- The paper proposes UniVid, which integrates a multimodal LLM with a DiT-based diffusion decoder to deliver state-of-the-art video understanding and generation.
- It introduces Temperature Modality Alignment for balancing semantic and visual fidelity and employs Pyramid Reflection to refine temporal reasoning.
- Evaluations on benchmarks like VBench-Long and video QA datasets show UniVid outperforming baselines, achieving a notable 2.2% improvement in overall scores.
UniVid: The Open-Source Unified Video Model
The paper presents UniVid, an innovative unified video model that tackles video understanding and generation challenges by integrating a multimodal LLM (MLLM) and a diffusion video decoder. UniVid introduces two mechanisms, Temperature Modality Alignment and Pyramid Reflection, which improve video modeling capabilities. This essay explores the practical implications and implementation strategies of UniVid for achieving superior performance in video tasks.
Architecture and Components
Multimodal LLM Integration
UniVid employs a state-of-the-art MLLM as its core component, which processes both textual and visual inputs. The model is equipped with ViT and VAE for encoding visual information, projecting it into a unified token space alongside text inputs. This integration allows for the generation and understanding of videos through rich semantic embeddings.
Diffusion Video Decoder
The model uses a DiT-based diffusion video decoder for high-fidelity video generation. Visual tokens from the MLLM are conditioned using cross-attention mechanisms within a latent space. This approach effectively synthesizes realistic video sequences by dynamically adjusting semantic and visual fidelity throughout the generation process.
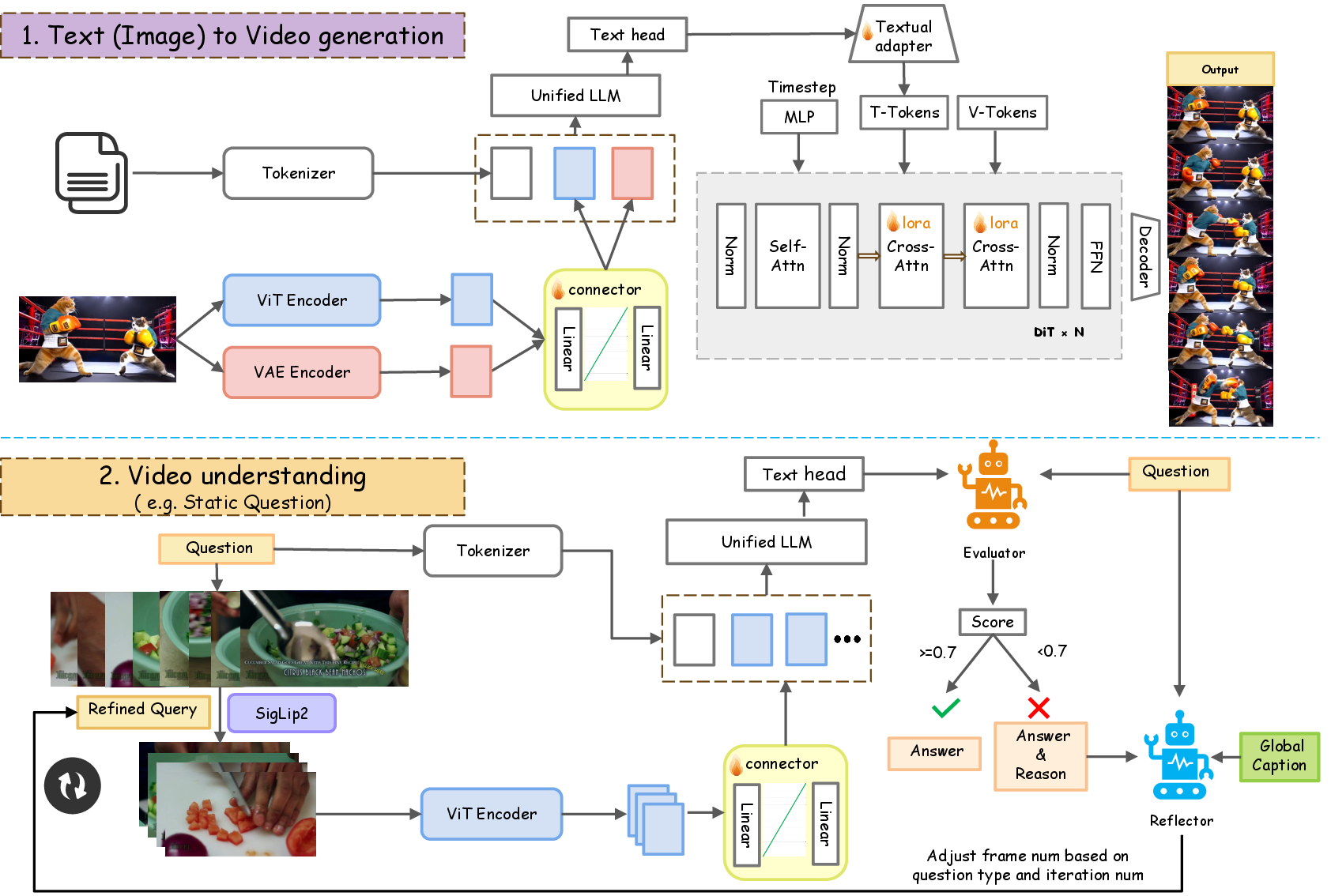
Figure 1: Overall architecture of our proposed UniVid for unified video understanding and generation. UniVid couples an autoregressive-based MLLM with a DiT-based diffusion decoder.
Key Innovations
Temperature Modality Alignment
UniVid introduces Temperature Modality Alignment to solve the imbalance of visual and textual token influence during generation. By manipulating the cross-modal attention schedule, early stages are dominated by semantic guidance, while later stages focus on refining visual details. This alignment ensures semantic faithfulness without compromising visual quality, addressing limitations found in previous MM-DiT approaches.
Pyramid Reflection for Video Understanding
The understanding branch leverages Pyramid Reflection, a sequential decision-making process mimicking test-time reinforcement learning. It iteratively refines evidence selection using verbal feedback to optimize frame selection. This method balances exploration and exploitation strategies, refining answers dynamically based on confidence signals.
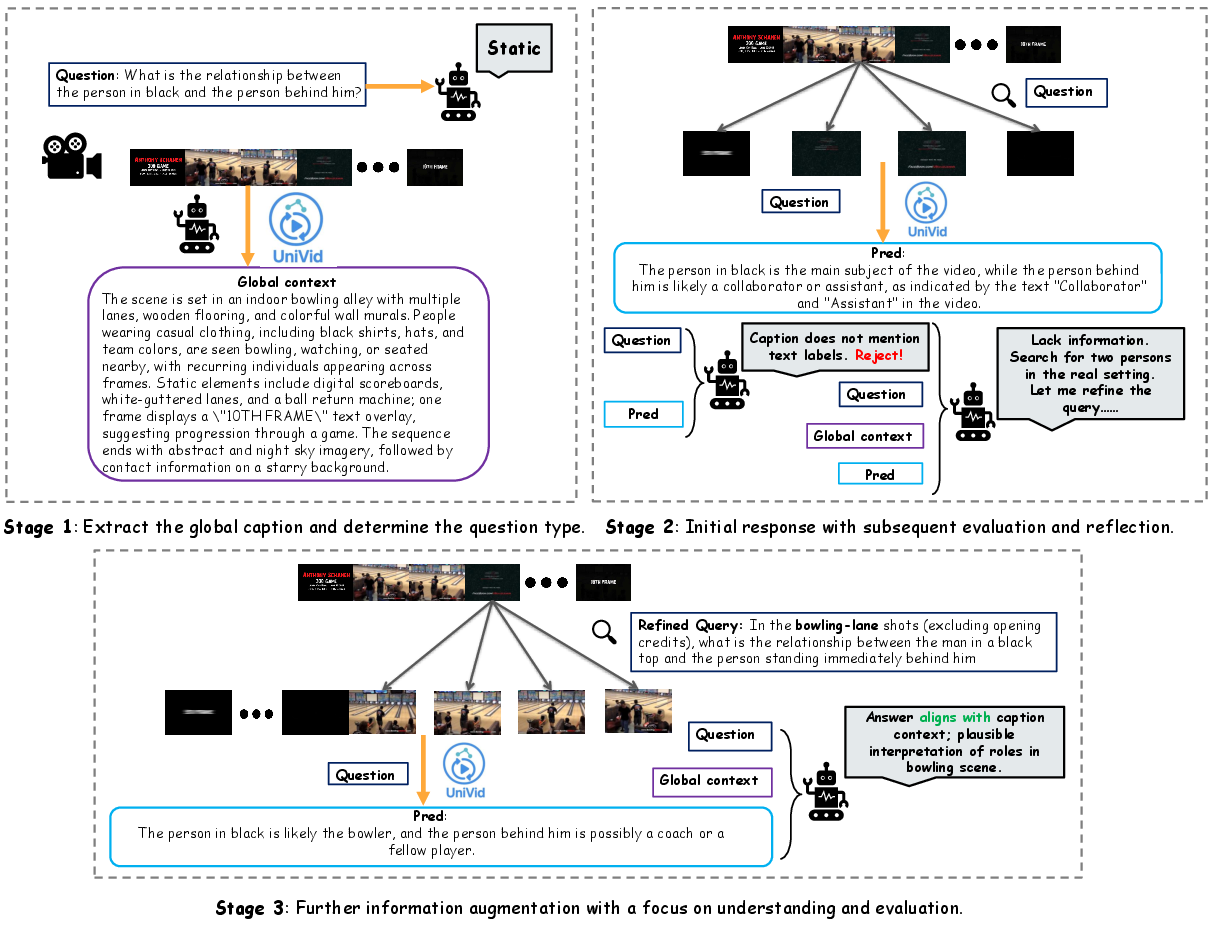
Figure 2: The pipeline of the video understanding.
Evaluation and Results
UniVid shows significant improvements over existing methods in several benchmark evaluations, achieving state-of-the-art scores on VBench-Long for video generation tasks and multiple video QA datasets. It demonstrates excellence in technical and aesthetic quality metrics, with a notable 2.2% improvement over EasyAnimateV5.1 in VBench-Long total score.

Figure 3: Comparisons with State-of-the-Art Video Generation Models.
Video Understanding
For video understanding tasks, UniVid surpasses baseline methods, particularly in action-binding and temporal reasoning. The implementation of Pyramid Reflection enhances the model's ability to effectively retrieve and reason over long video sequences, proving its robustness and efficiency.

Figure 4: The qualitative results of the video understanding.
Implementation Considerations
Training Strategy
UniVid employs a hierarchical training strategy that stepwise integrates generation and understanding capabilities. It uses a combination of fine-tuning and joint task training to efficiently leverage available resources, reducing computational overhead while maintaining high performance.
Computational Requirements
The integration of MLLM and diffusion models increases computational demands. Deployment requires careful balancing of resource allocation to optimize performance without straining hardware capacities, considering the flow-matching ODE sampler's optimal settings.
Conclusion
UniVid represents a significant advancement in unified video modeling, overcoming challenges in semantic faithfulness and temporal reasoning. By integrating Temperature Modality Alignment and Pyramid Reflection, UniVid achieves exceptional results in both video generation and understanding tasks. Future work could focus on optimizing computational efficiency and expanding the ability to process longer, more complex video sequences.
By releasing UniVid as an open-source project, the authors invite further exploration into unified video intelligence, paving the way for practical applications and advancements in multimodal AI research.