- The paper’s main contribution is proving that scale-wise VAR is mathematically equivalent to a deterministic discrete diffusion process.
- It introduces the SRDD framework with innovations like Classifier-Free Guidance, token resampling, and scale distillation to boost image quality and reduce computational cost.
- Empirical results reveal significant improvements in FID and IS scores across benchmarks, alongside superior zero-shot generalization in image editing tasks.
Scale-Wise VAR as Discrete Diffusion: Theoretical Foundations and Empirical Advances
Introduction
This paper establishes a formal equivalence between scale-wise Visual Autoregressive Generation (VAR) and discrete diffusion models, introducing the Scalable Visual Refinement with Discrete Diffusion (SRDD) framework. The authors demonstrate that, when equipped with a Markovian attention mask, VAR is mathematically identical to a structured discrete diffusion process. This reinterpretation enables the direct transfer of theoretical and practical advances from the diffusion literature to autoregressive visual generation, resulting in improved sample fidelity, efficiency, and zero-shot generalization.
Theoretical Connection: VAR and Discrete Diffusion
The central theoretical contribution is the proof that Markovian VAR—where each scale is conditioned only on its immediate predecessor—implements a deterministic discrete diffusion process. The forward process in VAR, which progressively refines images from coarse to fine scales, mirrors the signal-to-noise ratio (SNR) increase characteristic of diffusion models.

Figure 1: Scale-wise generation of VAR: The SNR increases through the generation process, similar to the diffusion process.
The loss function for Markovian VAR is shown to be equivalent to the evidence lower bound (ELBO) of discrete diffusion in the limiting case of deterministic transitions. This equivalence is established by analyzing the KL divergence between the forward posterior and model prediction, which reduces to cross-entropy at the non-deterministic token positions. The Markovian attention mask eliminates architectural inefficiencies present in the original VAR, which conditioned on all previous scales, and provides a principled explanation for observed empirical gains.
Methodological Innovations: SRDD and Diffusion-Inspired Enhancements
Building on the theoretical connection, the authors introduce SRDD, a Markovian variant of VAR that leverages discrete diffusion principles. Four key enhancements are proposed:
- Classifier-Free Guidance (CFG): SRDD incorporates CFG, enabling controlled trade-offs between sample diversity and fidelity. Unlike VAR, which exhibited unstable behavior under strong guidance, SRDD demonstrates monotonic improvements in FID and IS up to a saturation point.
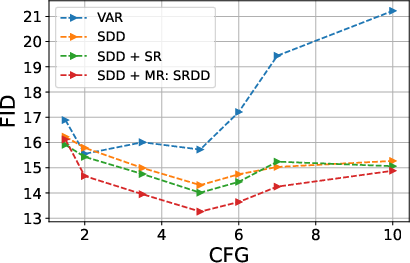
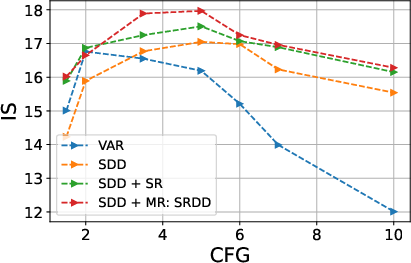
Figure 2: Effect of cfg on SUN397 Dataset: We Present the effect of cfg on FID and IS Score
- Token Resampling (MR): Inspired by masked diffusion models, SRDD refines low-confidence tokens at each scale, leading to sharper images and faster convergence. The ablation study reveals that a resampling threshold of presample=0.01 optimally balances coverage and context preservation.
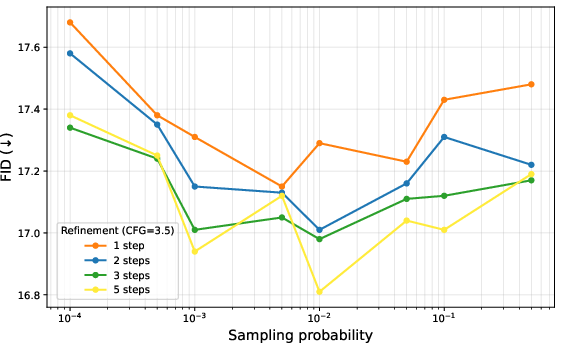
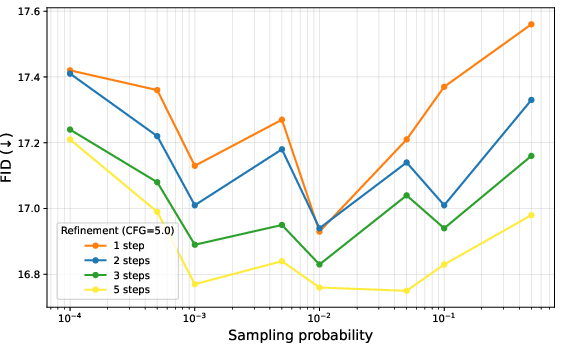
Figure 3: Ablation study illustrating the effect of MR: We experiment with different threshold $p_{\mathrm{resample}$ and the number of refinement steps.
- Simple Resampling (SR): Multiple refinement passes per scale further improve sample quality, analogous to increasing the number of denoising steps in diffusion models.
- Scale Distillation: SRDD supports progressive distillation, allowing the removal of intermediate scales without significant loss in perceptual quality. This reduces inference cost and memory usage, achieving up to 1.75× speedup and 3× memory reduction.
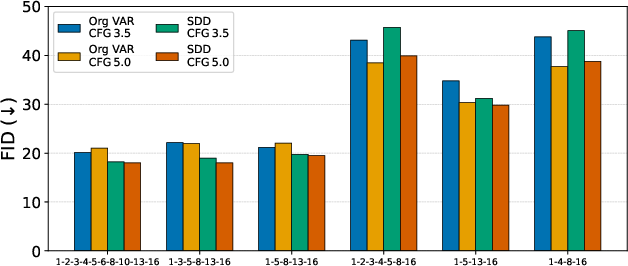
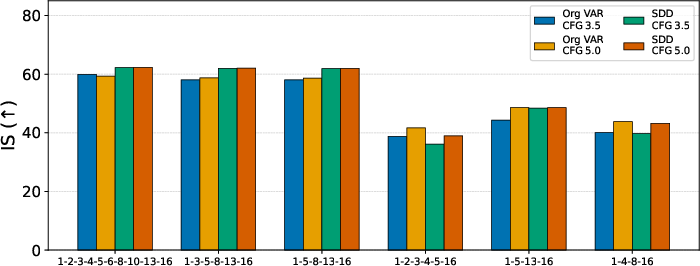
Figure 4: Effect of distillation on reducing the number of scales
Empirical Results: Benchmarking and Qualitative Analysis
SRDD is evaluated on MiniImageNet, SUN397, FFHQ, and AFHQ datasets, outperforming LDM, DiT-L/2, and the original VAR across all metrics. Notably, SRDD achieves a 20.2% FID reduction on MiniImageNet and 31.1% IS improvement on FFHQ relative to VAR. The Markovian attention mask and diffusion-inspired enhancements yield consistent gains in both conditional and unconditional generation.
Qualitative comparisons highlight SRDD's ability to produce images with sharper edges, cleaner textures, and fewer artifacts compared to competing models.

Figure 5: Qualitative Comparison of DiT-L/2, VAR and Ours: SRDD; We do not compare with LDM because LDM model didn't converge.

Figure 6: Qualitative Comparison on AFHQ Datasets, LDM, DiT-L/2, VAR and SRDD: DiT-L/2 didn't converge on AFHQ Datasets.

Figure 7: Qualitative Comparison of FFHQ Datasets LDM, DiT-L/2, VAR and SRDD.

Figure 8: Qualitative Comparison on SUN397 Datasets, LDM, DiT-L/2, VAR and SRDD.
Non-curated generations further demonstrate SRDD's robustness and diversity.

Figure 9: Non-curated example images generated by the proposed SRDD approach for the MiniImagenet Dataset.

Figure 10: Non-curated example images generated by the proposed SRDD approach for the AFHQ Dataset.

Figure 11: Non-curated example images generated by the proposed SRDD approach for the FFHQ Dataset.
Zero-Shot Generalization and Editing
SRDD exhibits superior zero-shot performance in inpainting, outpainting, and super-resolution tasks, outperforming VAR in LPIPS, FID, PSNR, and SSIM metrics. The Markovian decoder requires no additional training for these tasks, underscoring its generality and robustness.
Implementation Details and Scaling Considerations
SRDD is implemented as a decoder-only Transformer with a Markovian attention mask, sharing a single VQ codebook across all scales. Training is performed with AdamW, a batch size of 224, and gradient clipping, on 4 NVIDIA A6000 GPUs for 200 epochs. The Markovian mask reduces memory cost and enables efficient scaling with model size, maintaining strong scaling behavior as parameters increase.
Limitations and Future Directions
The authors acknowledge limitations in compute budget, dataset scope, and codebook expressiveness. Future work may explore larger-scale pretraining, learned resampling policies, hybrid continuous-discrete diffusion pipelines, and the integration of advances in discrete diffusion theory. The SRDD framework provides a pathway for inheriting future breakthroughs in discrete diffusion modeling.
Conclusion
This work rigorously connects scale-wise VAR to discrete diffusion, providing both theoretical clarity and practical efficiency. The Markovian formulation eliminates architectural inefficiencies, enables principled adoption of diffusion techniques, and achieves state-of-the-art performance across multiple benchmarks. SRDD opens new directions for scalable, unified visual generation and offers a robust foundation for future research in autoregressive and diffusion-based generative modeling.

