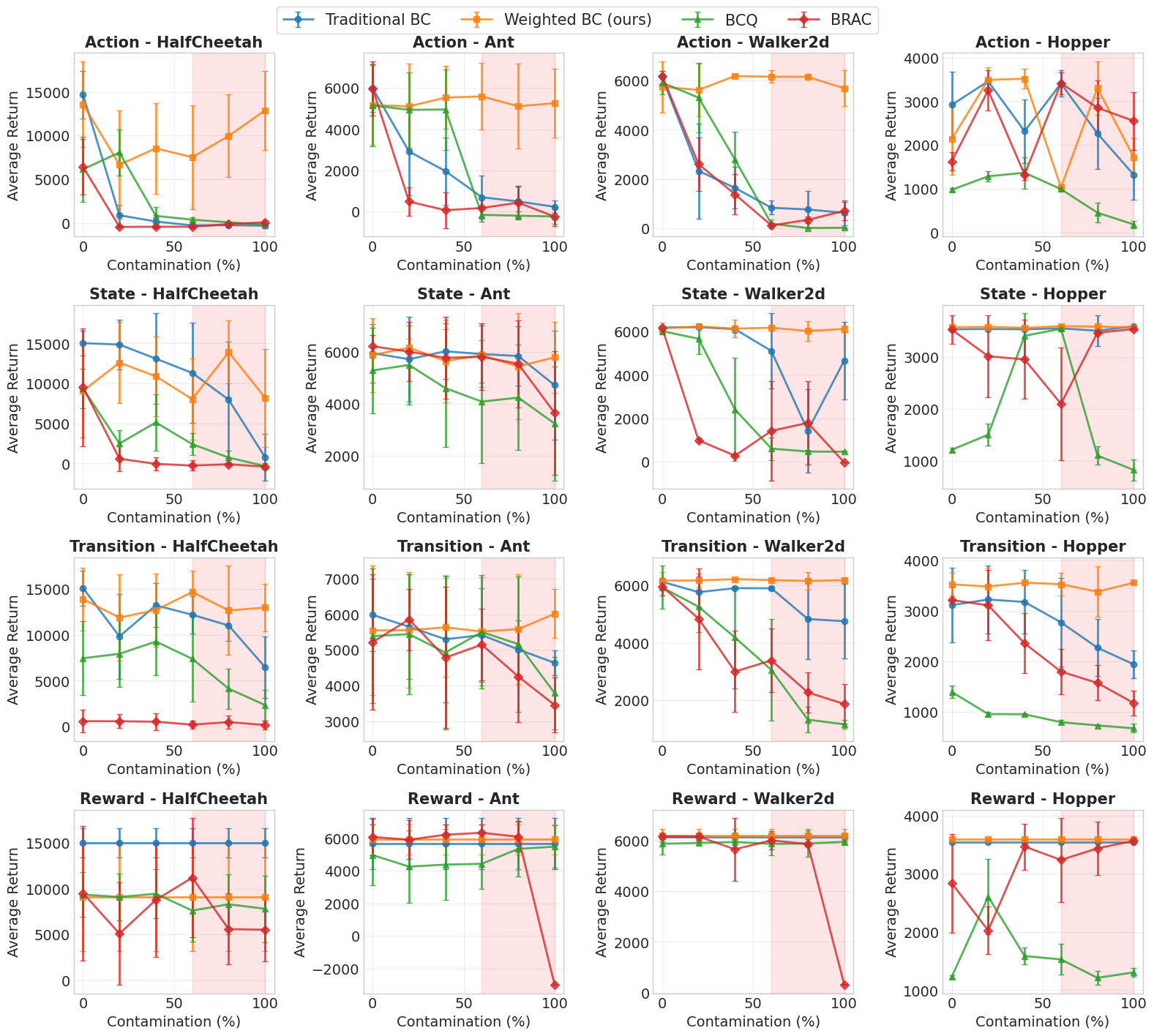
Figure 1: Average return as a function of contamination level α across four D4RL environments. Weighted BC shows superior performance even under high contamination.
Density-Ratio Estimation and Data Poisoning Generators
Density ratios are estimated using a binary discriminator, effectively balancing the clean reference against the contaminated dataset samples. Clipping ensures numerical stability during weight computation. Several poisoning generators simulate real-world contamination scenarios, including reward, state, transition, and action perturbations, to test the robustness of the method.
Theoretical Insights
The paper provides rigorous theoretical guarantees affirming the reliability of Weighted BC. The clean-risk approximation emphasizes finite-sample bounds independent of contamination severity, given appropriate clipping thresholds. The excess clean-risk guarantee further separates the effects of sample error, discriminator accuracy, and weighting bias, confirming robustness across various contamination scenarios.
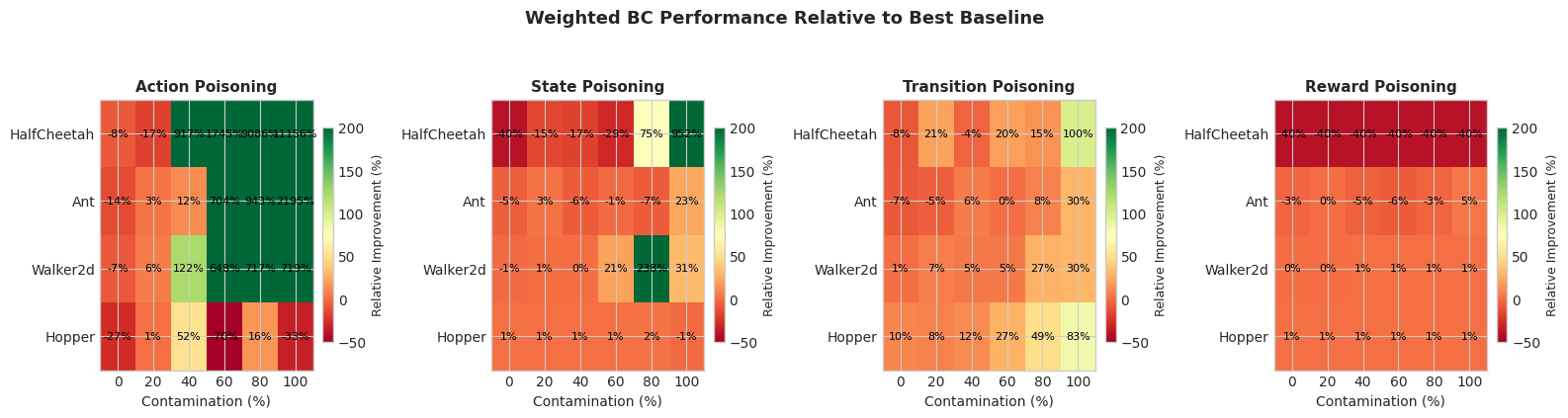
Figure 2: Relative performance improvement of Weighted BC over baseline methods at each contamination level. Consistently superior results highlight its robustness to contamination types.
Empirical Evaluation
Baseline Comparisons
Weighted BC is benchmarked against traditional BC, BCQ, and BRAC using common datasets with varying contamination levels. Results demonstrate its superior robustness, particularly in high-contamination regimes. Comparisons focus on retention and consistency of performance across multiple environments, affirming the effectiveness of its discriminator-weighted approach.
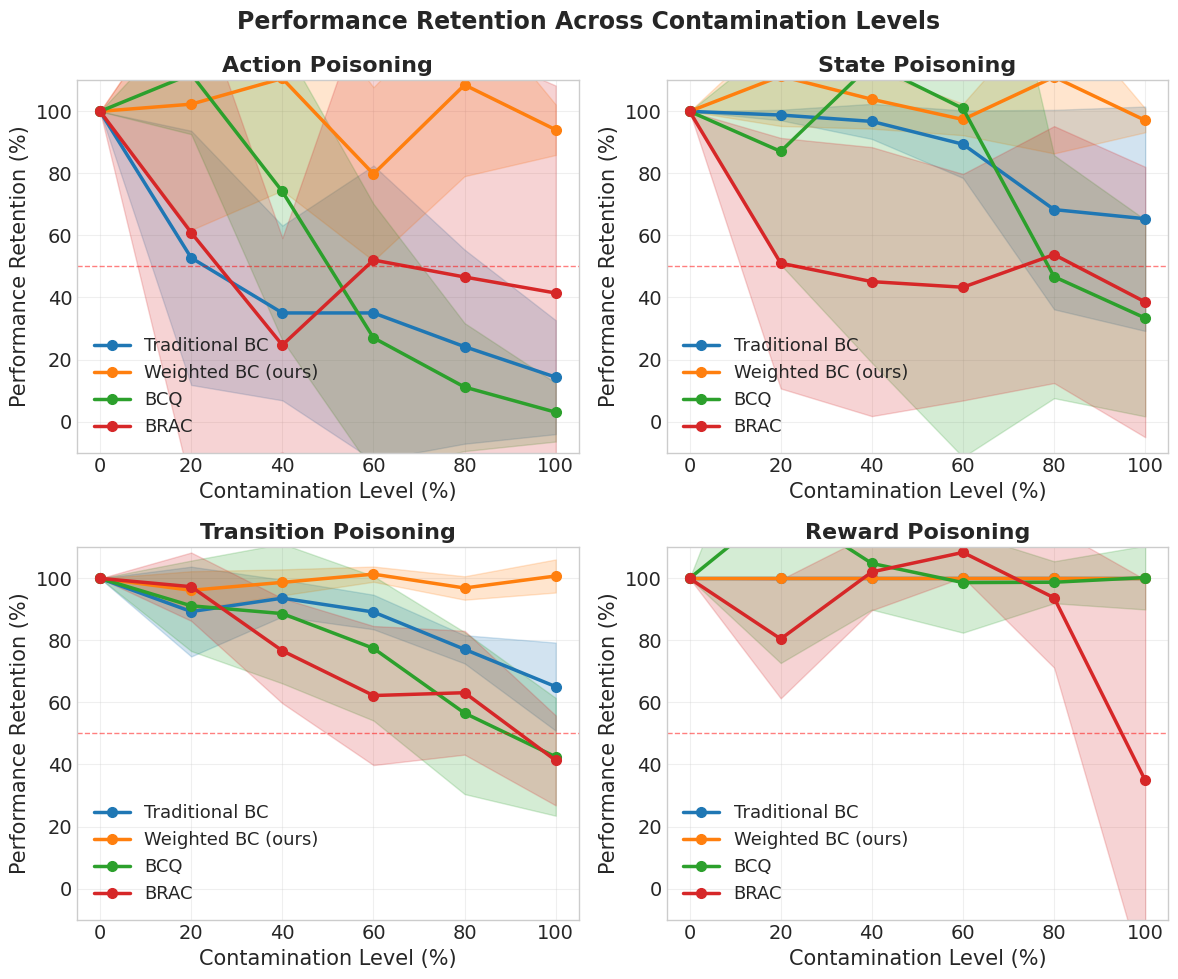
Figure 3: Performance retention normalized to clean baseline across poisoning types. Weighted BC maintains over 80% retention at 60% contamination.
Computational Efficiency
Analysis indicates Weighted BC incurs minimal overhead compared to standard BC, with only slight increases in training time and memory usage. This efficiency, coupled with its robustness, presents Weighted BC as a feasible solution for real-world applications requiring reliable policy learning from corrupted datasets.
Conclusion
"Density-Ratio Weighted Behavioral Cloning" proposes a formidable enhancement to offline RL methodologies, emphasizing robust policy learning amidst dataset contamination. With strong theoretical foundations and empirical validations, it emerges as a pragmatic solution for dynamic environments manipulated by adversarial attacks or subjected to systemic errors, maintaining high performance and reliability. This contribution lays the groundwork for future research directed at refining robustness techniques in offline learning scenarios.