- The paper establishes necessary and sufficient conditions for SAEs to uniquely recover ground truth monosemantic features from polysemantic inputs.
- It introduces an adaptive reweighting strategy in the SAE loss function to prioritize accurate reconstruction when ideal sparsity conditions are not met.
- Empirical results across synthetic and real-world data validate the framework, demonstrating improved interpretability in language and vision applications.
On the Theoretical Understanding of Identifiable Sparse Autoencoders and Beyond
Introduction
The paper "On the Theoretical Understanding of Identifiable Sparse Autoencoders and Beyond" addresses the critical issue of feature polysemanticity in neural networks, especially within the context of LLMs. Sparse autoencoders (SAEs) are proposed to interpret features and recover interpretable, monosemantic features from superposed polysemantic ones. The primary goal of this study is to establish the conditions under which SAEs can fully recover ground truth monosemantic features. This involves a focus on the identifiability of SAEs and a novel reweighting strategy to enhance feature recovery.
The paper begins with a mathematical model for feature superposition and sparse autoencoders (SAEs). The superposed polysemantic features xp are created from ground truth monosemantic features x and are reconstructed using an SAE.
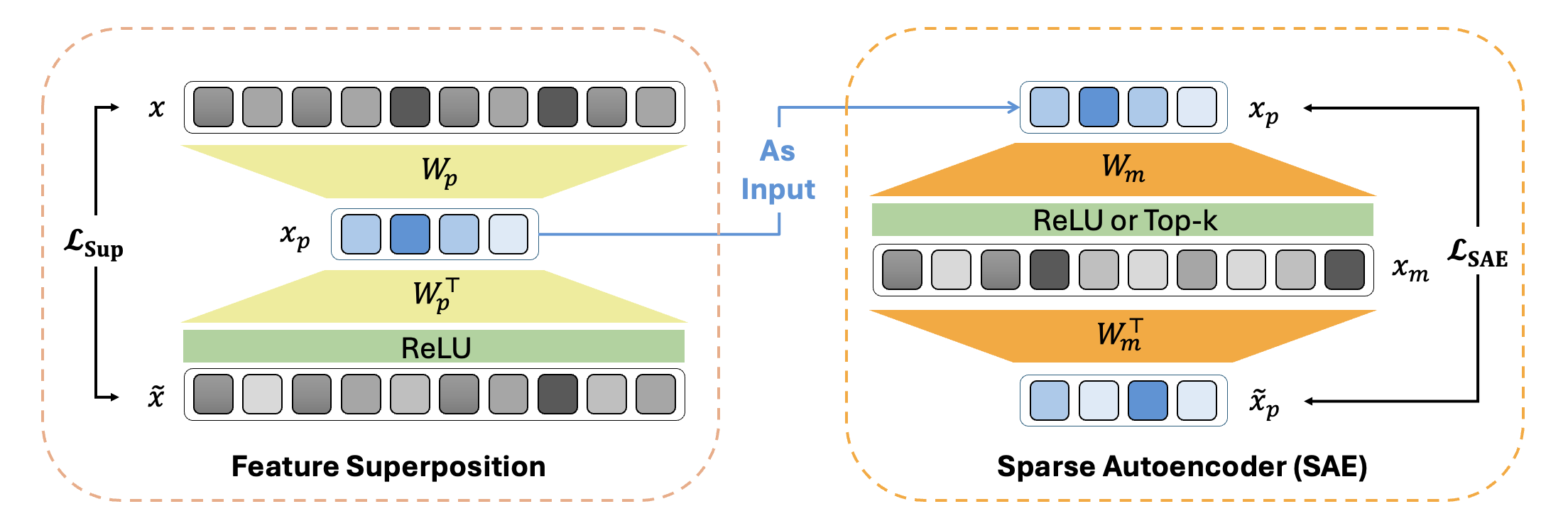
Figure 1: Mathematical modeling of feature superposition and sparse autoencoder (SAE).
Through rigorous theoretical analysis, the paper provides necessary and sufficient conditions for identifiable SAEs, which include:
- Extreme Sparsity: The ground truth features must exhibit high sparsity.
- Sparse Activation: The SAE should incorporate a sparse activation function like ReLU or Top-k.
- Adequate Hidden Dimensions: Sufficient hidden dimensions in the SAE are required for full recovery of input features.
The paper proves theoretically that under these conditions, SAEs can uniquely recover the ground truth monosemantic features.
Adaptive Reweighting Strategy
The authors extend the identifiability framework by introducing a reweighting strategy to improve feature recovery when the ideal conditions are not met. This approach modifies the loss function of SAEs to prioritize the reconstruction of monosemantic features over polysemantic ones.
The reweighting involves an adaptive weight matrix that assigns smaller weights to dimensions with greater polysemanticity, thereby narrowing the gap between SAE reconstruction loss and the desired ground truth reconstruction. This strategic weighting ensures that features with high polysemantic levels contribute less to the reconstruction loss, enhancing the interpretable feature extraction ability of SAEs.
Empirical Validation
The theory is validated through experiments with synthetic data and real-world applications in both language and vision domains. The experiments on toy models demonstrate the impact of input sparsity, activation functions, and hidden dimensions on the monosemanticity of SAE outputs.
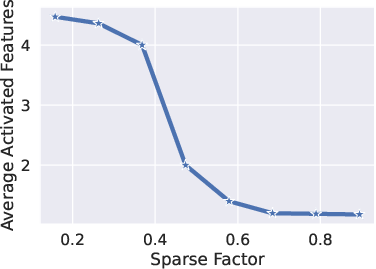
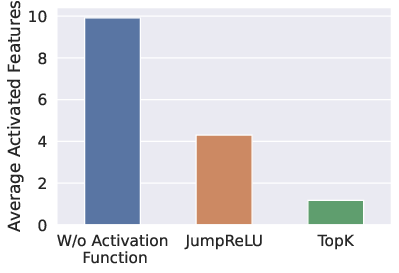
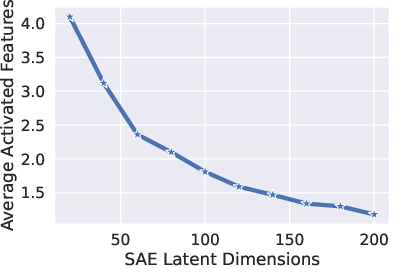
Figure 2: The empirical verifications of the necessary conditions for SAE recovery of monosemantic features on the toy model.
Furthermore, real-world experiments utilizing Pythia-160M LLM demonstrate significant gains in auto-interpretability scores when applying the reweighted SAE loss, confirming the paper's theoretical predictions.
Conclusion
The paper presents a comprehensive theoretical framework for understanding and improving the identifiability of sparse autoencoders. It establishes clear conditions essential for accurate feature recovery and proposes a practical reweighting strategy to handle non-ideal scenarios. The findings are substantiated by empirical evidence, suggesting substantial improvements in the interpretability and usefulness of features extracted by SAEs. Potential future work could include exploring the application of these techniques in diverse AI domains, such as detecting and mitigating harmful features in LLMs.

