Generalized Correctness Models: Learning Calibrated and Model-Agnostic Correctness Predictors from Historical Patterns
Abstract: Generating accurate and calibrated confidence estimates is critical for deploying LLMs in high-stakes or user-facing applications, and remains an open challenge. Prior research has often framed confidence as a problem of eliciting a model's "self-knowledge", i.e., the ability of an LLM to judge whether its own answers are correct; this approach implicitly assumes that there is some privileged information about the answer's correctness that is accessible to the model itself. However, our experiments reveal that an LLM attempting to predict the correctness of its own outputs generally performs no better than an unrelated LLM. Moreover, we hypothesize that a key factor in building a "Correctness Model" (CM) is exposure to a target model's historical predictions. We propose multiple methods to inject this historical correctness information, creating a Generalized Correctness Model (GCM). We first show that GCMs can be trained on the correctness data from many LLMs and learn patterns for correctness prediction applicable across datasets and models. We then use CMs as a lens for studying the source of correctness prediction ability and its generalization, systematically controlling their training data and finding that answer phrasing is a strong predictor for correctness. We further explore alternative methods of injecting history without training an LLM, finding that including history as in-context examples can help improve correctness prediction, and post-hoc calibration can provide complementary reductions in calibration error. We evaluate GCMs based on Qwen3-8B across 5 model families and the MMLU and TriviaQA datasets, as well as on a downstream selective prediction task, finding that reliable LLM confidence estimation is a generalizable and model-agnostic skill learned by systematically encoding correctness history rather than a model-specific skill reliant on self-introspection.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI systems to know how likely their answers are to be correct, and to say that confidence in a trustworthy way. The authors show that LLMs are not especially good at judging their own answers compared to judging other models’ answers. Instead, a better way is to train a separate “helper” model to predict correctness by learning from lots of past examples across many different LLMs. They call this helper a Generalized Correctness Model (GCM).
Think of it like a skilled coach who reviews many players’ past games to learn patterns of when a play succeeds or fails. That coach can then give good advice about the chance a new play will work, regardless of which player tries it.
Key Questions
The paper asks two main questions and follows up with practical ones:
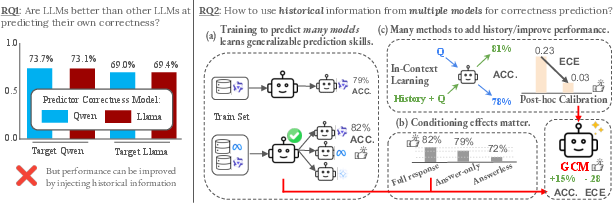
- RQ1: Are LLMs better at predicting whether their own answers are correct than other LLMs?
- RQ2: How does using “history” (past answers and whether they were right or wrong) from many models help build better, well-calibrated correctness predictions?
From RQ2, they explore three sub-questions:
- RQ2a: If we train on many models’ histories, do we learn general strategies that transfer to new models and tasks?
- RQ2b: Which inputs matter most for predicting correctness (the question, the final answer, the full wording of the response, or the model’s identity)?
- RQ2c: Can we add “history” without training a new model, using tricks like in-context examples or calibration after the fact?
Methods and Approach
Here’s how they studied these questions, using everyday analogies to explain terms:
- Correctness Model (CM): A CM is any method that estimates the probability an answer is correct. In simple terms, it takes a question and the model’s response and outputs a confidence like “I’m 80% sure this is right.” Calibration means those numbers should match reality over time; if it says 80%, it should be right about 80% of the time.
- Generalized Correctness Model (GCM): This is a CM trained on the combined histories of many LLMs. It learns patterns of correctness that work across different models, like a coach who watches many teams to understand strategies that generally succeed.
- Datasets: They used MMLU (a big test of many subjects) and TriviaQA (a question-answering dataset). For each question, they collected the model’s full response and a label saying whether it was correct, creating a “correctness dataset.”
- Measuring confidence: A practical trick they used was to ask a model something like, “Answer ‘yes’ or ‘no’: will this response be correct?” and measure the probability of “yes.” This acts as the model’s confidence score. They compared this to the GCM’s predictions.
- Training setups:
- Specific Correctness Model (SCM): Trained on one target model’s history (one player’s past games).
- GCM: Trained on the combined histories of many models (many players’ games), so it’s model-agnostic.
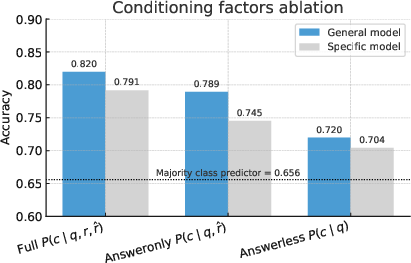
- Ablations (controlled tests): They tried versions that only see the question, only see the question plus the final answer, or see the full response with all wording. This shows which parts matter most for predicting correctness.
- Alternatives to training:
- In-context learning (ICL): Instead of training, they paste a few similar past examples into the prompt, so the model can “look” at history on the fly.
- Post-hoc calibration: After getting raw confidence scores, they adjust them using a small set of labeled examples to make the numbers better match real accuracy, like a thermometer that gets recalibrated to read the right temperature.
- Evaluations: They used simple metrics:
- Accuracy: How often the CM correctly predicts “right” vs “wrong.”
- Calibration error (ECE and RMSCE): How close the confidence numbers are to reality (lower is better).
- AUROC: A summary of how well the CM separates correct answers from incorrect ones (higher is better).
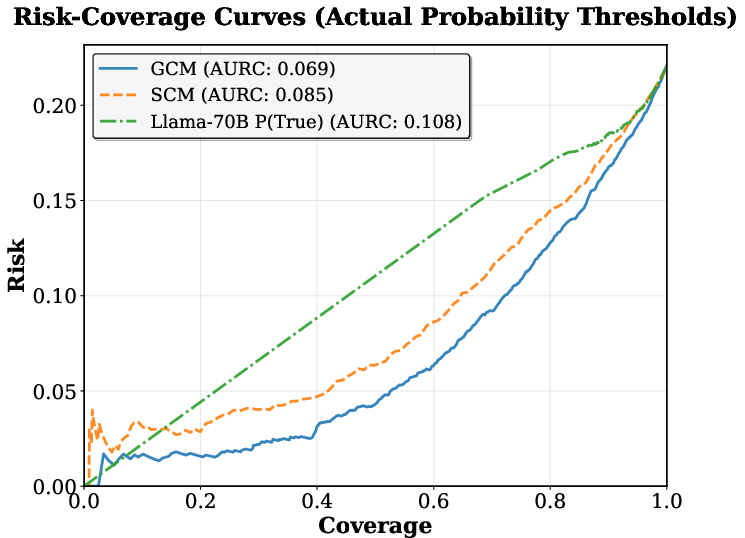
- Selective prediction: A practical test where the system chooses to answer only when its confidence is high enough, aiming for a good balance between coverage (answering many questions) and risk (not being wrong too often).
Main Findings and Why They Matter
- LLMs don’t have special “self-knowledge” for correctness: An LLM is not better at judging its own answer than it is at judging another model’s answer. Stronger models do better overall because they know more facts, not because they can introspect their own output.
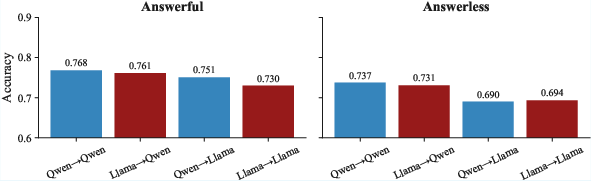
- History helps a lot, and generalizes: A GCM trained on many models’ past answers learns strategies that work across different model families and sizes. It often beat:
- SCMs trained on a single model’s history.
- The self-confidences of much larger models (for example, outperforming a 70B-parameter model’s own confidence scores).
- Even when tested on new, held-out models, the GCM stayed strong.
- What matters in the input:
- The full response phrasing is a strong clue. How an answer is worded (e.g., hedging like “I think…”, the level of detail, or reasoning steps) often signals correctness.
- World knowledge inside the CM helps. If the CM knows the subject matter, it can judge whether the final answer makes sense.
- The model’s identity (which LLM produced the answer) matters less than you might think. The learned patterns are largely model-agnostic.
- Transferring to new datasets is harder but fixable: A GCM trained on MMLU did slightly worse on TriviaQA without adjustment. However, simple post-hoc calibration with a small portion of the new dataset made it match or beat the specialized model, with very low calibration error.
- Training-free additions can help:
- In-context learning improves correctness for larger base models when they can use rich examples in the prompt.
- Post-hoc calibration reliably reduces calibration error; it’s an easy add-on when moving to new data.
- Better real-world behavior: In selective prediction, the GCM delivered a safer trade-off, answering more questions at low risk. In other words, it’s better at knowing when to answer and when to abstain.
Implications and Impact
This work suggests a shift in how we build trust in AI answers:
- Don’t rely on “self-introspection”: LLMs aren’t uniquely good at judging themselves. Instead, train model-agnostic correctness predictors on rich history across models.
- Build calibration into deployment: Calibrated confidence helps decide when to trust an answer, when to ask for help, or when to abstain. This is crucial in high-stakes areas like medicine, law, or education.
- A practical recipe: Use a GCM trained on many models’ histories, and apply post-hoc calibration when switching to new tasks or datasets. If training isn’t possible, use in-context examples for larger models, but expect higher cost and possibly weaker calibration.
- Safer, more reliable AI systems: With well-calibrated correctness predictions, systems can reduce hallucinations, route tough questions to experts, and set confidence thresholds that balance usefulness and safety.
Overall, the big idea is that reliable, well-calibrated correctness prediction is a general, learnable skill. It comes from systematically encoding historical patterns across models—not from a single model’s private “self-knowledge.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address to strengthen, stress-test, and generalize the proposed Generalized Correctness Models (GCMs):
- Task and domain scope: Evaluation is limited to QA-style datasets (MMLU, TriviaQA). It remains unknown how GCMs perform on open-ended generation (summarization, code synthesis, dialogue), multimodal tasks, safety/jailbreak detection, or retrieval-augmented settings.
- Dataset diversity and shift: Cross-dataset generalization is only tested from MMLU to TriviaQA and shows degraded calibration. Which dataset characteristics (topic, ambiguity, answer format, reasoning depth) drive failures, and how to robustify GCMs to broader domain and format shifts?
- Labeling reliability: Correctness is judged by an automatic “judge model with ground truth access.” The paper does not quantify judge accuracy, bias across subjects, or error rates versus human adjudication. How sensitive are results to judge choice and to label noise?
- Binary correctness granularity: Only binary labels are used. Can GCMs calibrate partial credit, degrees of factuality, reasoning-step correctness, or ambiguity-aware judgments, and how does this affect calibration and downstream decisions?
- Self-knowledge claim scope: The claim that LLMs lack privileged self-knowledge is supported by few model pairs and specific elicitation protocols. Do conclusions hold across more architectures, sampling temperatures/decoding regimes, hidden-state probing-based self-evaluation, reflection/self-consistency, or training-time introspection signals?
- Confounding from model strength: Stronger predictors outperform weaker ones at correctness prediction; it is unclear how much of the “no self-knowledge” result is explained by capacity/knowledge, versus a fundamental absence of privileged internal signals.
- Content leakage across models: The GCM is trained and tested on the same questions across different target models, enabling question-level cross-model transfer. How well do GCMs perform on entirely unseen questions for all models (i.e., content-wise OOD), and how does performance degrade without shared-question exposure?
- New target model adaptation: The paper shows some held-out model generalization, but does not study data efficiency. How many historical examples are needed to adapt a GCM to a new target model identity, and what are effective few-shot or online adaptation strategies?
- Nonstationarity and drift: Real systems change (model updates, prompts, tools). How robust is a GCM to temporal drift in a target model’s behavior, and can it adapt online while maintaining calibration guarantees?
- Robustness to phrasing manipulation: Since answer phrasing is a strong predictor, can target models (or adversaries) manipulate stylistic markers to falsely inflate confidence predictions? What defenses ensure robustness to style transfer, paraphrasing, and adversarial rephrasing?
- Feature ablations beyond text: The CM does not exploit target-model logits, token log-prob features, entropy, or other auxiliary signals. Do hybrid CMs that combine textual inputs with numeric uncertainty features yield further gains or better robustness?
- Capacity and scaling laws: Only one CM backbone (Qwen3-8B) is thoroughly explored. What are scaling relationships between CM capacity, amount/diversity of historical data, and calibration/predictive performance?
- Training objective and calibration loss: The paper notes batch-size choices aid ECE, but does not compare proper scoring rules (e.g., Brier score, focal losses) or calibration-aware objectives. Which objectives best trade off accuracy and calibration under shift?
- Calibration metrics and guarantees: Evaluation focuses on ECE/RMSCE/AUROC; no Brier score, NLL, conditional (per-topic) calibration, worst-group calibration, or finite-sample uncertainty. Can we provide formal coverage or risk-control guarantees (e.g., conformal prediction) for selective prediction?
- Retrieval and ICL design: ICL uses k=5 semantic neighbors without ablations on k, retriever choice, embedder, or memory contamination. What retrieval configurations and selection policies best improve calibration and robustness, and how do they scale?
- Post-hoc calibration sample complexity: Spline calibration with 5% data is reported but not stress-tested. How sensitive are gains to calibrator type, sample size, data shift, and overfitting, and can adaptive/online calibrators maintain low ECE under distribution drift?
- Generalization to proprietary and multilingual models: Experiments use open models and English datasets. Do GCMs transfer to closed-source LLMs (API-only), multilingual settings, low-resource languages, or domain-specific models (biomed, legal)?
- Safety and fairness analyses: There is no subgroup analysis (by subject, difficulty, demographics) of calibration/coverage. Do GCMs introduce or reduce disparate calibration errors across subpopulations, and how should selective prediction thresholds be set to ensure equitable risk?
- Broader downstream tasks: Only selective prediction is evaluated. How do GCMs impact routing-to-experts, reranking, aggregation/ensembling, active learning, or rejection sampling pipelines in realistic applications?
- Comparative baselines: The study does not compare against small non-LLM calibrators (e.g., logistic/beta/isotonic on engineered features), hidden-state probes of target models, or ensemble uncertainty methods. Where do GCMs sit relative to these alternatives in accuracy, calibration, and cost?
- Data governance and privacy: Training on historical outputs of many models may involve sensitive prompts/responses. How can one construct privacy-preserving GCMs, respect licensing constraints, and prevent leakage of proprietary model behaviors?
- Interpretability of learned cues: While phrasing and world knowledge are implicated, there is no systematic feature-level analysis (e.g., epistemic markers, hedging, logical consistency). Which linguistic or semantic cues are most predictive, and can we make them actionable or controllable?
- Scalability to many targets: The GCM is trained on eight models. Does performance saturate or improve with dozens/hundreds of target models, and how can we avoid negative transfer or catastrophic interference in a continually growing registry?
- Reproducibility and variance: Results are reported without confidence intervals or repeated runs. What is the variability across seeds/splits, and are improvements statistically significant across datasets and model families?
Practical Applications
Immediate Applications
The findings enable several deployable use cases across sectors. Each bullet gives the application, sector(s), a concrete tool/workflow idea, and key assumptions/dependencies.
- Correctness-as-a-Service layer for LLM platforms (software/AI infrastructure)
- Tool/workflow: A model-agnostic “GCM microservice” that takes query + model response and returns calibrated P(is_correct), exposing both probability and uncertainty metrics (ECE, RMSCE, AUROC). Integrate as a prefill-only call for low latency.
- Sectors: Software, cloud AI platforms, enterprise AI.
- Assumptions/Dependencies: Access to historical correctness datasets across multiple models; reliable ground-truth labels (including a judge model or human labels); initial fine-tuning capacity (e.g., LoRA on ~8B models); adherence to a standardized elicitation prompt for consistent confidence extraction.
- Selective prediction gating to reduce user risk (cross-industry)
- Tool/workflow: A “confidence gate” that abstains or escalates when predicted risk exceeds threshold, optimizing risk-coverage trade-offs; configurable thresholds per domain.
- Sectors: Healthcare (triage/chatbots, clinical coding), Finance (customer support, reporting), Legal (contract analysis), Education (tutoring systems), Public sector services.
- Assumptions/Dependencies: Organizational consensus on acceptable risk thresholds; routing paths (to humans or stronger models); calibration monitoring to ensure thresholds remain appropriate under drift.
- Expert routing and model orchestration (multi-model environments)
- Tool/workflow: Route queries to the model with the highest predicted correctness or escalate to human experts when no model exceeds confidence; combine with re-ranking of multiple candidate responses.
- Sectors: Customer support, enterprise knowledge bases, developer tools, research assistants.
- Assumptions/Dependencies: Multiple model endpoints; per-model response capture; GCM trained on aggregated histories of those models; orchestration infrastructure.
- Hallucination detection and reliability labeling in user-facing QA/search (daily life + platforms)
- Tool/workflow: A “reliability meter” UI element that displays calibrated correctness probabilities next to answers, with automatic warning banners for low-confidence outputs; optional content filters.
- Sectors: Consumer assistants, search engines, media platforms, education tools.
- Assumptions/Dependencies: UX capacity to present confidence; guardrail policies; consistent prompt formats; ongoing recalibration under dataset shift.
- Calibration monitoring and audit dashboards (policy + compliance)
- Tool/workflow: A “Calibration Monitor” that tracks ECE, RMSCE, AUROC for deployed assistants across models and domains; supports periodic post-hoc calibration; produces audit reports.
- Sectors: Regulated industries (healthcare, finance), public sector procurement.
- Assumptions/Dependencies: Logging of predictions and outcomes; governance for data retention; small labeled holdout sets to recalibrate (e.g., 5% samples for spline calibration).
- Rapid dataset-shift adaptation via post-hoc calibration (operations)
- Tool/workflow: Use spline calibration (or beta/isotonic/Platt) with a small labeled slice (~5%) of the new dataset to align probabilities to a new domain while preserving AUROC.
- Sectors: Enterprise deployments, content moderation, knowledge management.
- Assumptions/Dependencies: Availability of small labeled set in new domain; stable labeling process; the underlying GCM’s ranking power is OOD-robust (as observed).
- Model-agnostic ensemble routing and re-ranking (software + developer tools)
- Tool/workflow: A “response ranker” that scores multiple candidate answers (from one model via sampling or several models) and selects the highest predicted correctness; pairs with rejection sampling.
- Sectors: Code assistants, documentation Q&A, retrieval-augmented systems.
- Assumptions/Dependencies: Ability to collect multiple candidates; consistent formatting of query/response; enough world knowledge in the GCM to leverage answer phrasing and content.
- Training-free in-context history injection for strong models when fine-tuning is not feasible
- Tool/workflow: Retrieve top-k similar (q, r, answer, correctness) examples and prompt a larger model to provide calibrated verbal probabilities for correctness; useful for quick pilots.
- Sectors: Prototyping, research, teams with limited training pipelines.
- Assumptions/Dependencies: Vector database and embeddings; higher inference costs; minimum base capability (ICL benefits were observed with larger models more than ~8B); careful prompt design.
- Confidence-aware UI/UX in tutoring and assistance (daily life + education)
- Tool/workflow: Show confidence next to hints/solutions; reveal steps only above a threshold; adapt difficulty when confidence is low to encourage clarification.
- Sectors: Education technology, language learning apps, study assistants.
- Assumptions/Dependencies: Reliable domain-specific labeling; age-appropriate UX; periodic recalibration; safeguards to discourage misplaced trust in high-confidence wrong answers.
- Procurement and deployment checklists for calibrated AI (policy)
- Tool/workflow: Vendor requirements to report ECE/RMSCE/AUROC on representative datasets and demonstrate post-hoc calibration on held-out domains; include an “assurance layer” in contracts.
- Sectors: Government, regulated enterprise procurement.
- Assumptions/Dependencies: Agreement on metrics and thresholds; representative test suites; audit access to logs and calibration procedures.
Long-Term Applications
These opportunities benefit from further research, scaling, or development prior to wide deployment.
- Industry-wide calibration standards and certification programs (“Calibration Label”)
- Tool/workflow: A standardized label (akin to a nutrition label) that certifies correctness calibration quality across tasks, with domain-specific benchmarks and drift testing.
- Sectors: Cross-sector, regulators, standards bodies.
- Assumptions/Dependencies: Consensus on metrics and reporting; third-party auditing; sector-specific datasets and acceptable thresholds.
- Confidence-driven reinforcement learning and training signals
- Tool/workflow: Use correctness probabilities as auxiliary rewards to improve generation policies or discourage low-quality, overconfident outputs.
- Sectors: Model development, platform training pipelines.
- Assumptions/Dependencies: Safe RL tooling; stable mapping from correctness to reward; guardrails to avoid gaming; robust evaluation.
- Autonomous agents and robotics with correctness gating for actions
- Tool/workflow: Route uncertain plans to human oversight; ask clarifying questions when confidence is low; gate tool execution behind correctness thresholds.
- Sectors: Robotics, industrial automation, energy operations.
- Assumptions/Dependencies: Real-time inference constraints; reliable correctness for non-text actions; multimodal extensions; validated safety cases.
- Domain-specialized GCMs (e.g., medical, legal, finance) with strong world knowledge
- Tool/workflow: Train GCMs on curated, high-quality correctness histories with domain judges; integrate with domain ontologies and retrieval for improved world-knowledge leveraging.
- Sectors: Healthcare, legal, finance, scientific R&D.
- Assumptions/Dependencies: Expert-labeled correctness at scale; privacy-preserving pipelines; domain shifts and evolving guidelines.
- Continual learning and drift-aware GCMs
- Tool/workflow: Ongoing ingestion of correctness histories; automated re-calibration; alerts when ECE exceeds thresholds; active learning to target mislabeled/ambiguous cases.
- Sectors: Enterprise AI operations, large platforms.
- Assumptions/Dependencies: Robust data governance; monitoring infra; label budget; drift detection mechanisms.
- Federated or privacy-preserving aggregation of correctness histories
- Tool/workflow: Share calibration signals across organizations without sharing raw data (via federated learning or secure aggregation) to improve model-agnostic GCMs.
- Sectors: Healthcare networks, finance consortia, gov agencies.
- Assumptions/Dependencies: Privacy tech maturity; legal agreements; standardized logging; interoperable formats.
- Calibration-aware model marketplaces and SLAs
- Tool/workflow: Use GCM benchmarks to set risk-aware pricing tiers; SLAs specify maximum ECE; routing frameworks choose models based on cost vs predicted correctness.
- Sectors: AI marketplaces, cloud providers.
- Assumptions/Dependencies: Market adoption; trustworthy benchmarking; transparent reporting; economic incentives aligned with calibration quality.
- Generation-side phrasing coaching to reduce misleading confidence markers
- Tool/workflow: Train generators to modulate epistemic markers (e.g., avoid overly assertive phrasing) informed by the paper’s finding that answer phrasing signals correctness; couple with post-generation calibration.
- Sectors: Content generation, education, customer service.
- Assumptions/Dependencies: Avoiding style-only changes that mask true uncertainty; human factors research; maintaining usability while reducing misleading confidence cues.
- Multimodal GCMs (code, vision, audio) and agent tool-use correctness
- Tool/workflow: Extend correctness prediction to code execution results, perception tasks, and tool pipelines; score end-to-end task correctness rather than text alone.
- Sectors: Software engineering, autonomous systems, media platforms.
- Assumptions/Dependencies: Multimodal correctness datasets; reliable judges; domain-specific metrics; unified interfaces.
- Regulation-driven risk coverage policies in public services
- Tool/workflow: Formal guidelines that mandate abstention under defined thresholds; audit trails for abstentions; public reporting of calibration metrics.
- Sectors: Government services, public health, legal aid.
- Assumptions/Dependencies: Legislative frameworks; operational capacity; fairness analysis to prevent disproportionate abstention on marginalized queries.
- Lightweight/edge GCMs for constrained devices
- Tool/workflow: Distilled or quantized correctness predictors that run on-device to gate local assistants (e.g., medical wearables, industrial HMIs).
- Sectors: IoT, healthcare devices, energy field ops.
- Assumptions/Dependencies: Efficient architectures; edge calibration; offline labeling strategies; security hardening.
- Open hubs for multi-model correctness histories and GCM training kits
- Tool/workflow: Community datasets of (q, r, answer, correctness), evaluation harnesses, and LoRA-based training recipes; reproducible baselines on AUROC/ECE across families.
- Sectors: Academia, open-source, industry R&D.
- Assumptions/Dependencies: Licensing and data-sharing norms; judge reliability; representativeness across domains; maintenance and governance.
Notes on feasibility across applications:
- The paper shows strong cross-model generalization and improved calibration without relying on self-knowledge, but cross-dataset transfer requires post-hoc calibration (often achievable with ~5% labeled samples).
- World knowledge and answer phrasing are key drivers of correctness prediction; gains depend on the base model’s capability and the availability/quality of correctness labels.
- Training-free ICL helps mostly with larger models and increases inference costs; fine-tuned GCMs are more efficient and exhibit lower calibration error.
- Reliable, privacy-compliant logging and labeling (including judge models or human graders) are critical dependencies; label noise and domain drift need active monitoring and periodic recalibration.
Glossary
- Ablation: Experimental removal of components or inputs to assess their impact on performance. "We ablate the GCM and SCM into Answerless Correctness Models, and further introduce an Answer-only model type on MMLU as an intermediate ablation."
- Answer-only Correctness Model: A correctness predictor conditioned on the question and the extracted answer, without the full response text, modeling . "We train Answer-only Correctness Models $P(c|q, \hat{r)$} by extracting the answer choice letter from the target model's full response and training a SCM/GCM on the query and answer letter."
- Answerless Correctness Model: A correctness predictor conditioned only on the question, modeling . "We train Answerless Correctness Models ... by finetuning a LLM to predict the probability that a target model will respond correctly to a query given only query, without the model response."
- AURC (Area Under the Risk-Coverage curve): A metric summarizing the trade-off between error (risk) and answered fraction (coverage); lower is better. "Risk-Coverage Curves for Selective Prediction, lower AURC curves are better."
- AUROC (Area Under the Receiver Operating Characteristic): A threshold-independent metric of discrimination performance; higher indicates better ability to separate correct from incorrect. "We also include the Area Under the Curve of the Receiver Operating Characteristic (AUROC) which gives a more holistic estimate of predictive power."
- Beta calibration: A parametric post-hoc probability calibration method based on the beta distribution. "We also test alternate posthoc calibration strategies including beta-calibration ..."
- ECE (Expected Calibration Error): A scalar measure of how closely predicted probabilities match empirical correctness frequencies. "We utilize a specialized optimal batch size to obtain well calibrated ( .03 ECE) Correctness Models out of the box with cross-entropy loss ..."
- Epistemic markers: Linguistic cues indicating uncertainty or belief that can correlate with correctness. "these findings align with work like \citet{zhou2024relying}, who study the importance of epistemic markers in confidence"
- GCM (General Correctness Model): A correctness predictor trained on historical data from multiple models to learn model-agnostic correctness patterns. "We train General Correctness Models (GCMs) by finetuning a LLM -- in this paper, Qwen-3-8B -- on the concatenation of 8 correctness datasets ..."
- ICL (In-Context Learning): Supplying examples within the prompt so the model can condition on retrieved history without parameter updates. "We inject semantic ICL examples into models by embedding the train split of a correctness dataset () into a vector database, and retrieving the top k=5 ... to inject into the prompt ..."
- Instruction tuning: Fine-tuning LLMs on instruction-following data to improve adherence to prompts. "Unless otherwise noted, all models used in this work are instruction tuned models."
- Isotonic regression: A non-parametric monotonic mapping used for post-hoc probability calibration. "We also test alternate posthoc calibration strategies including beta-calibration, isotonic regression, or Platt scaling algorithms to map raw model probabilities to calibrated probabilities."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that inserts trainable low-rank adapters into a pretrained model. "we use LoRA \citep{hu_lora_2021} with rank 32 and batch size 16 and train for 1 epoch ..."
- Logit-based confidences: Confidence scores derived from raw model logits, often by probing a specific token probability. "we extract confidences from models via logit based confidences for all methods we study."
- MMLU (Massive Multitask Language Understanding): A benchmark dataset covering diverse subjects to assess broad knowledge and reasoning. "Our main analysis is based on the MMLU dataset \citep{hendrycks_measuring_2021} ..."
- OOD (Out-of-Distribution): Settings or data points that differ from the training distribution, used to evaluate generalization. "Out-of-Distribution Generalization. Qwen3-8B GCM predicting correctness on Phi-3-mini and Qwen3-32B, models that are held out from the GCM training set."
- Parametric knowledge: Knowledge encoded in model parameters (as opposed to retrieved or external), affecting its ability to judge correctness. "We attribute this to Qwen2.5-7B being a stronger model with greater parametric knowledge of the true answer to the MMLU questions ..."
- Platt scaling: A sigmoid-based post-hoc calibration mapping often applied to classifier scores to produce calibrated probabilities. "We also test alternate posthoc calibration strategies including beta-calibration, isotonic regression, or Platt scaling algorithms to map raw model probabilities to calibrated probabilities."
- P(True): A probing-based confidence elicitation that measures the probability the model answers correctly, typically via a “yes” token. "We elicit logit based confidences “P(True)” by measuring the probability of the token “yes” after exposure to a prompt and a model response appended with the question ..."
- Prefill-only method: An inference mode that uses only the initial forward pass (prefill) without generating long outputs, improving efficiency. "the GCM is a inference efficient prefill only method, with one evaluation on MMLU ... requiring only 7.3 minutes."
- RMSCE (Root Mean Squared Calibration Error): An adaptively binned calibration metric measuring the squared deviation between predicted and empirical probabilities. "we include the Root Mean Squared Calibration Error \citep{hendrycks_deep_2019} an adaptively binned measurement of calibration."
- SCM (Specific Correctness Model): A correctness predictor trained on one target model’s historical data to predict that model’s correctness. "We train Specific Correctness Models (SCMs) by finetuning a LLM on a correctness dataset to predict the correctness of a response given a query."
- Selective prediction: A framework where the system abstains on uncertain cases to trade coverage for lower risk. "Selective prediction requires a system to selectively abstain from examples that are unlikely to be correct ..."
- Spline calibration: A smooth, flexible post-hoc calibration method using spline functions to map raw confidences to calibrated probabilities. "We posthoc calibrate models by holding out 5\% of a correctness dataset and using the spline calibration ..."
- Verbalized confidences: Confidence estimates produced by the model in natural language as explicit probabilities. "We elicit verbalized confidences \citep{tian_just_2023} by prompting the model to give the “calibrated percent probability that the answer will be correct”."
Collections
Sign up for free to add this paper to one or more collections.