- The paper's main contribution is introducing PWMPR, which grows winning subnetworks using a novel Path Weight Magnitude Product score.
- It demonstrates that iteratively adding connections can achieve comparable accuracy to traditional pruning methods while reducing computational cost on benchmarks.
- The work outlines a practical growth strategy that balances network performance and training efficiency, with potential applications to various architectures.
Growing Winning Subnetworks, Not Pruning Them: A Paradigm for Density Discovery in Sparse Neural Networks
Introduction to Growth-Based Density Discovery
The paper "Growing Winning Subnetworks, Not Pruning Them: A Paradigm for Density Discovery in Sparse Neural Networks" introduces a novel methodology for constructing sparse neural networks. Instead of relying on traditional pruning methods, the authors propose Path Weight Magnitude Product-biased Random growth (PWMPR) to automatically discover optimal densities in sparse networks by adding rather than removing connections. PWMPR aims to identify subnetworks capable of performance comparable to dense networks but at a significantly lower computational cost.
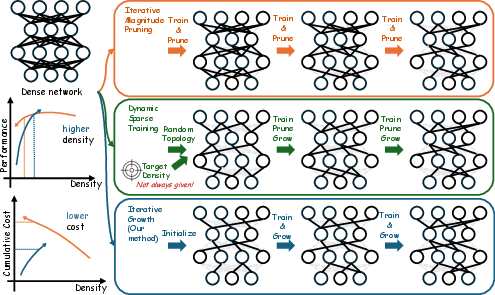
Figure 1: Conceptual comparison of strategies for identifying sparse neural networks that match dense network performance.
Methodology
Path Weight Magnitude Product: A New Growth Metric
The cornerstone of PWMPR is the Path Weight Magnitude Product (PWMP) score. This metric facilitates the efficient growth of sparse networks by computing potential connections based on the weight magnitudes of paths between nodes. Instead of a complex enumeration of all paths, PWMPR employs a simplified computation through forward and backward passes. This algorithm enables the identification of edges that can maximally enhance network capacity while mitigating computational complexity.
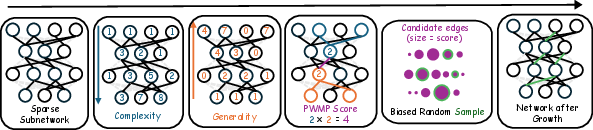
Figure 2: Illustration of the PWMP random growth algorithm, including computation of PWMP scores through forward/backward passes and sampling new connections based on the scores.
Practical Implementation
PWMPR initializes with a sparse mask generated via a PHEW-based approach, ensuring no isolated nodes. During training, PWMPR iteratively increases network density based on a pre-defined growth ratio, which is crucial for balancing exploration and computational efficiency. Notably, connections are initialized to zero to maintain stable learning trajectories.
PWMPR employs a logistic-fit strategy to determine when to halt growth, using performance-density curves to balance accuracy gains against training costs effectively.
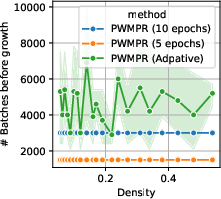
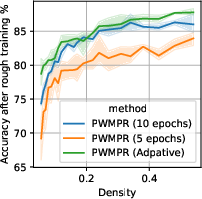
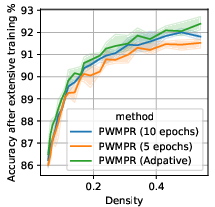
Figure 3: Effect of growth timing on CIFAR-10 with ResNet-32, highlighting the impact on batch computation and accuracy.
Results and Insights
PWMPR demonstrated superior or comparable performance to state-of-the-art pruning methods across multiple benchmarks including CIFAR-10, CIFAR-100, and TinyImageNet. The results highlight PWMPR's capability to achieve nearly the same accuracy as Iterative Magnitude Pruning (IMP) but at lower densities, thus reducing the normally high training costs associated with sparse network training (about 1.5x the cost compared to 3-4x for IMP).
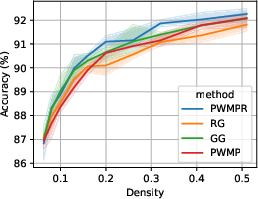
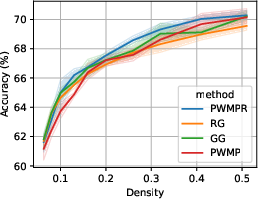
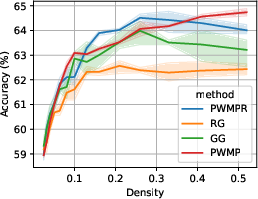
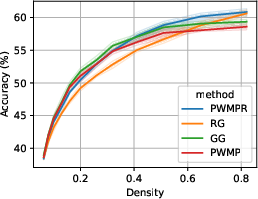
Figure 4: Performance-density relationship of PWMPR compared with other growth mechanisms and the ablated version, highlighting its competitive edge.
Comparative Analysis
PWMPR's efficiency was particularly pronounced against other dynamic sparse training mechanisms like RigL and static entrants like PHEW. In trials, PWMPR consistently converged to high-performing configurations more rapidly and economically.
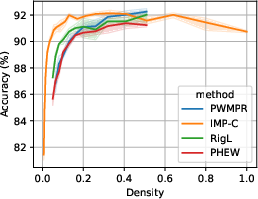
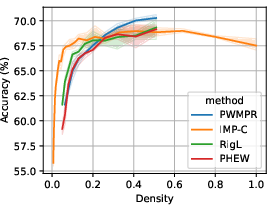
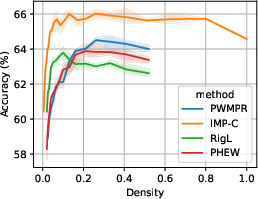
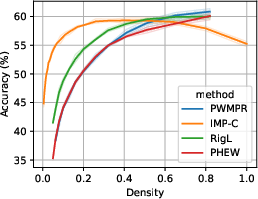
Figure 5: Performance-density relationship of PWMPR compared with other sparsity strategies, showcasing its efficacy.
Topological Insights
The topological analysis of networks grown by PWMPR reveals a balance between maximizing path weights and minimizing topological bottlenecks, essential for preserving generalization capabilities in sparse networks.
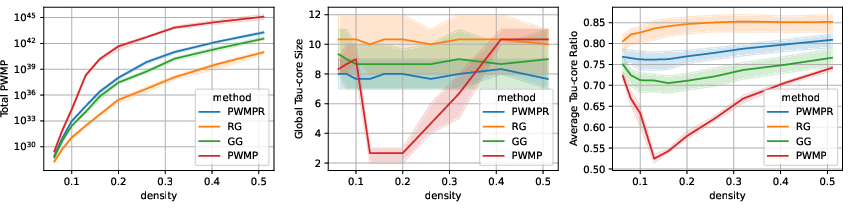
Figure 6: Evolution of topological metrics during iterative growth, showcasing PWMPR's effectiveness in avoiding bottlenecks.
Conclusion
The PWMPR framework offers a transformative approach to training efficient sparse neural networks by leveraging a growth paradigm rather than traditional pruning. While currently applied primarily to convolutional and feed-forward architectures, future research could explore adapting PWMPR to attention-based models with appropriate synaptic growth rules. Such explorations may further solidify PWMPR's role in domain-spanning applications of sparse neural networks. Additionally, hybrid grow-prune methods and large-scale dataset validations present promising avenues for future development. PWMPR posits a compelling shift in approaching efficient neural network design, advocating for growth-based density discovery as a complementary paradigm to traditional sparse network optimization techniques.

