Artificial Phantasia: Evidence for Propositional Reasoning-Based Mental Imagery in Large Language Models
Abstract: This study offers a novel approach for benchmarking complex cognitive behavior in artificial systems. Almost universally, LLMs perform best on tasks which may be included in their training data and can be accomplished solely using natural language, limiting our understanding of their emergent sophisticated cognitive capacities. In this work, we created dozens of novel items of a classic mental imagery task from cognitive psychology. A task which, traditionally, cognitive psychologists have argued is solvable exclusively via visual mental imagery (i.e., language alone would be insufficient). LLMs are perfect for testing this hypothesis. First, we tested several state-of-the-art LLMs by giving text-only models written instructions and asking them to report the resulting object after performing the transformations in the aforementioned task. Then, we created a baseline by testing 100 human subjects in exactly the same task. We found that the best LLMs performed significantly above average human performance. Finally, we tested reasoning models set to different levels of reasoning and found the strongest performance when models allocate greater amounts of reasoning tokens. These results provide evidence that the best LLMs may have the capability to complete imagery-dependent tasks despite the non-pictorial nature of their architectures. Our study not only demonstrates an emergent cognitive capacity in LLMs while performing a novel task, but it also provides the field with a new task that leaves lots of room for improvement in otherwise already highly capable models. Finally, our findings reignite the debate over the formats of representation of visual imagery in humans, suggesting that propositional reasoning (or at least non-imagistic reasoning) may be sufficient to complete tasks that were long-thought to be imagery-dependent.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Artificial Phantasia: Evidence for Propositional Reasoning-Based Mental Imagery in LLMs”
What is this paper about?
This paper asks a big question: can computer programs that understand and generate text (called LLMs, or LLMs) solve puzzles that people thought required “pictures in your head”? The authors test whether top LLMs can follow short step-by-step instructions to mentally build a picture from letters and shapes—like imagining a rotated “B” stuck to a flipped “C” to make something that looks like “glasses”—and then name the final object. Surprisingly, the best LLMs did better than the average human.
What were the main questions?
The researchers focused on three simple questions:
- Can LLMs solve classic “mental imagery” puzzles using only text, even though they don’t have a visual brain or actual pictures in memory?
- Do these models do better when they are allowed to “think longer” (use more reasoning steps)?
- Does making the models generate images during the process help or hurt?
How did they test it?
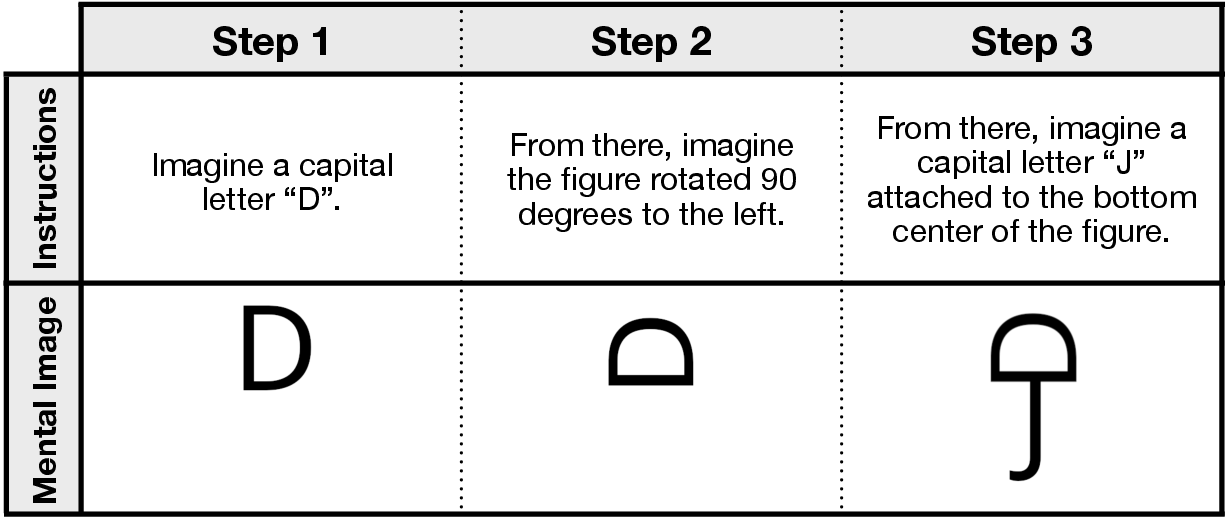
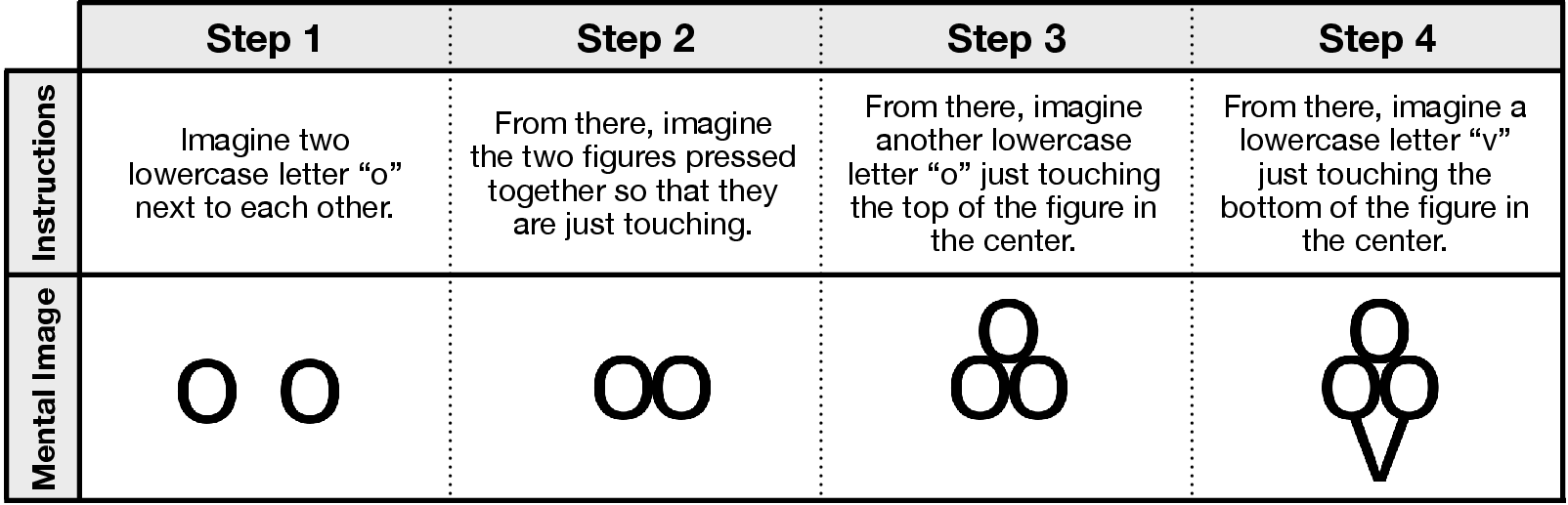
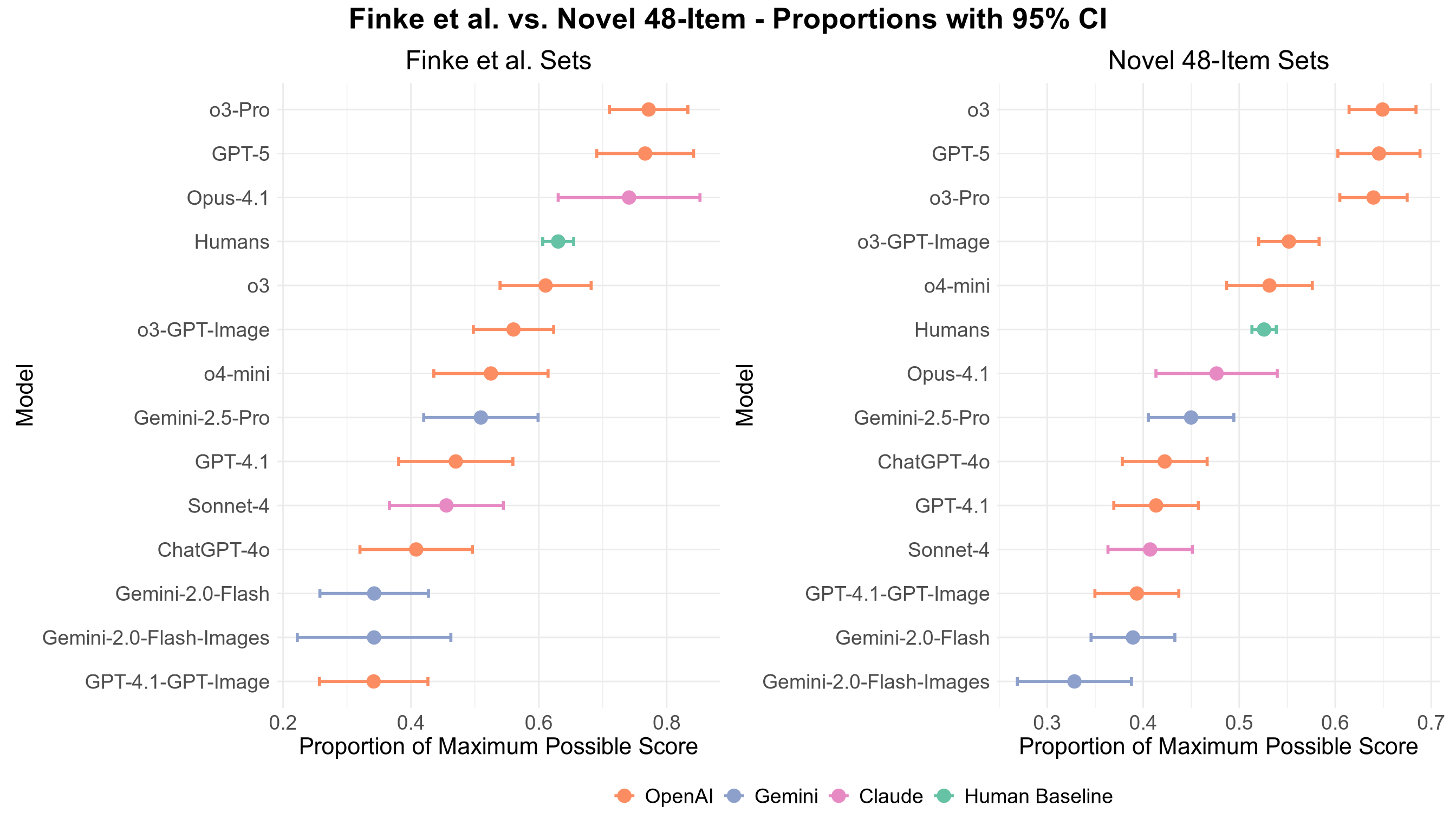
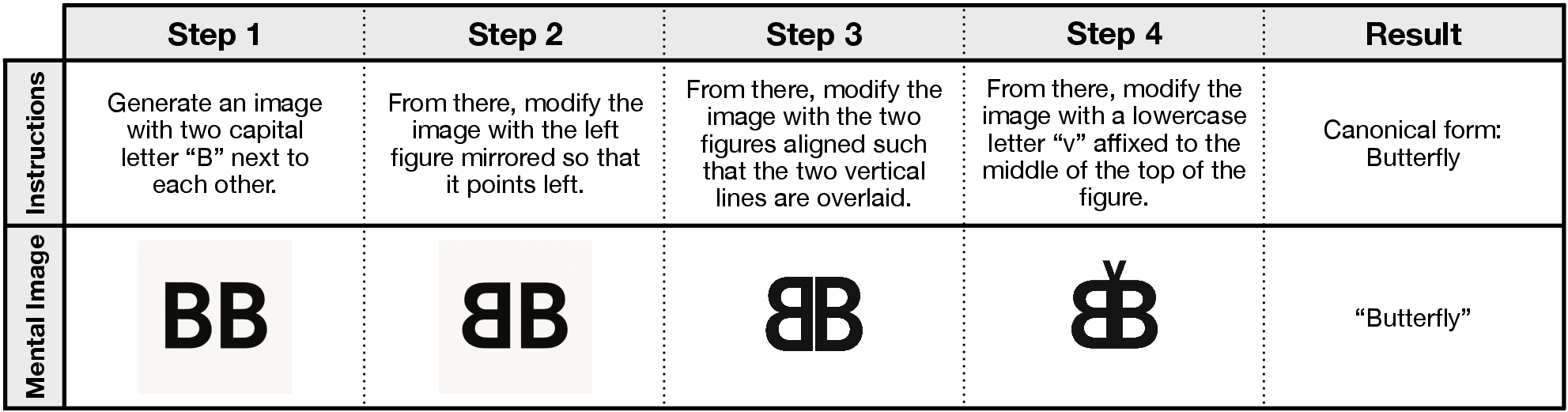
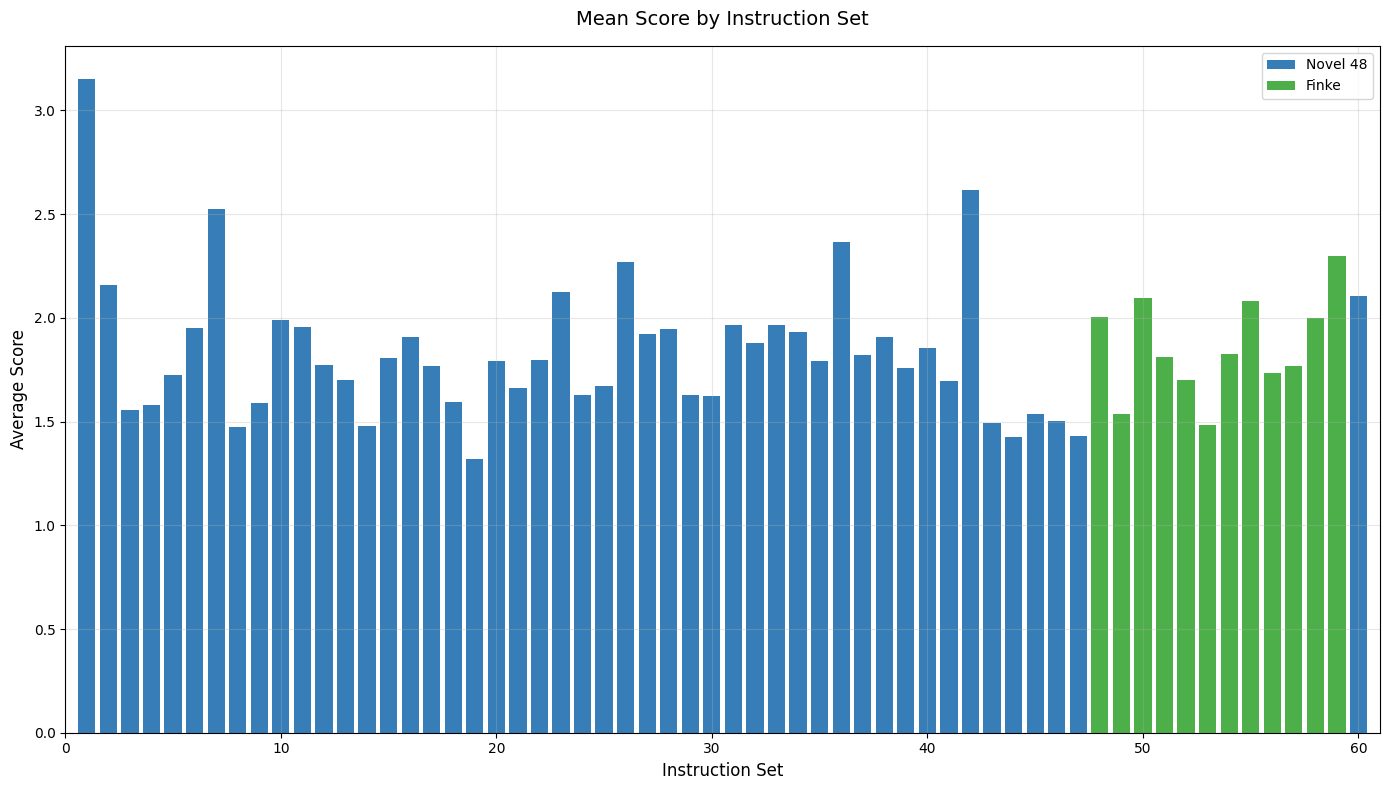
The team created a new set of 60 mental imagery puzzles—48 were brand new and 12 were updated versions of classic puzzles used by psychologists. Each puzzle gave 3–5 short steps like:
- “Imagine a capital E.”
- “Rotate it 90 degrees.”
- “Add a circle to the right.”
- “What object does it look like now?”
They ran the same puzzles in three ways:
- With several top LLMs using text-only instructions.
- With some LLMs that also generated step-by-step images (to see if visuals helped).
- With 100 human participants as a baseline.
To grade answers fairly (because some puzzles can have more than one good label, like “balloons” or “ice cream”), they showed a reference image for each puzzle and asked hundreds of independent people online (plus the authors) to rate how well each answer matched the image. They turned these ratings into a score.
Think of it like a Lego-in-your-head challenge: you hear instructions, imagine combining parts, and then say what the final build looks like—all without actually drawing it.
What did they find?
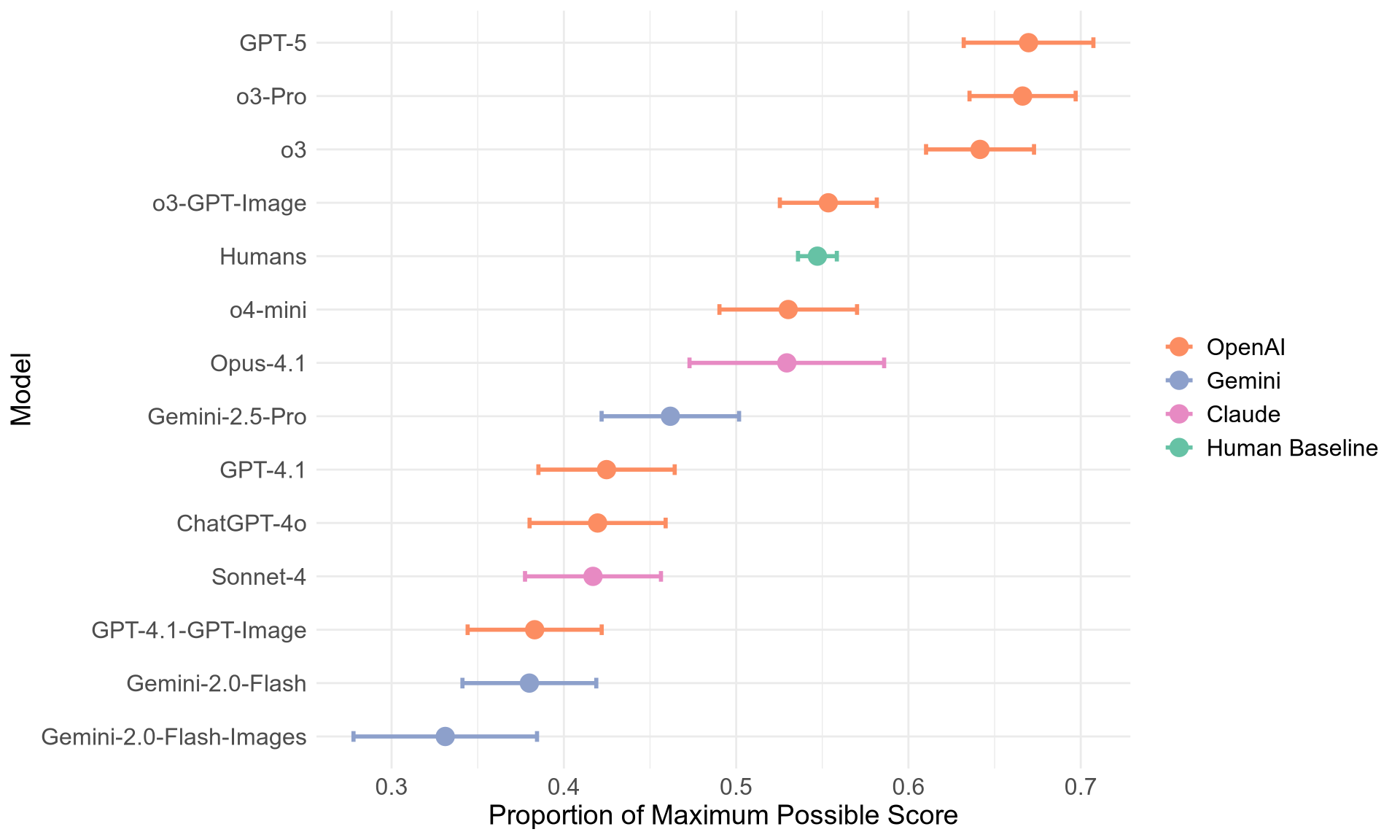
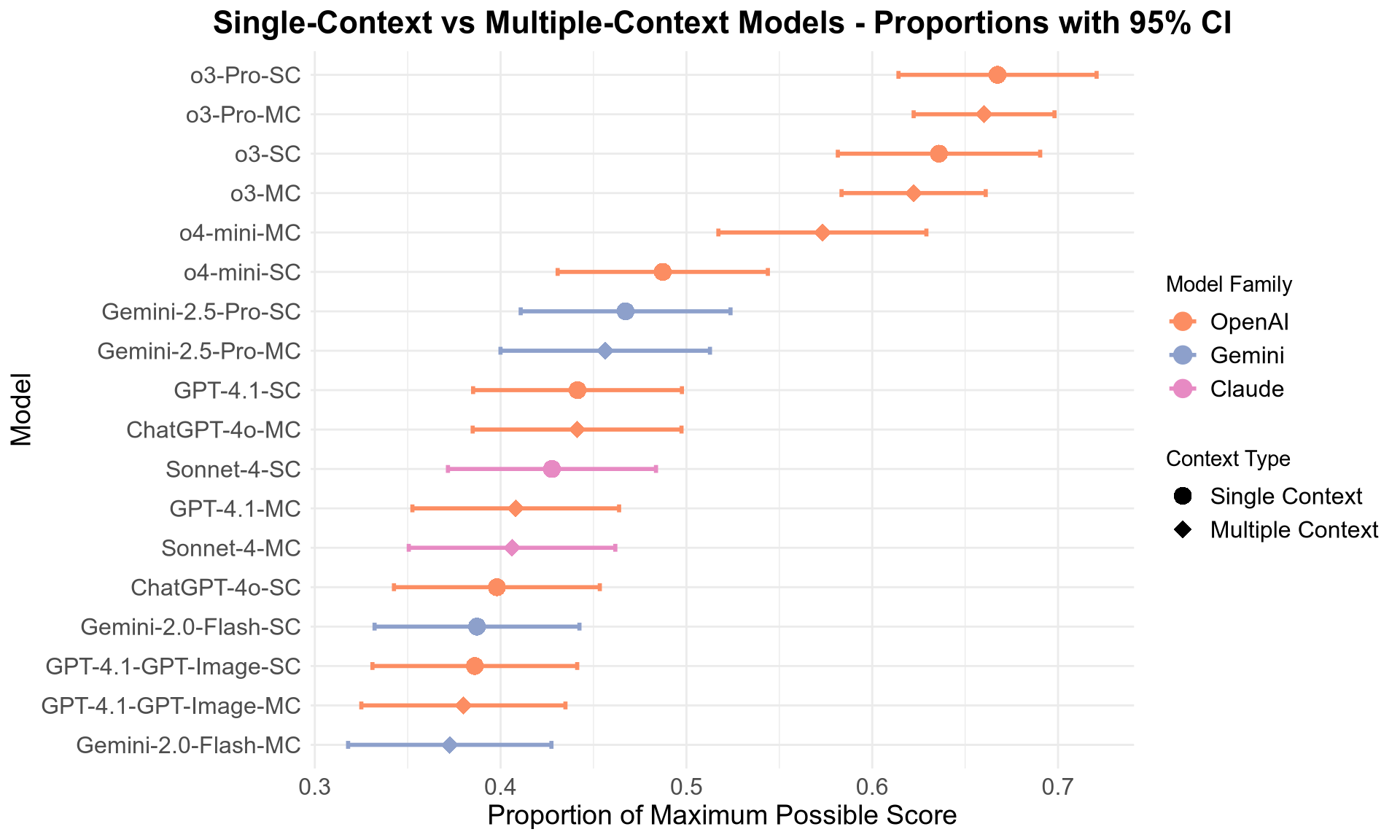
- The best LLMs beat the human average by a clear margin. Humans scored about 54.7%. The top models (OpenAI’s o3 family and GPT-5) scored around 64–67%—about 10–12 points higher.
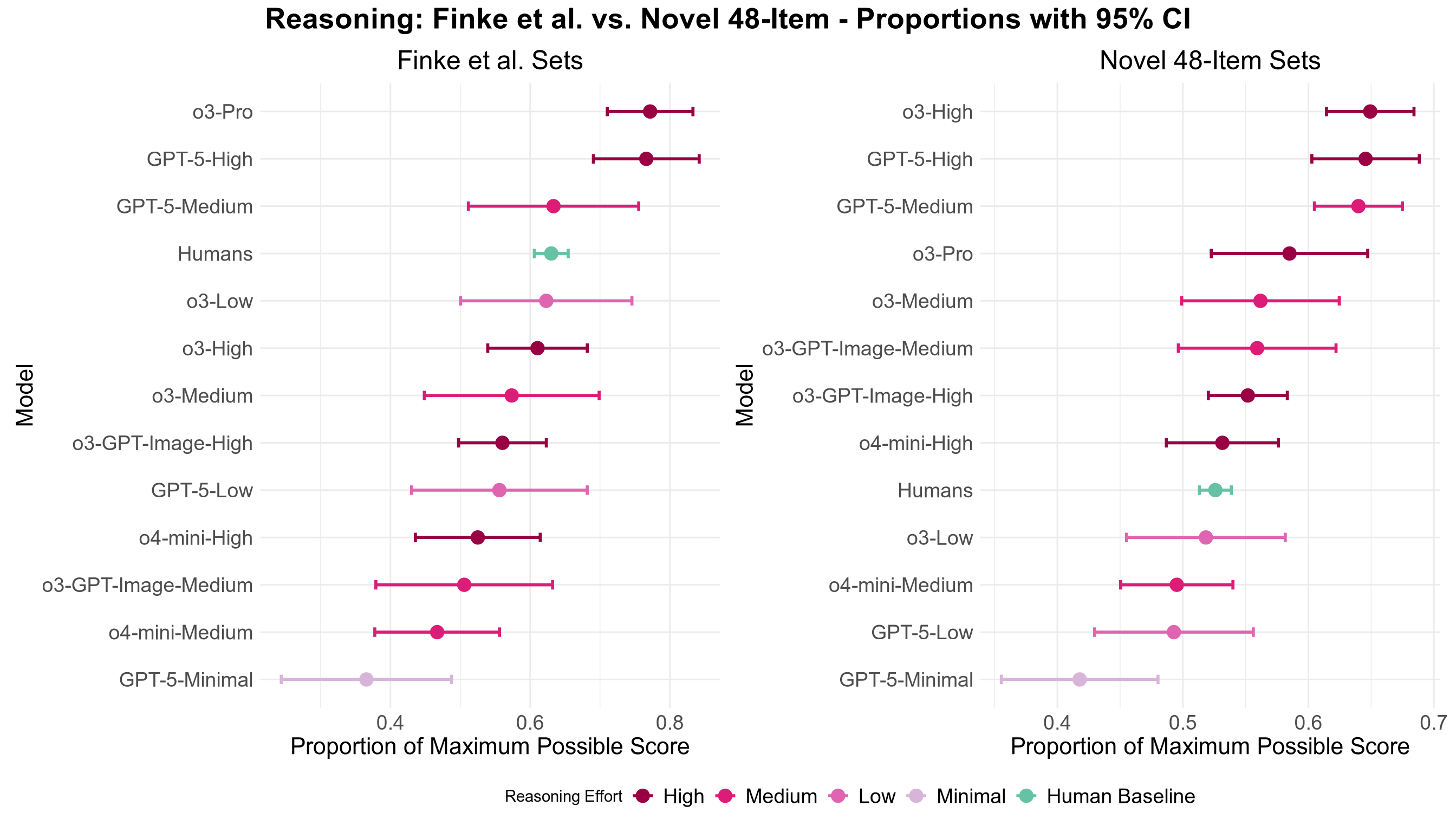
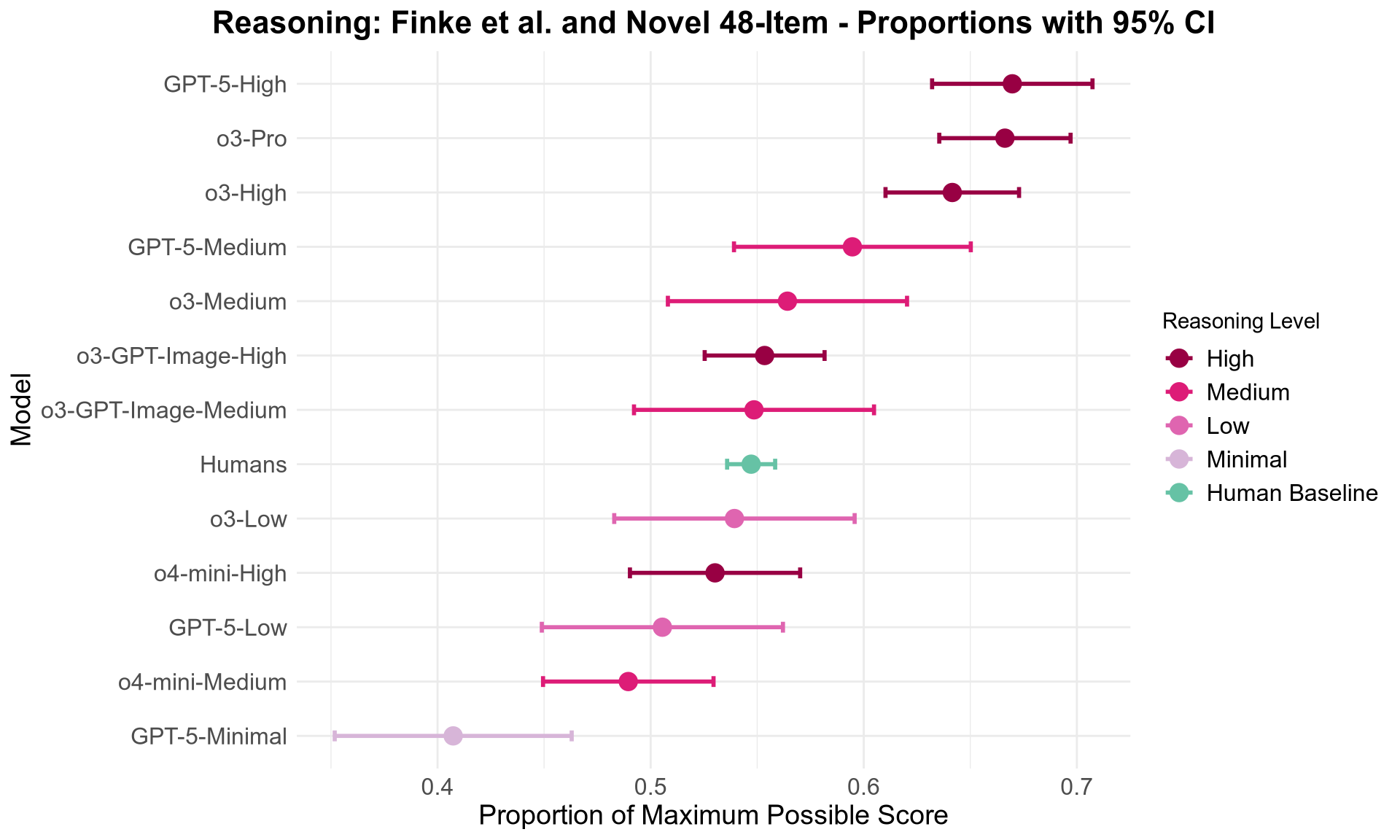
- Giving models extra “thinking time” (more reasoning steps/tokens) helped them do better.
- Asking models to generate images during the process did not help. In fact, it usually made performance worse, even for strong models.
- Using previous examples in the same chat (in-context learning) didn’t make much difference.
- Not all models were equal. Only the strongest ones matched or beat humans. Several popular or cheaper models performed noticeably worse.
Why is this important?
For years, many psychologists have argued that some tasks—like building and recognizing shapes in your mind—require picture-like mental images. But these LLMs don’t have eyes, a visual brain, or “mind’s-eye” pictures. Yet they still solved the puzzles well, sometimes better than people. That suggests another way to solve “imagery” problems: using language-like, step-by-step reasoning (called propositional reasoning), rather than actual inner pictures.
This matters for two fields:
- Artificial intelligence: It shows that language-based models can handle complex spatial and visualization-like tasks by reasoning in words, not pixels.
- Cognitive science (the science of how we think): It challenges the idea that picture-like mental images are always necessary. It also fits with research on aphantasia (people who report little or no mental imagery) who still do well on many imagery tasks—maybe by using verbal strategies or focusing on spatial relations.
What could this change?
- How we test AI: The paper offers a new kind of benchmark that can’t just be memorized from the internet and that pushes reasoning, memory, and spatial understanding together.
- How we think about the mind: It supports the idea that there may be multiple ways to “imagine”—for example, separating object imagery (what things look like) from spatial imagery (where things are and how they fit together). LLMs may be especially good at the spatial/logical side, even without actual inner pictures.
- How we design future models: Letting models “think longer” helps. Forcing them to produce images mid-reasoning didn’t help here, so future work should explore when visuals help and when they distract.
A quick note on limits
The strongest models are expensive to run, so the team couldn’t repeat every test many times. Also, these top models are closed-source, so we don’t know exactly how they work inside. Still, the puzzles were mostly brand new, which makes it unlikely that the models had seen them before.
The takeaway
LLMs can solve “mental imagery” tasks using words and logical steps alone—and sometimes outperform humans. That suggests that language-like reasoning can substitute for picture-like imagery, at least for some tasks, opening new doors for both AI research and our understanding of the human mind.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the study.
- Unidentified internal mechanisms: The paper cannot explain what representations or computations enable LLMs to solve imagery tasks (e.g., spatial embeddings, latent “visual” codes, linguistic heuristics). Test with open‑weight models, interpretability probes (activation steering, causal tracing), and ablations (disabling spatial tokens, disrupting geometric terms) to isolate causal mechanisms.
- Data contamination not audited: While items were created ex novo, no formal contamination audit was performed. Run benchmark‑specific contamination checks (nearest‑neighbor search over known training corpora, memorization probes, perplexity shifts, and redaction tests) across each model to quantify contamination risk.
- Human–LLM comparability confound (modality and effort): Humans received audio instructions; LLMs received text. Time/effort budgets and external aids were asymmetric (LLMs can use many reasoning tokens; humans were disallowed drawing). Re‑run with matched modalities (text vs audio for both), matched time budgets, and controlled external aids (e.g., allow humans scratchpads; constrain LLM token budgets) to ensure fair comparisons.
- Stepwise compliance unverified: Models were not required to commit to intermediate states or transformations. Introduce step‑by‑step outputs with automatic consistency checks (symbolic scene graphs, programmatic validators) to determine whether models truly follow transformations versus guessing the final label.
- Scoring validity and reliability unclear: The “reasonableness” grading using exemplar images is subjective; expert weights and inter‑rater reliability (e.g., ICC/Kendall’s W) are not reported; canonical forms are ambiguous. Predefine multi‑canonical ground truth sets, report rater reliability, publish weighting schema, and test alternative scoring (exact‑match, structured equivalence, IRT).
- Heuristic cue confounds: Some letter combinations may prime common objects without genuine spatial reasoning. Design adversarial stimuli that minimize lexical/semantic associations (abstract shapes, non‑roman glyphs, randomized transforms) and control for priming effects.
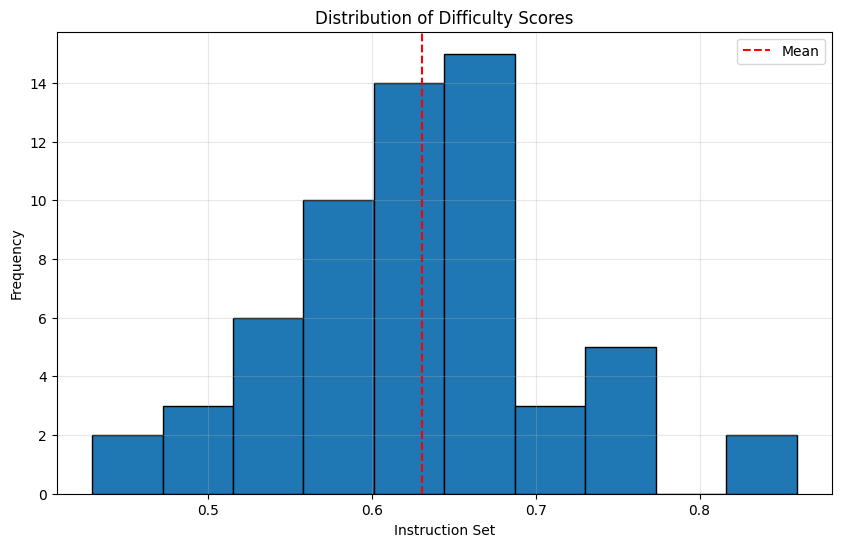
- Complexity scaling untested: Only 2–4 step tasks were used; scaling limits are unknown. Systematically vary task length (5–10 steps), compositionality, and transformation types (rotation vs mirror vs translation vs scaling) to identify breakpoints and error profiles.
- Image‑aided pipeline not controlled: Performance drops with image generation are uninterpretable without verifying image fidelity/edit success. Use controlled visual scratchpads (ASCII/SVG/scene graphs), deterministic editing APIs, and fidelity checks to ensure images reflect instructed transforms.
- In‑context learning (ICL) scope limited: ICL was only assessed for select models and binary regimes (single vs multiple context). Explore few‑shot counts, curated exemplars, and curriculum ordering to quantify ICL benefits, transfer, and stability across providers.
- Reasoning hyperparameter ablations incomplete: Effects of reasoning tokens were measured primarily for OpenAI models; temperature and prompting styles (CoT vs no‑CoT) across all providers remain untested. Perform broad ablations (token budgets, temperature sweeps, scratchpad styles, self‑consistency) to map performance sensitivity.
- Statistical analysis choices not fully justified: Use of χ² on “proportion of maximum score” may be inappropriate; variance structure and CI computation are unclear; no preregistration. Report per‑item distributions, mixed‑effects/IRT models, power analyses, and preregistered analysis plans.
- Individual differences underexplored: VVIQ shows a small negative correlation without deeper analysis; aphantasia was not directly sampled. Recruit targeted cohorts (aphantasia, high/low VVIQ), collect strategy self‑reports, and measure response times to link performance to imagery profiles and strategies.
- Task generalization open: Only object reconstruction was tested. Evaluate other classic imagery tasks (mental rotation, image scanning latencies, image inspection for detail/location) to assess whether LLM gains generalize or are task‑specific.
- Cross‑linguistic and script robustness untested: Instructions were English‑only and letter shapes are script‑dependent. Test across languages/scripts (Latin, Cyrillic, Devanagari, Arabic), and different typographies to assess language/script effects on performance.
- Training data claims not evidenced: The assertion that all 48 items are absent from training data is plausible but unproven. Provide provenance metadata, public release timing vs model training cutoffs, and automated corpus scans to substantiate novelty.
- Resource fairness and speed–accuracy trade‑offs: LLMs leveraged large reasoning token budgets; human effort/time constraints were not matched. Quantify speed–accuracy curves for both humans and LLMs under equalized resource constraints.
- Abstention handling may bias results: Excluding “I don’t know” or nonsensical outputs can differentially affect models and humans. Analyze performance with and without abstentions, and calibrate/penalize abstention behavior uniformly.
- Failure mode taxonomy absent: No analysis of error types (misapplied transform, spatial relation mistake, label selection error). Build a failure taxonomy and annotate per‑item/model errors to guide targeted improvements.
- Replicability across versions/providers: Frontier models evolve rapidly; few runs were conducted due to cost. Establish automated benchmarking harnesses, version pinning, and repeated trials to assess stability and drift across model updates.
- Spatial vs object imagery dissociation untested: The proposed explanation (preserved spatial but not object imagery) is not empirically distinguished. Create stimuli that orthogonally manipulate spatial relations and object surface features; test differential sensitivities in humans and LLMs.
- Tool use audit lacking: It is not verified that models avoided hidden tools or latent “visual” modules. Enforce tool‑free runs, audit logs, and sandboxed inference to confirm purely linguistic processing.
- Exemplar‑image bias in grading: Using single images to grade “reasonableness” may bias toward one canonical form. Provide multiple canonical exemplars per item or use structured equivalence checks to avoid anchoring effects.
- Font/typography variability not considered: Human mental images of letters vary by font; LLMs likely assume canonical glyphs. Test robustness across typographic variants and explicit font cues.
- Instruction rewrites as a confound: Modifications to Finke items (flip vs rotation; abstract referencing) may change cognitive demands. Compare original vs rewritten phrasing to quantify their impact on performance.
- Context window and working memory limits: The role of context length and working memory (for longer sequences) was not analyzed. Vary context/window sizes and introduce distractors to test memory constraints and interference.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with current tools and models, derived from the paper’s findings and methods.
- Propositional Imagery Benchmark Suite for LLMs
- Sector: Software/AI; Model evaluation, safety, and procurement
- What: Package the 60-item mental imagery task (and its grading protocol) as a contamination-resistant benchmark to evaluate “reasoning-token” models on compositional, spatial, and instruction-following capabilities.
- Tools/workflows: CI-style model regression tests; capability cards including “Propositional Imagery Score”; vendor evaluations for model selection; leaderboard contributions.
- Assumptions/dependencies: Access to frontier reasoning models; rights to use the released items; crowd+expert grading pipeline. In-context examples not required (no significant benefit), simplifying setup.
- Reasoning Token Budgeting in Production
- Sector: Software/AI platforms
- What: Operationalize the paper’s finding that higher reasoning effort improves performance by routing specific tasks to higher “reasoning tokens” configurations.
- Tools/workflows: Dynamic “reasoning effort” schedulers; policy rules to escalate token budgets only for spatial/compositional prompts; cost-performance dashboards.
- Assumptions/dependencies: Vendor support for reasoning controls; acceptable latency and cost budgets.
- Voice-Only Spatial Reasoning Tutors and Assessments
- Sector: Education/EdTech
- What: Create audio-driven spatial reasoning exercises (like the paper’s audio-based items) for mental rotation, geometry, and compositional thinking; adaptive difficulty calibrated to the provided human baseline.
- Tools/workflows: LMS plugins with item banks; automatic scoring via the weighted crowd+expert rubric; accessibility-friendly audio delivery (reduces textual bias).
- Assumptions/dependencies: Validation for specific learner populations; content moderation for ambiguous/subjective answers; equitable use across languages/accents.
- Aphantasia-Friendly Cognitive Screening and Training
- Sector: Healthcare/Neuropsychology; Digital health
- What: Use the language-only task as a screening and training instrument for spatial reasoning independent of pictorial imagery, supporting aphantasia research and patient monitoring.
- Tools/workflows: Web-based tests (audio-first) with automated scoring; clinician dashboards to track progress; research studies on spatial vs object imagery profiles.
- Assumptions/dependencies: Clinical validation and IRB approvals for diagnostic use; careful interpretation (not a diagnostic by itself).
- Open-Ended Output Grading Pipeline (Crowd+Expert Weighted)
- Sector: Research infrastructure; Evaluation
- What: Generalize the paper’s scalable human-in-the-loop scoring system (weighted naïve crowd raters plus expert graders) for any task with multiple “reasonable” outputs.
- Tools/workflows: Annotation platforms (e.g., Prolific/MTurk) with reliability weighting; reusable rubrics and code; audit trails for evaluation reproducibility.
- Assumptions/dependencies: Stable access to crowd platforms; inter-rater reliability monitoring; task-specific rubric design.
- Verbal-to-Procedure Translators for Spatial Tasks
- Sector: Robotics, Manufacturing, Field Operations, Customer Support
- What: Convert stepwise verbal instructions into structured transformation plans (graphs) for assembly, packing, or orientation tasks; produce checklists and QA questions without requiring images.
- Tools/workflows: Instruction parsers and plan validators; job aid generators (PDF/voice); call-center assistants that transform customer descriptions into procedural steps.
- Assumptions/dependencies: Domain grounding (e.g., parts catalogs); human-in-the-loop for safety-critical steps; clear instruction syntax.
- Model Selection Guidance for Spatial and Compositional Use Cases
- Sector: Software/AI product teams
- What: Prefer frontier reasoning models (e.g., o3 family, GPT-5–class) for text-only spatial/compositional tasks; avoid image-aided steps where performance is currently degraded.
- Tools/workflows: Decision matrices in engineering playbooks; A/B tests comparing “text-only” vs “image-aided” pipelines; fallback policies to cheaper models when acceptable.
- Assumptions/dependencies: Vendor availability; cost constraints; acceptance of closed-weight models.
- Contamination-Resistant Evaluations for Model Procurement and Audits
- Sector: Policy/Government/Enterprise Compliance
- What: Include benchmark items created ex novo (like this paper’s) in procurement RFPs and capability audits to reduce data contamination concerns.
- Tools/workflows: Evaluation kits with provenance-tracked items; signed attestations on evaluation integrity; audits that document reasoning token policies.
- Assumptions/dependencies: Legal approvals to share evaluation data; reproducibility policies; vendor cooperation.
- Accessibility-Oriented Guided Visualization by Language
- Sector: Accessibility/Assistive Technology; Wellness
- What: Provide language-only guided visualization and mental rehearsal (e.g., orientation strategies, structured imagery scripts) for users with low vision or imagery differences.
- Tools/workflows: Voice assistants with structured spatial prompts; safety rails to avoid overclaiming therapeutic value; user feedback loops.
- Assumptions/dependencies: Non-clinical use unless validated; personalization for user preferences and cognitive profiles.
- Prompt and Curriculum Design for Spatial Reasoning
- Sector: Education/Instructional Design; Prompt Engineering
- What: Adopt the paper’s best practices (clarity, abstraction over letter names, step counts) to craft robust prompts and curricula for compositional reasoning tasks.
- Tools/workflows: Prompt templates; item generators that vary steps and transformations; difficulty calibration against the human baseline.
- Assumptions/dependencies: Care with ambiguous forms; alignment with learning objectives; evaluation via human-in-the-loop graders.
Long-Term Applications
These opportunities require further research, scaling, validation, or integration work before deployment.
- Propositional Spatial Engine for Robots and Agents
- Sector: Robotics/Autonomy
- What: Embed a “verbal-to-spatial-transformations” engine that converts natural language into reliable spatial plans without visual input; later integrate with sensors for cross-modal grounding.
- Tools/products: Spatial plan compiler; constraint checker; hybrid symbolic–LLM architectures.
- Assumptions/dependencies: Robust grounding to real-world physics/geometry; safety certifications; strong error recovery.
- Voice-Driven CAD and Sketching Assistants
- Sector: Design/Engineering
- What: From stepwise verbal descriptions, generate parametric sketches or constraints for CAD; eventually integrate with multimodal latent visual tokens for intermediate previews.
- Tools/products: “Propositional sketch” DSL; plugin for CAD suites; iterative “explain/adjust” loops.
- Assumptions/dependencies: Current image-aided reasoning underperforms; needs improved multimodal reasoning and verification; domain-specific constraints.
- Standardized Contamination-Resistant Benchmarking Consortium
- Sector: AI governance; Standards
- What: Establish a public consortium to maintain living, newly synthesized benchmarks (like the paper’s) for spatial/compositional reasoning, with provenance tracking and auditability.
- Tools/products: Item synthesis frameworks; secure item escrow; standardized reporting schemas.
- Assumptions/dependencies: Multi-stakeholder buy-in; funding for item generation and curation; legal/IP frameworks.
- Clinical Neuropsych Batteries Distinguishing Spatial vs Object Imagery
- Sector: Healthcare/Clinical Psychology
- What: Build validated, language-first instruments that tease apart spatial and object imagery capacities; support diagnosis, rehabilitation planning, and tracking (e.g., post-lesion).
- Tools/products: Digitally delivered assessments; normative datasets; longitudinal analytics.
- Assumptions/dependencies: Multi-site clinical trials; regulatory approvals; demographic representativeness.
- Educational Digital Therapeutics for Imagery Training
- Sector: Digital health/EdTech
- What: Personalized training programs that strengthen spatial reasoning through verbal exercises; optionally combined with biofeedback or AR overlays for transfer.
- Tools/products: Adaptive training app; teacher/clinician dashboards; progression models.
- Assumptions/dependencies: Evidence for transfer to real-world tasks; careful claims; data privacy safeguards.
- Multimodal Reasoning Architectures that Don’t Regress with Images
- Sector: AI R&D
- What: Architectures that combine propositional spatial reasoning with visual tokens or scene graphs without the performance drop observed in current image-aided pipelines.
- Tools/products: Latent-visual-token modules; structured intermediate representations; self-validation via consistency checks.
- Assumptions/dependencies: Better integration of visual and textual embeddings; training curricula for compositional visual reasoning.
- Synthetic Item Generators for Forever-Fresh Benchmarks
- Sector: AI evaluation/Research tooling
- What: Algorithms to produce infinitely many novel, compositional tasks with guaranteed novelty and difficulty controls, preventing benchmark saturation and data leakage.
- Tools/products: Programmatic item generator; difficulty estimators; novelty detectors.
- Assumptions/dependencies: Formal guarantees of uniqueness; continuous item validation against new models.
- Hiring and Training Assessments for Spatial-Heavy Roles (with safeguards)
- Sector: HR/Workforce Development
- What: Fair, validated assessments targeting compositional and spatial reasoning (verbal-only), e.g., for logistics, manufacturing, or design apprenticeships.
- Tools/products: Proctored online tests; explainable scoring; accommodations for imagery differences.
- Assumptions/dependencies: Strong fairness validation; clear job relevance; careful policy to avoid disadvantaging specific cognitive profiles.
- Safety/Capability Gating via Reasoning Profiles
- Sector: AI Safety & Release Management
- What: Use tasks like these to characterize a model’s “reasoning footprint” (e.g., spatial planning competence) to inform staged releases, guardrails, and allowed application domains.
- Tools/products: Capability thresholds; red/amber/green risk profiles; automated release checklists.
- Assumptions/dependencies: Community agreement on thresholds; evidence of external validity; cost-effective repeated testing.
- Cognitive HCI for Navigation and Planning Without Maps
- Sector: Consumer assistants; Automotive
- What: Voice agents that guide users through spatial planning (packing a car, arranging furniture, route simulation) using propositional reasoning rather than visual maps or images.
- Tools/products: Task-specific “spatial coaching” skills; simulation of alternatives; preference-aware suggestions.
- Assumptions/dependencies: Grounding in user context and constraints; robust error handling; user trust and transparency.
Notes on Feasibility and Dependencies (Cross-Cutting)
- Model capability variance: The strongest results are limited to frontier reasoning models; cheaper/older models underperform. Budget and latency constraints will shape deployment choices.
- Image-aided caution: Current evidence shows performance degradation when forcing image generation mid-reasoning. Multimodal integrations should be validated before production.
- Evaluation complexity: Because multiple labels can be “reasonable,” scalable human-in-the-loop grading (crowd+expert weighting) or strong automatic proxies are needed.
- External validity: Success on these tasks may not directly translate to all spatial problems; domain-specific validation is required, especially for safety-critical uses.
- Ethics and fairness: For clinical or HR settings, rigorous validation, bias audits, and accommodations for diverse cognitive profiles (e.g., aphantasia) are essential.
- Reproducibility and provenance: Maintaining contamination-resistant, novel item pools is key for credible evaluation and policy use; requires governance and sustained funding.
Glossary
- Aphantasia: A condition characterized by an absence or marked impairment of voluntary visual mental imagery. "Aphantasia research has recently re-opened questions regarding the nature of mental imagery representations"
- Bonferroni correction: A method for controlling family-wise error rate in multiple hypothesis testing by dividing the significance threshold by the number of comparisons. "Statistical significance in the main results presented in Figure \ref{fig:collapsed_ci} and Table \ref{tab:combined_results} was determined after correcting for multiple comparisons using Bonferroni: alpha = 0.05 / 13 = 0.0038."
- Chi-square statistic: A test statistic used to assess differences between observed and expected frequencies; here used to compare performance proportions. "χ2 = 28.631"
- Closed weight: Refers to models whose parameters and architectures are not publicly released. "the state-of-the-art frontier models are all closed weight and closed architecture"
- Compositionality: The property of tasks or representations where complex outputs are formed by combining simpler parts according to structured rules. "As the object reconstruction task we used is compositional (different images or aspects of images from each step need to be combined in subsequent steps to obtain the final answer)"
- Confidence interval (CI): A range of values that likely contains the true parameter, expressing uncertainty around estimates. "CI = [-0.128, -0.06]"
- Data contamination: The presence of benchmark or test content in a model’s training data, potentially inflating performance. "prone to data contamination risks from preexisting information in their training dataset"
- Deep Neural Networks (DNNs): Multi-layered neural architectures used in machine learning, often exhibiting emergent representational properties. "Deep Neural Networks (DNNs) are useful tools for understanding human cognition in general"
- Embeddings: Numeric vector representations of tokens or inputs that capture semantic or structural information. "they still rely on high-dimensional embeddings that are not visual in nature"
- Frontier LLMs: The most advanced, cutting-edge LLMs. "Frontier LLMs give a new perspective to the debate on the formats of mental imagery"
- Hyperparameter: A configuration value external to model training (not learned) that influences performance or behavior. "modification of the `reasoning_effort' hyperparameter led to almost identical results"
- In-context learning: A model’s ability to adapt behavior based on examples provided in the prompt without updating weights. "This indicates that in-context learning was not significantly beneficial for this task."
- International Radiotelephony Spelling Alphabet: A standardized phonetic alphabet used to clarify spoken letters (e.g., “Bravo” for B). "include the corresponding phonetic word from the International Radiotelephony Spelling Alphabet"
- Language of thought: A theoretical framework positing internal, propositional, language-like mental representations. "propositional descriptions (i.e., discursive elements) in a language of thought"
- Large Reasoning Models: LLMs augmented or configured to allocate additional computation toward structured reasoning. "Advancements in Large Reasoning Models have progressed so quickly"
- Mental rotation: A cognitive process of rotating mental representations of objects in space. "such as remembering a scene and mental rotation"
- Multimodal: Involving or integrating multiple input/output modalities (e.g., text and images). "recent multimodal extensions have been trained not just on linguistic corpora but on images as well"
- Neuroimaging: Techniques that measure brain activity and structure to study cognition. "neuroimaging studies showing similarities in neural activity between visual and imagery tasks"
- Object imagery: The ability to form mental images of objects and their features, distinct from spatial relations. "a preserved spatial imagery despite a diminished or absent object imagery"
- Object reconstruction task: A mental imagery experiment requiring subjects to transform and combine shapes to identify a final object. "One of the foundational studies of pictorial mental imagery is an object reconstruction task"
- Open weight models: Models whose parameters are publicly available for inspection and modification. "outside of initial testing of open weight models"
- Pictorial mental imagery: The view that mental imagery is depictive or picture-like in format. "The pictorial view of mental imagery vastly dominates psychology today"
- Propositional reasoning: Symbolic, language-like reasoning using discrete statements rather than depictive imagery. "propositional reasoning (or at least non-imagistic reasoning)"
- Reasoning tokens: Additional computational budget allocated to step-by-step reasoning within a model’s inference. "found the strongest performance when models allocate greater amounts of reasoning tokens"
- reasoning_effort: A model parameter controlling the extent of internal reasoning during inference. "we measured the effect of the `reasoning_effort' parameter"
- Spatial cognition: Cognitive abilities related to understanding spatial relationships and navigation. "evaluating spatial cognition as an emergent property of frontier models"
- Spatial imagery: Mental imagery focused on spatial relations among elements rather than object features. "spatial imagery questionnaires"
- Temperature (sampling temperature): A generation parameter controlling randomness in probabilistic sampling; lower values yield more deterministic outputs. "For models that allow temperature modification, the value was set to 0.1"
- Transformer architecture: A neural network design using attention mechanisms, foundational for modern LLMs. "beyond just those of the transformer architecture"
- Visual-LLMs: Models jointly trained or designed to process and reason over both visual and textual inputs. "visual-LLMs"
- Vividness of Visual Imagery Questionnaire (VVIQ): A standardized self-report instrument measuring the vividness of mental imagery. "Vividness of Visual Imagery Questionnaire (VVIQ)"
- Weighted average: An average where different components contribute with specified weights. "a weighted average of the expert's grades and the outsourced grades"
Collections
Sign up for free to add this paper to one or more collections.

