Adaptive Test-Time Reasoning via Reward-Guided Dual-Phase Search
Abstract: LLMs have achieved significant advances in reasoning tasks. A key approach is tree-based search with verifiers, which expand candidate reasoning paths and use reward models to guide pruning and selection. Although effective in improving accuracy, these methods are not optimal in terms of efficiency: they perform simple decomposition on the reasoning process, but ignore the planning-execution nature of tasks such as math reasoning or code generation. This results in inefficient exploration of reasoning process. To address this, we propose a dual-phase test-time scaling framework that explicitly separates reasoning into planning and execution, and performs search over the two phases individually. Specifically, we decompose reasoning trajectories and develop reward models for each phase, enabling the search to explore and prune plans and executions separately. We further introduce a dynamic budget allocation mechanism that adaptively redistributes sampling effort based on reward feedback, allowing early stopping on confident steps and reallocation of computation to more challenging parts of the reasoning process. Experiments on both mathematical reasoning and code generation benchmarks demonstrate that our approach consistently improves accuracy while reducing redundant computation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Explanation of “Adaptive Test-Time Reasoning via Reward-Guided Dual-Phase Search”
Overview
This paper is about helping AI LLMs think better and faster when solving problems like math puzzles or writing computer code. The authors introduce a method called DREAM that splits the model’s reasoning into two clear parts—first making a plan, then carrying it out—and uses “rewards” to guide each part. It also decides how much effort to spend at each step so the AI doesn’t waste time on easy parts and focuses more on hard parts.
Objectives
The paper tries to answer these simple questions:
- Can an AI do better if it treats problem-solving like two separate phases: planning what to do and then doing it?
- Can we score (or “reward”) each phase separately to keep good ideas and throw away bad ones early?
- Can we save time by spending less effort on easy steps and more on difficult steps during solving?
Methods and Approach
To make this easy to understand, imagine solving a math problem or fixing a bug in a program:
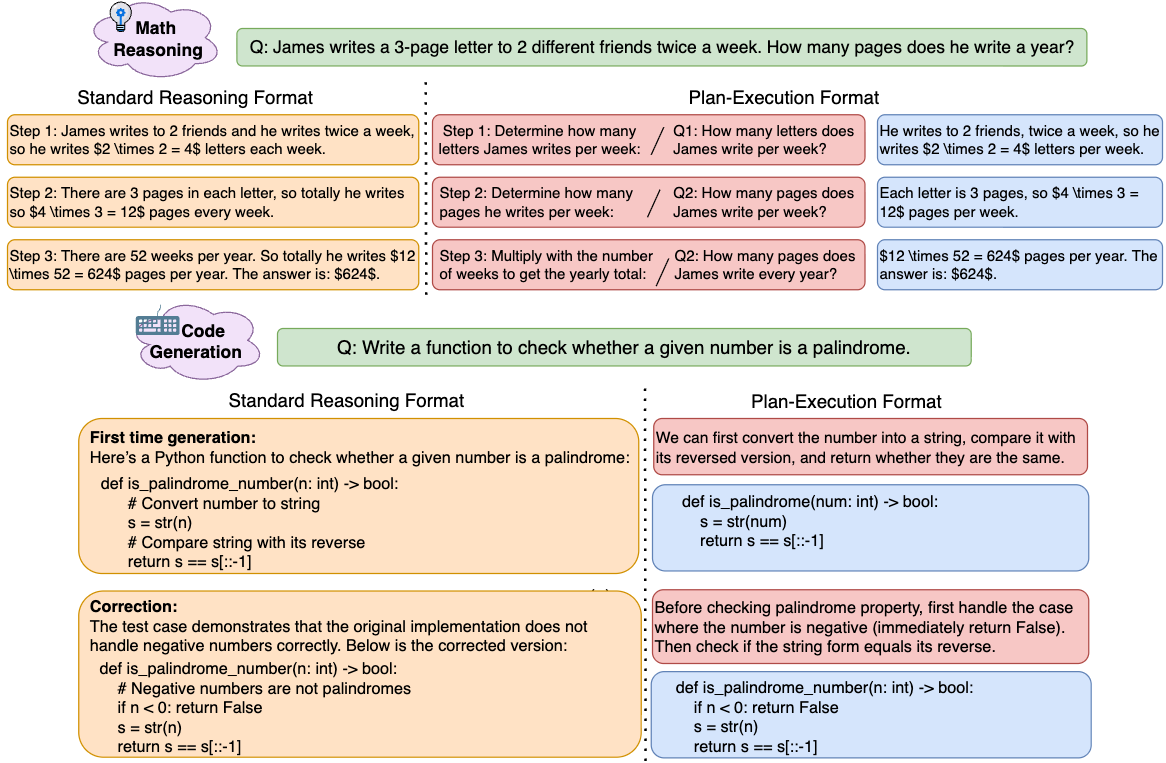
- Two-phase reasoning:
- Planning is like writing a short “to-do list” for the next step (e.g., “set up an equation”).
- Execution is like actually doing the math or writing the code based on that plan.
- Reward models (step judges):
- Think of a helpful coach scoring each plan and each execution step.
- Good plans get kept; weak plans get dropped before the AI wastes time executing them.
- Good executions are chosen; poor executions are discarded.
- Adaptive budget (spending effort smartly):
- If a step is clearly good (the “coach” gives a high score), the AI stops early and moves on.
- If nothing looks good yet, the AI tries a few more options for that step.
- This saves time on easy parts and pushes more effort to the tricky parts.
- How they tested it:
- Math reasoning: The AI solves word problems and more advanced math questions.
- Code generation: The AI writes programs and runs test cases to see if the code works. They adapt an existing “tree search” method called CodeTree by inserting the two-phase search and reward scoring.
- Training the “reward” judges: They build lots of solution attempts step-by-step, then label which steps help lead to correct final answers. Using these labels, they teach a smaller model to score steps as helpful or not.
Main Findings
Here are the key results and why they matter:
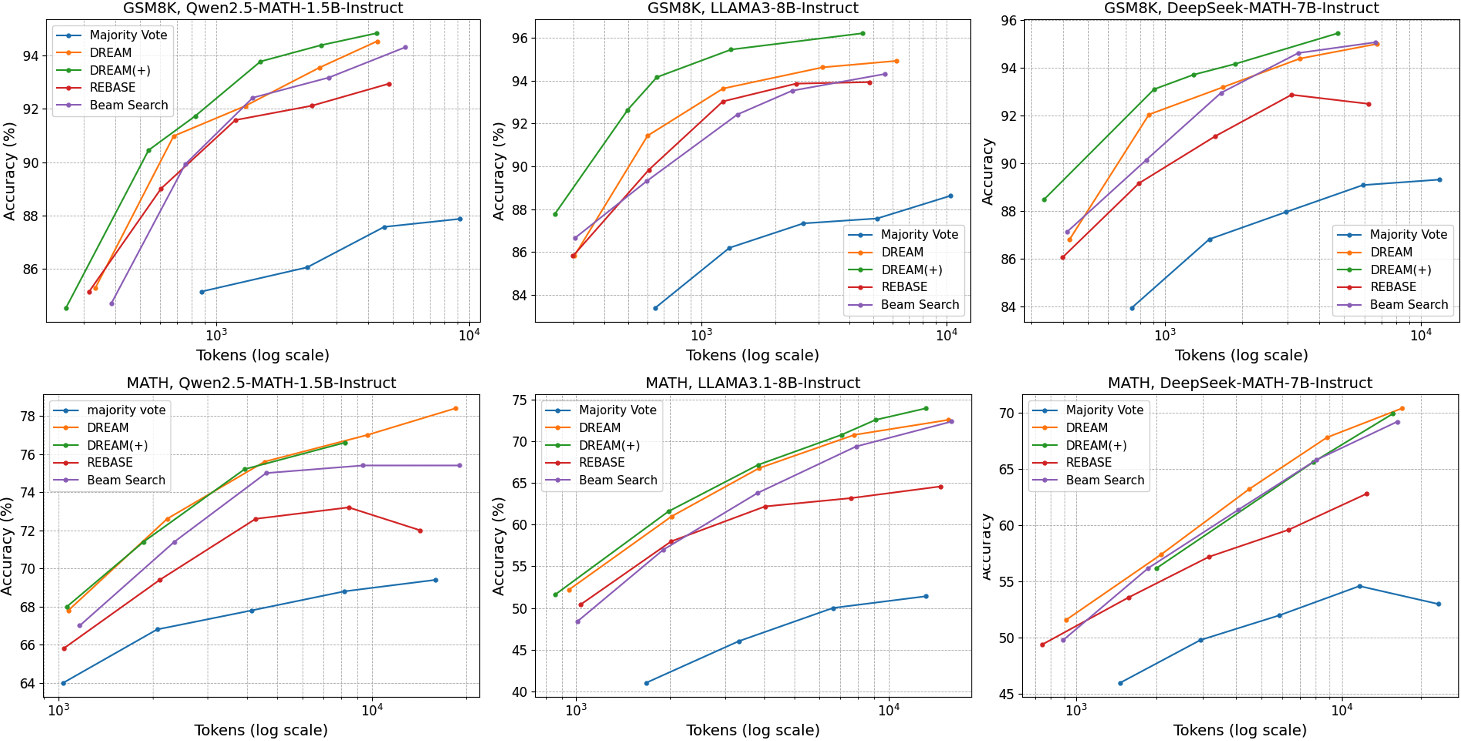
- Separating planning and execution improves accuracy. The AI keeps strong plans even if one execution attempt fails, and it can retry the execution without throwing away good ideas.
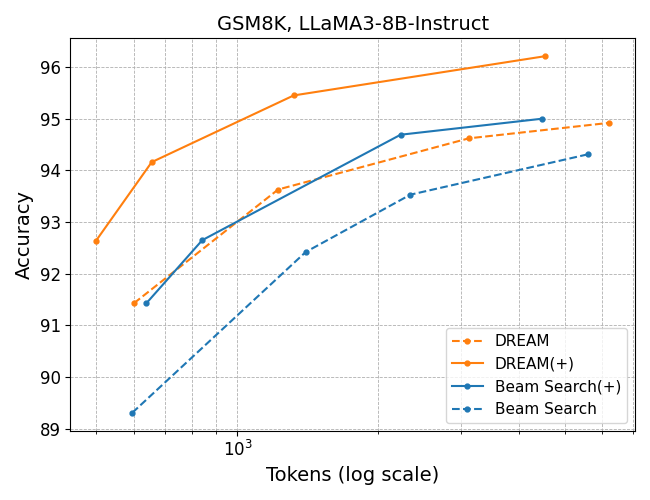
- Adaptive effort saves time. The AI stops early on easy steps and tries more samples on hard steps, using fewer “tokens” (less generated text and computation).
- Works across different models and datasets. The approach improved performance for math and code tasks with multiple AI models, even on new, unseen problem sets.
- Better than popular baselines. It generally outperforms methods like majority voting, standard beam search, and known code-generation strategies (e.g., CodeTree and Reflexion).
- Reward model size helps, but smaller ones still work. Larger “judges” score steps more accurately, but smaller ones also give solid gains while being cheaper.
Implications and Impact
This research shows a practical way to make AI solve problems more like a careful student: make a plan, check it, then do the work—while managing time wisely. That means:
- More reliable answers in math and coding help.
- Faster solutions and lower computing costs.
- A general strategy that could extend beyond math and code to other multi-step tasks, like science questions, logic puzzles, or multi-stage decision-making.
In short, DREAM helps AI think smarter at test time by splitting planning from doing, guiding both with rewards, and spending effort where it matters most.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to be actionable for future research.
Methodological scope and generalization
- Validate dual-phase search beyond math and single-file Python code: test on commonsense/multi-hop QA, tool-augmented reasoning, scientific QA, theorem proving, and multimodal tasks where plan–execution decomposition may be ambiguous or multi-granular.
- Assess robustness to alternative plan granularity: how sensitive is DREAM to different plan step sizes, subgoal definitions, or noisy adherence to the plan–execution format by the base LLM.
- Extend to multi-language and multi-file software generation (e.g., Java, C++, TypeScript, projects with dependencies) to test whether planning/execution rewards transfer to larger, modular codebases.
- Combine step-wise (intra-trajectory) allocation with sample-wise (across problems/trajectories) allocation in a unified policy; quantify gains and interactions.
Reward modeling: training data, signal quality, and calibration
- Quantify label noise from rollout-based annotation: analyze how using “≥1 of 5 rollouts leads to a correct final answer → positive” introduces false positives (lucky continuations) and false negatives (insufficient rollouts); study sensitivity to number of rollouts, temperatures, and backbone LLM used for labeling.
- Compare alternative reward signals: human-verified labels, LLM-as-judge verifiers, program analysis tools, or probabilistic value estimates; evaluate trade-offs in accuracy, cost, and bias.
- Calibrate reward scores across models/datasets: investigate reliability and calibration of PRM scores under distribution shifts (different backbones, prompts, and plan granularities); develop calibration or uncertainty-aware thresholds.
- Causal credit assignment: determine whether a plan/execution is “truly causal” for success vs merely correlated; explore counterfactual or interventional labeling to avoid spurious positives.
- Data efficiency: measure the marginal benefit of reward-data size (e.g., 50k vs 400k samples); design active or curriculum data collection to reduce labeling cost.
- Model size vs performance frontier: go beyond 7B/32B ablation to test distillation, quantization, and small-model ensembling for deployable PRMs.
Budget allocation policy and search dynamics
- Learn the allocation policy rather than fixing thresholds: replace the two-threshold rule and fixed m1/m2 with learnable controllers (bandits/RL) that optimize accuracy–compute trade-offs online.
- Sensitivity analysis of hyperparameters (N1, N2, n1, n2, τp1/τe1, τp2/τe2, m1/m2): provide systematic evaluation, auto-tuning, or adaptive per-problem/per-step selection.
- Diversity vs early stopping: quantify whether early stopping harms exploration by reducing diversity; incorporate diversity- or novelty-aware criteria and analyze trade-offs.
- Theoretical analysis: derive sample complexity or regret bounds for dual-phase search with PRMs and adaptive budgets; characterize when separating plan/execution is provably beneficial.
- Failure mode analysis of pruning: identify cases where good plans are prematurely pruned due to noisy rewards; design safety nets (e.g., delayed pruning, soft-keep buffers).
Code generation specifics
- Reward hacking and overfitting to visible tests: quantify how often candidates exploit test artifacts; evaluate with adversarial/robust tests and hidden, mutation, or property-based tests.
- Runtime cost accounting: include program execution time and test-running overhead (not only token counts) in the efficiency metric; report wall-clock latency and variance due to flaky tests.
- Reintroduce or improve critics: the paper removes the critic agent due to marginal gains—investigate stronger verifiers (static analysis, type/state invariants, fuzzing) and hybrid execution–analysis rewards.
- Scaling beyond “full program per step”: test intra-program plan–execution (e.g., function-level plans, patch-based edits), and reuse partial correct executions across branches.
Evaluation breadth and baselines
- Broader baselines: compare against recent strong test-time scaling methods (e.g., s1, RAP/LiteSearch/rStar variants, Tree-of-Thoughts/ToT-style methods, Best-of-N with re-ranking) under matched compute.
- Cross-benchmark generalization: evaluate on GSM-Hard, SVAMP, AQuA, SAT/logic benchmarks, and more code suites (e.g., APPS, Codeforces) to stress-test generality.
- Robustness to prompt and format shifts: test different templates for plan–execution prompts, few-shot exemplars, and plan–execution separators to assess brittleness.
- Ablate plan-only vs execution-only PRMs: quantify the incremental value of each PRM and their interaction across tasks/datasets.
Practicality, deployment, and reproducibility
- Compute and memory footprint of PRMs: report training/inference cost of 32B PRMs and end-to-end overhead; study caching, batching, and pipeline parallelism for practical deployment.
- Token accounting clarity: specify whether PRM inference tokens and test execution logs are counted in the “tokens” metric; provide a standardized accounting protocol.
- Reproducibility: release code, data, and exact hyperparameters/thresholds; document seeds, decoding settings, and PRM training recipes to facilitate replication.
Conceptual extensions and open directions
- Beyond two phases: explore multi-phase or hierarchical planning (plan–subplan–execution) and dynamic phase skipping/merging based on reward signals.
- Tool-augmented and interactive settings: integrate external tools (CAS/SMT solvers, theorem provers, retrieval, simulators) within dual-phase search and define phase-specific reward interfaces.
- Uncertainty-aware stopping: use PRM uncertainty or conformal bounds to drive stopping/reallocation decisions with guarantees on error rates.
- Detect “uniformly hard” instances: design a meta-controller to identify cases where adaptive step-wise allocation yields little gain and switch to alternative strategies (e.g., deeper search or improved verifier).
- Safety and specification adherence: for code and math, evaluate correctness beyond final answers (side effects, resource use, numerical stability, and specification compliance) and reflect these in execution rewards.
Practical Applications
Immediate Applications
The following applications can be deployed with current LLMs, available datasets, and established workflows (e.g., unit testing for code, math tutoring formats). Each item includes the sector, a concrete use case, and assumptions or dependencies.
- Software engineering: IDE plugin for dual-phase code generation and debugging
- Use case: Integrate DREAM-style plan selection and execution sampling into IDEs (VS Code, JetBrains) to generate code from natural-language plans, run unit tests, early-stop on high-confidence solutions, and reallocate sampling when tests fail.
- Tools/workflows: “DREAM Engine” inference module + “Plan PRM” (ranks design plans) + “Exec PRM” (ranks code candidates via test pass rates), CI integration to gate merges.
- Assumptions/dependencies: Availability of test cases or auto-synthesized tests; sandboxed execution; domain-specific PRMs for specialized stacks.
- DevOps/CI: Adaptive compute allocation in CI pipelines
- Use case: Control per-step sampling tokens for code assistants during CI (PR review bots, automated bug repair), stopping early on easy fixes and spending more time on tricky failures.
- Tools/workflows: “Adaptive Sampling Controller” that exposes thresholds and budgets; CodeTree+DREAM backend; policy rules for compute governance.
- Assumptions/dependencies: Access to inference orchestration; safe execution environment; tests must reflect correctness.
- Data science and analytics engineering: Notebook/code assistant for ETL and analysis scripts
- Use case: Generate pandas/SQL pipelines via plan-first then execute variants; verify with unit tests and sample data; adapt budget to hard joins or window functions.
- Tools/workflows: Plan PRM trained on ETL patterns; Exec PRM using test assertions and evalplus-style datasets; Jupyter/LangChain integration.
- Assumptions/dependencies: Testable tasks; representative sample data; domain-specific reward models for data cleaning/transforms.
- Education (EdTech): Step-level math tutoring with plan–execution feedback
- Use case: Tutors that separate subgoal planning (e.g., “set equations, define variables”) from execution (calculations), giving targeted feedback and allocating more “thinking” to hard steps.
- Tools/workflows: Math PRMs trained on GSM8K/MATH; least-to-most prompting; adaptive token budgets to improve latency on easy problems.
- Assumptions/dependencies: Grade-level alignment; content safety and pedagogy review; generalization of reward signals to curricula.
- Knowledge work productivity: Structured writing assistants
- Use case: Draft reports with plan outlines ranked by Plan PRM; generate section variants via Exec PRM; early-stop when clarity/coverage thresholds are met.
- Tools/workflows: Outline generator + section generator; custom PRMs (clarity, coverage, style); compute budget policies for enterprise teams.
- Assumptions/dependencies: Domain tuning of PRMs (e.g., finance vs. marketing); access to evaluation rubrics.
- Cloud cost and latency management: Per-step compute governance
- Use case: Reduce inference costs by early stopping on high-reward steps and dynamically redistributing tokens where needed (e.g., math/code assistants, internal bots).
- Tools/workflows: DREAM-aware middleware in inference servers; dashboards showing token savings and accuracy trade-offs.
- Assumptions/dependencies: Observability hooks in serving stack; calibrated thresholds; acceptance of minor accuracy variability.
- Research tooling (academia/industry): Reward modeling and test-time scaling toolkit
- Use case: Train PRMs via rollout-based labeling; reproduce dual-phase search baselines; study step-wise difficulty distributions and their impact on compute.
- Tools/workflows: Data generation scripts; PRM fine-tuning pipelines; benchmarking harnesses for GSM8K, MATH, MBPP/HumanEval(+).
- Assumptions/dependencies: Compute for PRM training; availability of base LLMs and datasets; reproducible labeling via rollouts.
- Robotics (simulation): Code-generated skills with dual-phase reasoning
- Use case: In simulation, plan task decomposition (high-level actions) and generate control code; use reward from task success/tests; adapt budget when policies fail.
- Tools/workflows: Sim-specific PRMs; test suites for tasks (e.g., manipulation scenarios); CodeTree+DREAM flow to refine controllers.
- Assumptions/dependencies: Reliable simulators; well-defined task tests; limited to sim until physical validation.
- Enterprise search/QA: Stepwise verification for complex queries
- Use case: Split queries into subgoals (plan), execute retrieval and synthesis separately; drop low-quality plans early; invest effort in ambiguous subgoals.
- Tools/workflows: PRMs for query planning and evidence synthesis; retrieval pipelines; adaptive sampling based on verifier feedback.
- Assumptions/dependencies: Access to high-quality corpora; verifiers tuned for domain-specific correctness and attribution.
Long-Term Applications
These applications require domain-specific PRMs, rigorous safety/validation, broader datasets, or engineering to scale into production across environments.
- Healthcare: Clinical decision support with plan–execution verifiers
- Use case: Verify diagnostic plans (differential diagnosis) and execution steps (test interpretation, guideline adherence) with dual PRMs; allocate compute to ambiguous cases.
- Sector: Healthcare (clinical reasoning, documentation).
- Assumptions/dependencies: Medical-grade datasets and reward functions; regulatory and safety approvals; explainability; robust auditing.
- Legal and policy drafting: Compliance-aware plan and execution PRMs
- Use case: Evaluate legal argument structures (plan) and statutory text (execution) for compliance, precedence, and consistency; adaptive compute on complex sections.
- Sector: Law, public policy.
- Assumptions/dependencies: Domain corpora, compliance verifiers; human-in-the-loop validation; jurisdiction-specific rules.
- Autonomous robotics: Dual-phase planning and low-level policy generation on hardware
- Use case: High-level task plans scored for feasibility; multiple low-level control executions sampled with environment rewards; adaptive compute to safety-critical phases.
- Sector: Robotics (manufacturing, logistics).
- Assumptions/dependencies: Real-world reward estimation; safety constraints; on-device compute optimization; formal verification.
- Finance and risk analysis: Scenario planning and execution audits
- Use case: Plan stress-test scenarios; execute portfolio simulations; reward models verify plan coverage and execution robustness; compute allocation favors high-impact scenarios.
- Sector: Finance.
- Assumptions/dependencies: Proprietary data; model risk management; backtesting; regulatory compliance.
- General-purpose “Reasoning OS layer” for LLM apps
- Use case: Standard APIs for plan–execution formatting, PRM scoring, and adaptive budgets across diverse tasks (code, math, analytics, ops).
- Sector: Software platforms, AI infrastructure.
- Assumptions/dependencies: Broad domain PRM libraries; developer adoption; performance guarantees.
- Education (personalization at scale): Step difficulty-aware curriculum generation
- Use case: Detect per-step difficulty and adapt instructional paths; plan subskills and exercises, execute solution variants and feedback; long-term tracking.
- Sector: Education.
- Assumptions/dependencies: Longitudinal datasets; pedagogical validation; fairness and accessibility.
- Safety and reliability frameworks: Process-level verification in regulated AI
- Use case: Governance modules that enforce per-step reward thresholds, log decisions, and audit compute allocation; deploy across critical workflows.
- Sector: Cross-sector compliance.
- Assumptions/dependencies: Standards for process-verification; audit trails; alignment with internal risk policies.
- Hardware and systems optimization: Per-step dynamic compute gating
- Use case: Accelerator/runtime support for early-stop and budget reallocation (e.g., per-layer/beam adjustments), reducing energy and latency.
- Sector: Semiconductors, cloud infrastructure.
- Assumptions/dependencies: Co-design with hardware vendors; standardized interfaces; workload characterization.
- Multi-agent systems: Coordinated dual-phase reasoning across agents
- Use case: Agents specialize in planning or execution; PRMs arbitrate handoffs; budgets shift among agents based on step-level confidence.
- Sector: Software, robotics, operations research.
- Assumptions/dependencies: Agent coordination protocols; robust inter-agent evaluation signals; scalability.
- Enterprise process automation: End-to-end workflows with stepwise verifiers
- Use case: Decompose complex processes (e.g., ERP updates, compliance checks) into subplans and executable steps; reuse partial correct plans across executions.
- Sector: Enterprise software.
- Assumptions/dependencies: Process modeling; domain PRMs; integration with legacy systems; change management.
- Scientific computing and code synthesis: Verified simulation pipelines
- Use case: Plan experimental pipelines; generate simulation code; validate execution against known invariants and tests; adapt compute for unstable regimes.
- Sector: Scientific R&D.
- Assumptions/dependencies: Domain benchmarks/invariants; high-trust execution sandboxes; provenance tracking.
In summary, the paper’s dual-phase search with reward-guided pruning and adaptive budget allocation can immediately improve code generation, math tutoring, research workflows, and inference cost management. Long-term, the same principles extend to safety-critical domains (healthcare, law, finance, robotics) once domain-appropriate reward models, test suites, and governance frameworks are established.
Glossary
- Agent-based searching frameworks: Structured multi-agent approaches that guide code generation via coordinated exploration and refinement. "tree-structured or agent-based searching frameworks like CodeTree~\citep{li2024codetree}, Tree-of-Code~\citep{ni2024tree} and Funcoder~\cite{chen2024divide}"
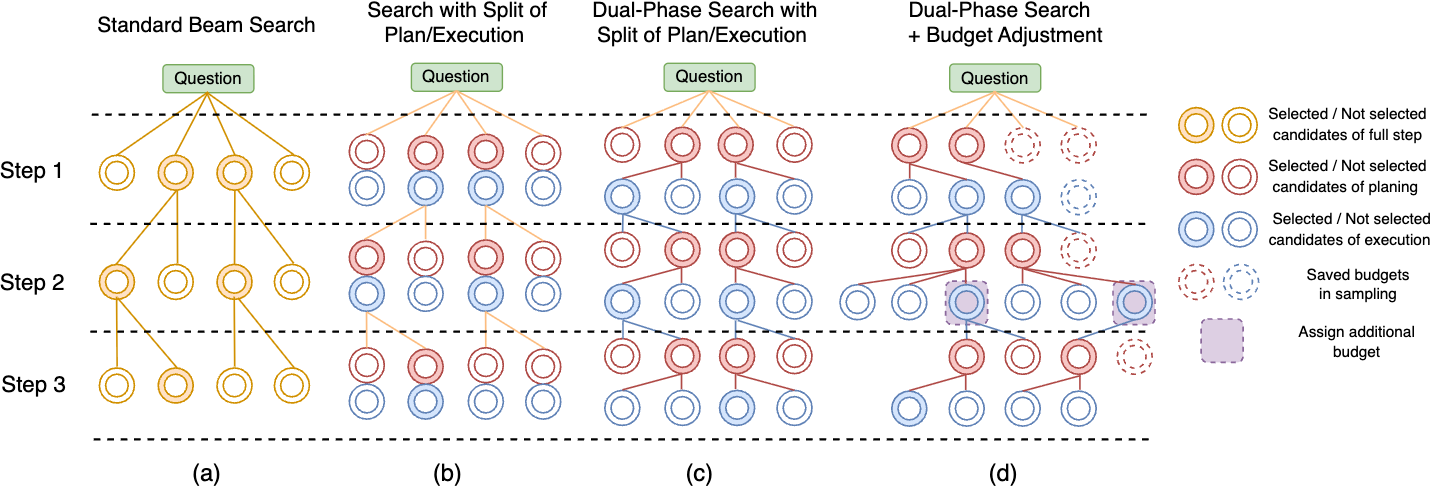
- Beam search: A heuristic search algorithm that keeps the top-scoring partial solutions at each step to efficiently explore sequences. "Our dual-phase search builds on the standard beam search framework, whose workflow is shown in Figure~\ref{fig:workflow} (a)."
- Best-of-N: A sampling strategy that generates multiple solutions and selects the most consistent or highest-voted one. "and {Best-of-N}~\citep{wang2022self}, which samples multiple candidate reasoning chains in parallel and aggregates via majority voting (self-consistency)."
- Budget-adjusted dual-phase search: A two-stage search that dynamically adjusts sampling counts in planning and execution based on confidence thresholds. "we further extend our method to a budget-adjusted dual-phase search that incorporates adaptive allocation."
- Chain-of-Thought (CoT) prompting: Prompting that elicits step-by-step reasoning from LLMs to improve problem-solving performance. "A common approach to improve LLM reasoning is Chain-of-Thought (CoT) prompting~\citep{wei2022chain}, which guides the model to generate intermediate reasoning steps in a stepwise manner"
- CodeTree: A tree-structured framework for code generation that iteratively generates and debugs programs guided by rewards. "In the original CodeTree algorithm, both the initial generation and subsequent debugging involve sampling multiple planning candidates per step"
- Distribution-Based Sampling: Test-time scaling that improves generation quality by refining candidate sampling distributions. "According to~\cite{snell2024scaling}, two primary mechanisms for scaling test-time include (1) {Distribution-Based Sampling} and (2) {Reward-Based Searching}."
- DREAM: The proposed Dual-phase REward-guided Adaptive reasoning framework at test time that separates planning and execution with reward-guided search. "For DREAM, we consider the variants with/without budget allocation, which are labeled
DREAM" andDREAM(+)", respectively." - Dual-phase search: A search method that independently explores and scores planning and execution phases to prune and select reasoning steps. "our dual-phase search (Figure~\ref{fig:workflow}(c)) explicitly separates each step into a planning phase (red nodes) and an execution phase (blue nodes)."
- Dynamic budget allocation mechanism: A strategy that adaptively reallocates sampling effort based on reward feedback, enabling early termination or extra search. "we further introduce a dynamic budget allocation mechanism that adaptively redistributes sampling effort based on reward feedback"
- Early stopping: Halting further sampling once sufficiently confident candidates are found to save computation. "allowing early stopping on confident steps and reallocation of computation to more challenging parts of the reasoning process."
- Execution reward model: A learned scoring model that evaluates execution steps (e.g., calculations or code outputs) to guide selection. "scored by an execution reward model ($\text{PRM}_{\text{exec}$)."
- Fine-grained supervision: Step-level feedback that scores intermediate reasoning steps rather than only final outcomes. "PRM provides fine-grained supervision at the process level, assigning rewards to intermediate steps"
- Instruction-tuned LLM: A LLM fine-tuned on instruction-following datasets to better adhere to prompts and tasks. "We implement the reward model by fine-tuning an instruction-tuned LLM."
- Iterative debugging: Successive refinement of generated code by fixing errors revealed by test cases. "and subsequent steps perform iterative debugging based on execution results from failed test cases of earlier solutions."
- Least-to-most prompting paradigm: A format where problems are broken into sub-questions (plans) followed by answers (executions), moving from simpler to complex. "When the plan is expressed as a sub-question and the execution as its answer, it is known as the least-to-most prompting paradigm~\citep{zhou2022least}."
- Logits: Pre-softmax model outputs used to compute probabilities for labels or tokens. "/ {are the logits output by the model when predicting the special tokens {
+"}/{â"}.}" - Majority voting (self-consistency): Selecting the final answer by voting across multiple sampled reasoning chains. "aggregates via majority voting (self-consistency)."
- Monte Carlo Tree Search (MCTS): A search algorithm that uses random simulations to guide tree exploration toward promising nodes. "which apply Monte Carlo Tree Search to explore reasoning paths"
- Next-token prediction task: Reformulating classification as predicting a special token at the end of the input sequence. "we follow~\cite{dong2024rlhf} to reformulate the prediction as a next-token prediction task"
- Plan–execution format: A step structure that first specifies a subgoal (plan) and then carries it out (execution). "in planâexecution format, each step is decomposed into (i) a plan, which formulates a sub-question or a subgoal, and (ii) an execution"
- Planning reward model: A learned scorer that evaluates the quality of proposed plans/subgoals before execution. "In the planning phase, candidate subgoals are sampled and scored by a planning reward model ($\text{PRM}_{\text{plan}$)"
- Process Reward Modeling (PRM): Training a reward model to score intermediate reasoning steps to guide search and pruning. "Process Reward Modeling (PRM)~\citep{wu2024inference} has shown strong performance by evaluating partial reasoning steps and guiding the search process accordingly."
- Process-supervised reward models (PRMs): Reward models trained with step-level labels to assess intermediate reasoning quality. "process-supervised reward models (PRMs)~\citep{lightman2023let,wu2024inference,hooper2025ets} to score and prune candidates."
- Reward-Based Searching: Test-time search guided by verifiers or reward models that score candidates and direct exploration. "According to~\cite{snell2024scaling}, two primary mechanisms for scaling test-time include (1) {Distribution-Based Sampling} and (2) {Reward-Based Searching}."
- Reward model: A model that assigns scores to candidates (plans or executions) to guide selection and pruning. "use reward models to guide pruning and selection."
- Rollout-based labeling strategy: Assigning step labels by generating multiple continuations (rollouts) and checking if any leads to a correct answer. "To annotate the steps, we adopt a rollout-based labeling strategy."
- Search tree: A tree structure whose nodes represent intermediate reasoning states expanded by the base LLM. "work by treating intermediate reasoning states as nodes in a search tree and expand continuations via the base LLM."
- Self-consistency: A selection tactic that relies on agreement across multiple sampled solutions to improve robustness. "aggregates via majority voting (self-consistency)."
- Softmax: A function that converts logits into probabilities used to compute rewards. "\text{softmax}(\ell(x))_{+}"
- Test-time scaling: Improving reasoning by expending more computation during inference without changing model parameters. "Test-time scaling methods improve reasoning quality without parameter updates by expending more computation at inference."
- Token budget: The total number of generated tokens used as a measure of computational cost. "when the token budget (log scale) is below ."
- Tree-based search: Exploration over a tree of reasoning states where branches represent alternative paths. "tree-based search with verifiers"
- Two-threshold rule: A sampling policy that stops early when enough high-scoring candidates appear or allocates extra samples when none exceed a lower threshold. "sampling in both the planning and execution phases follows a two-threshold rule."
- Verifier-based methods: Approaches that use outcome-level judges or reward models to assess candidate solutions. "and verifier-based methods, which rely on outcome-level judges~\citep{cobbe2021training, snell2024scaling} or process-supervised reward models (PRMs)"
- Verifiers: Models or procedures that check the correctness of outputs, guiding pruning and selection. "tree-based search with verifiers"
Collections
Sign up for free to add this paper to one or more collections.

