- The paper introduces DiDi-Instruct, a method to distill discrete diffusion language models into efficient few-step generators while preserving sample diversity.
- It employs a novel IKL divergence minimization and an auxiliary discriminator to provide robust adversarial reward signals for stable training.
- Empirical results show state-of-the-art perplexity improvements and latency-quality trade-offs, proving its effectiveness across language and protein sequence generation.
Ultra-Fast Language Generation via Discrete Diffusion Divergence Instruct
Introduction and Motivation
The paper introduces Discrete Diffusion Divergence Instruct (DiDi-Instruct), a distillation framework for accelerating discrete diffusion LLMs (dLLMs). The motivation is to overcome the inherent sequential bottleneck of autoregressive (AR) LLMs, which limits parallelism and throughput, and to address the inefficiency of existing dLLMs that require a large number of function evaluations (NFEs) to match AR model performance. Prior distillation methods for dLLMs, such as SDTT and DUO, have not achieved optimal trade-offs between speed and quality, and often lack a principled theoretical foundation. DiDi-Instruct is proposed as a theoretically grounded, efficient, and effective approach for distilling high-quality, few-step student generators from pre-trained dLLM teachers.
Theoretical Framework
The core of DiDi-Instruct is the minimization of an Integral Kullback–Leibler (IKL) divergence between the marginal distributions of the student and teacher models across the entire diffusion trajectory. This approach is inspired by distribution-matching principles from continuous diffusion distillation, specifically Diff-Instruct, but is adapted to the discrete setting of language modeling. The IKL objective is formulated as:
DIKL(qν∥qθ)=∫01ω(t)KL(qν(⋅,t)∥qθ(⋅,t))dt
where qν and qθ are the student and teacher marginals at time t, and ω(t) is a weighting function. The gradient of this objective is estimated using a score-function (policy gradient) approach, which is tractable in the discrete domain and avoids the need for differentiating through non-differentiable operations such as argmax.
A key technical component is the use of an auxiliary discriminator to estimate the log-density ratio between the student and teacher marginals, providing a reward signal for the policy gradient update. The optimal discriminator D∗ satisfies:
qθ(zt,t)qν(zt,t)=1−D∗(zt,t)D∗(zt,t)
This adversarial setup enables efficient and stable estimation of the reward signal required for distillation.
Algorithmic Innovations
The DiDi-Instruct pipeline consists of several algorithmic enhancements:
- Grouped Reward Normalization: To reduce the variance of the reward signal, rewards are normalized within each mini-batch using group relative policy optimization, stabilizing training.
- Intermediate-State Matching (Score Decomposition): The student is exposed to intermediate corruption levels by decomposing the score function, mitigating entropy collapse and improving generalization.
- Reward-Guided Ancestral Sampler (RGAS): At inference, the trained discriminator guides the sampling process via gradient tilting and multi-candidate re-ranking, improving sample quality and diversity, especially at low NFE budgets.
The overall training and inference pipeline is illustrated in the following schematic.
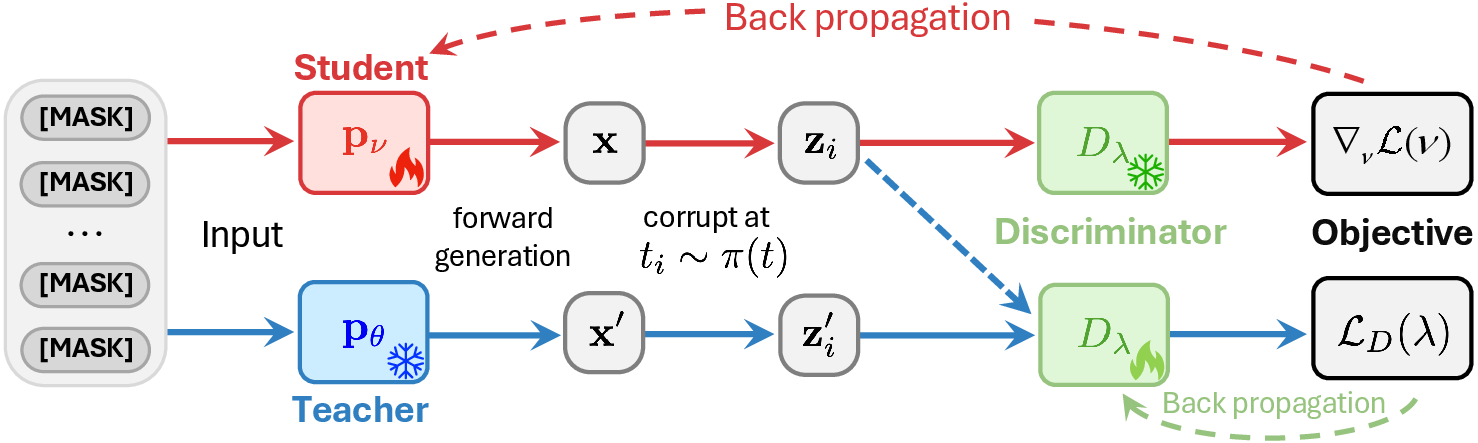
Figure 1: The DiDi-Instruct pipeline alternates between updating the discriminator and the student, using adversarial reward estimation and score decomposition for stable and efficient distillation.
Empirical Results
Language Generation Quality and Efficiency
DiDi-Instruct achieves state-of-the-art perplexity (PPL) across a wide range of NFEs, outperforming both the teacher dLLM and strong baselines such as GPT-2 and prior accelerated dLLMs. Notably, with only 16 NFEs, the distilled student surpasses the 1024-step teacher in PPL, and at 1024 NFEs, achieves a 24% reduction in PPL relative to the best baseline. Entropy remains nearly unchanged, indicating that sample diversity is preserved.
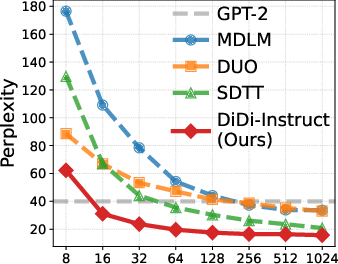
Figure 2: Perplexity as a function of NFEs, showing DiDi-Instruct's superior sample quality at all computational budgets.
Latency-Quality Trade-off
The RGAS decoding strategy yields a superior perplexity-latency trade-off compared to standard ancestral sampling (AS). DiDi-Instruct approaches the teacher's quality with significantly reduced computational cost, achieving lower PPL at all latency points.
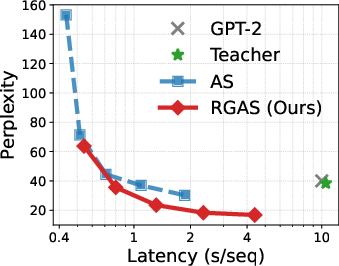
Figure 3: Perplexity versus latency, demonstrating that RGAS consistently achieves a better efficiency frontier than AS and the teacher model.
Model Scaling
Scaling experiments with 424M parameter models confirm that DiDi-Instruct's quality-efficiency advantages persist at larger scales. The distilled student achieves substantial PPL reductions (up to 88.5% at 8 NFEs) compared to the MDLM baseline, with entropy remaining stable.
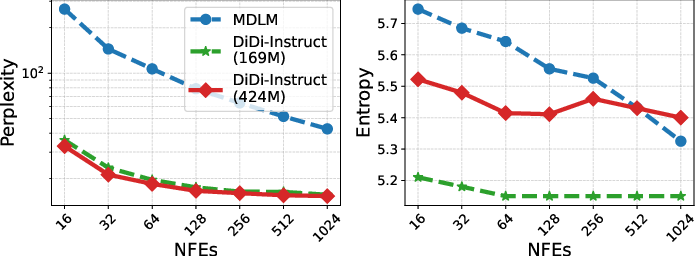
Figure 4: Scaling results for 424M models, with DiDi-Instruct significantly lowering PPL across all NFEs.
Generalization and Robustness
Zero-shot evaluation on seven out-of-domain corpora demonstrates that DiDi-Instruct maintains robust generalization, outperforming other distilled baselines and remaining competitive with undistilled models. Ablation studies confirm the necessity of each component, with score decomposition and time coupling being critical for stability and performance.
Protein Sequence Generation
DiDi-Instruct is also applied to unconditional protein sequence generation, distilling a DPLM-150M teacher. The student consistently achieves higher pLDDT scores (up to +10 at short sequence lengths) and more stable performance across NFEs and sequence lengths, with high-confidence structures generated at substantially fewer steps.
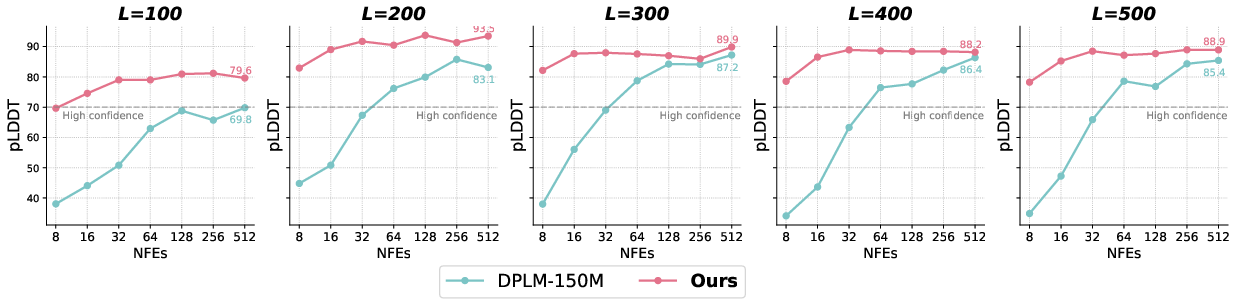
Figure 5: pLDDT comparison for protein sequence generation, with DiDi-Instruct outperforming the teacher in structural confidence and stability.
Implementation Considerations
- Resource Efficiency: DiDi-Instruct distillation is highly efficient, requiring only a single H100 GPU and completing in approximately one hour for 169M models, compared to 20+ GPU hours for multi-round methods.
- Architectural Flexibility: The framework is agnostic to the underlying dLLM architecture, requiring only access to the teacher's generative process and the ability to train a discriminator.
- Stability: Grouped reward normalization and score decomposition are essential for stable training, especially at low NFE budgets.
- Inference: RGAS provides a principled mechanism for leveraging the reward signal at inference, balancing quality and diversity.
Implications and Future Directions
DiDi-Instruct establishes a new state-of-the-art in fast, high-quality language generation with discrete diffusion models. The principled distribution-matching objective, combined with adversarial reward estimation and robust training/inference strategies, enables efficient distillation of few-step generators without sacrificing sample quality or diversity. The framework's applicability to both language and protein sequence generation suggests broad utility for discrete generative modeling.
Future work includes scaling DiDi-Instruct to billion-parameter models, which will require addressing GPU memory constraints for concurrent teacher, student, and discriminator training. The approach also opens avenues for further integration with preference optimization, reinforcement learning, and hybrid AR-diffusion architectures.
Conclusion
DiDi-Instruct provides a theoretically grounded, empirically validated framework for ultra-fast language generation via discrete diffusion distillation. By directly matching the student and teacher distributions across the diffusion trajectory, and leveraging adversarial reward estimation and guided sampling, it achieves strong improvements in both efficiency and quality. The method is robust, scalable, and generalizes well across domains, establishing a new benchmark for accelerated discrete generative modeling.