- The paper introduces a multi-stage pipeline combining knowledge graph filtering, enriched JSDoc indexing, and LLM query expansion that enhances API retrieval accuracy.
- It demonstrates an 87.86% top-40 accuracy through hypothetical code generation, outperforming traditional BM25 methods.
- Post-training optimization using SFT and reinforcement learning yields a compact 0.6B reranker achieving 68.58% top-5 accuracy with reduced latency.
DeepCodeSeek: Real-Time API Retrieval for Context-Aware Code Generation
Introduction and Motivation
DeepCodeSeek addresses the challenge of context-aware API retrieval for code generation in enterprise environments, specifically targeting ServiceNow's Script Includes—reusable JavaScript components encapsulating business logic. The core problem is inferring developer intent from partial code and retrieving the correct Script Include without explicit queries. Existing approaches, such as keyword search and generic dense retrieval, fail to capture nuanced intent and hierarchical relationships, especially in domains with custom APIs and sparse documentation. DeepCodeSeek introduces a multi-stage retrieval pipeline that leverages platform metadata, enriched indexing, LLM-powered query expansion, and compact reranking to maximize retrieval accuracy and enable real-time code completion.
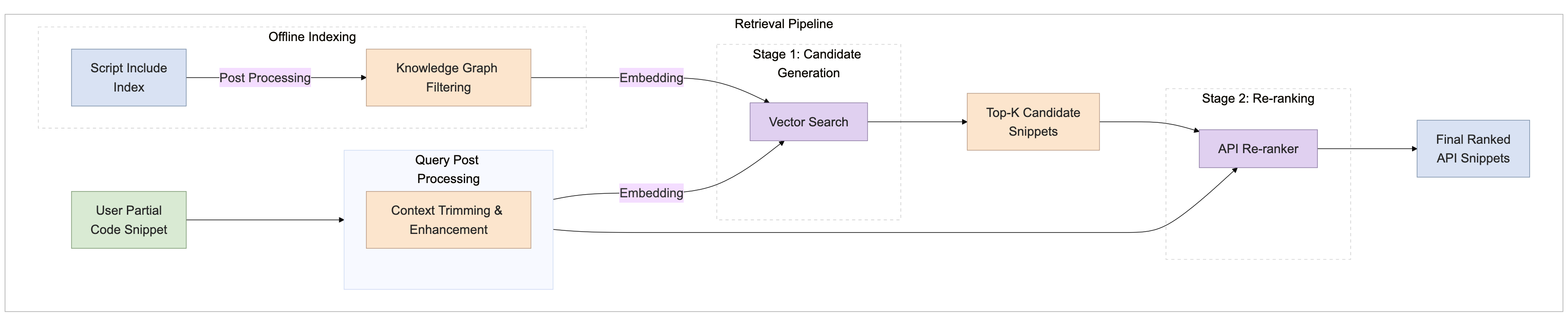
Figure 1: Overview of the proposed multi-stage retrieval pipeline.
Multi-Stage Retrieval Pipeline
The pipeline consists of several key components:
- Knowledge Graph Filtering: A hierarchical knowledge graph constructed from ServiceNow metadata prunes the search space by leveraging package, scope, and Script Include relationships. This reduces candidate APIs by 59% prior to expensive retrieval operations, improving both efficiency and relevance.
- Enriched Indexing: Instead of raw code, the index groups methods under their parent namespace and augments them with structured JSDoc documentation and API usage examples. This organization provides a cleaner signal for embedding models and reduces ambiguity.
- LLM-Powered Code Expansion: Partial code often lacks sufficient context for effective retrieval. At runtime, an LLM generates hypothetical code completions or natural language intent descriptions, enhancing the query and improving downstream retrieval accuracy.
- Reranking: Initial retrieval may surface the correct Script Include but not at the top. A cross-encoder or LLM reranker reorders candidates, moving relevant APIs into the top-K (e.g., top-5), which is critical for downstream code generation.
- Post-Training Optimization: Compact reranker models (Qwen 0.6B) are optimized via synthetic dataset generation, supervised fine-tuning (SFT), and reinforcement learning (RL), achieving performance comparable to much larger models (Qwen 8B) with 2.5x reduced latency.
Dataset and Index Construction
A custom evaluation dataset was constructed from 850 real-world ServiceNow code completion scenarios, each containing partial code and the ground-truth Script Include. The dataset is designed to be challenging: the prefix omits the target API, and the suffix adds extra lines without exposing it, requiring the model to infer intent from context.
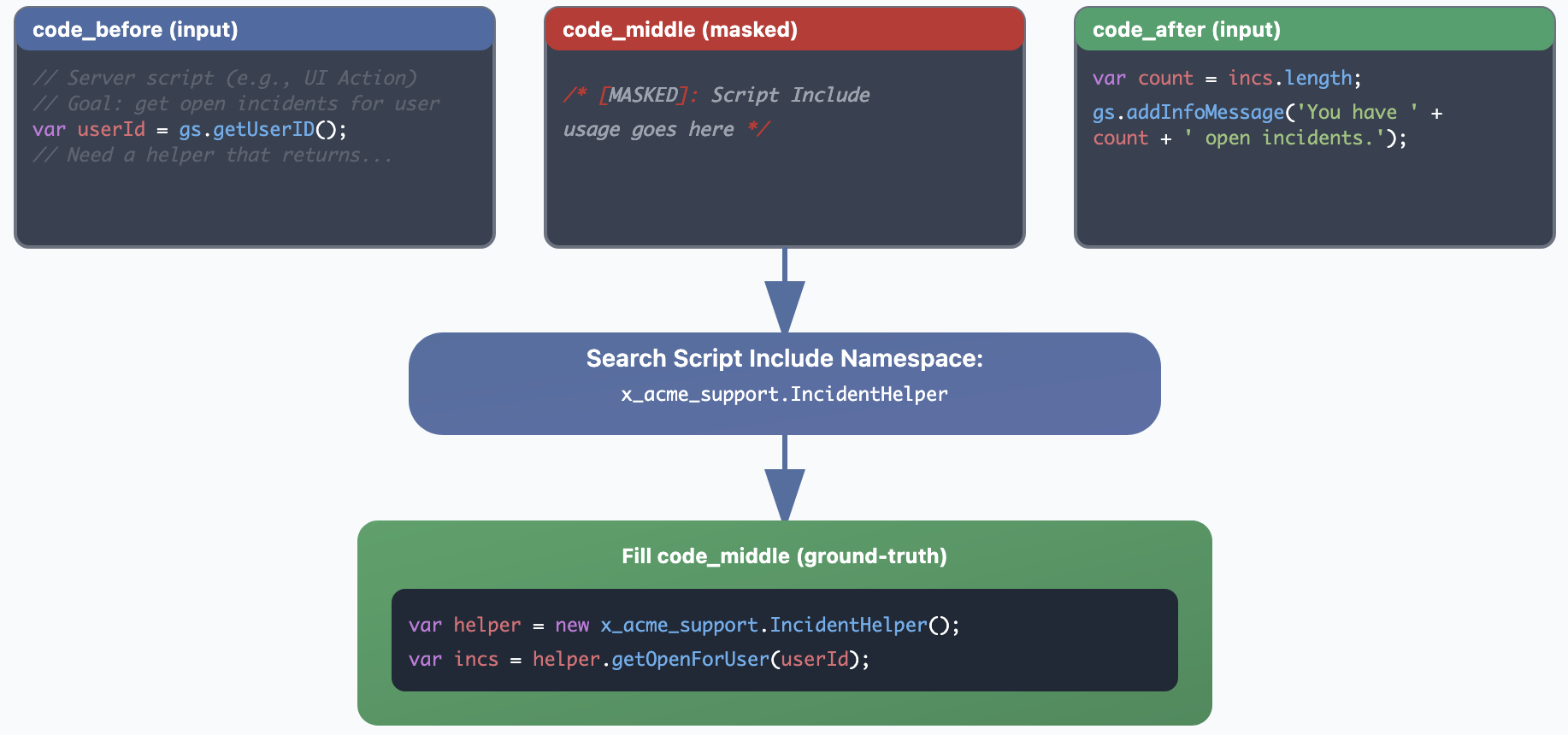
Figure 2: Task anatomy: highlighting how code_before, and code_after are used to recover the ground-truth Script Include required for code_middle.
The index covers 277 Script Include namespaces and 3,337 APIs. JSDoc summaries, ranging from 157 to 5,368 tokens, provide superior retrieval performance compared to raw code due to their structured and focused representation.
Experimental Setup and Evaluation
Retrieval performance is measured using Top-K Accuracy and Mean Reciprocal Rank (MRR). The pipeline is benchmarked against BM25 (53.02% top-40 accuracy) and several neural retrieval methods:
- Prefix Code Embed (Non-FIM): Embedding the code preceding the cursor.
- LLM Description: Generating a natural language description of user intent.
- Hypothetical Code Generation: LLM-generated hypothetical code completions.
The Hypothetical Code Generation method achieves 87.86% top-40 accuracy, more than doubling the BM25 baseline. MRR results confirm superior ranking quality.
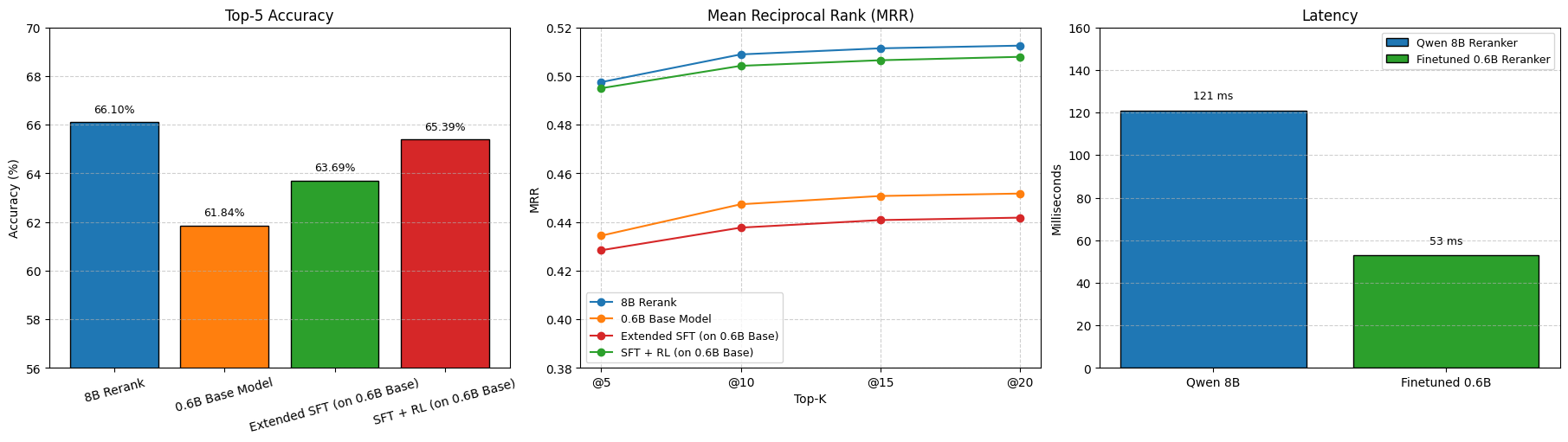
Figure 3: Qwen 0.6B: Top-5 accuracy after finetuning, Mean Reciprocal Rank (MRR) and Inference latency.
Latency analysis demonstrates that the optimized 0.6B reranker matches or exceeds the 8B model's accuracy while maintaining significantly reduced inference latency, enabling real-time deployment.
Ablation Studies
Ablation studies quantify the contribution of each pipeline component:
- Knowledge Graph Filtering: Reduces search space by 59%.
- Enhanced Indexing (JSDoc): Improves top-5 accuracy by 21.5 percentage points over baseline.
- LLM Reranking: Provides an additional 7 percentage point boost in top-5 accuracy.
- Context Length: Optimal retrieval is achieved with 8-10 lines of prefix code; excessive context introduces noise.
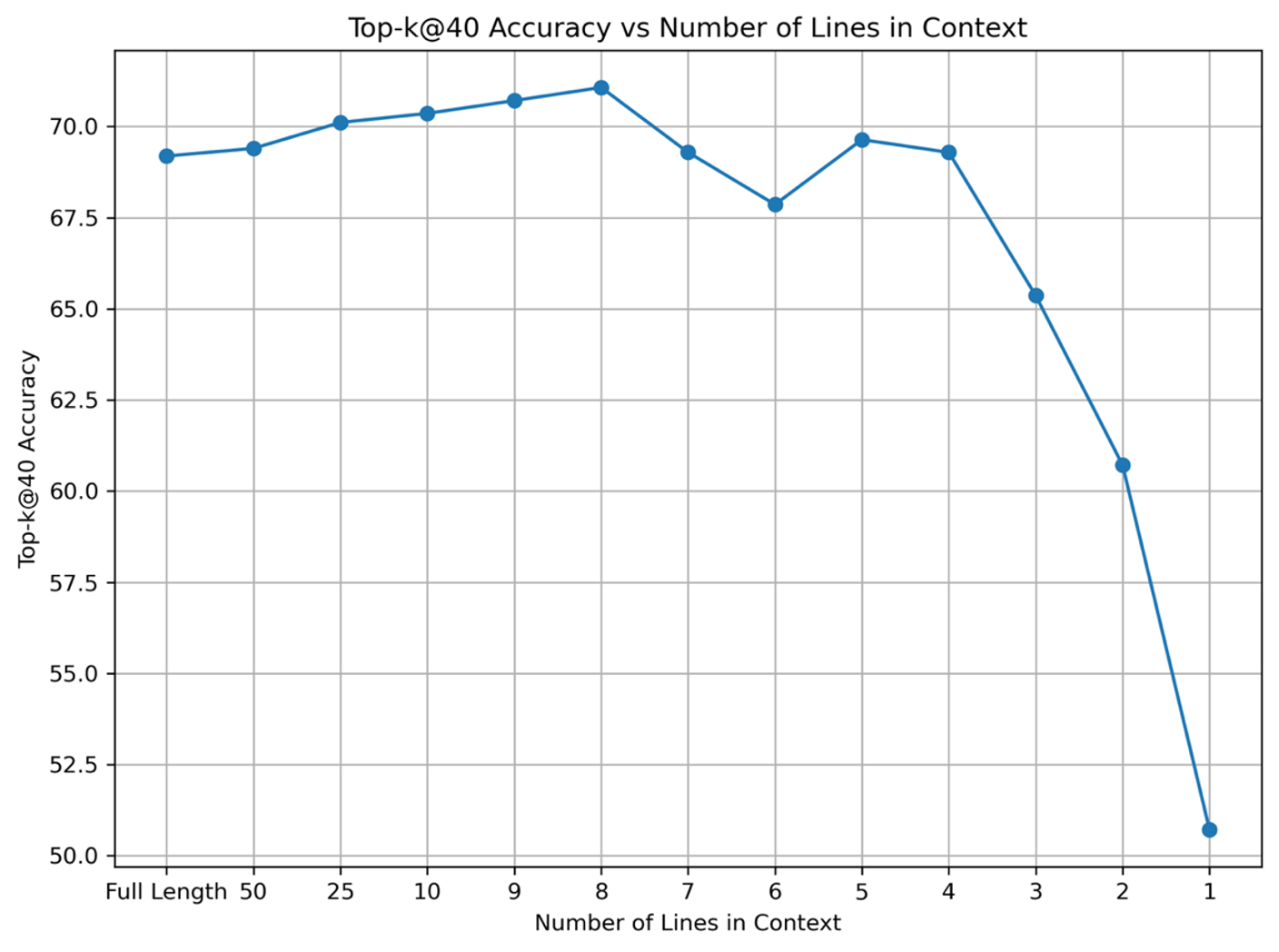
Figure 4: A4 code trimming and context length.
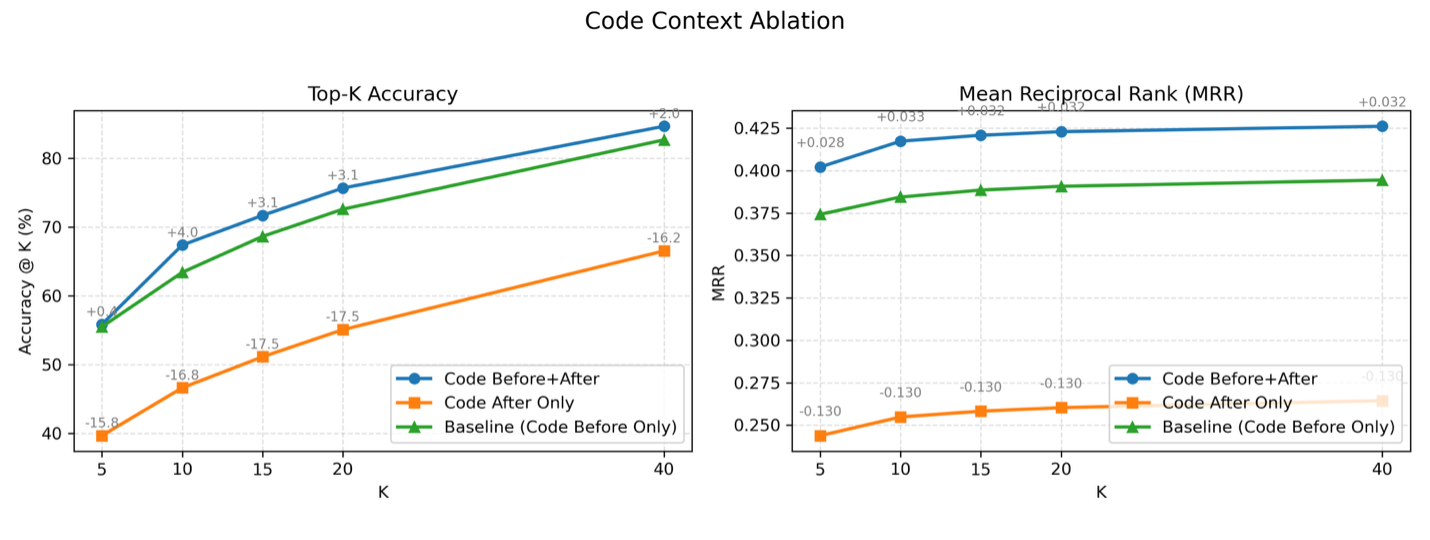
Figure 5: Performance of Code Context Ablation.
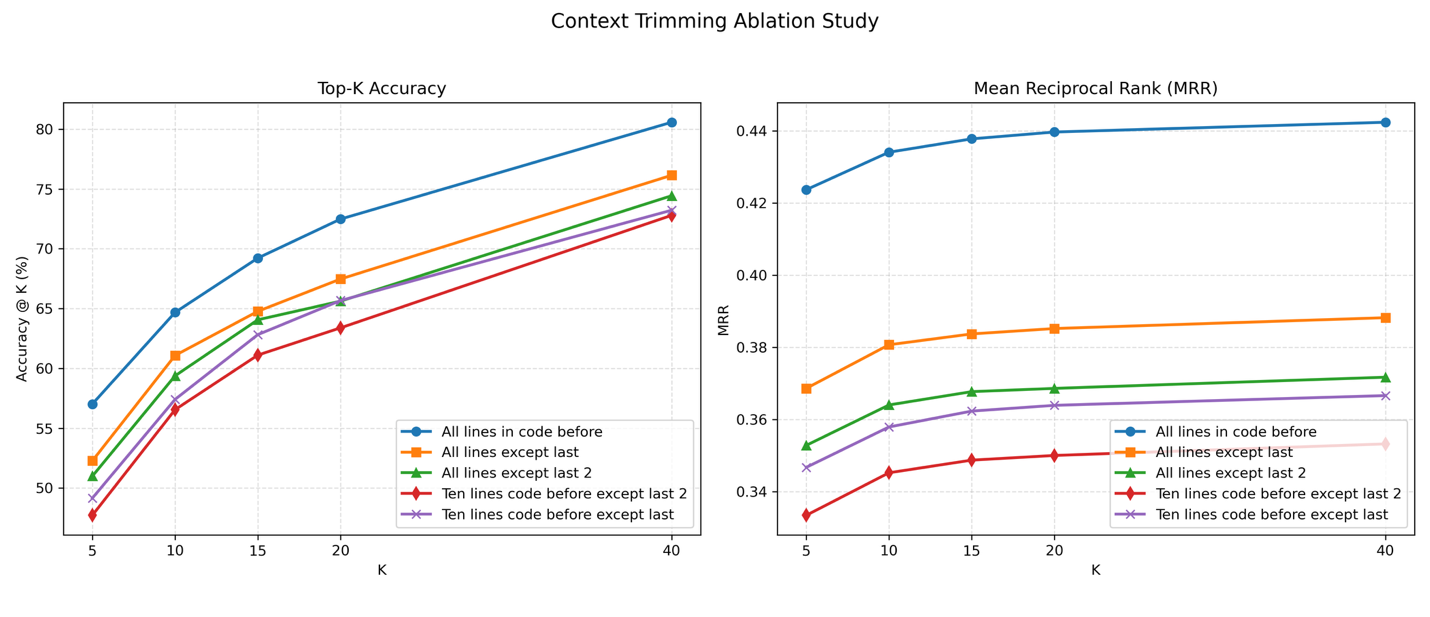
Figure 6: Effect of Code Proximity on Performance.
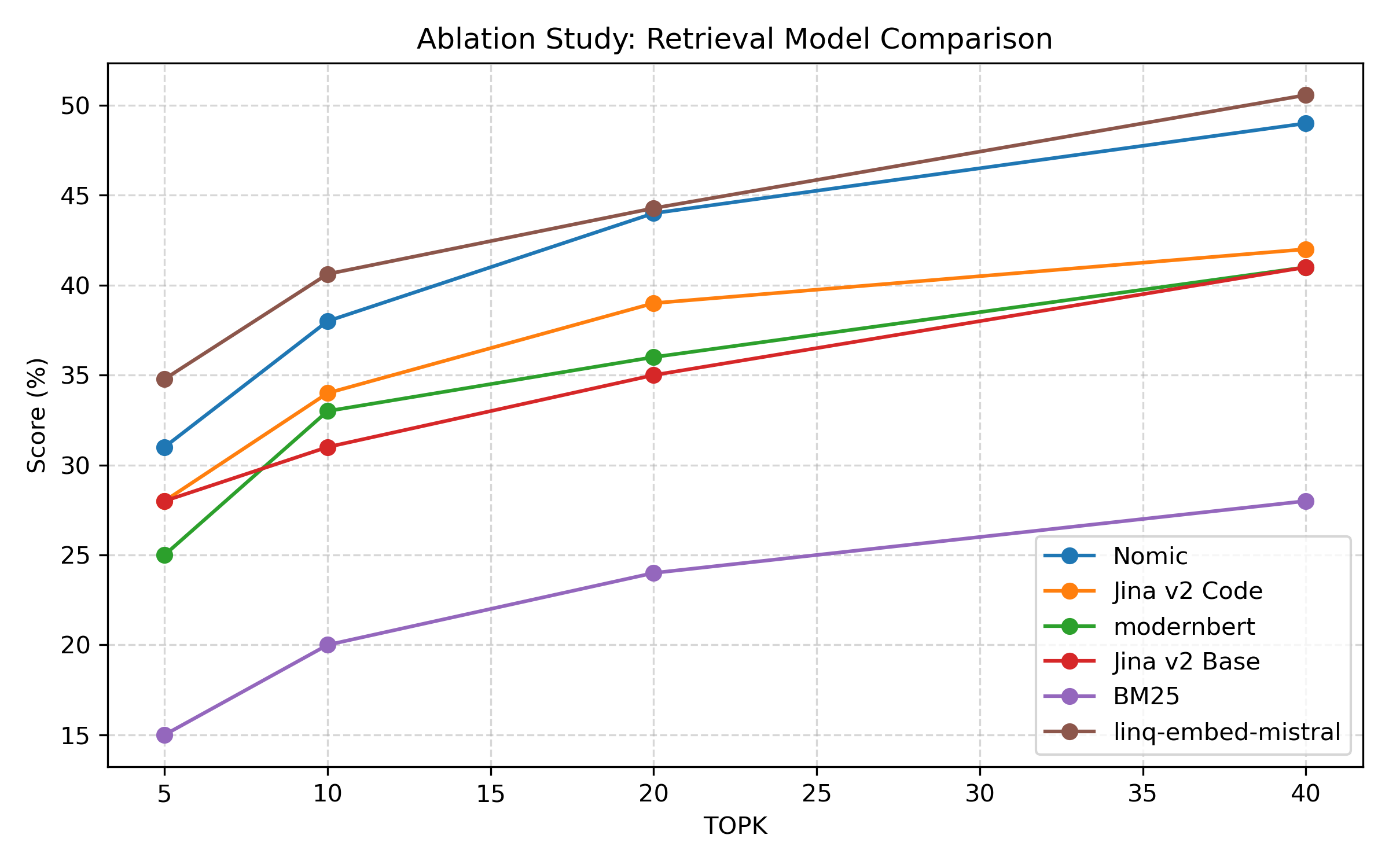
Figure 7: Ablation study comparing the retrieval performance of various models.
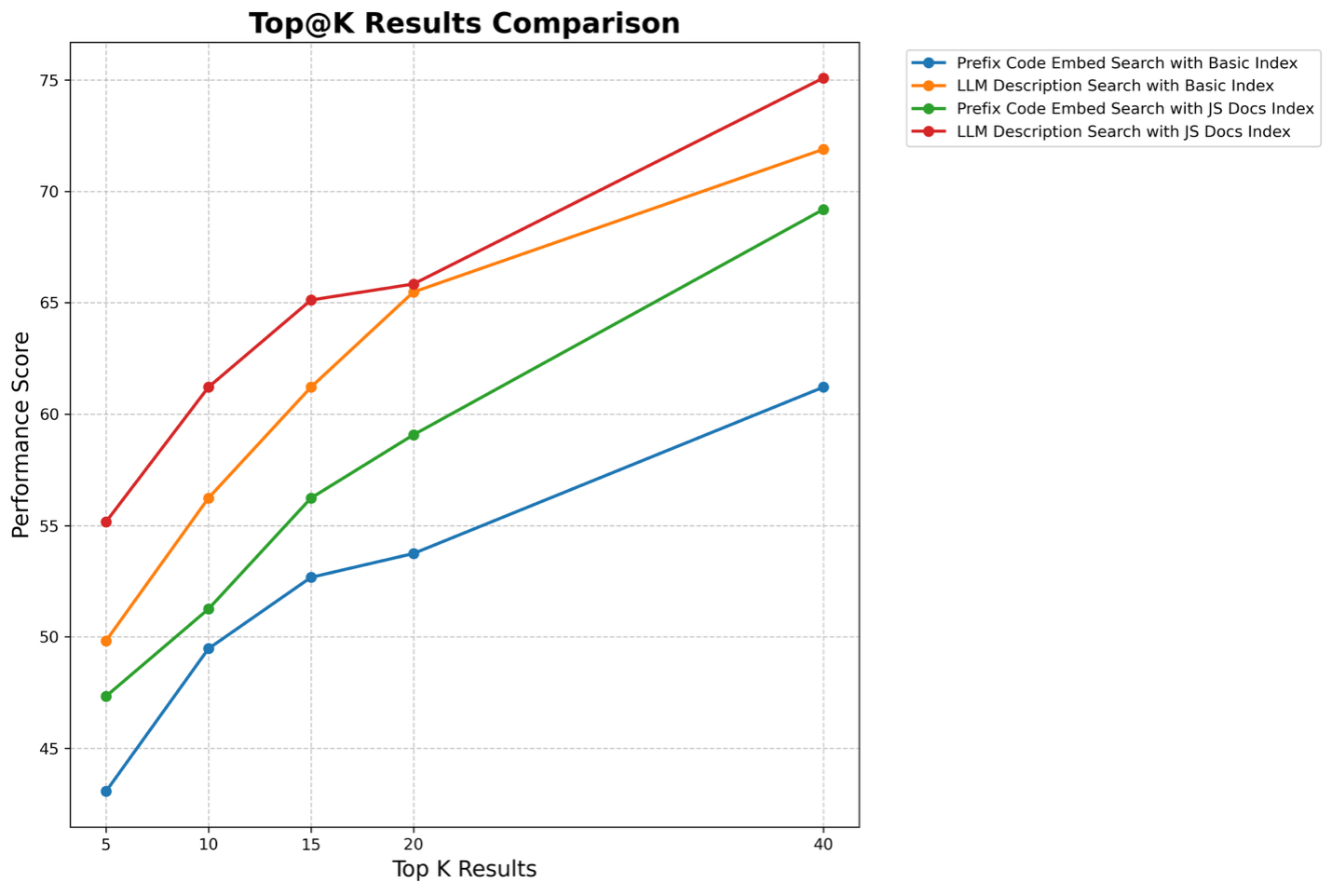
Figure 8: Performance comparison between JSDoc-based indexing and raw code descriptions across different retrieval methods. JSDoc indexing shows consistent improvements in retrieval accuracy.
Post-Training Optimization of Compact Reranker
The post-training pipeline for the Qwen 0.6B reranker consists of:
- Supervised Fine-Tuning (SFT): Trained on CodeR-Pile (JavaScript/TypeScript) and synthetic samples, using LoRA adapters for parameter efficiency. Balanced sampling and negative log-likelihood loss prevent class imbalance and overfitting.
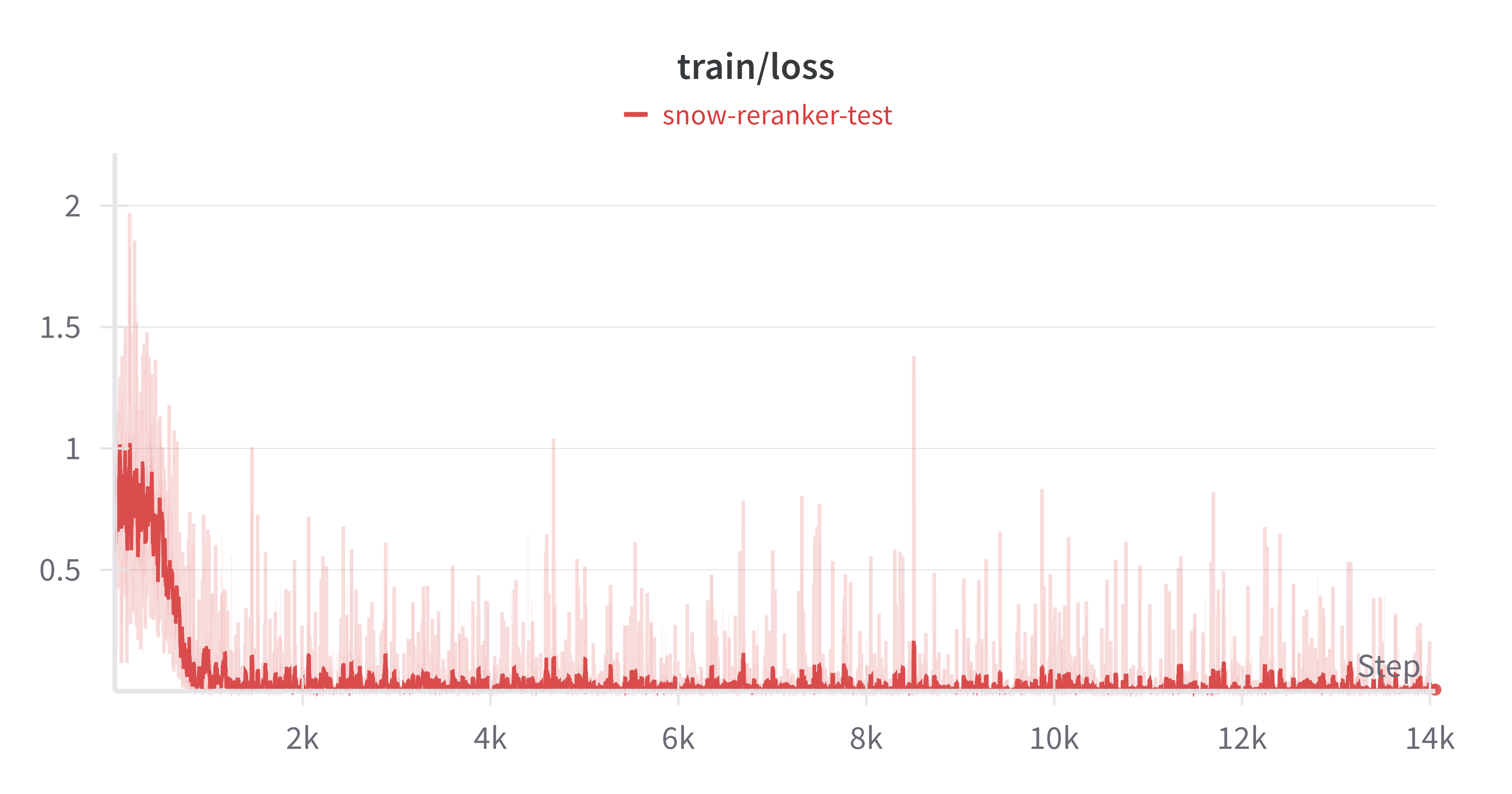
Figure 9: Training loss progression during supervised fine-tuning (SFT).
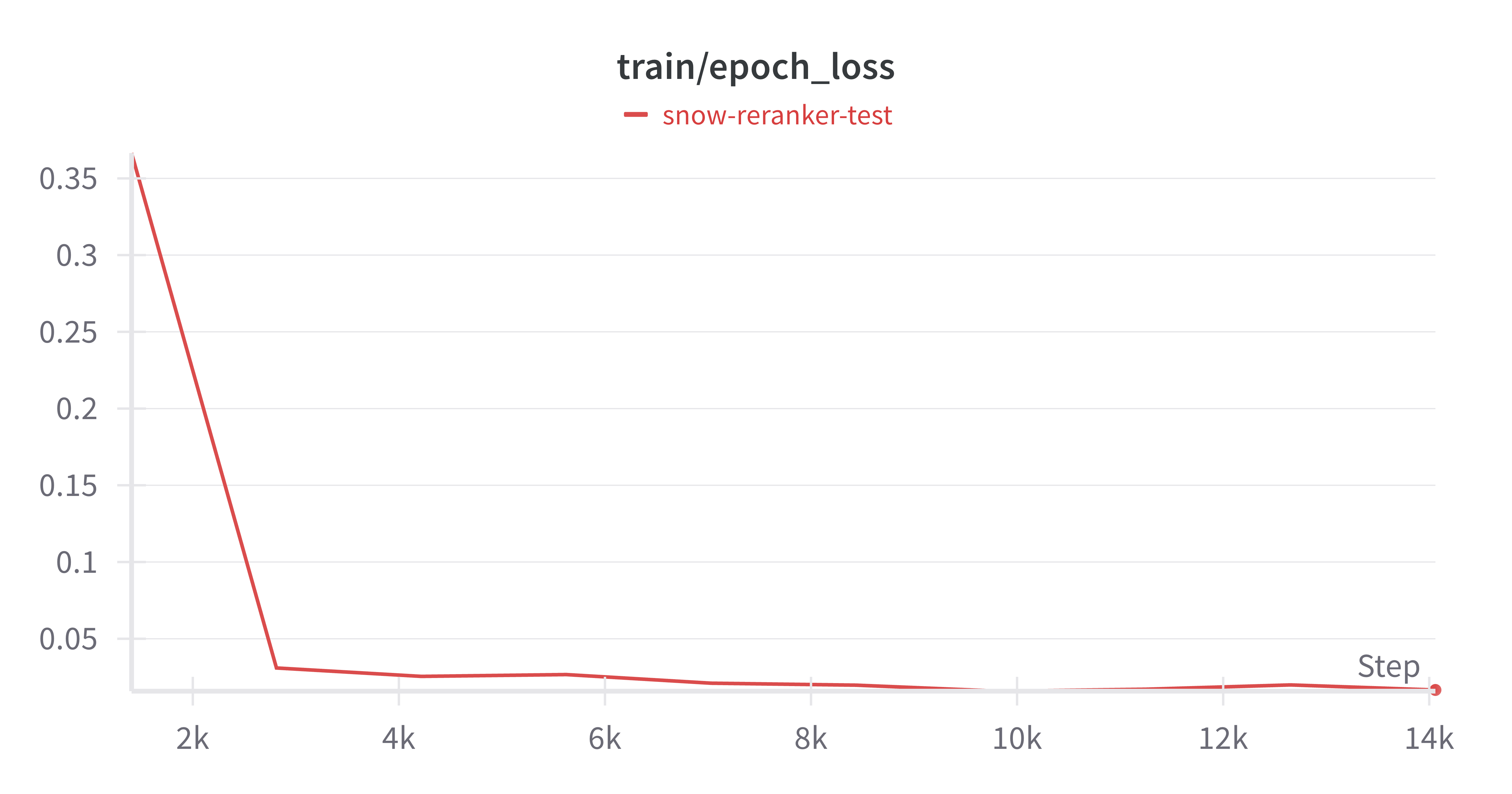
Figure 10: Epoch-wise loss during supervised fine-tuning (SFT).
- Reinforcement Learning (RL): GRPO-based RL with completion-aware binary rewards. RL is applied to SFT checkpoints, further fine-tuned with synthetic data, yielding the best ranking performance.
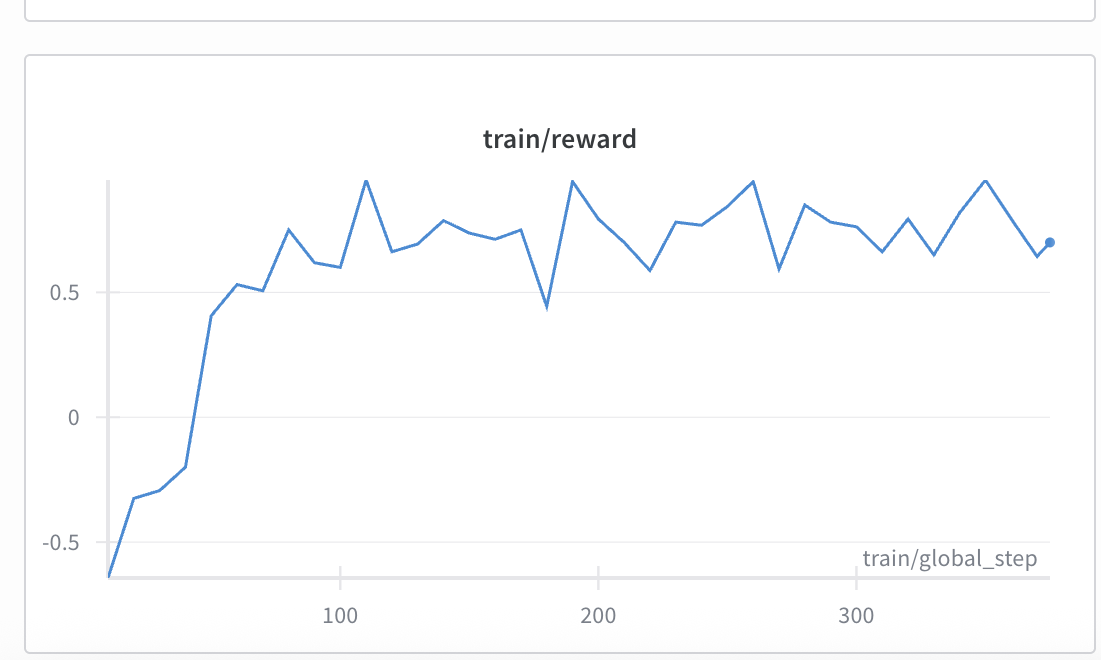
Figure 11: Reward progression during reinforcement learning training.
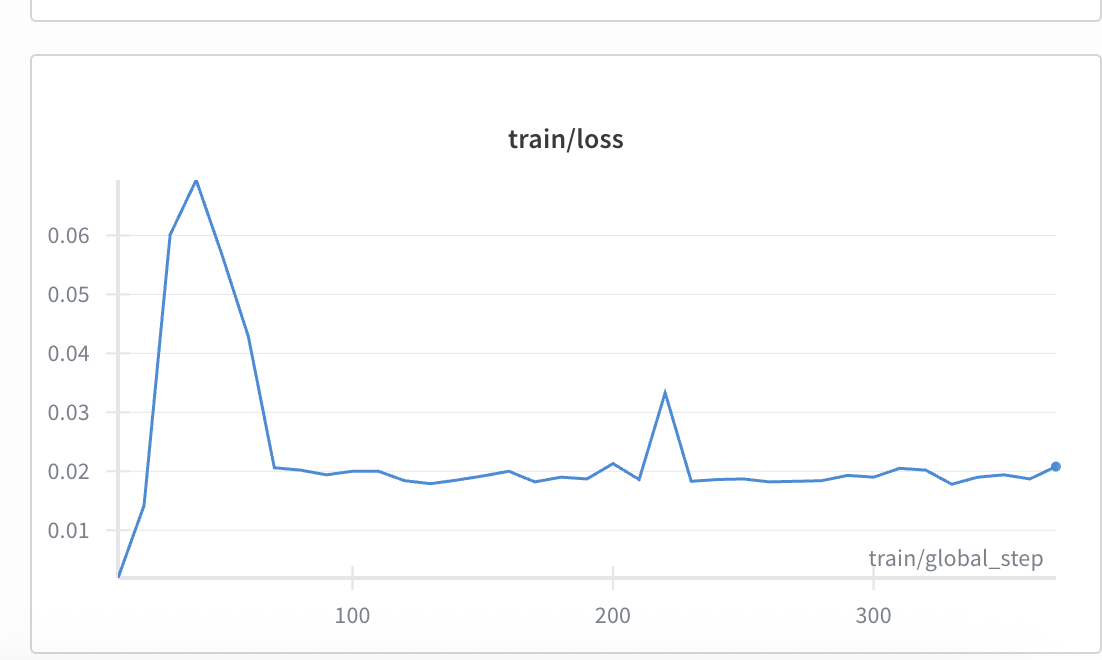
Figure 12: Training loss during reinforcement learning.
- Performance: The SFT+RL optimized 0.6B reranker achieves 68.58% top-5 accuracy, outperforming the 8B baseline (66.10%) while maintaining 2.5x reduced latency.
Out-of-Distribution Generalization
Evaluation on an out-of-distribution dataset confirms that the specialized reranker maintains generalization capabilities, with no significant degradation or overfitting observed.
Analysis of Query Enhancement Techniques
Code-based queries (Prefix Code Embed, Hypothetical Code Generation) consistently outperform LLM-generated natural language descriptions, as the latter may omit critical details. The immediate preceding lines before API invocation contain the most valuable information for retrieval.
Implementation Considerations
- Resource Requirements: The compact 0.6B reranker enables deployment in resource-constrained environments, supporting higher concurrency and lower tail latency.
- Scalability: Knowledge graph filtering and enriched indexing scale efficiently with the number of APIs and namespaces.
- Limitations: The dataset focuses on Script Includes, limiting generalization to other code completion contexts. Synthetic data may not fully capture real-world complexity.
Implications and Future Directions
DeepCodeSeek demonstrates that domain-specific retrieval pipelines, enriched indexing, and compact reranking can substantially improve context-aware code generation in enterprise environments. The approach is directly applicable to other platforms with custom APIs and sparse documentation. Future work should focus on expanding dataset coverage, refining knowledge graph construction, and further specializing rerankers for diverse code completion tasks.
Conclusion
DeepCodeSeek presents a robust, multi-stage retrieval pipeline for real-time API retrieval in enterprise code generation scenarios. The combination of knowledge graph filtering, JSDoc-enriched indexing, advanced query enhancement, and post-training optimization of compact rerankers yields state-of-the-art retrieval accuracy and latency. The methodology is validated through extensive ablation studies and out-of-distribution generalization, establishing a strong foundation for future research in context-aware code generation and retrieval-augmented programming assistants.