MapCoder-Lite: Squeezing Multi-Agent Coding into a Single Small LLM
Abstract: LLMs have advanced code generation from single-function tasks to competitive-programming problems, but existing multi-agent solutions either rely on costly large-scale ($>$ 30B) models or collapse when downsized to small open-source models. We present MapCoder-Lite, which upgrades a single 7B model into four role-specialised agents-retriever, planner, coder, and debugger-using only rank-32, role-specific LoRA adapters ($<3\%$ extra parameters). Three lightweight techniques make this possible: (i) trajectory distillation from strong LLMs fixes format fragility in retrieval and debugging, (ii) supervisor-guided correction strengthens planning and coding agents, and (iii) agent-wise LoRA fine-tuning delivers memory-efficient specialisation. Comprehensive evaluation on xCodeEval, APPS, and CodeContests shows that MapCoder-Lite more than doubles xCodeEval accuracy (from $13.2\%$ to $28.3\%$), eliminates all format failures, and closes to within six points of a 32B baseline while cutting GPU memory and token-generation time by $4\times$. These results demonstrate that careful agent-wise fine-tuning unleashes high-quality multi-agent coding on a small LLM.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a small AI model to write and fix computer programs for tough “competitive programming” problems. Instead of using one huge, expensive model, the authors show how to turn one small model into a smart “team” of four helpers—Retriever, Planner, Coder, and Debugger—by adding tiny plug-ins. Their approach makes the small model much more reliable and almost as good as a much larger model, while being faster and cheaper to run.
What questions does it try to answer?
The paper focuses on three simple questions:
- Can a small AI model solve hard coding problems if it acts like a team with different roles?
- How can we make each role (finding ideas, planning, coding, debugging) work well without using a huge model?
- Can we cut memory use and speed up generation while keeping accuracy high?
How did the researchers do it?
The authors start with one 7-billion-parameter LLM (think of it as a “small” model compared to giants). Then they give it four “hats” (roles): Retriever, Planner, Coder, and Debugger. Each hat is a small add-on that gently nudges the model to behave like a specialist.
A team of four roles in one small model
- Retriever: Looks up useful algorithm ideas (like searching a textbook).
- Planner: Lays out step-by-step instructions to solve the problem.
- Coder: Writes the actual program.
- Debugger: Runs tests and fixes mistakes until the code passes.
All four roles share the same brain (the same small model), but each role has its own tiny adapter that changes how the model thinks for that job.
Three simple tricks that make it work
The researchers use three lightweight ideas. Here’s what they mean in everyday terms:
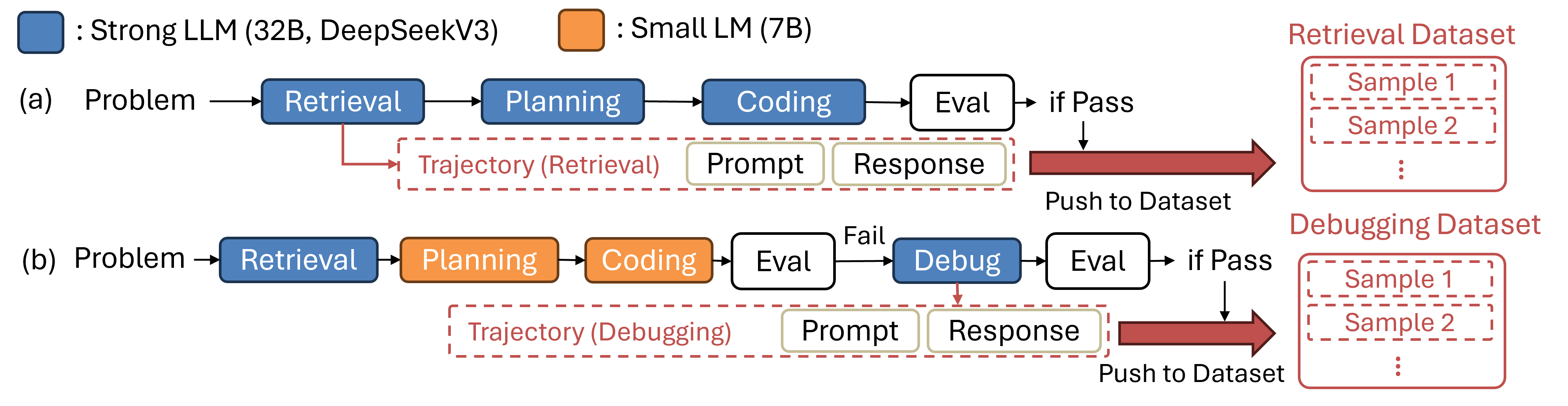
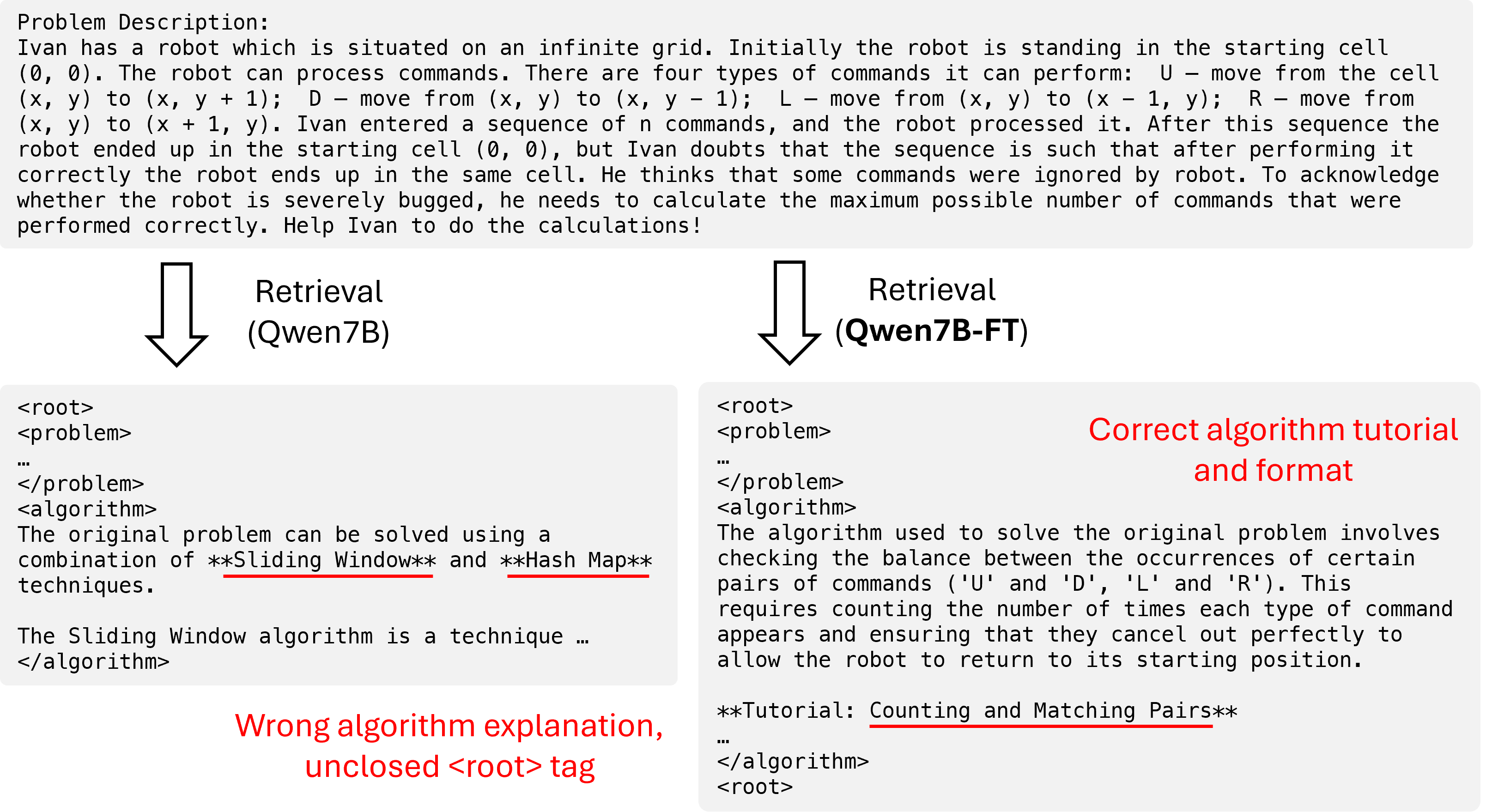
- Trajectory distillation: Imagine a top student solves a problem and shows every step of their thinking. The small model studies these “solution paths” (called trajectories) for two hard roles—Retrieval and Debugging. Importantly, they only keep examples where the final code passes tests. That way, the small model learns from correct, complete solutions.
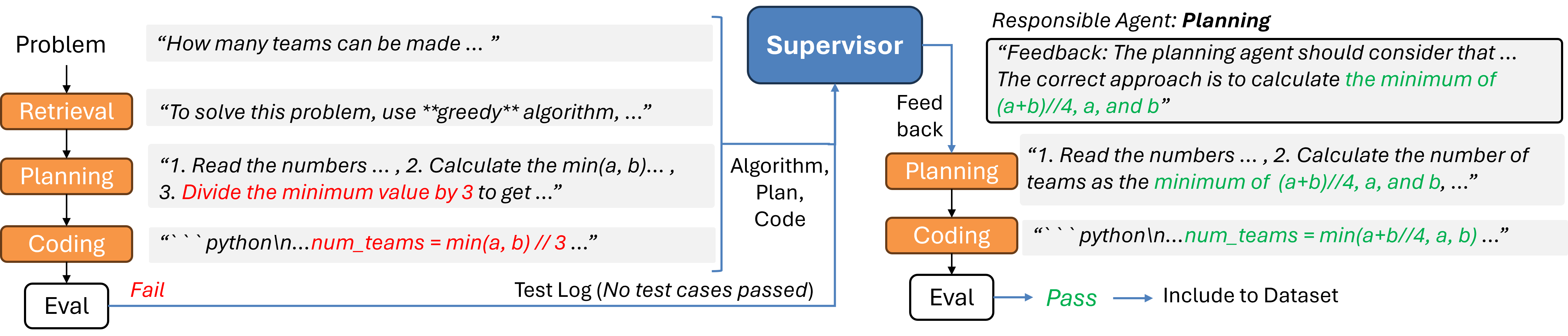
- Supervisor-guided correction: When the small model’s Plan or Code fails hidden tests, a stronger “supervisor” model points out what went wrong (like a teacher marking the exact mistake). The small model then tries again and saves only the corrected, working examples. Over time, it learns stronger planning and coding skills.
- LoRA adapters: Instead of retraining the whole model, they attach tiny plug-ins (LoRA adapters) for each role. Think of them as small “settings” files or hats the model wears to specialize. These add less than 3% extra parameters, so memory use stays low.
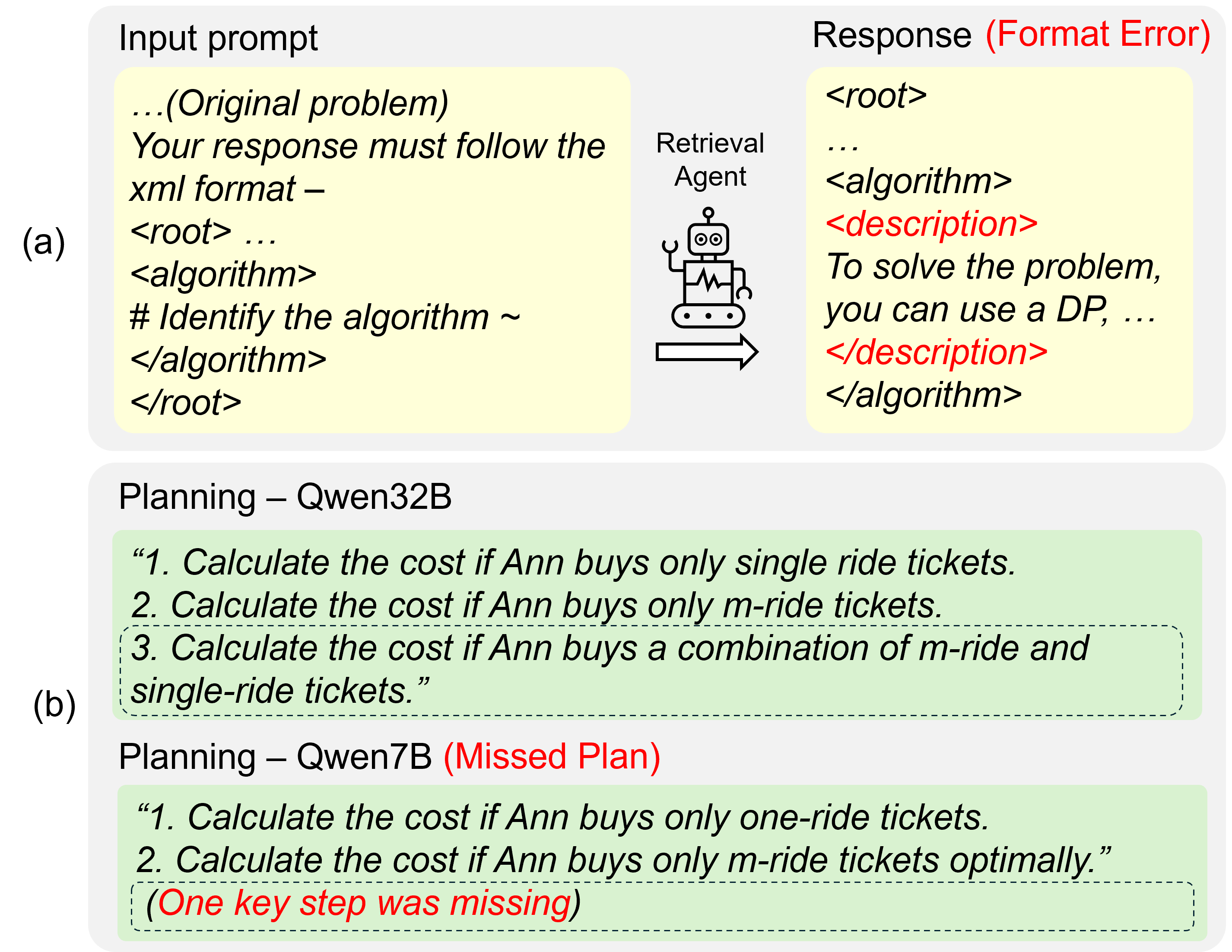
They also fix a common problem: the system needs strict, structured outputs (like filling a form correctly, often in XML). Small models often mess up the format (missing tags, extra text), which breaks the pipeline. By learning from clean, passing examples, the small model stops making these format mistakes.
What did they find?
Here are the key results, in simple terms:
- Big accuracy jump with a small model: On a tough benchmark (xCodeEval), accuracy more than doubled—from about 13% to 28%—after using their method.
- Zero format failures: The small model stopped breaking the required output format, which kept the whole pipeline running smoothly.
- Close to a much larger model: The improved small model got within about 6 percentage points of a strong 32-billion-parameter system.
- Much cheaper and faster: The new setup used about 4× less GPU memory and generated text about 4× faster per token. That’s a big deal for cost and speed.
They also showed steady gains on other benchmarks like APPS and CodeContests, and the method worked well even on simpler tasks (like HumanEval and MBPP).
Why does this matter?
- Lower cost, wider access: You can get high-quality code generation without needing huge, expensive models. This makes advanced AI tools more accessible to schools, startups, and hobbyists.
- More reliable pipelines: By eliminating format errors and improving each role, the overall system becomes more dependable.
- Reusable idea: The “small model + tiny role adapters” approach could be applied to other multi-step tasks beyond coding (like research workflows or data analysis).
Limitations and future possibilities
- Still needs big models for training data: The small model learns from examples created or checked by strong models. Reducing this dependency would be even better.
- Not yet beating the largest models: There’s still a gap, but the results show small models can get surprisingly close with the right training tricks.
Overall, the paper shows a practical way to get strong, team-like problem solving from a single small AI model—by giving it smart, tiny role adapters and training it on high-quality, tested examples.
Knowledge Gaps
Below is a focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is phrased to enable concrete follow-up work.
- End-to-end efficiency: The paper reports per-token speedups and memory use but does not provide full pipeline comparisons (forward-pass counts, wall-clock runtime, energy) for MapCoder-Lite vs 32B MapCoder across benchmarks. Measure and report end-to-end cost and throughput under identical orchestration.
- Multi-language coverage: While benchmarks like xCodeEval are multilingual, the paper does not analyze performance by programming language (e.g., Python vs C++). Evaluate per-language accuracy, format adherence, and debugging efficacy, and study whether role-specific LoRA needs language conditioning.
- Real-world contest generalization: Results are limited to APPS, CodeContests, and xCodeEval. Assess performance in live competitive settings (e.g., Codeforces/Gym), including interactive problems and stricter judge constraints (TLE/MLE/WA).
- Algorithmic efficiency: Passing unit tests does not guarantee time/memory efficiency. Add evaluations for asymptotic complexity, runtime on large inputs, and memory peaks; incorporate efficiency-aware training or constraints during planning/coding.
- Reliance on proprietary strong models: Trajectory distillation and supervision depend on DeepSeek-V3/Qwen-32B. Explore self-play, smaller teacher ensembles, open-source teachers, or teacher-free RL to reduce dependency and quantify accuracy vs teacher size.
- Data contamination and test leakage: Large teachers may have prior exposure to benchmark problems. Audit contamination, adopt contamination-free splits, and report performance on newly curated, unseen problem sets.
- Pass-based filtering bias: Keeping only trajectories that pass unit tests may bias training toward “easy” or certain problem types. Quantify the distributional shift, and investigate learning from hard/failing trajectories via contrastive, curriculum, or error-annotated training.
- Supervisor attribution accuracy: The supervisor decides which agent caused failure, but misattribution is unstudied. Evaluate attribution accuracy with human labels and study how misattributions affect downstream fine-tuning.
- Learning from rationales: The method discards supervisor feedback texts after data generation. Compare storing and training on feedback/rationales versus outputs-only to test whether rationale distillation improves planning/coding.
- Confidence calibration: Plans include confidence scores, but no calibration analysis exists. Measure calibration (e.g., ECE) and study whether calibrated confidence improves plan ranking and overall success.
- Structured decoding vs fine-tuning: Format failures are eliminated via fine-tuning; constrained decoding (XML/JSON schemas, regex) is not evaluated. Compare constrained decoding, structure-aware decoders, and grammar-based generation against fine-tuning for format reliability.
- LoRA design space: Only rank-32 LoRA on attention projections is explored. Analyze sensitivity to rank, target modules (MLP, embeddings), adapter composition, and multi-query attention, and report accuracy-efficiency trade-offs.
- LoRA interference and adapter management: Four role-specific LoRAs share a frozen backbone, but cross-adapter interference and merging strategies are unexplored. Study adapter stacking, composition, and co-training to improve cross-agent consistency.
- Quantization and deployment: Inference-time quantization (e.g., 4/8-bit, AWQ/GPTQ) is not assessed with role-specific LoRAs. Evaluate accuracy-memory-speed trade-offs under quantization and edge-device deployment constraints.
- Sampling strategies: All evaluations use greedy decoding. Test top-k/nucleus sampling or self-consistency at specific agents (planning/coding) to quantify diversity-accuracy gains and potential format drift risks.
- Dynamic orchestration: The pipeline is static. Investigate adaptive agent invocation, early exit criteria, and routing policies (e.g., skip debugging for high-confidence plans) to reduce cost while maintaining accuracy.
- Test generation and coverage: Debugging relies on benchmark tests; automatic test generation and coverage estimation are not explored. Integrate test synthesis, fuzzing, and coverage metrics to strengthen debugging and reduce overfitting to provided tests.
- Failure taxonomy: The paper offers qualitative cases but no quantitative taxonomy per agent (retrieval/planning/coding/debugging). Build a structured error taxonomy and report per-category rates to target training data collection and agent objectives.
- Negative-data utilization: Failing trajectories are discarded. Explore negative/contrastive signals, counterexamples, and pairwise preference training (e.g., DPO/IPO) using fail vs pass to sharpen agent decision boundaries.
- Generalization to other small LLMs: Results focus on Qwen2.5-7B; limited tests on Qwen2.5-Coder-7B suggest weaker reasoning. Systematically evaluate cross-backbone generality (LLaMA, Mistral, Gemma) and identify backbone traits predictive of multi-agent success.
- Debugging strategies: The debugger patches code iteratively but strategy selection (e.g., static analysis, differential testing, semantic invariants) is not compared. Benchmark alternative debugging techniques and hybrid tool-LLM approaches.
- Retrieval corpus transparency: The retrieval agent references a “private corpus” without details on content, coverage, or licensing. Release or describe the corpus, measure retrieval recall/precision, and study how corpus composition affects performance.
- Context length and long problems: Competitive problems can be long. Evaluate sensitivity to context length, truncation effects, and benefits of retrieval-augmented context management (chunking, memory modules).
- Joint end-to-end training: Agents are fine-tuned separately. Explore multi-agent co-training, shared objectives (pass@1 reward), and RL from execution to directly optimize end-to-end success while maintaining modularity.
- Robustness to adversarial/ambiguous prompts: No stress testing against adversarially written or ambiguous statements. Conduct robustness evaluations and develop prompt-normalization or semantic parsing stages to mitigate ambiguity.
- Reproducibility and release: Availability of datasets (filtered trajectories), code, prompts, and LoRA weights is unspecified. Release artifacts and provide detailed data-generation recipes to enable replication and fair comparison.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging MapCoder-Lite’s 7B multi-agent framework with role-specific LoRA adapters, trajectory distillation, and supervisor-guided refinement.
- Bold: Privacy-preserving, on-premise code assistant for enterprise software teams
- Sector: Software, Enterprise IT, Compliance
- Description: Deploy the 7B-based multi-agent pipeline (retriever → planner → coder → debugger) locally to generate, test, and patch code without sending proprietary source to external APIs, while maintaining reliability via structured XML outputs and pass-based verification.
- Potential tools/products/workflows:
- VSCode/JetBrains plugin that invokes the four agents per task with schema validation
- GitHub Actions/GitLab CI plugin that automatically runs the debugger agent on failing unit tests
- Containerized MapCoder-Lite service with vLLM for low-latency inference on A100/consumer GPUs
- Assumptions/dependencies:
- Adequate unit tests and build environment for supported languages
- Access to Qwen2.5-7B-Instruct and role-specific LoRA weights
- Curated internal algorithm retrieval corpus consistent with the XML schema
- Bold: Cost and energy reduction in LLM-enabled coding workflows
- Sector: Energy, IT Ops, Finance (Cost Management)
- Description: Replace ≥30B agentic coding systems with MapCoder-Lite to cut GPU memory and token-generation time by about 4× while preserving reliability (zero format failures) and improving task accuracy over naïve 7B prompting.
- Potential tools/products/workflows:
- Cost dashboards comparing 7B vs 32B pipelines (TPOT, memory usage, pass@1)
- Procurement playbooks recommending small-model deployment for coding tasks
- Assumptions/dependencies:
- Acceptance of slightly lower performance vs 32B models for certain edge cases
- Workload alignment to competitive-programming-like tasks or well-tested codebases
- Bold: Automated debugging agent for continuous integration
- Sector: Software, DevOps/QA
- Description: Trigger the debugger agent upon CI failures to propose minimal patches that pass unit tests; escalate to human review if fixes touch critical modules.
- Potential tools/products/workflows:
- “Agentic Test Fixer” CI step that compiles, runs tests, and applies patch suggestions
- Jira/GitHub issue auto-triage with responsible-agent tagging (retrieval/planning/coding/debugging)
- Assumptions/dependencies:
- High-quality unit/integration tests; compilation environment in CI
- Policy guardrails for auto-patching and secure code review
- Bold: Programming education tutor with stepwise plans and structured feedback
- Sector: Education
- Description: Use the planning and coding agents to generate pedagogical solution outlines, then run the debugging loop to demonstrate iterative problem solving; students see reliable XML-structured explanations and corrections.
- Potential tools/products/workflows:
- LMS plugin that auto-evaluates student submissions and generates agentic hints
- Auto-graded labs where the tutor provides a plan-to-code walkthrough with pass/fail feedback
- Assumptions/dependencies:
- Datasets of course problems with unit tests
- Instructor-defined schema and guardrails to prevent over-reliance or code leakage
- Bold: Structured-output enforcement library for multi-agent workflows
- Sector: Software (general multi-agent systems), Data Engineering
- Description: Adopt MapCoder-Lite’s format-conformance techniques (trajectory distillation, pass-based filtering) to eliminate schema violations in multi-agent pipelines beyond coding (e.g., XML/JSON output for downstream parsers).
- Potential tools/products/workflows:
- “Structured Output Enforcer” middleware validating agent responses against schemas
- Role-wise LoRA adapters for format fidelity under small-model constraints
- Assumptions/dependencies:
- Well-defined schemas, test or verification harness for downstream tasks
- Access to strong-model traces during adapter training or equivalent curated data
- Bold: Local generation of ETL scripts, SQL, and analysis notebooks within regulated environments
- Sector: Healthcare, Finance, Government
- Description: Use the coder and debugger agents to generate and refine data manipulation scripts without exposing sensitive datasets to cloud services; rely on pass-based tests for correctness.
- Potential tools/products/workflows:
- Connectors to secure databases with synthetic or masked test cases
- Compliance wrappers that log agent actions for auditability
- Assumptions/dependencies:
- Domain-adapted retrieval corpora and tests (SQL queries, ETL validations)
- Policy approval for local LLM use and audited agent operations
- Bold: Startup and SME-friendly prototyping of algorithmic solutions
- Sector: Software, IoT/Embedded
- Description: Rapidly create and iterate on algorithm-heavy components (parsers, scheduling, data structures) using a single GPU/CPU workstation, leveraging specialized 7B agents for planning and debugging.
- Potential tools/products/workflows:
- “LoRA Pack Manager” to swap in sector-specific role adapters
- On-device code generation for microservices and edge applications
- Assumptions/dependencies:
- Minimal hardware (≈16 GB GPU recommended) and Linux build environment
- Domain corpora for retrieval agent and language/toolchain support
- Bold: Open-source pipeline for role-specific dataset creation and fine-tuning
- Sector: Academia, Open-Source
- Description: Reproduce MapCoder-Lite’s supervisor-guided, pass-filtered trajectory collection to build high-quality corpora for retrieval, planning, coding, and debugging.
- Potential tools/products/workflows:
- PEFT-based training scripts and example trajectories
- Benchmarks and reproducible evaluation harnesses (xCodeEval, APPS, CodeContests)
- Assumptions/dependencies:
- Access to strong LLMs or high-quality human/automated traces for initial data collection
- Clear licensing for datasets and integration with execution engines
Long-Term Applications
The following applications require more research, scaling, domain adaptation, or productization to reach production-grade maturity.
- Bold: Cross-domain multi-agent small-model systems for complex tasks
- Sector: Robotics, Process Automation
- Description: Extend the role-specialization paradigm (retrieval → planning → coding → debugging) to robotic skills: retrieve control strategies, plan task sequences, generate controller code, and debug via simulation or hardware-in-the-loop.
- Potential tools/products/workflows:
- Simulator-integrated agent pipelines (Gazebo/Webots) with auto-patching loops
- Skill libraries as retrieval corpora and LoRA adapters per role
- Assumptions/dependencies:
- High-fidelity simulators, safety validation protocols, reliable trajectories for training
- Strong general reasoning or improved planning objectives beyond coding domains
- Bold: Autonomous software maintenance at scale
- Sector: Software, DevSecOps
- Description: Continuous agentic triage and patching of large repositories (lint, refactor, fix flakiness, retire dead code), with human-in-the-loop approvals and progressive rollout.
- Potential tools/products/workflows:
- Repository-wide agent orchestrators with code search and test generation
- Risk-aware patch synthesis integrated with SAST/DAST and policy gates
- Assumptions/dependencies:
- Robust test coverage and traceability; scalable code indexing; improved debugging and planning for edge cases
- Governance frameworks and rollback strategies
- Bold: Policy and standards for structured agent outputs and small-model deployment
- Sector: Public Policy, Standards Bodies, Sustainability
- Description: Formalize guidelines to prefer auditable, on-prem small models with enforced schemas (XML/JSON) to reduce environmental impact and vendor lock-in.
- Potential tools/products/workflows:
- Model procurement standards referencing pass@1, TPOT, memory usage, and format failure metrics
- Environmental impact calculators for LLM operations
- Assumptions/dependencies:
- Broad community benchmarks and transparent reporting
- Cross-industry consensus on schema and evaluation practices
- Bold: Offline programming education in low-resource settings
- Sector: Education, Public Sector
- Description: Distribute pre-packaged laptops with MapCoder-Lite and localized curricula for schools without reliable internet, enabling interactive, test-driven learning.
- Potential tools/products/workflows:
- Language-localized adapters and datasets, teacher training materials
- USB-based distribution of execution engines and problem sets
- Assumptions/dependencies:
- Multilingual support (programming and natural languages), culturally adapted content
- Maintenance and updates over intermittent connectivity
- Bold: Domain-specific coder adapters for regulated verticals
- Sector: Healthcare (clinical data pipelines), Finance (risk modeling), Embedded/IoT (firmware)
- Description: Train role-specific LoRA adapters on curated, domain-validated trajectories to generate reliable, regulation-aware code.
- Potential tools/products/workflows:
- Retrieval corpora of standards and best practices (HIPAA, IFRS, MISRA-C)
- Safety/Compliance validators integrated into the debugging loop
- Assumptions/dependencies:
- Access to domain datasets and expert-curated tests; regulatory approvals
- Additional alignment objectives and guardrails
- Bold: Native multi-agent orchestration in mainstream IDEs
- Sector: Software Tooling
- Description: Productize MapCoder-Lite workflows inside IDEs with persistent agent panes and telemetry on plan quality, code correctness, and debugging effectiveness.
- Potential tools/products/workflows:
- Built-in schema validators and per-role adapters; UX for branching plans and backtracking
- Assumptions/dependencies:
- Vendor collaboration, extensibility APIs, user study-driven UX refinement
- Bold: Edge deployment for autonomous devices and smart infrastructure
- Sector: Energy, IoT/Smart Cities
- Description: Use compact agents to author scripts for sensors, gateways, and automation controllers directly on devices (Jetson/Orin), enabling local adaptation and maintenance.
- Potential tools/products/workflows:
- On-device inference runtimes, battery-aware scheduling, hardware-accelerated decoding
- Assumptions/dependencies:
- Efficient runtimes, safety and reliability guarantees, secure update channels
- Bold: Agentic scientific computing workflows
- Sector: Academia, R&D
- Description: Generate reproducible analysis code, verify against unit tests, and auto-correct pipelines across data wrangling, simulation, and plotting.
- Potential tools/products/workflows:
- “Repro Lab Notebooks” integrating agent planning/coding/debugging with versioned datasets
- Assumptions/dependencies:
- High-quality tests and metadata; domain-specific retrieval corpora; mitigation of capacity gaps in complex reasoning
- Bold: Multilingual expansion for programming languages and natural languages
- Sector: Global Software Development
- Description: Extend adapters per programming language and locale to support multilingual codebases and documentation.
- Potential tools/products/workflows:
- Multilingual execution engines and per-language adapters, schema-localization kits
- Assumptions/dependencies:
- Per-language unit-test infrastructure and datasets; consistent schema enforcement across locales
- Bold: Automated vulnerability patching
- Sector: Security
- Description: Train debugging and coding agents with security-focused trajectories to propose CVE-aware patches that pass security tests and functional unit tests.
- Potential tools/products/workflows:
- Integration with SAST/DAST, exploit simulators, and secure coding checklists in the retrieval corpus
- Assumptions/dependencies:
- High-quality security datasets, rigorous human review, compliance with organizational risk policies
Notes on cross-cutting assumptions and dependencies:
- Unit-test availability is a primary enabler; pass-based filtering and debugging loops depend on executable verification.
- Access to strong LLMs (or high-quality traces) during training boosts adapter quality; inference remains light-weight with the 7B backbone.
- Reliability in unseen domains may require domain-specific retrieval corpora, language/toolchain support, and tailored objectives (e.g., safety, compliance).
- While MapCoder-Lite eliminates format failures and narrows the performance gap to 32B models, some complex tasks still benefit from larger backbones; acceptance criteria should reflect risk tolerance and task criticality.
Glossary
- Agent-wise fine-tuning: Fine-tuning each agent within a multi-agent system separately to specialize its behavior while sharing a common base model. "agent-wise LoRA fine-tuning delivers memory-efficient specialisation."
- Analogical prompting: A prompting strategy that guides models by providing analogous examples to the target task. "analogical prompting~\cite{yasunaga2024analogical}"
- Backbone: The shared base LLM that multiple role-specific adapters attach to in a multi-agent system. "All agents share a frozen Qwen-2.5-7B backbone"
- Capacity gap: The performance gap arising from the limited capacity of a smaller model compared to a larger one, impacting its ability to learn complex behaviors. "phenomenon called capacity gap~\cite{bansal2024smallerweakerbettertraining, xu2025speculativeknowledgedistillation}"
- Chain-of-thought (CoT): A prompting technique that elicits step-by-step reasoning from the model. "chain-of-thought (CoT)~\cite{wei2023chainofthought}"
- Confidence score: A numeric estimate of how likely a plan or output is correct, used to rank alternatives. "a confidence score is generated for each plan using XML format."
- Debugging agent: The agent that compiles, runs, and patches generated code iteratively to pass tests. "the debugging agent iteratively refines the code based on test outcomes."
- Execution tests: Automated runs of generated code to verify correctness and filter training data. "filtered through execution tests to ensure format correctness and semantic accuracy."
- Full fine-tuning (FFT): Updating all parameters of a model during training rather than using lightweight adapters. "full fine-tuning (FFT)"
- Greedy decoding: A generation method that selects the highest-probability token at each step without sampling. "All outputs are generated using greedy decoding"
- LoRA (Low-Rank Adaptation): A parameter-efficient technique that adds trainable low-rank adapters to a frozen model for specialization. "low-rank adapters (LoRA~\cite{hu2021lora})"
- Memory-bound: A regime where performance is limited by memory bandwidth rather than compute, common in LLM decoding. "LLM decoding being memory-bound"
- Monolithic prompting: Using a single prompt with one model to solve the entire task without modular roles or stages. "monolithic prompting"
- Multi-agent code-generation framework: A system where multiple specialized LLM agents collaborate to solve coding tasks through distinct roles and stages. "multi-agent code-generation frameworks"
- Parameter budget inflation: The increase in total parameter storage when fine-tuning multiple agents independently, undermining efficiency gains. "Parameter budget inflation: Even if fine-tuning recovers agent-specific capability, storing four independent 7B checkpoints nullifies memory savings, approaching the original 32B footprint."
- PEFT (Parameter-Efficient Fine-Tuning): Methods that adapt large models with a small number of additional trainable parameters. "PEFT libraries~\cite{huggingfacepeft}"
- Pass@1: The metric measuring whether the model’s top-1 output passes all test cases. "Pass@1 accuracy (\%)"
- Pass-based filtering: Keeping only trajectories whose final programs pass tests to create high-quality training data. "This passâbased filtering eliminates noisy or partially correct traces"
- Retrieval agent: The agent that fetches relevant algorithmic knowledge or references to guide later stages. "the retrieval agent fetches relevant algorithmic knowledge"
- Self-planning: A prompting strategy where the model generates its own plan before coding. "self-planning~\cite{jiang2024selfplanning}"
- Supervisor-guided refinement: A data-collection pipeline where a stronger model analyzes failures and guides targeted corrections for training. "We propose a supervisor-guided refinement pipeline"
- Supervisor model: A high-capacity model used offline to diagnose failures and provide role-specific feedback for data generation. "we employ a supervisor model that identifies failures, provides targeted feedback, and regenerates problematic steps"
- Time Per Output Token (TPOT): A latency metric for decoding speed, measuring time taken per generated token. "Time Per Output Tokens (ms)"
- Trajectory distillation: Training smaller agents using intermediate artifacts and solutions produced by stronger models. "Trajectory distillation from strong LLMs"
- vLLM: A high-throughput LLM inference engine used to measure decoding performance. "as measured using vLLM~\cite{kwon2023efficientmemorymanagementlarge}"
- XML-formatted responses: Structured outputs constrained by an XML schema to ensure machine-readable coordination across agents. "XML-formatted responses with tags like <root>, <algorithm> and <confidence>."
- XML schema: The structural rules that specify valid XML tags and organization for agent communication. "XML schema violations"
Collections
Sign up for free to add this paper to one or more collections.

