- The paper introduces the A.S.E benchmark as the first repository-level framework for assessing the security of AI-generated code by leveraging real-world repositories and reproducible pipelines.
- It evaluates code generation across three dimensions—security, build quality, and stability—revealing that fast-thinking decoding yields better security outcomes than multi-step reasoning.
- Experimental results highlight a narrow performance gap between open- and closed-source models and persistent challenges in patching complex vulnerabilities like path traversal.
A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Motivation and Limitations of Existing Benchmarks
The proliferation of LLMs in software engineering has elevated the need for rigorous, reproducible, and context-aware security evaluation of AI-generated code. Existing benchmarks predominantly focus on function- or snippet-level tasks, often neglecting repository-level dependencies, build constraints, and the interplay between context and security. Evaluation pipelines relying on LLM-based judgment or generic SAST tools suffer from instability, high false positive/negative rates, and lack of reproducibility. Furthermore, most studies fail to systematically link the quality of input context to the security of generated outputs, leaving a gap in understanding the causal relationship between information supply and secure code generation.
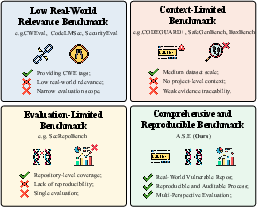
Figure 1: Comparison of code security assessment approaches.
A.S.E Benchmark: Design and Construction
A.S.E (AI Code Generation Security Evaluation) addresses these deficiencies by introducing a repository-level benchmark that emphasizes real-world engineering constraints, reproducibility, and multi-dimensional evaluation. The benchmark construction is governed by three principles:
- Real-World, Repository-Level Data: Tasks are derived from active open-source repositories with documented CVEs, preserving build systems, cross-file dependencies, and configuration files. Security-sensitive regions are precisely delimited, and light semantic/structural mutations (e.g., identifier renaming, control-flow reshaping) are applied to mitigate data leakage and enforce reasoning over memorization.
- Objective, Traceable, and Reproducible Evaluation: All evaluation steps are containerized, enabling deterministic replay. Security judgments are based on expert-calibrated, CWE-specific rules using industry-grade analyzers (CodeQL, Joern), and all artifacts (rule hits, locations, data/control-flow slices) are auditable.
- Multi-Perspective Evaluation: The benchmark adapts context windows per model (up to 128k tokens), employs retrieval models (BM25) to surface relevant files, and evaluates generated code along three axes: security (vulnerability elimination), build quality (integration and compilation), and stability (consistency across runs).
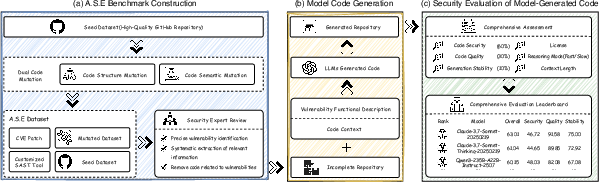
Figure 2: Overall workflow of A.S.E, from benchmark construction and code generation to security evaluation.
The construction pipeline involves algorithmic preselection of repositories based on CVE linkage, vulnerability type (XSS, SQLi, path traversal, command injection), and language (PHP, Python, Go, JavaScript, Java), followed by expert curation, reproducibility checks, and dual-toolchain SAST validation. Forty seed repositories are expanded to eighty variants via semantic and structural mutation, yielding 120 realistic, reproducible vulnerability scenarios.
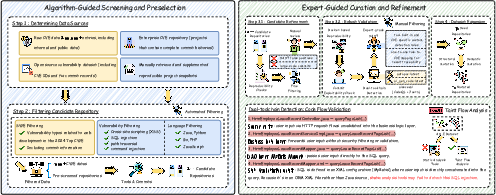
Figure 3: Overview of A.S.E benchmark construction, from CVE-linked source aggregation to expert-guided curation and mutation.
Dataset Characteristics
A.S.E targets four high-frequency vulnerability classes (CWE-79, CWE-89, CWE-22, CWE-78) and five mainstream programming languages, with a distribution reflecting real-world prevalence (PHP dominates at 50%). Each instance is validated for reproducibility and covers both original and mutated variants to assess model robustness and generalization.
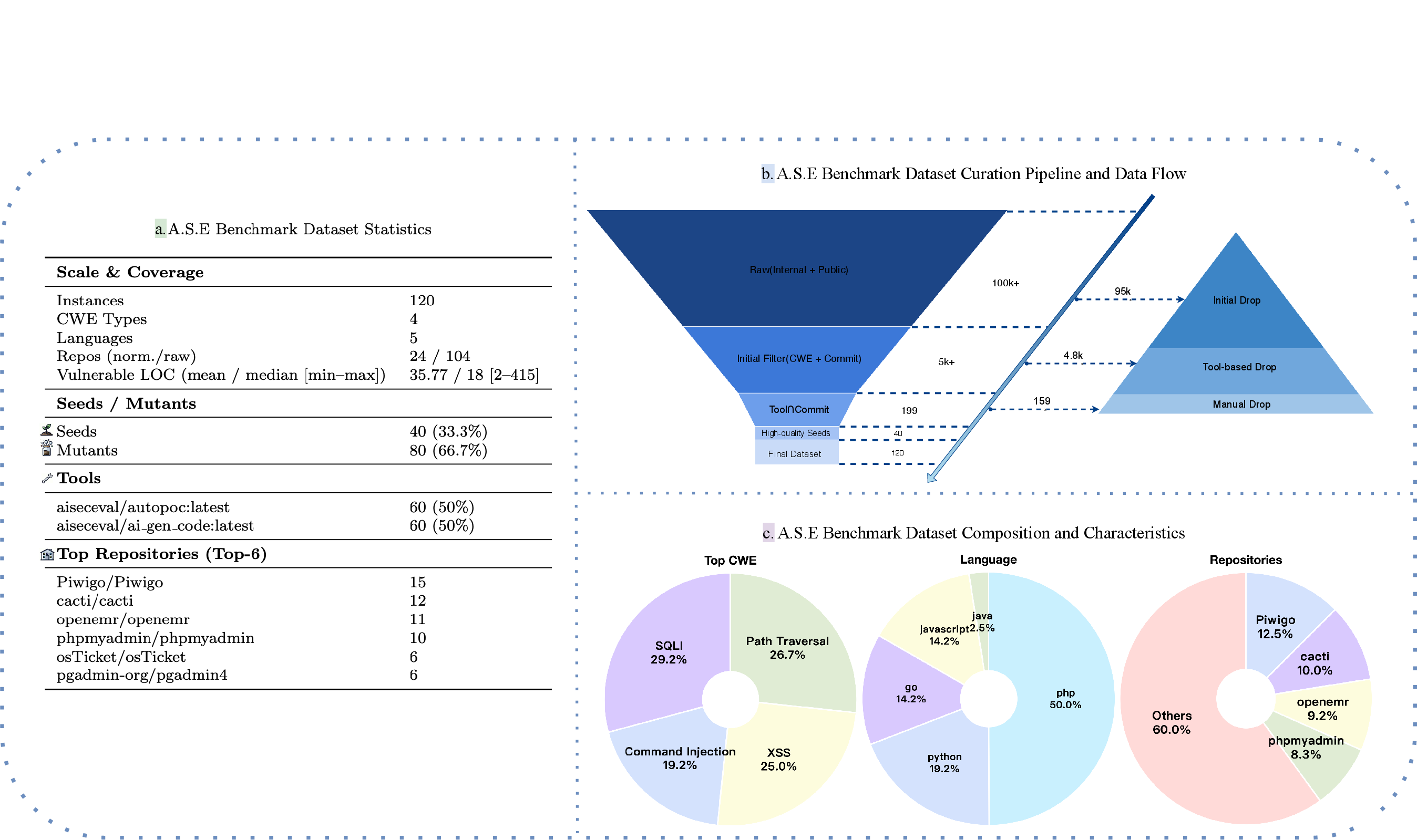
Figure 4: Statistics of A.S.E benchmark, including vulnerability and language distributions.
Evaluation Pipeline and Metrics
The evaluation pipeline consists of two stages:
- Code Generation: The model receives a masked repository (with the vulnerable region replaced by a special token), a functional vulnerability description, and repository-level context (BM25-selected files, README). The model is instructed to generate a patch, which is applied and tested in situ.
- Security Assessment: Three metrics are computed:
- Quality: Patch integration and static checks.
- Security: Reduction in detected vulnerabilities post-patch, using expert-crafted static analysis rules.
- Stability: Consistency across three independent runs, measured by standard deviation and normalized.
The overall score is a weighted sum: 0.6 × Security + 0.3 × Quality + 0.1 × Stability.
Experimental Results
Twenty-six SOTA LLMs (18 proprietary, 8 open-source) were evaluated under both "fast-thinking" (direct decoding) and "slow-thinking" (multi-step reasoning) paradigms. Key findings include:
- Security Remains a Bottleneck: No model exceeds 50 points in the Security metric. Claude-3.7-Sonnet leads overall (63.01), with high Quality (91.58) but only 46.72 in Security. Qwen3-235B-A22B-Instruct, an open-source model, achieves the highest Security score (48.03), surpassing all proprietary models.
- Repository-Level Complexity: Models that excel on snippet-level benchmarks (e.g., GPT-o3 on SafeGenBench) underperform on A.S.E due to the added complexity of cross-file dependencies and long-context reasoning.
- Fast-Thinking Outperforms Slow-Thinking: Across all models, concise, direct decoding strategies ("fast-thinking") consistently yield higher Security and Quality scores than more elaborate, multi-step reasoning ("slow-thinking"). This contradicts the expectation that increased reasoning budget improves security.
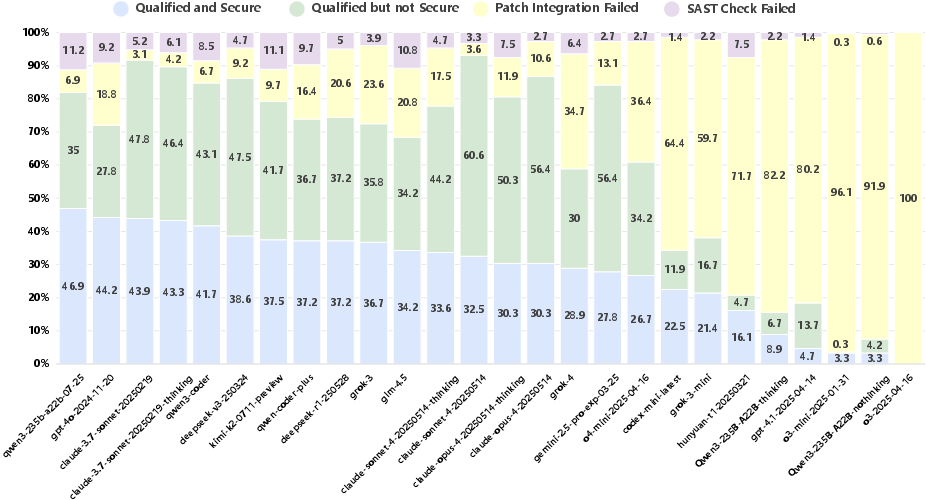
Figure 5: Attributional distribution across Code LLMs, highlighting the proportion of qualified but insecure code.
- Stability and Security Are Decoupled: Some models (e.g., GPT-o3) achieve high Stability but extremely low Security and Quality, indicating that consistent generation does not guarantee secure or correct code.
- Open-Source Competitiveness: The performance gap between open- and closed-source models is narrow. Qwen3-235B-A22B-Instruct and Kimi-K2 (open-source) are highly competitive with proprietary models in both Security and Stability.
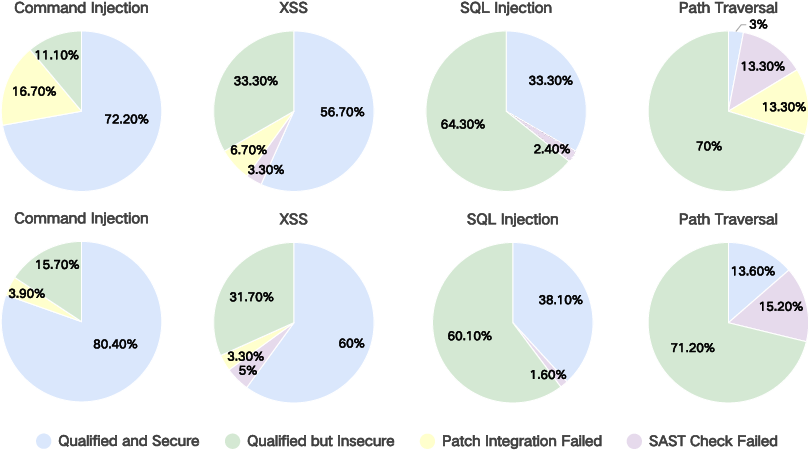
Figure 6: Detailed Attribution classification of Claude-3.7-Sonnet, showing the breakdown of code quality and security before and after mutation.
- Path Traversal Is the Hardest Task: All models perform worst on Path Traversal, with even the best models scoring below 50. This reflects the subtlety and context-dependence of path manipulation vulnerabilities.
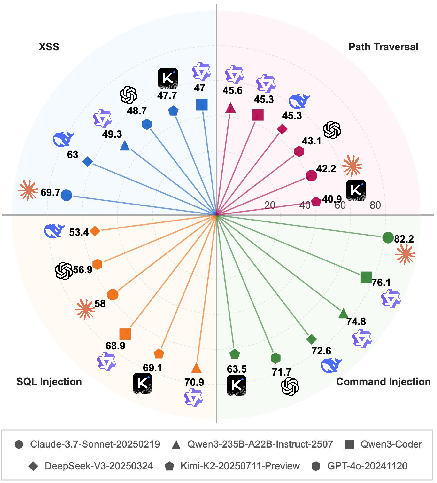
Figure 7: Detailed performance of various Code LLMs across the four A.S.E benchmark tasks.
- MoE Architectures Dominate: Leading open-source models (Qwen3, DeepSeek, Kimi-K2) employ Mixture-of-Experts architectures, which generally outperform dense models in security tasks.
Implications and Future Directions
A.S.E exposes the persistent gap between code correctness and security in LLM-generated code, especially in realistic, repository-level scenarios. The finding that "fast-thinking" decoding outperforms "slow-thinking" for security patching challenges prevailing assumptions about the benefits of multi-step reasoning in code repair. The narrow performance gap between open- and closed-source models suggests that open innovation is rapidly closing the gap in secure code generation.
Practically, A.S.E's reproducible, containerized, and multi-dimensional evaluation framework provides a robust foundation for future research in secure code generation, vulnerability repair, and context-aware code synthesis. The benchmark's extensibility to additional languages and vulnerability classes will facilitate broader adoption and more comprehensive evaluation.
Theoretically, the results highlight the need for models that explicitly reason about security properties, cross-file dependencies, and build constraints, rather than relying solely on local or syntactic cues. Future work should explore integrating formal verification, symbolic reasoning, and security-specific pretraining or instruction tuning to bridge the security gap.
Conclusion
A.S.E establishes a new standard for evaluating the security of AI-generated code at the repository level, addressing the limitations of prior snippet-based and unstable benchmarks. The benchmark's rigorous design, reproducible evaluation, and comprehensive metrics reveal that current LLMs, while proficient in code correctness, remain deficient in security, particularly for complex vulnerabilities like path traversal. The observed superiority of fast-thinking decoding and the competitiveness of open-source models have significant implications for both model development and deployment strategies. A.S.E will serve as a critical resource for advancing research and practice in secure, reliable AI-driven software engineering.