- The paper introduces Sigma, a unified framework that employs semantically informed pre-training to improve isolated recognition, continuous recognition, and gloss-free translation tasks.
- The methodology integrates SignEF for bidirectional cross-modal feature fusion, HAL for local and global alignment, and a dual-path SGT encoder for sign-text matching and language modeling.
- Comprehensive evaluations across multiple benchmarks demonstrate that Sigma outperforms traditional approaches with improved accuracy, efficiency, and semantic grounding.
Introduction and Motivation
Sigma addresses three persistent challenges in skeleton-based sign language understanding (SLU): weak semantic grounding of visual features, imbalance between local and global feature modeling, and inefficient cross-modal alignment. Existing skeleton-based SLU models often capture low-level motion patterns but fail to relate them to linguistic meaning, struggle to balance fine-grained gesture details with global context, and are limited in their ability to align visual and textual modalities. Sigma proposes a unified framework that leverages semantically informed pre-training to overcome these limitations, enabling robust performance across isolated sign language recognition (ISLR), continuous sign language recognition (CSLR), and gloss-free sign language translation (SLT).
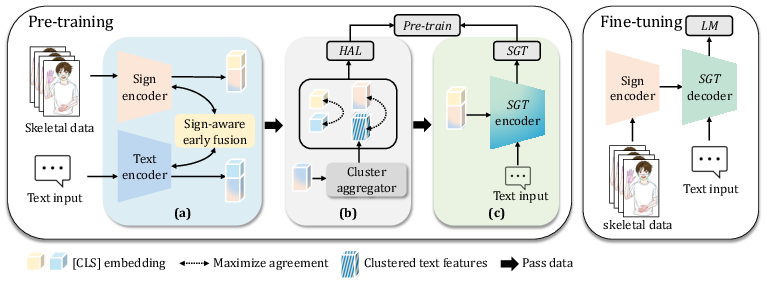
Figure 1: Overview of Sigma. (a) SignEF enhances visual-linguistic alignment by injecting cross-modal features into sign and text encoders. (b) HAL is used to maximise global and local cluster agreement. (c) SGT encoder jointly optimises sign-text matching and language modelling. During fine-tuning, both the sign and SGT encoders are reused across SLU tasks.
Methodology
Sign-aware Early Fusion (SignEF)
SignEF introduces bidirectional cross-modal interaction at the encoding stage, enabling deep integration of visual (skeletal) and textual features. This is implemented via cross-attention layers that inject textual cues into the visual encoding process and vice versa. The fusion is applied in the final layers of the encoders, with parameter sharing across attention heads to promote fine-grained alignment while maintaining efficiency. Empirical results show that the optimal number of fusion layers is task-dependent: shallow fusion benefits context-sensitive tasks (CSLR, SLT), while deeper fusion is advantageous for visually intensive tasks (ISLR).
Hierarchical Alignment Learning (HAL)
HAL maximizes agreement between sign-text pairs at both global and local cluster levels using contrastive objectives. Global alignment is achieved by projecting class-token representations from both modalities into a shared space, while local alignment is enforced by clustering subword-level textual tokens and aligning them with visual segments. The cluster aggregator module dynamically groups tokens into semantically meaningful units, approximating gloss-like groupings without requiring manual annotation.
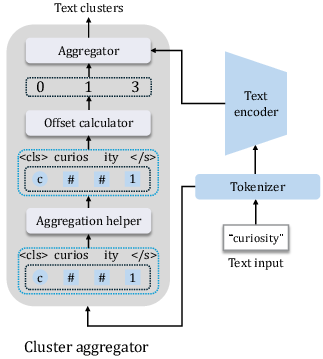
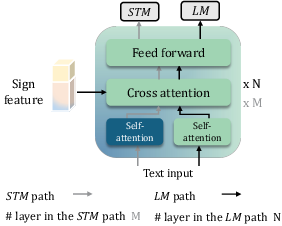
Figure 2: The overview of the cluster aggregator module. It converts sub-word token embeddings into cluster-level representations by grouping tokens, mapping them with offset indices, and aggregating hidden features for semantic alignment with visual inputs.
The HAL loss is a weighted sum of global and local contrastive losses, with a trade-off parameter α controlling the balance. Empirical analysis demonstrates that α=0.5 yields optimal results across all tasks, confirming the necessity of modeling both detailed gesture information and high-level semantics.
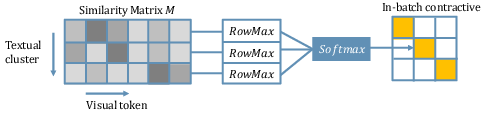
Figure 4: Illustration of the local cluster-wise contrastive learning process. The similarity matrix is computed between visual tokens and textual clusters, with in-batch local cluster contrastive learning applied to pull semantically aligned pairs closer.
Sign-grounded Text (SGT) Encoder
The SGT encoder unifies sign-text matching (STM) and language modeling (LM) within a dual-path architecture. The STM path uses cross-attention to align textual tokens with sign features, while the LM path preserves linguistic fluency via standard transformer layers. The composite SGT loss balances discriminative matching and generative modeling, with the trade-off parameter β tuned per task. This design enables the model to learn representations that are both semantically grounded in visual input and linguistically coherent.
Experimental Results
Sigma is evaluated on four benchmarks: WLASL2000 (ISLR), CSL-Daily (CSLR, SLT), How2Sign (SLT), and OpenASL (SLT). The model consistently achieves state-of-the-art results across all tasks and datasets, outperforming both skeleton-based and pose-RGB-based baselines.
- ISLR (WLASL2000): Sigma achieves 64.40% per-instance and 62.32% per-class Top-1 accuracy, surpassing prior SOTA by a significant margin.
- CSLR (CSL-Daily): Sigma attains a WER of 25.92% on the test set, outperforming the previous best by 0.08–0.28 absolute WER.
- SLT (How2Sign, OpenASL, CSL-Daily): Sigma sets new SOTA on OpenASL and How2Sign, and matches or exceeds gloss-based models on CSL-Daily, despite being gloss-free.
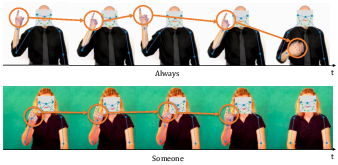
Figure 5: Visualization derived from the WLASL2000 dataset. The right hand and its motion trajectory are highlighted for two sign sequences, “Always” and “Someone.” Disambiguation requires both local detail and global temporal understanding, motivating Sigma’s multimodal representation learning.

Figure 7: t-SNE visualisation of ISLR on WLASL, showing improved cross-modal alignment and cluster compactness with Sigma’s pre-training.
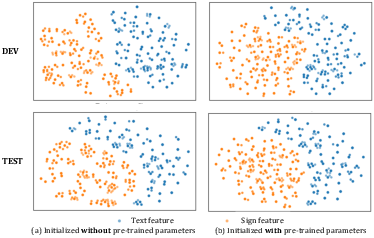
Figure 9: t-SNE visualisation of CSLR on CSL-Daily, demonstrating enhanced alignment between sign and text features after pre-training.
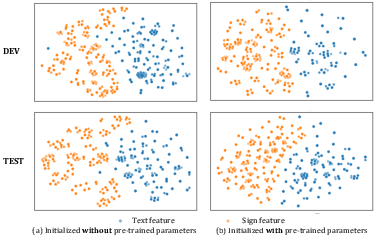
Figure 3: t-SNE visualization of SLT on CSL-Daily, illustrating the effect of pre-training on cross-modal semantic structure.
Qualitative analysis further demonstrates that Sigma’s outputs preserve semantic meaning even when lexical or syntactic variations occur, reflecting robust semantic grounding and cross-modal alignment.
Ablation and Analysis
Ablation studies confirm the necessity of each core component:
- Removing pre-training or omitting the sign encoder/SGT decoder leads to severe performance degradation.
- The cluster aggregator and local cluster-wise contrastive learning are critical for effective alignment, with row-wise max and softmax-based scoring yielding the best results.
- Unfreezing the text encoder during pre-training provides consistent, albeit modest, improvements.
Sigma’s reliance on skeletal data confers significant advantages in storage, computational efficiency, and privacy compared to RGB-based approaches, with negligible loss in recognition or translation quality.
Implications and Future Directions
Sigma demonstrates that semantically informed pre-training, hierarchical alignment, and unified cross-modal modeling can overcome longstanding challenges in skeleton-based SLU. The framework’s ability to generalize across languages, tasks, and datasets without reliance on costly gloss annotations is particularly notable. This has direct implications for scalable, privacy-preserving, and annotation-efficient SLU systems deployable in real-world assistive technologies.
Theoretically, Sigma’s approach to cluster-wise alignment and early cross-modal fusion may inform future work in other multimodal domains where fine-grained and global semantic integration is required. Practically, the modularity of the framework allows for extension to additional modalities (e.g., RGB, depth) or adaptation to low-resource sign languages.
Conclusion
Sigma establishes a new standard for skeleton-based sign language understanding by integrating sign-aware early fusion, hierarchical alignment learning, and unified pre-training objectives. The model achieves robust, transferable, and semantically grounded representations, enabling SOTA performance across ISLR, CSLR, and gloss-free SLT. The results validate the importance of semantically informative pre-training and provide a scalable path forward for multimodal language understanding systems.