- The paper introduces Atoms Theory, a novel framework redefining LLM components by demonstrating over 99.8% uniqueness in atom reconstruction compared to traditional neurons and features.
- It leverages the Atomic Inner Product to correct representation shifting, ensuring internal representation angles align close to 90° for accurate geometric interpretation.
- Experimental validation using sparse autoencoders on models like Gemma2 and Llama3.1 confirmed 99.9% sparse reconstruction, underscoring the robustness of the proposed atoms.
Towards Atoms of LLMs
Introduction to Atoms Theory
The paper "Towards Atoms of LLMs" proposes a novel theoretical framework, the Atoms Theory, which aims to redefine the fundamental units of LLMs. Traditional views considered neurons or features as the basic units, but these suffer from polysemy and instability, respectively. Atoms Theory introduces the concept of 'atoms' and defines these as the essential components that better encapsulate the internal representations within LLMs, providing improved interpretability and reconstruction capabilities.
Atomic Inner Product and Representation Shifting
A critical advancement in the paper is the introduction of the Atomic Inner Product (AIP), designed to correct representation shifting observed when using the Euclidean inner product. Representation shifting refers to the deviation of angle distributions between representations from 90∘ due to the inherent properties of the softmax function in LLMs.

Figure 1: Representation shifting caused by adopting the Euclidean inner product, where the centroid of angles distribution between representations deviates substantially from 90∘.
The AIP centers the angle distributions close to 90∘, providing a more accurate depiction of the geometric relationships between internal representations.

Figure 2: Correcting representation shifting by identifying and adopting the atomic inner product, where the centroid of angle distribution between representations approaches 90∘.
Validation of Atoms Theory
The paper validates the Atoms Theory through comprehensive experiments using sparse autoencoders (SAEs) equipped with threshold activations. These are trained on models such as Gemma2-2B, Gemma2-9B, and Llama3.1-8B, achieving 99.9% sparse reconstruction across layers. Unlike neurons and traditional features, more than 99.8% of the atoms meet the uniqueness conditions required for stable and interpretable representation. This contrasts sharply with neurons (0.5%) and features (68.2%).
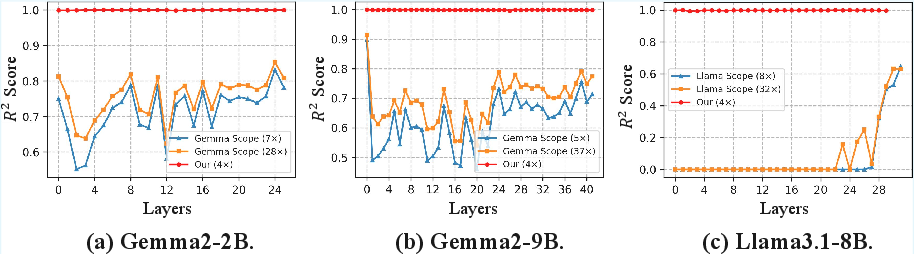
Figure 3: Sparse reconstruction R2 scores across models. GemmaScope and LlamaScope serve as standard tools for extracting features from representations.
Comparison with Neurons and Features
The Atoms Theory fundamentally challenges existing paradigms by demonstrating that atoms provide superior reconstructive fidelity and stability compared to neurons and features. Through systematic evaluation, atoms are shown to fulfill conditions for uniqueness and recoverability, supporting their role as more robust fundamental units.
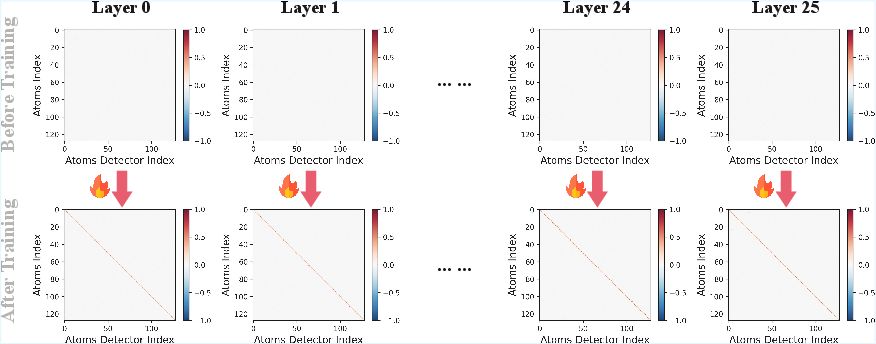
Figure 4: Spontaneous alignment between the encoder and decoder during training on Gemma2-2B.
Impacts and Future Directions
The theoretical underpinnings of Atoms Theory align closely with the principles of compressed sensing and provide rigorous guarantees such as the Restricted Isometry Property (RIP). This establishes a foundation for mechanistic interpretability of LLMs, significantly contributing to both theoretical and practical understanding. Future work will focus on refining computational methods for atom identification and exploring broader applications within AI interpretability frameworks.
Conclusion
"Towards Atoms of LLMs" presents a robust framework that effectively transcends limitations of traditional neuron and feature paradigms, offering a comprehensive approach to interpreting and reconstructing LLM representations. As the field progresses, the Atoms Theory may reshape our understanding of the fundamental structures underlying LLMs, highlighting the intricate balance between theoretical innovation and practical application.