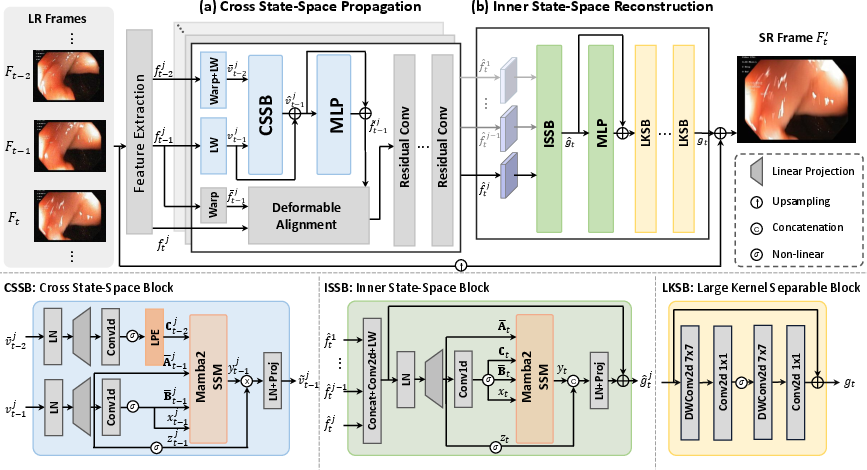
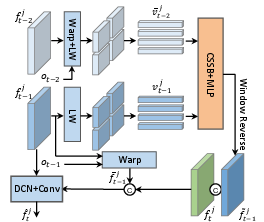
- The paper introduces MedVSR, which employs cross state-space propagation and inner state-space reconstruction to robustly enhance resolution in clinical videos.
- It achieves superior PSNR and SSIM metrics while using fewer parameters and lower FLOPs compared to state-of-the-art VSR models.
- The framework’s efficiency and artifact reduction suggest promising real-time applications in diagnostics and adaptive multi-modal video analysis.
MedVSR: Medical Video Super-Resolution with Cross State-Space Propagation
Motivation and Challenges in Medical Video Super-Resolution
Medical video super-resolution (VSR) is critical for enhancing diagnostic accuracy by reconstructing high-resolution (HR) frames from low-resolution (LR) clinical video sequences. Unlike natural scene videos, medical videos are characterized by abrupt transitions, camera jitter, and continuous tissue structures, which introduce significant challenges for conventional VSR models. These challenges manifest as large optical flow errors, unreliable frame alignment, and a propensity for artifact generation and texture distortion, especially when using standard CNN or transformer-based VSR architectures.
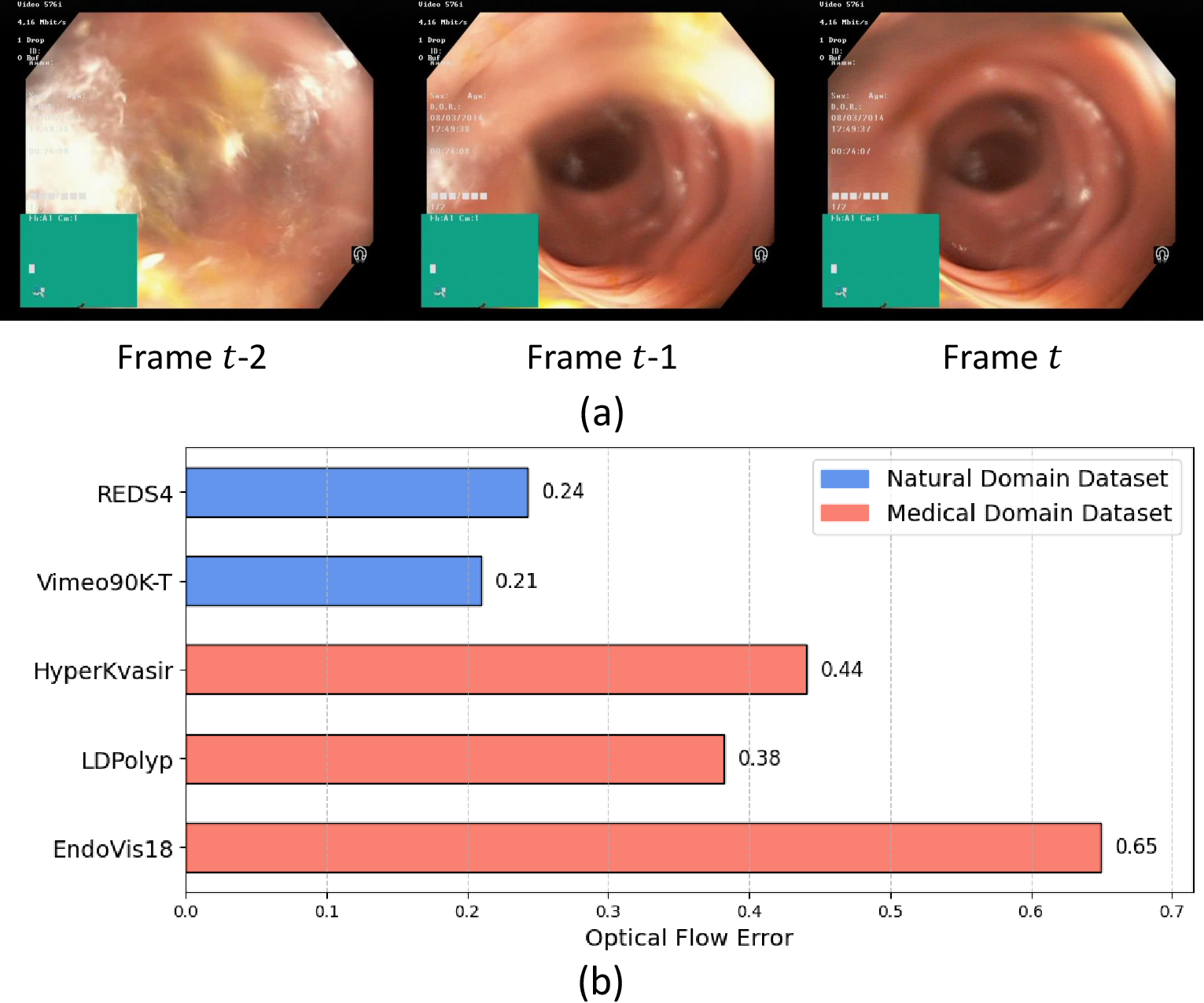
Figure 1: Example of sharp transitions and jitter in medical videos, especially for distant frames (e.g., frame t−2→t), which pose significant challenges for existing alignment methods.
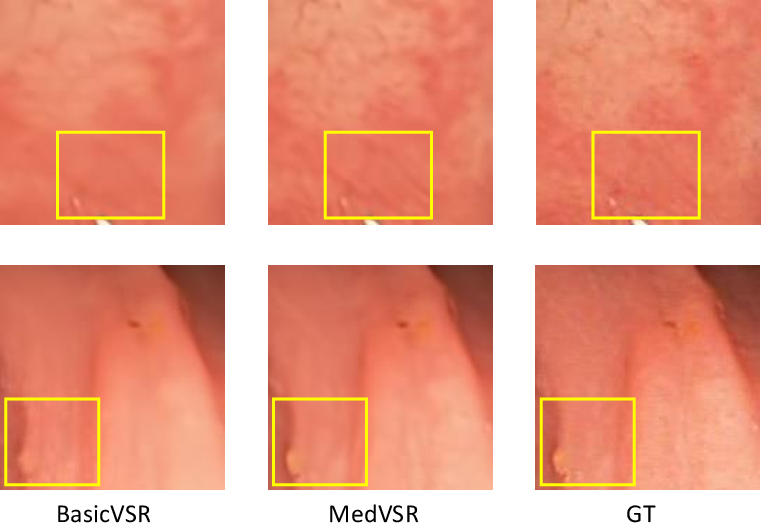
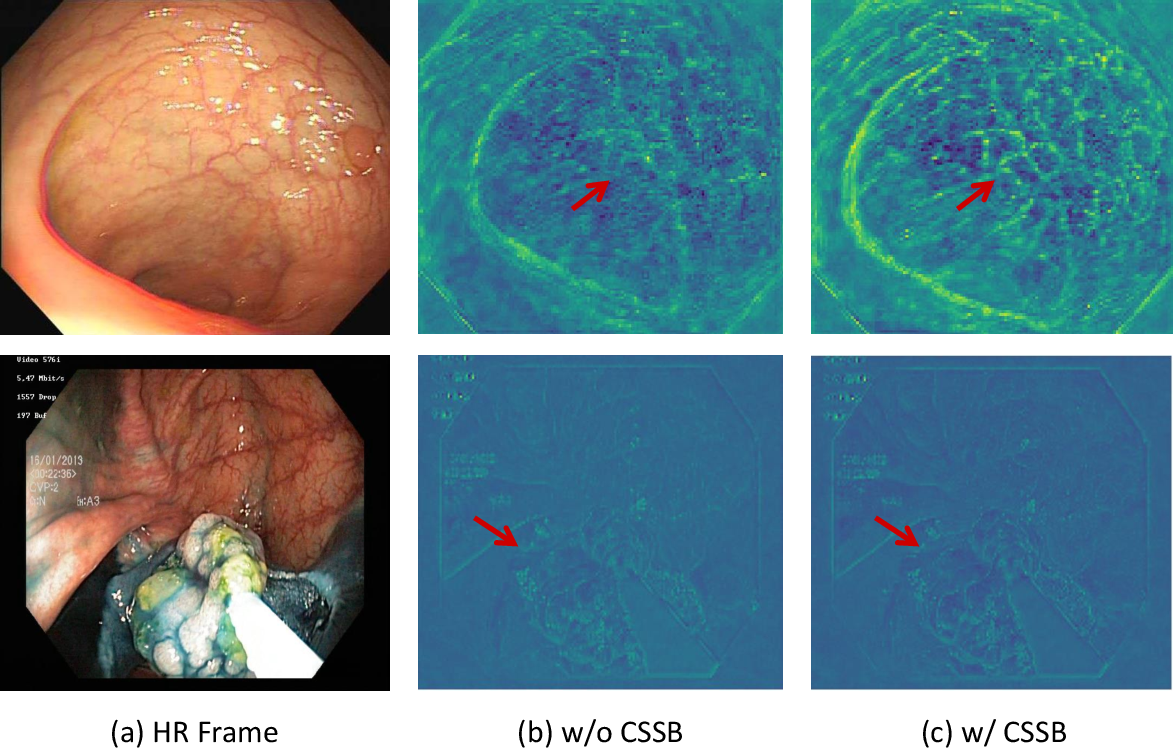
Figure 2: Examples of texture removal and shape distortion of existing VSR methods, which can mislead clinical interpretation.
MedVSR Framework Overview
MedVSR introduces a domain-specific VSR framework that leverages state-space models (SSMs) for robust feature propagation and reconstruction. The architecture consists of two principal modules:
Cross State-Space Propagation (CSSP)
CSSP departs from direct alignment of distant frames, instead projecting their features as control matrices in a cross state-space block (CSSB). This enables selective propagation of stable features, improving alignment robustness. The process involves:
Inner State-Space Reconstruction (ISSR)
ISSR aggregates features from multiple CSSP branches, concatenates them, and applies SSMs for long-range spatial modeling. Large kernel separable blocks (LKSB) are then used for short-range aggregation, which is empirically shown to reduce artifacts and preserve fine-grained anatomical details.
Experimental Results and Comparative Analysis
MedVSR is evaluated on four diverse medical video datasets, including HyperKvasir, LDPolyp, EndoVis18, and Cataract-101. The framework consistently outperforms state-of-the-art VSR models (EDVR, BasicVSR, BasicVSR++, VSRT, RVRT, TCNet, IART) in both quantitative metrics (PSNR, SSIM) and qualitative fidelity.
- On HyperKvasir, MedVSR achieves a PSNR of 32.10, surpassing VSRT by 0.32 while using 3.5× fewer parameters and 10.9× fewer FLOPs.
- On LDPolyp, MedVSR attains a PSNR of 31.83 and SSIM of 0.8673, outperforming IART with 3.6× fewer FLOPs.
- On Cataract-101, MedVSR yields 36.23 PSNR and 0.9308 SSIM, exceeding TCNet by 1.63 PSNR and 0.013 SSIM with lower computational cost.
MedVSR also demonstrates superior inference speed, being 6–18× faster than transformer-based VSR models on clinical video clips.
Figure 5: Qualitative comparisons on HyperKvasir, showing MedVSR's reduction of artifacts and accurate texture reconstruction.
Figure 6: Qualitative comparisons on Cataract-101, highlighting MedVSR's preservation of anatomical structure and color.
Ablation and Component Analysis
Ablation studies confirm the necessity of each architectural component:
Theoretical and Practical Implications
MedVSR demonstrates that SSM-based propagation and reconstruction are highly effective for medical VSR, where temporal instability and anatomical continuity are critical. The use of cross state-space modeling for inter-frame dependency and large-kernel aggregation for artifact suppression provides a robust solution for clinical video enhancement. The framework's efficiency and generalization across diverse medical scenarios suggest strong potential for real-time deployment in diagnostic and surgical settings.
Future Directions
The integration of SSMs in VSR opens avenues for further research in:
- Adaptive control matrix learning for multi-modal medical video analysis.
- Extension to 3D volumetric video and multi-view surgical scenes.
- Joint optimization with downstream clinical tasks (e.g., segmentation, detection) for end-to-end diagnostic pipelines.
- Hardware-aware model compression for edge deployment in operating rooms.
Conclusion
MedVSR introduces a principled approach to medical video super-resolution by leveraging cross state-space propagation and inner state-space reconstruction. The framework addresses the unique challenges of medical video data, achieving state-of-the-art performance and efficiency. Its architectural innovations and empirical results substantiate the utility of SSMs for robust, artifact-free medical video enhancement, with significant implications for clinical practice and future AI research in medical imaging.