- The paper establishes a Fano-style upper bound on the accuracy of single-pass LLM reasoning, revealing a sharp 'Accuracy Cliff' when the information demand exceeds output capacity.
- The methodology introduces InfoQA, a capacity-aware multi-call framework that decomposes complex queries into manageable sub-steps to maintain high per-step accuracy.
- The findings have significant implications for designing robust LLM systems, enabling improved handling of multi-hop tasks through adaptive reasoning decomposition.
Introduction
This paper presents a rigorous information-theoretic analysis of the limitations of single-pass LLMs in multi-hop question answering (MHQA). The authors derive a Fano-style upper bound on achievable accuracy, demonstrating that as the information demand of a task exceeds the model's output capacity, performance collapses abruptly—a phenomenon termed the "Accuracy Cliff." The work further introduces InfoQA, a multi-call reasoning framework designed to circumvent these bottlenecks by decomposing complex queries into capacity-aligned sub-steps, maintaining high per-step accuracy and robust reasoning chains. Empirical results on a synthetic, noise-rich MHQA benchmark validate both the theoretical predictions and the practical efficacy of InfoQA.
Theoretical Framework: Fano-Style Accuracy Bound
The core contribution is the derivation of a Fano-style upper bound on the accuracy of single-pass LLMs in MHQA. The analysis formalizes the intuition that LLMs, constrained by finite output entropy, cannot reliably integrate dispersed, interdependent evidence when the information demand of the task exceeds their output capacity.
Let A denote the ground-truth answer, Q the user query, C the context (composed of evidence E and noise N), and Y the model's output. The information demand is defined as β=H(A∣Q,C), and the model's output capacity as C=H(Y). The main theorem establishes:
h(Acc)+(1−Acc)log(∣A∣−1)≥β−C
where h(⋅) is the binary entropy function, and Acc is the maximum achievable accuracy. This result implies that perfect accuracy is unattainable whenever β>C.
The bound admits a particularly transparent form in the uniform answer distribution regime:
Acc≤min{1,βC+1}
This relationship predicts a sharp phase transition: as β crosses C+1, accuracy collapses hyperbolically—the "Accuracy Cliff."
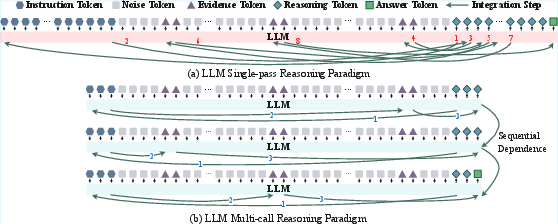
Figure 1: Comparison of single-pass and multi-call reasoning paradigms. Single-pass reasoning is constrained by the limited output capacity of LLMs, making it difficult to solve long-context and multi-hop problems. Multi-call reasoning mitigates this by decomposing tasks into sequentially dependent sub-steps, ensuring high per-step accuracy and a reliable reasoning chain.
Anatomy of the Multi-Hop Challenge
The paper dissects MHQA to identify two compounding challenges that exacerbate the single-pass bottleneck:
- Stepwise Capacity Overflow: The information demand β grows super-linearly with both the number of reasoning hops (h) and the effective context length (L), modeled as β(h,L)=β0+αLγh−1 with γ>1. This exponential growth rapidly pushes tasks beyond the model's capacity.
- Cross-Step Error Accumulation: Even with high per-step accuracy, the sequential nature of multi-hop reasoning amplifies small errors multiplicatively across steps. The overall success probability decays as (1−ε)K+1 for K hops and per-step error ε, leading to catastrophic failure as K increases.
These findings formalize why single-pass LLMs are fundamentally inadequate for complex MHQA tasks.
InfoQA: Capacity-Aware Multi-Call Reasoning
To address the identified limitations, the authors propose InfoQA, a multi-call reasoning framework that decomposes complex queries into a sequence of capacity-aligned sub-questions, each solvable within the model's per-pass information budget.

Figure 2: The InfoQA framework integrates three key components: (1) Capacity-Aware Task Decomposition, which reduces the information demand by generating single-hop sub-questions; (2) Dependency-Explicit Workflow, where the evolving contracted query carries the reasoning state across steps; and (3) Iterative Query Contraction, which prunes reasoning traces and rewrites the query with Z^k. Each LLM call approximates ϕk and produces Z^k.
Key Components:
- Capacity-Aware Task Decomposition: The initial multi-hop query is decomposed into single-hop sub-questions, each with reduced information demand, ensuring per-step accuracy remains high.
- Dependency-Explicit Workflow: The evolving query state is explicitly maintained and updated at each step, embedding intermediate findings to ensure alignment and prevent semantic drift.
- Iterative Query Contraction: After each step, the reasoning trace is pruned and the query is rewritten with the latest finding, preventing context inflation and keeping the information load manageable.
This design directly mitigates both the capacity and compounding crises identified in the theoretical analysis.
Empirical Validation
The authors construct a synthetic MHQA benchmark with fine-grained control over hop count and context length, embedding gold evidence among semantically similar distractors and irrelevant noise. This setup enables precise modulation of information demand and rigorous testing of theoretical predictions.
Single-Pass Baseline Results:
Empirical F1 scores for strong single-pass baselines (Direct, Chain-of-Thought, Self-Consistency, etc.) closely follow the predicted accuracy cliff as a function of effective information demand β. As β increases with hop count and context length, performance collapses sharply once the capacity threshold is crossed.
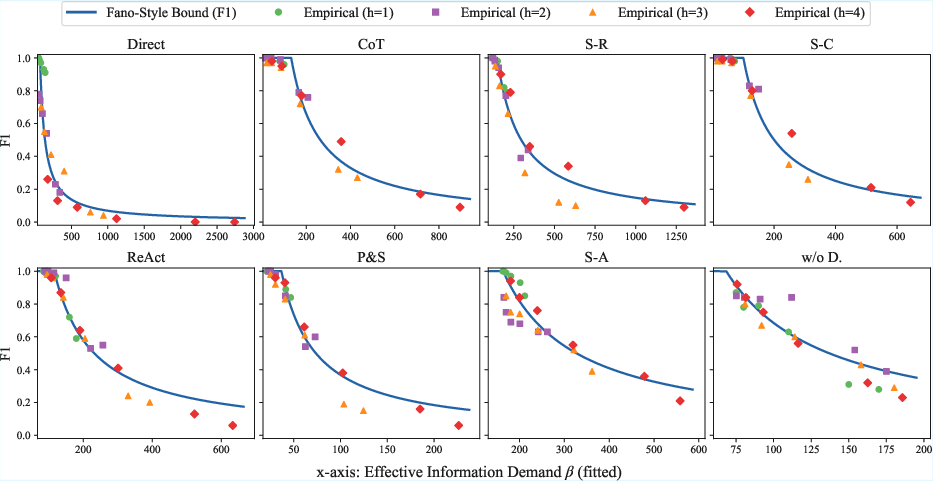
Figure 3: Qwen3-14B F1 vs.\ theoretical curves across single-pass methods. The x-axis shows the estimated effective information demand (β), fitted per method, and the y-axis shows the F1 score.
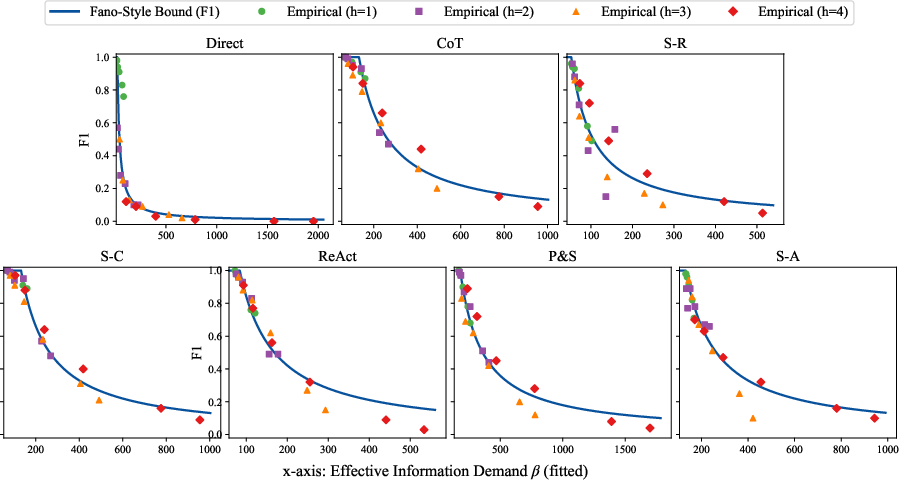
Figure 4: Qwen3-8B's Empirical F1 vs.\ theoretical curves across single-pass methods. The x-axis shows the estimated effective information demand (β), fitted per method, and the y-axis shows the F1 score.
InfoQA Performance:
InfoQA consistently outperforms all single-pass baselines, especially as hop count and context length increase. On 2–4 hop tasks, InfoQA achieves an overall average F1 of 0.86 (Qwen3-14B), compared to 0.75 for Self-Consistency and 0.73 for Chain-of-Thought. InfoQA maintains high accuracy even in long-context, high-hop regimes where single-pass methods collapse.
Ablation studies confirm that both capacity-aware decomposition and iterative pruning are indispensable: removing either component leads to substantial performance degradation, validating the necessity of InfoQA's design.
Implications and Future Directions
The paper's information-theoretic analysis provides a principled explanation for the empirical fragility of single-pass LLM reasoning in MHQA. The derived accuracy bound and the observed accuracy cliff have broad implications for the design and evaluation of LLM-based reasoning systems:
- Capacity-Aware System Design: Any system requiring compositional reasoning over long or noisy contexts must explicitly manage per-step information demand, either via multi-call decomposition or architectural innovations that increase output entropy.
- Benchmarking and Evaluation: The synthetic benchmark and fitting methodology offer a template for evaluating LLMs under controlled information demand, enabling precise diagnosis of capacity bottlenecks.
- Theoretical Extensions: Extending the analysis to multi-call and agentic workflows could clarify how information accumulates across calls and what new limits emerge.
- Adaptive Decomposition: Future systems may benefit from dynamic, context-sensitive decomposition strategies that optimize the trade-off between step granularity and reasoning chain length.
- Domain-Specific Applications: Applying the capacity-bound perspective to domains such as scientific literature analysis or legal reasoning will test its robustness under real-world noise and complexity.
Conclusion
This work establishes a rigorous information-theoretic foundation for understanding the limitations of single-pass LLM reasoning in multi-hop QA. The Fano-style accuracy bound and the empirical observation of the accuracy cliff provide a unified explanation for the failure modes of existing prompting strategies. The InfoQA framework demonstrates that capacity-aware, multi-call reasoning can robustly overcome these limitations, achieving substantial gains in both depth and length robustness. These insights are expected to inform the next generation of LLM-based reasoning systems and inspire further research into principled, capacity-aware architectures and workflows.