- The paper demonstrates that intrinsic confidence measures, when rescaled with Platt scaling, significantly enhance calibration in code generation tasks.
- It compares intrinsic versus reflective methods across function synthesis, code completion, and program repair, highlighting differences in consistency.
- Findings imply that better-calibrated LLMs aid in effective resource allocation for code review and risk mitigation in software development.
Calibration and Correctness of LLMs for Code
Introduction
The integration of generative LLMs into software engineering has become widespread, particularly in tasks such as code completion, review, and automatic code generation. These models are, however, prone to generating incorrect code, thus necessitating an effective mechanism to gauge the confidence in their predictions. The calibration of LLMs refers to the statistical alignment between predicted confidence levels and actual correctness rates—a well-calibrated model provides confidence scores that closely match the empirical probability of correctness. This paper presents a comprehensive study on the calibration of code-generating LLMs, particularly focusing on the efficacy of various confidence measures and calibration methods.
Background
Calibration Fundamentals
Calibration in machine learning models, especially in prediction tasks, ensures that the model's confidence outputs reflect true correctness probabilities. A model is considered well-calibrated if, for instance, out of all instances where the model predicts an event with 70% probability, the event actually occurs approximately 70% of the time. This principle is crucial for software development, where wrongly calibrated models may lead to inefficient resource allocation in code review processes.
Code-Generative Tasks
The text outlines three primary tasks where LLMs are extensively utilized:
- Function Synthesis: Generation of entire function bodies from natural language descriptions (Docstrings).
- Line-Level Code Completion: Predicting the next line or sequence of code based on preceding context.
- Program Repair: Correcting buggy code snippets into functionally correct versions.
For each task, both exact-match correctness and test-passing correctness are considered, acknowledging the complexities and potential inadequacies inherent in each approach.
Methodology
Datasets and Models
The study utilizes multiple datasets, including DyPyBench for real-world line-level completion, HumanEval and MBPP for function synthesis, and Defects4J and SStubs for program repair. The models evaluated include OpenAI's Codex and GPT-3.5-Turbo-Instruct, as well as the open-source CodeGen2, each offering varying capabilities and scale.
Confidence Measures
- Intrinsic Measures: Average Token Probability and Total Generated Sequence Probability, derived natively from model output probabilities.
- Reflective Measures: Verbalized Self-Ask and Question Answering probabilistic logits, obtained through additional model queries designed to assess self-predicted confidence in outputs.
Calibration Metrics
The calibration performance is quantified using:
- Brier Score: Measures the mean squared difference between predicted probabilities and observed outcomes.
- Expected Calibration Error (ECE): Represents the average deviation of predicted probabilities from true correctness probabilities across binned confidence levels.
- Skill Score (SS): Compares model performance against a naive (unskilled) predictor.
Results
Calibration Analysis
The study finds that without any rescaling, intrinsic measures generally perform slightly better in calibration than reflective ones. However, the application of Platt scaling significantly enhances calibration, particularly for intrinsic measures such as Total Probability, bringing models like Codex close to a Skill Score improvement of 0.15 in function synthesis tasks.
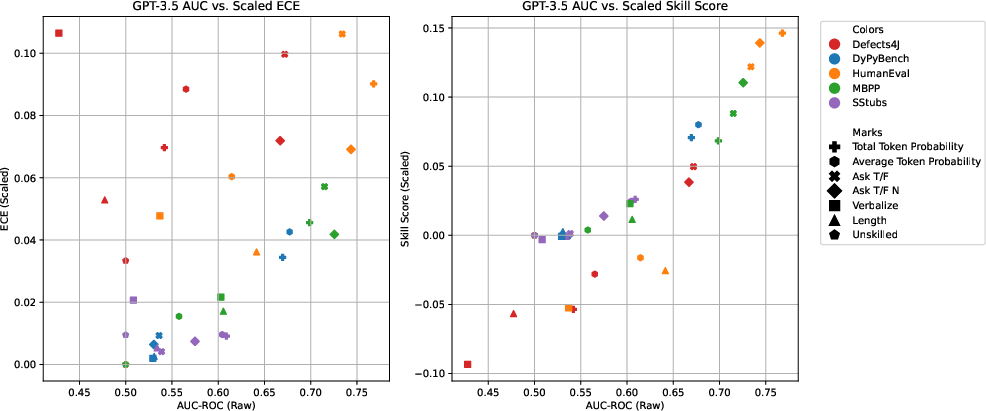
Figure 1: AUC vs Scaled Skill Score (right) for GPT-3.5 confidence measures on all tasks.
RQ Findings
- Intrinsic Calibration: Measures like Total Probability show reasonable calibration with rescaling, albeit with some inconsistencies.
- Reflective Calibration: Reflective measures, particularly those based on direct model output like Verbalized Self-Ask, generally exhibit poorer calibration compared to intrinsic measures.
- Impact of Rescaling: Platt scaling improves the Skill Score and reduces ECE across tasks, confirming its utility in refining confidence measures.
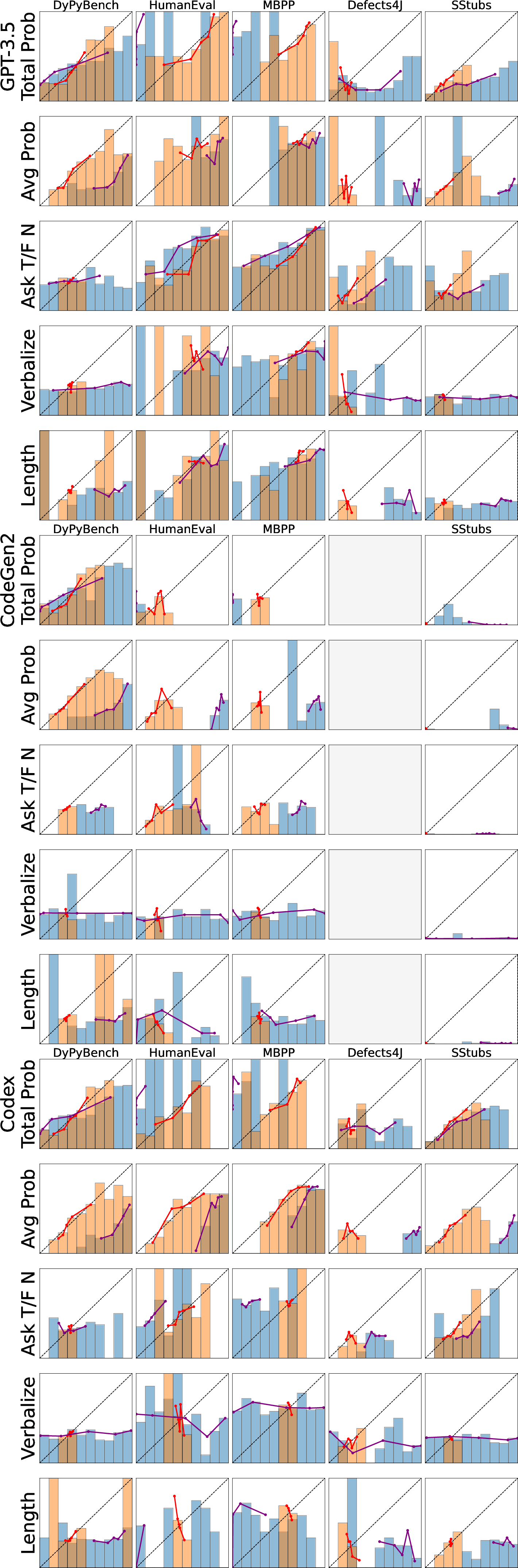
Figure 2: Calibration plots per model, confidence measure, and task.
Discussion
The enhancement of calibration through rescaling suggests a path forward for utilizing confidence measures in real-world software engineering. The capability to distinguish between varying levels of correctness allows developers to allocate review resources more effectively, mitigate risks, and potentially integrate more sophisticated, probabilistic quality-control processes into software development practices.
Conclusion
Generative LLMs hold promise for increasing productivity in software engineering. However, the study highlights the necessity of well-calibrated confidence measures to maximize their utility while minimizing risks. Future research should focus on refining these confidence measures, exploring alternative calibration techniques, and validating findings across larger, diverse datasets to ensure robust integration into software development workflows.


