MENLO: From Preferences to Proficiency -- Evaluating and Modeling Native-like Quality Across 47 Languages
Abstract: Ensuring native-like quality of LLM responses across many languages is challenging. To address this, we introduce MENLO, a framework that operationalizes the evaluation of native-like response quality based on audience design-inspired mechanisms. Using MENLO, we create a dataset of 6,423 human-annotated prompt-response preference pairs covering four quality dimensions with high inter-annotator agreement in 47 language varieties. Our evaluation reveals that zero-shot LLM judges benefit significantly from pairwise evaluation and our structured annotation rubrics, yet they still underperform human annotators on our dataset. We demonstrate substantial improvements through fine-tuning with reinforcement learning, reward shaping, and multi-task learning approaches. Additionally, we show that RL-trained judges can serve as generative reward models to enhance LLMs' multilingual proficiency, though discrepancies with human judgment remain. Our findings suggest promising directions for scalable multilingual evaluation and preference alignment. We release our dataset and evaluation framework to support further research in multilingual LLM evaluation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Menlo, a way to check how “native-like” AI chat responses sound across many languages. “Native-like” means the reply feels fluent, natural, and culturally right—so a local speaker wouldn’t think it was written by a machine or by someone who doesn’t really know the language or the place.
The authors build:
- A clear framework for what “native-like” means.
- A large dataset with human ratings in 47 language varieties.
- Better AI “judges” that can score responses more reliably.
- A way to use these judges to actually improve AI’s multilingual writing quality.
What questions did the researchers ask?
They wanted to know:
- How do we define and measure “native-like” quality in different languages and places?
- Can AI models act as fair judges of response quality, like teachers grading essays?
- What judging setup works best: scoring one answer at a time, or comparing two answers side-by-side?
- Can training these AI judges make them better than simple, untrained judges?
- Can these judges also help improve the AI’s writing, not just score it?
How did they do it?
First, they created the Menlo framework, which breaks “native-like” quality into four dimensions. Think of this like a grading rubric teachers use:
- Fluency: Is the language smooth and correct?
- Tone: Does the reply sound appropriate and natural for the situation?
- Localized tone: Does it match the style and culture of a specific place or variety (for example, Mexican Spanish vs. Spanish in Spain)?
- Localized factuality: Are the facts accurate for that local context (names, holidays, laws, places)?
Then they built a dataset:
- They wrote prompt templates in English that clearly define who the audience is (for example, talking to a local group), then translated and localized them for 47 language varieties.
- They asked native speakers to rate two AI-generated responses per prompt on a 1–5 scale (1 is poor, 5 is excellent).
- They used clear, step-by-step rubrics so different annotators would judge the same way. The raters agreed with each other a lot, which is a good sign that the rules were clear.
Next, they tested ways for AI models to judge response quality:
- Pointwise scoring: grade one response by itself.
- Pairwise scoring: grade two responses side-by-side for the same prompt. This is like comparing two essays at once, which makes judging easier.
- With and without rubrics: they checked if giving the AI judges the same grading rules helps.
Finally, they trained AI judges:
- They used reinforcement learning (RL), which is like practicing judging and giving the AI “points” when it judges correctly.
- They shaped the reward, meaning they didn’t only give full points for perfect scores—they also gave partial points when the judge was close and extra points when it picked the better of two answers correctly.
- They tested single-task training (one skill at a time) and multi-task training (learning all four dimensions together).
After that, they used the trained judges to improve an AI writer:
- The judge scores pairs of AI responses so the AI can learn which writing is better.
- They checked improvements using other AI judges and human annotators.
What did they find, and why does it matter?
- Comparing two answers side-by-side (pairwise) works much better than judging one at a time. It helps both simple and advanced models judge more accurately.
- Giving judges clear rubrics also helps, especially when they score one response at a time.
- Training judges with reinforcement learning, shaped rewards, and multi-task learning made them stronger—sometimes close to human-level agreement.
- These trained judges can be used to teach AI models to write better across languages. After training, the improved AI responses were preferred in most cases by both AI judges and humans.
- However, AI judges tend to be more optimistic than humans about how much quality improved. In short, the judges agree that things got better—but they often think the improvement is bigger than human reviewers do.
This matters because good, native-like AI replies help people worldwide use AI more comfortably. It’s not enough for answers to be grammatically correct; they also need to fit local culture, style, and facts.
What does this mean for the future?
- Scalable multilingual evaluation: The Menlo framework and dataset make it easier to judge AI quality across many languages consistently.
- Better AI alignment: Trained judges can guide AI models to produce more fluent, culturally sensitive, and locally accurate responses.
- Practical path forward: Pairwise judging, clear rubrics, and reinforcement learning together form a strong toolkit for improving multilingual AI.
- Remaining challenges: AI judges still don’t perfectly match human judgment, especially on local facts. Future work may combine judges with tools like search or retrieval to handle locally grounded information more reliably.
If you want to explore the dataset, it’s available here: https://huggingface.co/datasets/facebook/menlo
Overall, Menlo shows a clear recipe for making AI chat more truly “native-like” across the world: define what “good” looks like, collect high-quality human ratings, train AI judges to follow those rules, and use those judges to teach AI to write better.
Knowledge Gaps
Below is a concise, action-oriented list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- The four evaluation dimensions (fluency, tone, localized tone, localized factuality) omit key aspects of native-like communication such as pragmatics, politeness strategies, register shifting, idiomaticity, code-switching, dialectal variation within locales, and multi-modal or spoken prosody.
- Menlo focuses on single-turn, long-form responses; native-like quality in multi-turn conversations (e.g., turn-taking, repair, grounding, alignment over time) is not addressed.
- Romanized variants for non-Latin-script languages may distort authenticity; the impact of romanization on perceived “native-like” quality and judge reliability is unexplored.
- Parametric, English-authored templates localized by native speakers may introduce subtle translationese or template-induced style constraints; the effect of prompt templating on naturalness and diversity of language use is not analyzed.
- Locale instantiation (e.g., holidays, entities) is narrow and may not capture the broader range of sociolinguistic audience design phenomena (e.g., intergroup identity marking, slang, in-group humor, indirectness).
- The dataset’s topical coverage and domain breadth are not characterized; it is unclear how well judges generalize across topics (news, technical, humor, health) or genres (narrative vs. expository).
- Only long-form text is evaluated; native-like quality for short-form tasks, mixed-form outputs (lists, tables), and multi-modal contexts remains untested.
- Annotation uses 1–5 Likert ratings aggregated by majority vote, discarding rater heterogeneity and uncertainty; pluralistic alignment and label distribution modeling over multiple valid ratings per item is not explored.
- Cross-language equivalence of rubrics is assumed; there is no analysis of whether rubric criteria are semantically and culturally isomorphic across languages and locales (risk of cross-cultural construct drift).
- The frequency and handling of ties and near-ties are not analyzed; their relation to inter-annotator agreement and preference inference reliability is unclear.
- Expert “gold” labels are used when available and otherwise averaged annotations; the impact of this mixed labeling strategy on judge training and evaluation consistency is not quantified.
- Metrics emphasize Macro-F1 (5-way classification) and preference accuracy inferred from grades; calibration (e.g., ECE, Brier), rank correlation, and reliability under label noise are not evaluated.
- Pairwise evaluation improves results, but listwise (3+ responses) or tournament-style comparisons—potentially stronger anchors—are not tested.
- The source of cross-language performance variance (script, morphology, resource level, typological features, training data exposure) is not investigated; drivers of poor performance in certain locales remain unclear.
- Localized factuality is the weakest dimension; retrieval, search, tool-use, and evidence attribution are suggested but not implemented or evaluated within Menlo’s judge or policy training.
- The study uses responses generated by a limited set of frontier models; generalization of judges to responses from unseen or weaker models, human-written responses, or adversarial/hard negatives is unknown.
- Judges are largely trained and evaluated on the same distribution induced by Menlo prompts; robustness to distribution shift (new prompt styles, domains, and audiences) is not assessed.
- RL judges may learn stylistic caricatures of “native-like quality,” as suggested by overestimation vs. human ratings; concrete methods to calibrate judges to human magnitude of improvement are not presented.
- Chain-of-thought quality and faithfulness of judge reasoning are not evaluated; the extent to which reasoning aligns with rubrics or introduces spurious justifications is unanswered.
- Positional bias mitigation is limited to AB/BA augmentation; no quantitative analysis of residual positional bias or more rigorous debiasing strategies is provided.
- Reward design targets final grades and relative preferences but not reasoning consistency, rubric adherence, or evidence use; richer reward shaping (e.g., rubric-anchored sub-rewards, factual verification) remains unexplored.
- Post-training as generative RM is demonstrated on a single small policy model (Qwen3-4B) and excludes localized factuality; scalability to larger models, other architectures, and all dimensions is untested.
- Human validation covers only 10 high-resource languages; the gap between LLM and human raters for mid/low-resource languages and non-Latin scripts is unknown.
- The absolute magnitude of LLM-judged improvements is systematically higher than human-judged improvements; methods for judge calibration, debiasing, and human-in-the-loop adjustment are not implemented.
- Using judges as reward models invites potential reward hacking; safeguards against policy gaming of rubric-like artifacts and superficial stylistic cues are not studied.
- Cost, latency, and scalability trade-offs of pairwise judging vs. pointwise (and potential listwise) in production settings are not measured.
- The effects of few-shot exemplars in pairwise setups are minimal for one model; the general role of demonstration selection, diversity, and locale-specific exemplars is not explored.
- Cross-lingual transfer is weak when training judges on English-only data; strategies for multilingual curriculum learning, language-adaptive pretraining, or parameter-efficient fine-tuning are not examined.
- Dataset size per language is modest; sample efficiency, data augmentation, and active learning to target underperforming languages or dimensions are not evaluated.
- Ethical and fairness aspects are not analyzed: possible judge biases against certain dialects, orthographies, or culturally marked styles are unaddressed; no fairness or harm audits are reported.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be adopted now, leveraging Menlo’s dataset, framework, and judge training methods.
- Multilingual LLM quality gates for product releases
- Sector: Software, Platform AI
- What: Integrate Menlo-style pairwise judges (e.g., Qwen3-4B-RL-Judge, Llama4-Scout-RL-Judge) into CI/CD to block regressions on fluency, tone, localized tone, and localized factuality across locales.
- Tools/Workflow: Pairwise evaluation template; rubric-guided prompts; locale heatmaps; automated Win/Loss/Tie dashboards; periodic human spot checks.
- Assumptions/Dependencies: Judges overestimate improvements vs humans; require human calibration loops; coverage limited to 47 language varieties.
- Localization QA and cultural tone audits
- Sector: Marketing, Localization, Media
- What: Use Menlo rubrics and audience-design prompts to audit copy for cultural appropriateness (localized tone) and naturalness before launch.
- Tools/Workflow: Parametric prompt templates with locale placeholders; pairwise judge to compare candidate phrasings; reviewer-in-the-loop signoff.
- Assumptions/Dependencies: Localized factuality is harder; consider retrieval support or local SMEs for factual checks.
- Customer support chatbot tuning and monitoring
- Sector: Customer Service, E-commerce, Telecom, Utilities
- What: Post-train support bots with generative reward models (Menlo-trained judges) to improve polite, native-like tone and region-specific phrasing.
- Tools/Workflow: GRPO-based post-training with pairwise scoring; A/B evaluation via LLM judges; human QA on top markets.
- Assumptions/Dependencies: LLM judge optimism; need safety guardrails; ensure locale-specific policy compliance.
- Multilingual instruction-following evaluation for internal models
- Sector: Model Development, MLOps
- What: Replace pointwise scoring with pairwise evaluation to increase reliability when ranking generations during RLHF or DPO data curation.
- Tools/Workflow: Pairwise templates; reward shaping (binary + smoothing + preference bonus); listwise experiments as future enhancement.
- Assumptions/Dependencies: Longer contexts increase latency/cost; positional bias must be mitigated via order augmentation.
- Reference-free translation/localization quality estimation (QE)
- Sector: Localization, Translation Tech
- What: Use judges to rank and filter outputs from MT/LLM systems without human references, focusing on naturalness and localized tone.
- Tools/Workflow: Pairwise judge scoring and preference aggregation; rubric prompts for fluency vs tone vs locale; batch QE pipelines.
- Assumptions/Dependencies: Not a substitute for factual accuracy in regulated content; add retrieval or human review for critical facts.
- Standardized rubric packs and prompt libraries for locale style calibration
- Sector: Content Ops, Education, Enterprise Communications
- What: Deploy Menlo rubrics and audience design templates to guide generation toward native-like style across locales in email, docs, and marketing.
- Tools/Workflow: Template library with placeholders (e.g., [locale_holiday], [locale_nationality]); pre-flight “Style & Tone” checker.
- Assumptions/Dependencies: Rubrics must be adapted for domain-specific tone (legal, medical); norms evolve over time.
- Human annotation operations playbook
- Sector: Data Labeling, Research Ops
- What: Reuse Menlo’s guidelines, screening tests, expert annotator model, and reconciliation workflow to increase IAA on multilingual labeling tasks.
- Tools/Workflow: Custom annotation interface with Likert + preference; language-specific expert feedback; gold-set spot checks.
- Assumptions/Dependencies: Requires native annotators by locale; budget for expert reviews.
- Safety, sensitivity, and reputation risk checks through localized tone
- Sector: Trust & Safety, PR, Policy
- What: Detect culturally insensitive phrasing, inappropriate politeness levels, or register mismatches before publication.
- Tools/Workflow: Pairwise judges focused on tone/localized tone; red-team prompts in local context; escalation to human reviewers.
- Assumptions/Dependencies: Judges are not safety models; combine with toxicity/harms classifiers and legal review.
- Marketing message A/B testing across regions
- Sector: Marketing Tech
- What: Rapidly down-select ad copy variants using pairwise judges that better capture native-like appeal than pointwise scoring.
- Tools/Workflow: Variant generator; pairwise judge re-ranking; human validation on finalists; uplift tracking after deployment.
- Assumptions/Dependencies: Alignment between “native-like tone” and conversion may vary; keep experimental controls.
- Multilingual pedagogy aids and writing assistants
- Sector: Education, Productivity
- What: Writing assistants that critique tone/fluency against Menlo rubrics and suggest locale-appropriate rewrites.
- Tools/Workflow: Inline feedback with rubric references; pairwise candidate comparisons; “why” rationales from judge reasoning.
- Assumptions/Dependencies: Avoid prescriptive monoculture; allow user-configurable style targets.
- Developer tooling for LLMOps
- Sector: Software Tooling
- What: Ship a “MenloJudge” plugin for evaluation pipelines (Hugging Face datasets/models) and a “Native-like Scorecard” CLI.
- Tools/Workflow: HF dataset: facebook/menlo; judge checkpoints; template pack; CI gate; locale performance heatmaps.
- Assumptions/Dependencies: License and data governance; compute costs for pairwise inference.
- Domain adaptation with generative reward models (small models)
- Sector: SMB/On-Device AI
- What: Improve 4–8B models in target locales via post-training with Menlo judges to reach acceptable tone/fluency when large APIs are costly.
- Tools/Workflow: GRPO post-training; 8-rollout sampling; averaging pairwise rewards; periodic human QA on priority markets.
- Assumptions/Dependencies: Gains are real but smaller when validated by humans; monitor for “style caricature.”
Long-Term Applications
Below are applications that are promising but need further research, scaling, or integration work.
- Multilingual AI quality standards and certification
- Sector: Policy, Standards Bodies, Procurement
- What: Institutionalize Menlo-like dimensions and rubrics as acceptance criteria for public-sector AI (e.g., citizen services chatbots).
- Dependencies: Broader language/variant coverage; standardized human calibration; legal/regulatory endorsement.
- Judge-in-the-loop public service agents across locales
- Sector: Government, Healthcare, Social Services
- What: Deploy real-time judges to gate responses for tone and localized factuality before end-user delivery.
- Dependencies: Low-latency inference; robust retrieval for local facts; audit logs; safety and privacy compliance.
- Retrieval-augmented localized factuality judges
- Sector: News, Finance, Health, Travel
- What: Combine Menlo judges with search/knowledge graphs to reliably check locale-specific facts (e.g., holidays, regulations, addresses).
- Dependencies: High-quality, locale-curated KBs; attribution standards; disinformation defenses.
- Dynamic rubric induction and adaptive evaluation
- Sector: Research, Tooling
- What: LLMs generate context-specific rubrics on the fly, narrowing the gap between pairwise and pointwise scoring and reducing human rubric authoring.
- Dependencies: Reliable rubric generation; stability across topics; human calibration workflows.
- Listwise and multi-criteria evaluation for generation ranking
- Sector: Model Training, Recommenders
- What: Extend pairwise to listwise judging to select from many candidates; jointly optimize fluency, tone, localized tone, and factuality.
- Dependencies: Efficient inference; robust aggregation; diminishing returns analysis.
- Personalized audience-design generation
- Sector: Consumer Apps, CRM, Education
- What: Move from locale-level “native-like” to persona-specific style control (age, profession, region), guided by audience-design principles.
- Dependencies: Privacy-preserving personalization; bias/fairness audits; consent management.
- Multilingual fairness and bias audits via tone profiling
- Sector: Trust & Safety, Compliance
- What: Systematically detect uneven politeness/register across demographic groups or dialects; remediate with targeted post-training.
- Dependencies: Representative datasets; sociolinguistic expertise; governance frameworks.
- Language learning and assessment tools
- Sector: EdTech
- What: Use rubric-grounded judges as “native-like” coaches that provide graded feedback on fluency and tone, with localized examples.
- Dependencies: Pedagogical validation; adaptation to CEFR/TOEFL-like scales; explainability standards.
- Regulated communications assistants
- Sector: Finance, Healthcare, Legal
- What: Draft client communications that satisfy local tone expectations and insert required disclaimers/phrasing per jurisdiction.
- Dependencies: Verified localized factuality; compliance approvals; audit trails.
- Voice agents and embodied systems with locale-appropriate pragmatics
- Sector: Robotics, Automotive, Smart Home
- What: Ensure spoken interactions respect local politeness norms and cultural cues; reduce user friction and complaints.
- Dependencies: Prosody and speech synthesis alignment with textual tone; cross-modal evaluation standards.
- Market research at scale across regions
- Sector: Consumer Insights
- What: Simulate and evaluate message resonance in different locales; rapidly iterate on culturally tuned campaigns.
- Dependencies: Correlation between “native-like” metrics and business KPIs; ongoing human panel validation.
- On-device locale-specialized small models
- Sector: Mobile, Edge AI
- What: Ship compact models post-trained with generative RMs to provide offline, native-like interactions in target markets.
- Dependencies: Efficient training/inference; energy constraints; continual learning without drift.
- Expansion to dialects, code-switching, and low-resource languages
- Sector: Global Access, Inclusion
- What: Extend Menlo to more varieties and code-switch contexts; active learning to acquire scarce annotations.
- Dependencies: Native annotator availability; ethical data sourcing; cross-lingual transfer methods beyond English-only.
Cross-Cutting Assumptions and Risks
- Human calibration remains necessary: LLM judges systematically overestimate improvements relative to humans, especially on style “caricature.”
- Localized factuality is the hardest dimension: expect to integrate retrieval, search, and curated local knowledge bases for reliable deployment.
- Cultural norms evolve: rubrics and templates require periodic updates, regional SME input, and versioning of style guidance.
- Compute and latency costs: pairwise/listwise evaluation increases inference budgets; plan for batching, caching, and sampling strategies.
- Bias and coverage: current 47 varieties do not cover all locales or dialects; fairness audits and expansion plans are needed.
- Reward hacking risks: monitor for metric gaming; rotate judges and maintain human-in-the-loop evaluations.
Resources to get started:
- Dataset: facebook/menlo (Hugging Face)
- Building blocks: Menlo pairwise evaluation template, four-dimension rubrics, RL reward shaping (binary + smoothing + preference bonus), GRPO-based training
- Quick wins: Add a pairwise judge gate to your multilingual eval suite; adopt the rubric-guided prompt library for content teams; run a pilot post-training with judge-as-RM on a single priority locale and validate with human raters.
Glossary
- Accommodation: In sociolinguistics, adapting one’s style to align with the interlocutor. "Key mechanisms include accommodation, where speakers adapt their style to the addressee, and referee design, where speakers align with an absent reference group they wish to identify with."
- Audience design: Sociolinguistic principle that speakers tailor language to the audience’s identity and expectations. "Building on mechanisms from audience design \citep{bell1984language}, we propose creating tailored prompts..."
- Chain-of-Thought (CoT) reasoning: Explicit step-by-step reasoning generated before answers or judgments. "For inherently thinking models like Qwen3-4B, SFT without Chain-of-Thought (CoT) reasoning actually hurts performance"
- CoT supervision: Training signals that include Chain-of-Thought rationales to guide reasoning. "This suggests that for tasks requiring reasoning, it is preferable to start RL directly when the SFT target lacks CoT supervision."
- Cross-entropy loss: A standard loss function for classification that measures divergence between predicted and true distributions. "For SFT, models directly predict 5-point grades using cross-entropy loss under teacher forcing"
- Few-shot: Providing a small number of labeled examples in context to guide model behavior. "Few-shot pointwise improves Macro-F1 relative to zero-shot pointwise"
- Frontier API models: The most capable, cutting-edge proprietary models available via APIs. "a multi-task Llama4-Scout model trained with shaped rewards surpasses frontier API models with the strongest overall performance across 47 language varieties"
- Generative reward models (RMs): Models that produce reward signals (often via judgments) to train or improve generative policies. "RL-trained judges can serve as generative reward models to enhance LLMs' multilingual proficiency"
- GRPO: A reinforcement learning algorithm used to optimize policies via relative comparisons. "For RL, we use GRPO \citep{shao2024deepseekmath}"
- In-context examples: Labeled exemplars placed in the prompt to condition model outputs. "The unexpectedly large gains over few-shot in-context examples highlight pairwise evaluation"
- Instruction-tuned: Fine-tuned to follow instructions and align outputs with task directives. "Llama models are instruction-tuned and we omit the Instruct suffix for brevity."
- Inter-annotator agreement (IAA): A measure of consistency among different annotators’ labels. "IAA presents Krippendorffâs~ measuring inter-annotator agreement."
- Krippendorff’s alpha: A reliability coefficient for assessing inter-annotator agreement, accounting for chance. "Krippendorffâs "
- Likert scale: An ordinal rating scale, typically 1–5, used to measure judgments. "Responses are generated using state-of-the-art LLMs and annotated with ratings on a 1--5 Likert scale"
- Listwise evaluation: Assessing multiple candidates at once to determine relative quality across a set. "Future work may investigate whether extending pairwise comparisons to a listwise evaluation of multiple responses offers additional benefits."
- LLM judge: A LLM used to evaluate or grade the quality of other model outputs. "We thus evaluate the ability of LLMs to serve as judges of native-like quality responses."
- Macro-F1: The F1 score averaged over classes, treating each class equally. "Macro-F1 shows 5-way classification performance"
- Majority vote: Aggregating multiple annotations by selecting the label with the most votes. "with final scores aggregated via majority vote."
- Mixture-of-Experts: An architecture that routes inputs to specialized sub-models (“experts”). "Llama4-Scout (Mixture-of-Experts, non-reasoning)"
- Parametric prompt templates: Structured prompts with placeholders that are instantiated for specific contexts. "human-written parametric English prompt templates"
- Pairwise evaluation: Scoring two responses side-by-side for the same prompt. "pairwise evaluation---where models predict scores for two responses simultaneously (without explicitly predicting preference)---significantly outperforms its pointwise counterpart."
- Pairwise RL training: Reinforcement learning that uses pairwise comparisons to shape rewards and policies. "This demonstrates the promise of pairwise RL training across model families, scales, and reasoning capabilities."
- Pluralistic alignment: Modeling and aligning to diverse, potentially conflicting human preferences. "Multiple annotations can be used in future work on pluralistic alignment \citep{sorensen2024roadmap}."
- Policy model: The generative model being optimized via reinforcement learning. "to directly improve a policy model's proficiency."
- Pointwise evaluation: Scoring a single response independently of alternatives. "pointwise evaluation is in principle sufficient: a model could assign absolute scores to individual responses without needing comparisons."
- Positional bias: Systematic preference related to the ordering of presented options. "to mitigate positional bias."
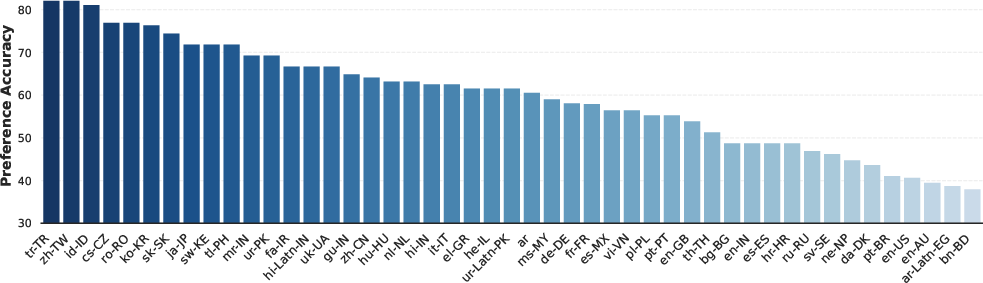
- Preference accuracy: Accuracy computed over Win/Loss/Tie outcomes derived from assigned scores. "Preference accuracy over Win/Loss/Tie outcomes."
- Preference alignment: Training to make model outputs align with human or target audience preferences. "Our findings suggest promising directions for scalable multilingual evaluation and preference alignment."
- Preference bonus: An added reward component for correctly matching the relative ordering of two items. "Preference bonus: additional if the sign of the difference between the two predicted scores matches the label."
- Referee design: Aligning style with an absent group the speaker identifies with. "referee design, where speakers align with an absent reference group they wish to identify with."
- Reinforcement learning (RL): Optimizing behavior via rewards from interactions or evaluations. "We demonstrate substantial improvements through fine-tuning with reinforcement learning, reward shaping, and multi-task learning approaches."
- Retrieval: Using external information sources to ground or verify content. "such as incorporating retrieval, search, or external tool use, may be necessary."
- Reward shaping: Modifying reward signals to guide learning more effectively. "we show that multi-task RL and reward shaping enables fine-tuning a judge that is on par with human annotators in 47 language varieties."
- Reward smoothing: Granting partial reward for near-correct predictions to stabilize training. "Reward smoothing: partial reward () if the prediction differs by exactly one grade."
- Romanized: Writing non-Latin script languages using Latin characters. "romanized versions of non-Latin script languages"
- Style Axiom: A sociolinguistic principle linking intraspeaker style variation to social variation. "the Style Axiom \citep{bell1984language} states that intraspeaker variation (style) reflects interspeaker variation (social)."
- Supervised fine-tuning (SFT): Training a model on labeled data to improve task performance. "We compare supervised fine-tuning (SFT) and reinforcement learning (RL)"
- Teacher forcing: Training method where the model is fed gold outputs to condition its next-step predictions. "using cross-entropy loss under teacher forcing"
- Typologically diverse: Spanning languages with different structural characteristics. "representing a typologically diverse set of widely used languages"
- Zero-shot: Using a model without task-specific training examples. "We find that in zero-shot setting, pairwise evaluation---where models predict scores for two responses simultaneously (without explicitly predicting preference)---significantly outperforms its pointwise counterpart."
Collections
Sign up for free to add this paper to one or more collections.

