Quantized Visual Geometry Grounded Transformer
Abstract: Learning-based 3D reconstruction models, represented by Visual Geometry Grounded Transformers (VGGTs), have made remarkable progress with the use of large-scale transformers. Their prohibitive computational and memory costs severely hinder real-world deployment. Post-Training Quantization (PTQ) has become a common practice for compressing and accelerating models. However, we empirically observe that PTQ faces unique obstacles when compressing billion-scale VGGTs: the data-independent special tokens induce heavy-tailed activation distributions, while the multi-view nature of 3D data makes calibration sample selection highly unstable. This paper proposes the first Quantization framework for VGGTs, namely QuantVGGT. This mainly relies on two technical contributions: First, we introduce Dual-Smoothed Fine-Grained Quantization, which integrates pre-global Hadamard rotation and post-local channel smoothing to mitigate heavy-tailed distributions and inter-channel variance robustly. Second, we design Noise-Filtered Diverse Sampling, which filters outliers via deep-layer statistics and constructs frame-aware diverse calibration clusters to ensure stable quantization ranges. Comprehensive experiments demonstrate that QuantVGGT achieves the state-of-the-art results across different benchmarks and bit-width, surpassing the previous state-of-the-art generic quantization method with a great margin. We highlight that our 4-bit QuantVGGT can deliver a 3.7$\times$ memory reduction and 2.5$\times$ acceleration in real-hardware inference, while maintaining reconstruction accuracy above 98\% of its full-precision counterpart. This demonstrates the vast advantages and practicality of QuantVGGT in resource-constrained scenarios. Our code is released in https://github.com/wlfeng0509/QuantVGGT.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making a very large 3D vision AI model (called VGGT) much smaller and faster so it can run on real devices without losing much accuracy. VGGT turns a short video (several pictures of the same scene) into useful 3D information like camera positions, depth maps, and 3D points. The problem is: the model is huge (about 1.2 billion parameters), so it’s slow and needs a lot of memory. The authors introduce QuantVGGT, a way to shrink (quantize) VGGT to 4-bit numbers while keeping it accurate.
What questions did the researchers ask?
- How can we compress a giant 3D transformer (VGGT) so it uses much less memory and runs faster, but still gives almost the same results?
- Why do usual compression tricks (post-training quantization) struggle on 3D models like VGGT?
- Can we fix those problems with new techniques that understand how VGGT processes multi-view 3D data?
How did they do it?
The authors focus on post-training quantization (PTQ). Think of PTQ like turning detailed measurements (floating-point numbers) into shorter notes (small integers) to save space and speed up math. But doing this naively can ruin accuracy if some numbers are weirdly large or if the example data you use to “set your dials” is not representative.
The problem with making a huge 3D model smaller
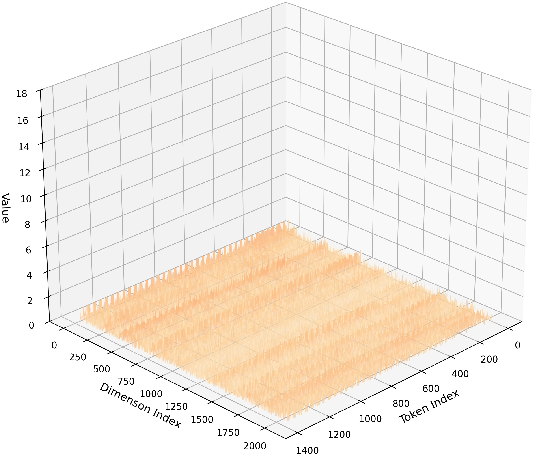
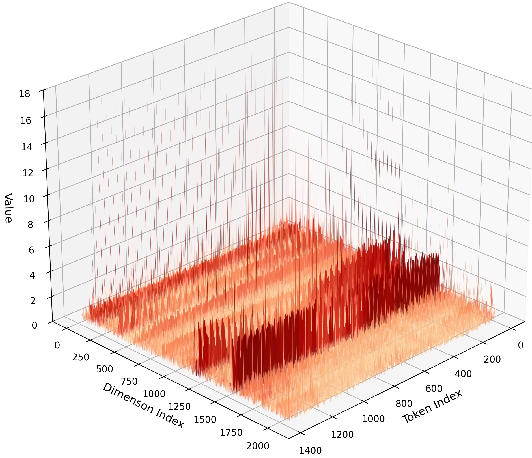
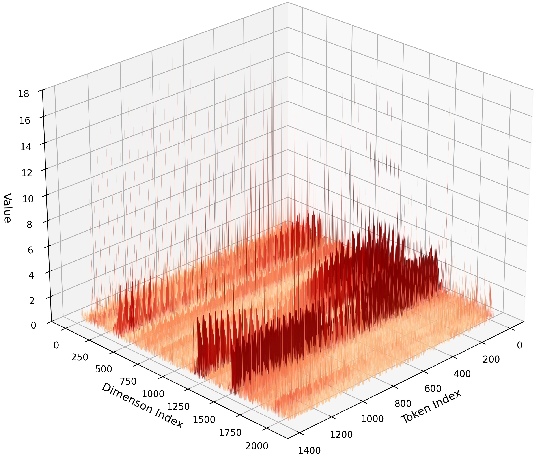
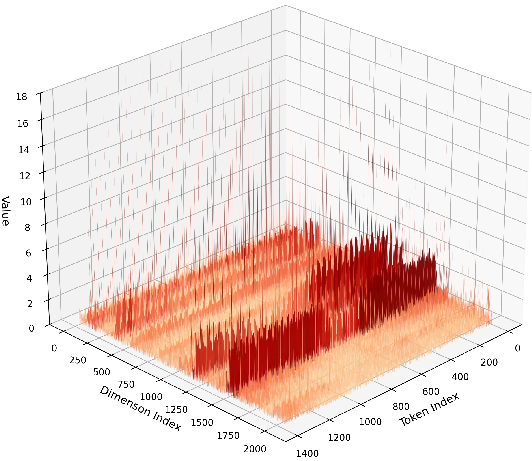
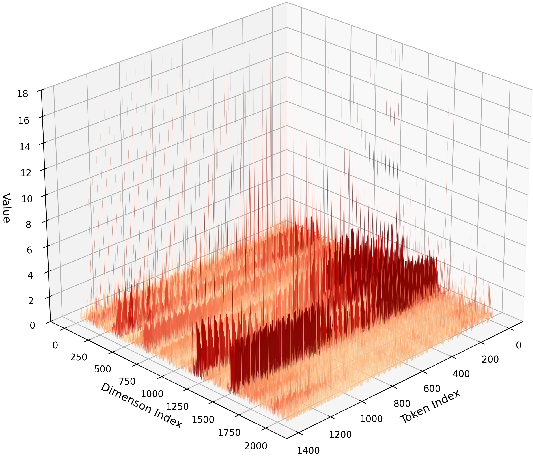
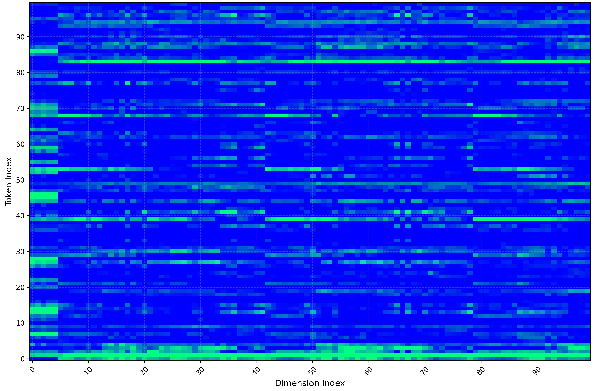
- VGGT uses special “tokens” (extra learned vectors for cameras and registration) that aren’t directly from the input images. These tokens can create heavy-tailed activations—imagine most values are small, but a few are extremely large. That makes it hard to choose good quantization ranges.
- 3D input is multi-view (many different frames). If you pick the wrong few examples to calibrate the quantizer, you’ll set bad ranges and accuracy will drop on new scenes.
To fix these, the paper proposes two main techniques.
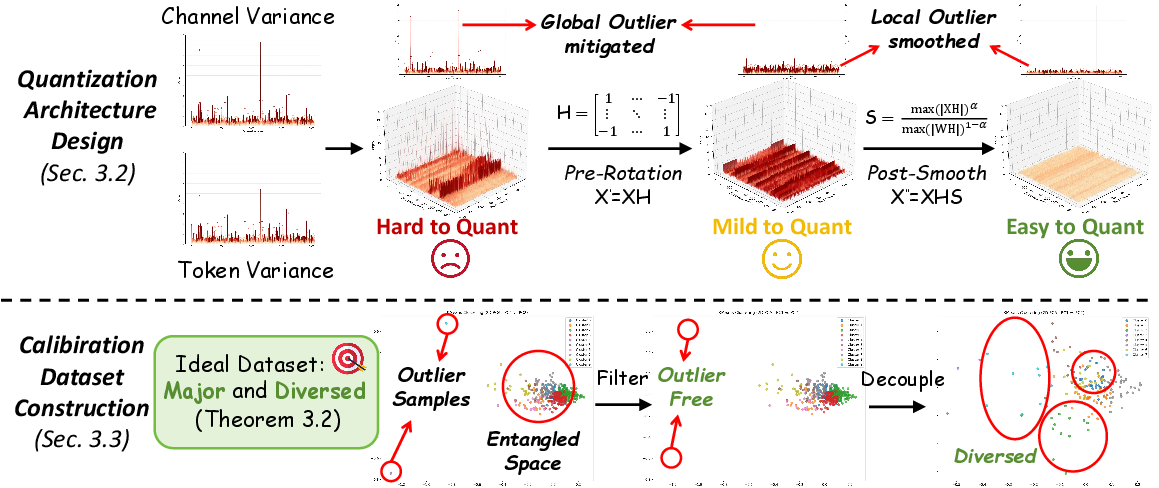
Trick 1: Dual-Smoothed Fine-Grained Quantization (DSFQ)
Goal: make the numbers more “well-behaved” before turning them into low-bit integers.
- Pre-global rotation (Hadamard transform):
- Analogy: If a few students shout while everyone else whispers, it’s hard to set the right microphone volume. A Hadamard rotation is like redistributing sound so each mic hears a more even mix. Mathematically, it “mixes” values across channels without changing the final result, spreading out extreme values so the distribution is smoother.
- Post-local smoothing (channel-wise scaling in the rotated space):
- Analogy: After mixing, some mics may still be a bit louder than others. Channel-wise scaling acts like individual volume knobs to balance each channel so none dominates.
- Fine-grained quantization granularity:
- Instead of using one shared scale for everything, they use finer-grained scales (for example, per output row for weights or per token for activations) where it doesn’t slow down the hardware. This reduces error because each small group gets its own “best-fit” scale.
Together, this dual-smoothing plus fine-grained setup significantly lowers quantization error with almost no extra runtime cost.
Trick 2: Noise-Filtered Diverse Sampling (NFDS)
Goal: pick better calibration samples so the quantizer sets fair ranges.
- Filter out noisy outliers:
- Analogy: If you’re setting the thermostat for a school, you don’t pick a weird day with a sudden heat spike. They analyze activations in deeper layers (which are more informative) and remove samples that look unusually extreme across many statistics.
- Frame-aware diverse clustering:
- 3D scenes depend on how frames relate to the first frame (VGGT has a strong “first vs. others” design). The authors compute how similar each frame is to the first frame, then cluster samples by this pattern. Finally, they pick a balanced set from all clusters. This ensures the calibration set is both representative and diverse.
What did they find?
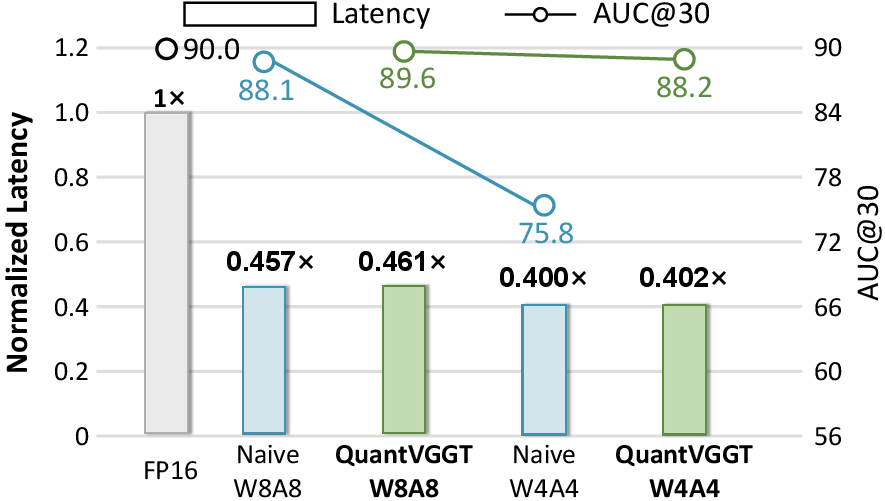
- With 4-bit weights and 4-bit activations (W4A4), QuantVGGT achieves about:
- 3.7× less memory usage
- 2.5× faster inference on real hardware
- More than 98% of the original model’s accuracy on key 3D tasks
- On two well-known 3D benchmarks:
- Co3Dv2 (camera pose estimation): QuantVGGT holds accuracy very close to the full-precision model even at 4-bit, and clearly outperforms other popular quantization methods.
- DTU (point map estimation): QuantVGGT remains strong even when the calibration data comes from a different dataset, showing good generalization.
- The new methods (DSFQ and NFDS) together beat prior quantization baselines. Rotation alone or scaling alone helps, but combining both with fine-grained quantization works best.
Why is this important?
- It makes state-of-the-art 3D understanding practical on devices with limited compute and memory, such as drones, AR/VR headsets, robots, and phones.
- Faster and smaller models save energy and reduce cost while keeping quality high.
- The ideas—smoothing extreme activations and choosing smarter calibration samples—could help compress other large multi-view or special-token transformers, not just VGGT.
In short
- Problem: VGGT is powerful for 3D tasks but too big and slow for many real uses.
- Key insight: Special tokens and multi-view data create tricky number patterns and unstable calibration.
- Solution: Dual-Smoothed Fine-Grained Quantization (mix then balance) + Noise-Filtered Diverse Sampling (filter outliers, then cluster by frame relationships).
- Result: 3.7× smaller, 2.5× faster, and still over 98% as accurate, beating other methods.
- Impact: Enables practical, high-quality 3D vision on everyday hardware.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Generalization beyond VGGT-1B: The method is only validated on VGGT-1B; it is unclear how DSFQ and NFDS transfer to other 3D transformers, smaller/larger VGGT variants, or architectures without special tokens.
- Coverage of VGGT’s full task suite: VGGT predicts depth, point maps, camera pose, and point tracking, but experiments assess only camera pose and point map; the impact on dense depth estimation and point tracking remains unknown.
- Quantization of non-linear transformer components: The paper does not specify whether and how operations like LayerNorm, Softmax attention, residual scaling, and positional encodings are quantized (or left in full precision), limiting reproducibility and clarity on what drives gains.
- Robustness under variable sequence lengths: NFDS relies on frame-aware correlation vectors anchored to the first frame; the behavior when the number of frames varies at inference/calibration time (e.g., variable f, missing first-frame semantics) is not assessed.
- Choice and sensitivity of DSFQ hyperparameters: The balancing factor α is set to 0.5 without sensitivity analysis; how performance varies with α, alternative scaling statistics (e.g., percentile vs max), and per-layer tuning is not explored.
- Per-layer quantization behavior: DSFQ’s effect across different layer depths/blocks and components (e.g., MLP vs attention projections) is not characterized, offering no guidance on which parts benefit most or fail under low-bit quantization.
- Granularity design ablation: The paper adopts out-dimension-wise weight quantization and token-wise activation quantization, but does not compare against other granularities (per-channel, per-head, per-group) to justify the chosen scheme.
- Extremely low-bit regimes: Results are reported for W8A8 and W4A4; feasibility and failure modes at W3A3/W2A2 (or mixed-precision regimes) are unexamined.
- Special-token handling alternatives: The approach mitigates heavy tails via Hadamard rotation and smoothing; alternatives such as mixed-precision for special tokens, token reparameterization, or token gating are not investigated.
- Hadamard rotation practicality: Implementation details for non-power-of-two dimensions (padding, block-wise Hadamard, or alternative orthogonal transforms) and their impact on accuracy/latency are not provided.
- Quantization error theory: The “central limit effect” lemma is stated informally; formal conditions under which Hadamard rotation yields Gaussianization and quantization error bounds are not established, limiting theoretical guarantees.
- Attention-range calibration: How NFDS and DSFQ stabilize quantization ranges for attention logits/Softmax (which are highly sensitive) is not described; potential underflow/overflow and mitigation strategies are unclear.
- Calibration pipeline specification: The size of the calibration set, number of clusters K, percentile threshold T, layer set L, and the computational overhead of NFDS (feature extraction + K-Means) are not quantified, obstructing practical replication.
- Domain shift robustness: Calibration is done on Co3Dv2 while evaluation includes DTU, but a systematic study of cross-dataset/domain shifts (e.g., indoor/outdoor, occlusions, motion blur, extreme lighting) is missing.
- Outlier handling at inference: NFDS filters outliers during calibration, yet the method’s robustness when encountering unseen or extreme outliers at inference time is not evaluated.
- Hardware and kernel details: Reported 2.5× speedup and 3.7× memory reduction lack explicit hardware specs (GPU/CPU/NPU/ISA), integer GEMM kernels, activation caching strategies, and memory measurement protocol (batch size, sequence length), limiting portability and reproducibility.
- Integer-only execution scope: Claims about avoiding dequantization when “sharing quantization parameters across the summation” do not detail how per-token activation scales are implemented in GEMM without incurring extra conversions; practical kernel designs and constraints are not shown.
- Mixed-precision opportunities: The paper does not evaluate mixed schemes (e.g., higher precision for special tokens, attention logits, LayerNorm) that could further stabilize low-bit inference.
- Failure-case analysis: No qualitative or per-scene error analysis (e.g., failure modes under textureless surfaces, specularities, fast motion, large parallax) is provided to understand residual weaknesses.
- Energy and deployment metrics: Latency is reported, but energy consumption, throughput under memory bandwidth constraints, and end-to-end system-level performance in edge devices are not measured.
- Fairness and tuning parity of baselines: It is unclear whether baseline methods (e.g., SmoothQuant, QuaRot, GPTQ) received task-specific tuning or optimal calibrations for 3D models; potential under-tuning may bias comparisons.
- Reproducibility constraints: Key implementation details are deferred to the appendix and code release is “upon publication,” making independent verification difficult at present.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, grounded in the paper’s findings and released code, and mapped to likely sectors. Each item highlights potential tools/workflows and the assumptions or dependencies that affect feasibility.
- Robotics (SLAM, navigation, mapping)
- Application: Deploy VGGT quantized to W4A4 on embedded platforms (e.g., NVIDIA Jetson, Qualcomm/Apple NPUs) to run real-time multi-view SLAM and 3D mapping with 2.5× speedup and 3.7× memory reduction while maintaining ~98% accuracy.
- Tools/Workflows: Integrate the Dual-Smoothed Fine-Grained Quantization (DSFQ) into the inference graph, perform NFDS calibration with representative scenes, compile INT kernels via TensorRT/TVM, fuse scale factors as suggested by the paper.
- Assumptions/Dependencies: Availability of INT4/INT8 acceleration; access to multi-view camera streams; target domain similar to calibration data; adaptation effort to real-time pipelines.
- AR/VR and XR (inside-out tracking, room-scale reconstruction)
- Application: On-device dense depth and point map reconstruction in headsets or smartphones, reducing latency and power consumption for stable tracking and spatial anchoring.
- Tools/Workflows: Use NFDS to build a small, representative calibration set from typical indoor scenes; deploy DSFQ-quantized VGGT via mobile inference runtimes; fuse DSFQ’s scales to keep runtime overhead near-zero.
- Assumptions/Dependencies: Mobile runtime support for low-bit matmul; consistent multi-view inputs; calibration data reflecting indoor lighting/texture variability.
- Drones/UAVs (real-time surveying and inspection)
- Application: Real-time camera pose estimation and point map generation on resource-limited flight controllers, enabling faster coverage and longer endurance due to lower compute and memory.
- Tools/Workflows: Pre-flight NFDS calibration from known terrains (e.g., construction site, farmland); deploy DSFQ-quantized VGGT on edge modules; pair with GPS/IMU for robustness.
- Assumptions/Dependencies: Hardware support for low-bit inference on drone compute; reliable multi-view capture; domain generalization from calibration scenes.
- Consumer 3D scanning and photogrammetry apps
- Application: Improve responsiveness and battery life in mobile apps capturing rooms/objects for e-commerce, home improvement, and digital twins, with quantized VGGT replacing heavier pipelines.
- Tools/Workflows: App-side NFDS calibration wizard (captures a short, diverse video of target environments); push DSFQ-quantized model updates; export meshes/point clouds via standard formats.
- Assumptions/Dependencies: Smartphone NPUs/GPUs with suitable integer kernels; user consent and storage limits; robust handling of diverse lighting and motion blur.
- Cloud cost and energy reduction for 3D pipelines
- Application: Reduce inference cost and carbon footprint for large-scale 3D reconstruction jobs (e.g., content creation, digital-twin generation) by switching full-precision VGGT to W8A8/W4A4 with minimal accuracy loss.
- Tools/Workflows: Batch NFDS calibration for typical client domains; DSFQ quantization of VGGT in PyTorch/ONNX; track accuracy vs. cost via ML Ops dashboards.
- Assumptions/Dependencies: Cloud accelerators with low-bit support; end-user tolerance for small accuracy differences; monitoring for domain drift.
- Academic research enablement (lower barrier to experimentation)
- Application: Run billion-parameter VGGT variants on commodity GPUs for teaching and experimentation (depth estimation, pose prediction, tracking) with quantization reducing memory and latency.
- Tools/Workflows: Incorporate the authors’ released code; adopt NFDS to create small calibration sets per dataset; reproduce benchmarks and ablations with reduced compute.
- Assumptions/Dependencies: Access to VGGT weights and licenses; students’ hardware supports INT8/INT4; domain-specific calibration is performed.
- Privacy-preserving, on-device processing (Policy and compliance)
- Application: Keep multi-view visual data on-device (instead of uploading to cloud) by leveraging efficient quantized inference, improving compliance with data-protection laws.
- Tools/Workflows: NFDS calibration performed locally; DSFQ quantization compiled to the device runtime; implement privacy controls and model cards documenting quantization performance.
- Assumptions/Dependencies: Local hardware acceleration; legal review for edge processing; robust logging to satisfy audit trails.
- Daily life consumer use (capturing personal spaces/objects)
- Application: Faster, more battery-friendly 3D capture for home remodel planning, furniture fitting, and DIY projects using quantized VGGT in camera apps.
- Tools/Workflows: Guided NFDS calibration mode “scan your room in 30 seconds”; DSFQ model updated via app; offline export for AR visualization.
- Assumptions/Dependencies: Device support; user willingness to run calibration; variability in home environments and lighting conditions.
Long-Term Applications
Below are applications that may require additional research, scaling, hardware standardization, or regulatory validation before deployment.
- Hardware–algorithm co-design for INT4/INT8 3D transformers
- Application: Native kernels/hardware units that fuse Hadamard rotation and per-channel scaling, reducing overhead and making DSFQ a first-class primitive in compilers/runtimes.
- Tools/Workflows: Co-design with silicon vendors; add DSFQ passes to compilers (TVM/XLA); standardized INT4 ops across CUDA, Metal, and NNAPI.
- Assumptions/Dependencies: Industry-wide support for INT4; compiler changes; vendor buy-in and benchmarking.
- Adaptive, streaming calibration for distribution shifts
- Application: NFDS extended to online, continual calibration for changing environments (weather, lighting, scene types), maintaining accuracy on-device over time.
- Tools/Workflows: Rolling NFDS buffers; automatic outlier filtering via deep-layer statistics; K-Means updates to cluster assignments; watchdogs for accuracy drift.
- Assumptions/Dependencies: Safe on-device metrics; storage and compute budgets; robust fallback to full precision or higher bit-width during anomalies.
- Generalization to other 3D foundation models with special tokens
- Application: Apply DSFQ+NFDS to multi-task 3D models beyond VGGT (e.g., newer architectures with data-independent tokens), creating a standard quantization recipe for 3D transformers.
- Tools/Workflows: Model-agnostic DSFQ modules; token-aware statistics collectors; sector-specific calibration suites.
- Assumptions/Dependencies: Access to model internals; matching inductive biases (frame-relative modeling); empirical validation across tasks.
- Integrated AR cloud and mobile ecosystems
- Application: Hybrid workflows where quantized on-device VGGT handles real-time capture and the cloud refines models asynchronously, balancing privacy, latency, and fidelity.
- Tools/Workflows: Edge–cloud handoff policies; configurable bit-widths per stage; ML Ops for calibration lifecycle management.
- Assumptions/Dependencies: Reliable connectivity; interoperable formats; consistent scene semantics between edge and cloud.
- Healthcare (endoscopy, surgical planning, medical training)
- Application: Real-time 3D reconstruction from multi-view medical imagery on low-power devices for navigation and training, reducing hardware complexity in operating rooms.
- Tools/Workflows: Domain-specific NFDS calibration from approved datasets; rigorous validation under clinical protocols; hardware with deterministic low-bit behavior.
- Assumptions/Dependencies: Regulatory approval; clinical-grade reliability; careful bias and safety audits; collaboration with medical device manufacturers.
- Industrial inspection and metrology
- Application: On-device 3D mapping of factory floors, pipelines, and assemblies with quantized VGGT, enabling frequent inspections without heavy compute.
- Tools/Workflows: NFDS calibrated to materials/lighting of industrial sites; DSFQ compiled for ruggedized edge computers; tie-ins to maintenance software.
- Assumptions/Dependencies: Harsh environment robustness; reflective/textureless surfaces; integration with existing asset-management systems.
- Standards and policy for “Green AI” quantization practices
- Application: Incorporate quantization (e.g., W8A8/W4A4) into procurement and compliance guidelines to reduce energy footprints in public-sector and enterprise AI deployments.
- Tools/Workflows: Model cards reporting energy/accuracy trade-offs; audits requiring NFDS-like calibration transparency; benchmarking standards for 3D models.
- Assumptions/Dependencies: Policymaker adoption; sector-specific thresholds for accuracy; agreed-upon measurement protocols.
- Education and workforce development
- Application: Curriculum on efficient 3D perception that includes DSFQ/NFDS, preparing students and engineers to deploy large 3D models on commodity hardware.
- Tools/Workflows: Teaching modules; lab exercises reproducing W8A8/W4A4 performance; open datasets and code exercises from the authors’ repository.
- Assumptions/Dependencies: Continued open-source access; hardware availability in classrooms; alignment with evolving 3D model designs.
Glossary
- AUC@30: A task-specific area-under-curve metric thresholded at 30 (often degrees) for camera pose evaluation. "with AUC@30 of 89.4 and 89.5 for FP (Full Precision)."
- Bit-width: The number of bits used to represent weights or activations in quantized models. "across different benchmarks and bit-width, surpassing the previous state-of-the-art generic quantization method with a great margin."
- Block-wise reconstruction: A PTQ strategy that minimizes reconstruction error at the block level to improve quantized accuracy. "BRECQ builds the block-wise reconstruction framework,"
- Calibration clusters: Groupings of samples used during PTQ calibration to ensure representative coverage of data modes. "constructs frame-aware diverse calibration clusters"
- Calibration dataset: A small set of data used to tune quantization parameters without retraining model weights. "a relatively small calibration dataset"
- Calibration set: The selected subset of samples ultimately used during calibration. "a small calibration set"
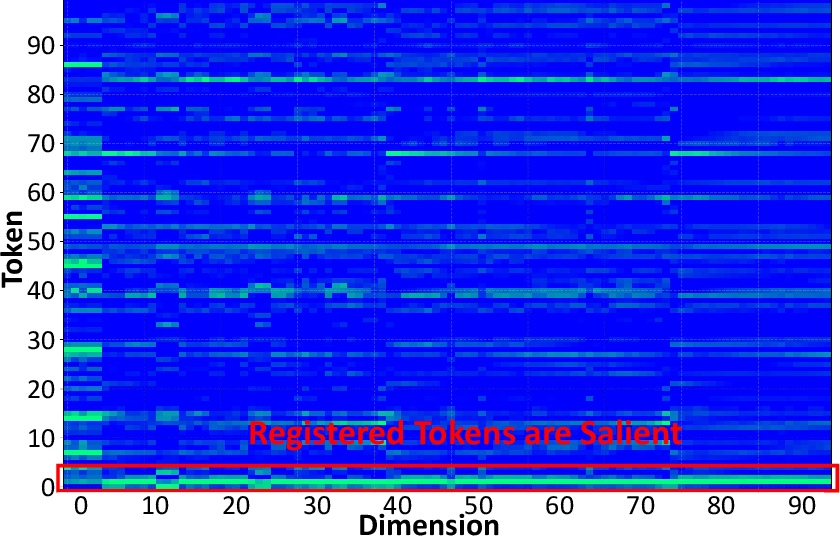
- Camera token: A special token appended to frame tokens to aggregate global camera-related information. "augments each frame with one camera token and four register tokens"
- Central limit effect: The tendency of aggregated random variables to approximate a Gaussian distribution, used to justify distribution smoothing. "Due to the central limit effect, the distribution of values after Hadamard rotation tends to approximate a Gaussian,"
- Channel-wise scale: Per-channel scaling factors applied to balance activation/weight magnitudes before quantization. "we introduce a channel-wise scale to normalize the internal channel distributions:"
- Co3Dv2: A dataset for evaluating camera pose and 3D reconstruction performance. "on Co3Dv2 dataset"
- Data-independent special tokens: Learned tokens injected regardless of input that can skew activation statistics. "data-independent special tokens (camera and register tokens)"
- Dense depth estimation: Predicting a per-pixel depth map for an image or frame. "including dense depth estimation, point map regression, camera pose prediction, and point tracking"
- DINOv2: A pretrained vision backbone used for tokenizing frames. "such as DINOv2"
- DTU: A dataset used for point map estimation and 3D benchmarking. "DTU dataset"
- Dual-Smoothed Fine-Grained Quantization (DSFQ): The paper’s rotate-and-scale PTQ scheme combining global Hadamard rotation and local channel smoothing with fine granularity. "Dual-Smoothed Fine-Grained Quantization (DSFQ)"
- Fine-Grained Quantization Granularity: Using smaller quantization groups (e.g., per-token or per-output-channel) to reduce quantization error. "Fine-Grained Quantization Granularity."
- Frame-aware correlation vector: A compact representation measuring similarity between the first frame and subsequent frames to guide clustering. "construct a compact frame-aware correlation vector"
- Full-precision: The original floating-point model representation before quantization. "full-precision counterpart."
- Hadamard matrix: An orthogonal matrix with entries ±1 used here to rotate features without changing dot products. "A Hadamard matrix"
- Hadamard rotation: Applying a Hadamard transform to spread outliers and smooth activation/weight distributions. "the distribution of values after Hadamard rotation tends to approximate a Gaussian,"
- Heavy-tailed activation distributions: Activation distributions with extreme outliers that hinder effective quantization. "heavy-tailed activation distributions"
- Inductive bias: Architectural or procedural assumptions that guide learning, such as frame-relative modeling. "contains a strong inductive bias"
- K-Means: A clustering algorithm used to form calibration regions. "using K-Means"
- Low-bit quantization: Representing weights/activations with very few bits (e.g., 4-bit) to save memory and compute. "ensuring its performance even at low-bit quantization."
- Matrix multiplication invariance: Property that certain rotations preserve the result of matrix multiplication, enabling lossless pre/post transforms. "the matrix multiplication invariance is preserved as follows:"
- Mu-coherent: A measure of quantization difficulty bounding the maximum element relative to the group norm. "the concept of `-coherent'"
- Multi-view: Data comprising multiple distinct views of a scene, common in 3D reconstruction. "the multi-view nature of 3D data"
- Noise-Filtered Diverse Sampling (NFDS): The proposed calibration sample selection that filters outliers and enforces diversity via clustering. "Noise-Filtered Diverse Sampling (NFDS)"
- Noise-score: A statistic combining layerwise mean/variance deviations to identify and remove outlier samples. "We then compute a noise-score using global robust moments:"
- Out-dimension-wise quantization: Quantizing weights per output dimension (row-wise) to reduce error while preserving integer GEMM efficiency. "we apply out-dimension-wise quantization to the weights"
- Outlier filtering: Removing atypical samples whose statistics deviate strongly to stabilize calibration. "filters outliers via deep-layer statistics"
- Point map estimation: Predicting 3D point locations corresponding to image pixels/patches. "the point map estimation task"
- Post-local channel smoothing: Channel-wise normalization applied after rotation to balance per-channel variance. "post-local channel smoothing"
- Post-Training Quantization (PTQ): Quantization that tunes scaling/ranges using a small calibration set without updating model weights. "Post-Training Quantization (PTQ)"
- Pre-global Hadamard rotation: A global Hadamard transformation applied before smoothing to disperse outliers. "pre-global Hadamard rotation"
- Quantization-Aware Training (QAT): Training with simulated quantization in the loop to learn robust weights/scales. "Quantization-Aware Training (QAT)"
- Quantization bins: Discrete integer levels to which continuous values are mapped in quantization. "occupy most of the quantization bins"
- Quantization ranges: The min/max (or scale) bounds used to map real values to quantized levels. "ensure stable quantization ranges"
- QuantVGGT: The paper’s quantization framework specialized for VGGT models. "QuantVGGT"
- Register tokens: Special tokens appended to frames to aggregate specific 3D attributes across views. "four register tokens"
- Rotation-based quantization: PTQ methods that apply orthogonal rotations (e.g., Hadamard) to smooth distributions before quantization. "rotation-based quantization"
- Robust moments: Statistics (means/variances) computed in a way that is resilient to outliers for scoring/filtering. "global robust moments"
- Symmetric quantization: Mapping values to signed integer ranges centered at zero using a single scale per group. "the symmetric quantization procedure can be described as:"
- Token registration: The process of concatenating special tokens (e.g., camera/register) to frame tokens before the backbone. "the token registration process is defined as"
- Token-wise quantization: Quantizing activations per token to reduce loss while keeping integer accumulation coherent. "token-wise quantization"
- Tokenization: Converting input images into sequences of tokens via a vision backbone. "VGGT first tokenizes each frame"
- Visual Geometry Grounded Transformer (VGGT): A large transformer that predicts multiple 3D attributes from image sequences in one pass. "Visual Geometry Grounded Transformer (VGGT)"
- W4A4: A 4-bit weight and 4-bit activation quantization configuration. "to W4A4 without compromising visual quality"
- W8A8: An 8-bit weight and 8-bit activation quantization configuration. "W8A8 (8-bit weight and 8-bit activation quantization)"
Collections
Sign up for free to add this paper to one or more collections.