EmbeddingGemma: Powerful and Lightweight Text Representations
Abstract: We introduce EmbeddingGemma, a new lightweight, open text embedding model based on the Gemma 3 LLM family. Our innovative training recipe strategically captures knowledge from larger models via encoder-decoder initialization and geometric embedding distillation. We improve model robustness and expressiveness with a spread-out regularizer, and ensure generalizability by merging checkpoints from varied, optimized mixtures. Evaluated on the Massive Text Embedding Benchmark (MTEB) across multilingual, English, and code domains, EmbeddingGemma (300M) achieves state-of-the-art results. Notably, it outperforms prior top models, both proprietary and open, with fewer than 500M parameters, and provides performance comparable to models double its size, offering an exceptional performance-to-cost ratio. Remarkably, this lead persists when quantizing model weights or truncating embedding outputs. This makes EmbeddingGemma particularly well-suited for low-latency and high-throughput use cases such as on-device applications. We provide ablation studies exploring our key design choices. We release EmbeddingGemma to the community to promote further research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces EmbeddingGemma, a small but powerful AI model that turns text into numbers (called “embeddings”) so computers can understand meaning. Even though the model is lightweight (about 308 million parameters), it performs as well as or better than many bigger models on a huge set of tests, across many languages and even code. It’s designed to be fast, cheap to run, and good for use on devices like phones.
Goals
The authors set out to:
- Build a compact text embedding model that works great across many tasks and languages.
- Keep the model fast and low-cost so it can run with low delay and high throughput (lots of requests quickly).
- Show that smart training tricks can make small models compete with much larger ones.
How they built it (Methods)
What is a “text embedding”?
Think of each sentence as a dot on a giant map. If two sentences mean similar things, their dots sit close together. A text embedding model places text on that map by turning words into a fixed-length list of numbers. That lets apps quickly find related texts, cluster topics, or search for the right answer.
Starting from a strong base
The team begins with Gemma 3, a strong LLM. They reshape it into an “encoder–decoder” style and then take the “encoder” part to build EmbeddingGemma.
- Encoder: Focuses on understanding input (like reading and summarizing).
- Decoder: Focuses on generating output (like writing).
- Why encoder–decoder? The encoder learns to look both forward and backward in a sentence (bidirectional attention), which helps it make richer, more context-aware representations. It’s like reading a paragraph multiple ways to fully grasp it.
Learning from a teacher (distillation)
They use a bigger, highly capable “teacher” model (Gemini Embedding). EmbeddingGemma learns by matching the teacher’s embeddings—like a student copying how the teacher organizes ideas on the map. This “embedding matching” teaches the small model the teacher’s sense of meaning and closeness between texts, including hard cases.
- Hard negatives: Tricky wrong answers that look similar to the right one (e.g., two articles about similar topics). Training with these helps the model learn fine distinctions.
Keeping embeddings “spread out” (regularizer)
Imagine all dots on the map clumping in one corner—then it’s hard to tell them apart. A “spread-out” regularizer nudges embeddings to occupy the space more evenly. This:
- Makes the model more expressive (it can represent more varied ideas).
- Helps with compression and speed (better for running on-device or in databases).
Training in two phases
- Pre-finetuning: Train on massive, noisy, diverse data (many languages and tasks) without hard negatives, using big batches. This builds general skill and stability.
- Finetuning: Train on cleaner, task-specific data with hard negatives. They add short “task prompts” (like labels) so the model knows whether it’s doing search, similarity, code retrieval, etc. They explore different combinations (mixtures) of tasks to balance strengths.
Mixing models like soups (“model souping”)
Instead of picking one best finetuned model, they average the weights of several that were trained on different task mixtures. Think of blending several smoothies, each with a different flavor, into one tasty mix. This often improves overall performance and robustness because different models specialize in different areas.
Making it run on small devices (quantization)
They also train versions that store numbers with fewer bits (like compressing a photo to lower resolution), such as 8-bit and 4-bit weights. They use “quantization-aware training” so quality stays high even after compression. The model also supports shorter embeddings (like 512, 256, or 128 numbers) and still works well.
Main findings
- Strong performance for its size: EmbeddingGemma (≈308M parameters) reaches state-of-the-art results among models under 500M parameters on big benchmarks like MTEB (which tests many languages and tasks), including:
- Multilingual text tasks (over 250 languages)
- English tasks
- Code search tasks
- Competitive with larger models: It performs similarly to models almost twice its size.
- Robust when compressed:
- Still very strong even if embeddings are only 128 numbers long.
- Keeps high quality with 4-bit or 8-bit weights (good for speed and memory).
- Key design choices matter:
- Initializing from an encoder–decoder beats starting from a decoder-only model.
- Simple “mean pooling” (averaging token representations) works better than more complicated attention pooling for embeddings.
- Model souping (averaging models from different training mixtures) improves results across task types.
Why is this important? These results show you don’t need massive, expensive models to get top-tier embeddings. With a smart training recipe, a small model can deliver excellent accuracy, speed, and flexibility.
Implications
EmbeddingGemma is a strong fit for:
- On-device apps (privacy, offline use) where speed and memory matter.
- High-traffic systems (search, recommendation) that need low latency and high throughput.
- Multilingual and cross-domain use (natural languages and code).
By open-sourcing a compact model with state-of-the-art performance, the authors help the community build faster, cheaper, and more accessible AI tools—potentially powering better search engines, chat assistants, knowledge bases, and coding helpers without heavy cloud costs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and missing details that constrain reproducibility, deployment, and scientific understanding of EmbeddingGemma. Each point is framed to be concrete and actionable for future research.
- Training data transparency and contamination
- The pre-finetuning corpus (“billions of title–body pairs crawled from websites”) lacks disclosure of sources, crawl dates, filtering, deduplication, language distribution, licensing, and toxicity/PII handling, limiting reproducibility and bias assessment.
- No analysis of potential data contamination with MTEB/XOR/XTREME-UP tasks; the paper excludes other models trained on >25% MTEB but does not quantify contamination in EmbeddingGemma’s own mixtures.
- Code-domain datasets are not enumerated; language coverage (e.g., Python vs. Java vs. SQL) and supervision quality/noise are unspecified.
- Reproducibility and release gaps
- The encoder–decoder checkpoint used for initialization (UL2-pretrained T5Gemma-style) is not released; exact pretraining hyperparameters (optimizer, learning rate schedule, steps, batch size, dropout, masking mixes, vocabulary) are missing.
- Finetuning/pre-finetuning mixtures (dataset list, sampling rates, example counts, per-task batch sizes, number of steps, LR schedules, seed control) are not detailed or packaged for replication.
- Hard-negative mining pipeline is unspecified (teacher- or BM25-based, mining depth, refresh frequency, overlap control, language-specific strategies), preventing reimplementation.
- Teacher dependence and distillation specifics
- Embedding matching is anchored to Gemini Embedding, but the paper does not provide a reproducible path for users without access to that proprietary teacher (e.g., alternative open teachers or teacher ensembles).
- No ablation of distillation loss components or weighting (queries vs. positives vs. hard negatives), nor analysis of sensitivity to teacher–student dimensional mismatches.
- The rationale for two randomly initialized linear projections (g: 768→3072, f: 3072→768) in the embedding head is not justified or ablated (e.g., single projection vs. identity mapping vs. learned teacher alignment).
- Regularization and ANN retrieval claims
- The spread-out regularizer is reduced to a “second-moment” term without comparing against the full GOR objective or other sphere-packing/orthogonality methods; the paper lacks empirical evidence linking regularizer choices to ANN index recall/latency at scale.
- No measurements of vector database behavior (HNSW/IVF/ScaNN) for large corpora (10M–1B items), index build times, memory, and retrieval latency/recall with various embedding dimensions and quantization levels.
- Pooling and representation aggregation
- The pooling comparison covers mean/first/last/attention pooling only; stronger learned pooling/aggregation strategies (e.g., gated pooling, CLS-style learned token with pretraining, multi-layer pooling, learned positional reweighting, GeM) remain unexplored.
- No analysis of task- or language-dependent pooling preferences (e.g., whether certain domains benefit from attention pooling or multi-layer fusion).
- Matryoshka Representation Learning (MRL) configuration
- The paper does not report the choice of k (number of overlapping subspaces), overlap schedule, or truncation strategy beyond offering 768/512/256/128d; no ablation on how MRL settings trade off quality vs. flexibility.
- Automatic dimension selection (per task, latency target, or index constraints) is not studied; guidelines for choosing embedding dimensionality are omitted.
- Quantization scope and hardware outcomes
- Quantization-aware training (QAT) focuses on weights (int4/int8/mixed per-channel vs. per-block), but activation quantization, calibration, and inference-time stability are not evaluated.
- “Per-block” quantization is not defined (block size, grouping policy); per-layer sensitivity and failure modes are not reported.
- No real hardware benchmarks (latency, throughput, energy) on edge/mobile CPUs/NPUs/GPUs; memory footprint for quantized checkpoints, end-to-end retrieval latency, and accuracy–performance trade-offs are missing.
- On-device deployment claims without benchmarks
- Despite positioning for on-device use, the paper provides no measurements on representative devices (Android/iOS SoCs, laptop CPUs), nor evaluations under memory constraints, thermal throttling, or offline vector DB scenarios.
- Long-context behavior and truncation limits
- Context lengths >512 are mentioned only for specific tasks (e.g., passkey retrieval); there is no systematic study of performance vs. sequence length (1k–4k–8k), nor robustness to long noisy inputs or extreme code files.
- MRL truncation is evaluated down to 128d, but the behavior below 128d (e.g., 64d/32d) and under extreme compression (PQ/SQ) is unreported.
- Prompt sensitivity and multilingual prompt design
- The paper uses task strings (prompts) but does not quantify sensitivity to prompt phrasing, language localization (prompt in user language vs. English), or domain-specific templates.
- No guidelines for adapting or auto-selecting prompts across languages and task types; no ablation on prompt translation quality impacts.
- Hard-negative weighting and NCE details
- The hardness weight α is fixed at 5.0 without sensitivity analysis; alternative weighting functions (e.g., margin-based, temperature scheduling), negative sampling strategies, and refresh cadence are not explored.
- Duplicate/false-negative masking criteria are simplistic (exact string equality); cross-lingual paraphrases, near-duplicates, and semantic duplicates are not addressed.
- Model souping methodology and theory
- Checkpoint selection (which steps per run, number of runs, stability across seeds) and potential weighted averaging or SWA are not examined; unweighted parameter averaging may not be optimal.
- No theoretical or empirical analysis of why mixtures obtained via Bayesian optimization complement each other; no diagnostics of specialization (e.g., per-task Fisher information or gradient diversity).
- Bias, fairness, and safety
- No audit of demographic, cultural, or gender bias in embeddings; no analysis of low-resource vs. high-resource language disparities, nor mitigation strategies.
- Security/privacy risks (e.g., inversion attacks on embeddings, leakage of sensitive information, memorization from web crawl) are not considered; no robustness to adversarial or toxic inputs.
- Tokenization and multilingual/code coverage
- Tokenizer/vocabulary details (size, script coverage, normalization, code tokenization strategy) are not provided; handling of code-specific tokens and multilingual scripts (e.g., Indic, RTL, CJK) is unspecified.
- No breakdown of code-task performance by language or paradigm; the model’s ability to generalize across code ecosystems (Python/Java/C++/SQL) is unquantified.
- Evaluation metric clarity and statistical rigor
- Several instruction-retrieval scores in tables are negative without explanation of the metric or its scale; metric definitions and units for each task type are unclear.
- No confidence intervals, statistical significance tests, or multiple-run variance; stability across seeds/checkpoints is not reported.
- Environmental and compute footprint
- Compute resources, training time, hardware configuration, and energy/CO2 estimates for UL2 pretraining, pre-finetuning (314B tokens), and finetuning (20B tokens) are missing.
- Alternative pretraining and initialization pathways
- Encoder–decoder UL2 adaptation is shown beneficial, but comparisons against masked language modeling or contrastive pretraining from scratch, or against other encoder-initialization recipes, are absent.
- Real-world retrieval pipelines at scale
- End-to-end evaluations on large corpora (≥100M documents) with online indexing, query latency SLAs, and memory constraints are missing; integration guidance for production vector DBs is not provided.
- Guidelines for dimension and index selection
- Practical recommendations for choosing embedding dimensionality vs. index type (HNSW vs. IVF vs. graph-based) and quantization levels under specific latency/recall targets are not offered.
- Release completeness and licensing
- It is unclear which artifacts (training scripts, data recipes, UL2 encoder–decoder checkpoint, mining tools) are released, and under what license; lack of clear licensing for web-crawled data impedes adoption.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage EmbeddingGemma’s current capabilities, highlighting sectors, tools/workflows, and feasibility notes.
- Multilingual enterprise search and retrieval (Sector: software; finance; healthcare)
- What: Low‑latency, cross‑lingual semantic search across wikis, tickets, documents, and emails; privacy‑preserving on-device or on‑prem RAG.
- How: Embed corpora with 256d/128d MRL settings; store in FAISS/ScaNN/Milvus/Qdrant/Pinecone; use task prompts for “search result | query”.
- Why EmbeddingGemma: Strong MTEB(Multilingual) and retrieval scores; robust to 4/8‑bit quantization; spread‑out regularizer improves ANN recall.
- Assumptions/Dependencies: Correct prompt templates; domain‑specific chunking; vector DB integration; device memory (quantized checkpoints recommended).
- Customer support routing and FAQ assistants (Sector: telecom; e‑commerce; public services)
- What: Auto‑route tickets, retrieve relevant answers, and suggest resolutions across 250+ languages.
- How: Pair classification + instruction retrieval pipelines; embed queries and FAQs; rerank candidates.
- Why EmbeddingGemma: Leading instruction retrieval, pair classification, and reranking performance under 500M params.
- Assumptions: Clean FAQ corpora; multilingual UI; latency budgets met via int4/int8 weights and smaller dims.
- On-device personal search for notes, emails, and documents (Sector: daily life productivity)
- What: Private, offline search on laptops/phones; semantic clustering of notes; deduplication.
- How: Quantized int4 per‑block; 128d embeddings; mean pooling; local vector DB (SQLite + ANN or lightweight in‑memory index).
- Why EmbeddingGemma: Small footprint, strong STS/clustering; minimal quality loss under quantization.
- Assumptions: Sufficient device RAM/CPU/GPU; OS access for background indexing.
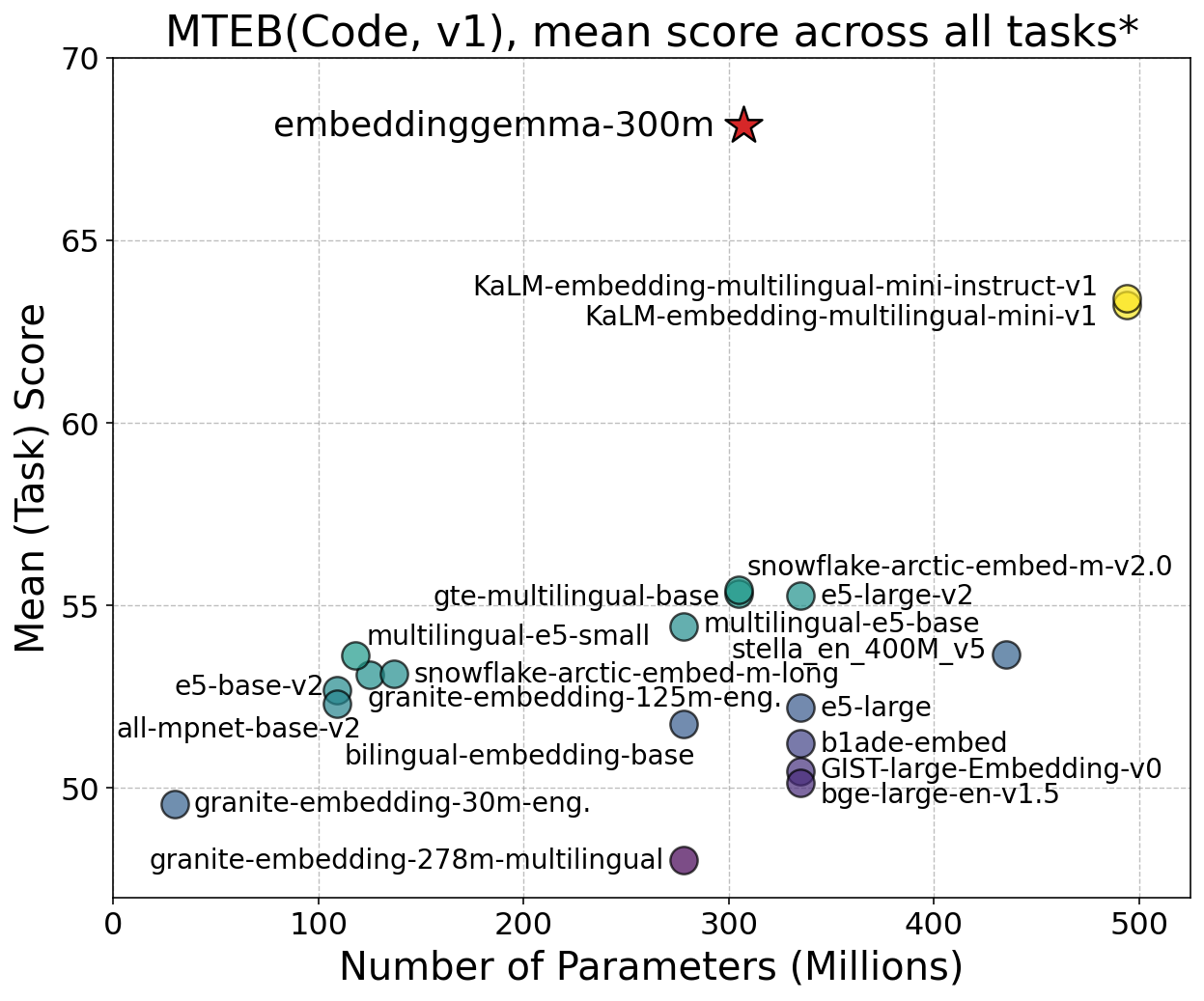
- Code search in IDEs and repos (Sector: software)
- What: Natural language → code snippet retrieval; cross‑repo query; “how‑to” snippet discovery.
- How: Index code with 256d embeddings; integrate with VS Code/JetBrains; rerank top‑k with simple heuristics.
- Why EmbeddingGemma: Top MTEB(Code) performance, large gains on AppsRetrieval and CosQA.
- Assumptions: Efficient repository chunking; language‑aware tokenization; CI/CD indexing pipeline.
- Compliance and risk monitoring (Sector: finance; healthcare; legal)
- What: Semantic monitoring of communications for policy breaches; retrieval of precedent cases and regulations.
- How: Pair classification + retrieval + reranking; multilingual coverage for global teams.
- Why EmbeddingGemma: Strong classification/reranking across languages; high throughput for large streams.
- Assumptions: Governance and audit trails; tuned thresholds; legal review.
- Contract and policy document search (Sector: legal; HR; procurement)
- What: Find clauses, related agreements, and precedents; cluster similar documents.
- How: 256d embeddings; domain prompts; ANN index with spread‑out regularizer benefits.
- Why: Strong STS/clustering; robust ANN behavior; low latency for large archives.
- Assumptions: Domain‑specific pre‑finetuning improves accuracy; careful chunking and citation handling.
- Multilingual bitext mining for MT dataset construction (Sector: language tech; academia)
- What: Identify parallel sentence pairs to bootstrap/augment translation corpora.
- How: Bitext mining tasks with thresholding; post‑filtering heuristics; script normalization.
- Why: Competitive bitext mining scores; wide language coverage via Gemma‑derived knowledge.
- Assumptions: Post‑processing required to reduce noise; language‑pair balancing.
- App review and social feedback analysis (Sector: software; media)
- What: Cluster and summarize user feedback; surface top issues across languages.
- How: Clustering + summarization task prompts; 128d embeddings for scale.
- Why: Strong clustering and summarization in MTEB(Eng); multilingual generalization.
- Assumptions: Summarization quality depends on prompt discipline; deduplication pipeline.
- Knowledge graph entity resolution and record linkage (Sector: data engineering)
- What: Link entities across systems; resolve duplicates semantically.
- How: Pair classification + STS thresholds; vector joins with ANN.
- Why: High pair classification performance; matryoshka dims reduce memory overhead.
- Assumptions: Domain calibration of thresholds; outlier handling.
- Academic literature retrieval and similarity (Sector: academia)
- What: Cross‑domain paper search; related‑work discovery; citation clustering.
- How: Index titles/abstracts/full texts; task prompts for query/passages; rerank top‑k.
- Why: Strong multilingual retrieval and STS; low cost relative to larger models.
- Assumptions: Access to full‑text; proper chunking; field‑specific tuning.
- Multilingual citizen service search portals (Sector: government/policy)
- What: Unified search over forms, benefits, FAQs for underrepresented languages.
- How: Use 256d/128d embeddings; kiosks/offline endpoints with int8 weights.
- Why: Good XTREME‑UP and XOR‑Retrieve performance; low‑latency public deployments.
- Assumptions: Accessibility requirements; content freshness workflows.
- RAG pipeline optimization via matryoshka dimensions (Sector: ML platforms)
- What: Tiered retrieval: use 128d for broad recall, 768d for precise rerank.
- How: MRL sub‑dimension compatibility; two‑stage ANN retrieval.
- Why: Built‑in MRL enables dimension‑aware trade-offs; throughput and cost reduction.
- Assumptions: Vector DB supports multi‑index tiers; orchestration in LangChain/LlamaIndex/Haystack.
- Embedding distillation to domain specialists (Sector: any, with teacher models)
- What: Create small, domain‑specific embeddings by matching a large teacher’s space.
- How: Embedding matching on queries/positives/hard negatives; hard‑negative weighting.
- Why: Recipe in paper is turnkey for orgs with internal teachers; improves small-model quality.
- Assumptions: Access to high‑quality teacher embeddings; curated domain data; compute for finetuning.
Long-Term Applications
These applications are feasible but may require additional research, scaling, integration work, or ecosystem support.
- Privacy‑first, fully offline personal assistants (Sector: consumer; healthcare)
- What: End‑to‑end on‑device retrieval and reasoning over personal data (notes, messages, health logs) across languages.
- Why: Model’s small size and quantization‑robust training are promising; needs tight integration with local ASR/NLU and secure storage.
- Dependencies: Hardware acceleration (mobile NPUs), efficient indexing, secure enclaves, energy constraints.
- Federated fine‑tuning of domain embeddings (Sector: healthcare; finance; industrial)
- What: Train specialized embeddings across institutions without centralizing sensitive data.
- Why: Encoder‑decoder initialization and embedding matching are compatible with federated paradigms.
- Dependencies: Federated orchestration, privacy guarantees, secure aggregation, regulatory buy‑in.
- Dimension‑adaptive retrieval engines (Sector: infrastructure; cloud)
- What: Retrieval systems that dynamically choose embedding dimensionality per query/document (cost‑quality trade‑off).
- Why: Matryoshka representation learning provides native sub‑dimensions; requires DB/runtime support.
- Dependencies: Vector DB APIs for adaptive dims, query classifiers, SLA‑aware routing.
- Automated “mixture‑of‑experts” souping for enterprise domains (Sector: ML platforms)
- What: Auto‑generate domain experts via Bayesian‑optimized mixtures and weight‑averaged soups.
- Why: Paper shows souping across mixtures yields robust generalization; can be productized as an “Embedder Studio.”
- Dependencies: Data curation pipelines, evaluation harnesses, guardrails, versioning.
- Language inclusion programs and public digital goods (Sector: policy; education)
- What: Deploy multilingual search in underrepresented languages for civic services and learning resources.
- Why: Strong cross‑lingual generalization and XTREME‑UP gains; needs content digitization and community validation.
- Dependencies: Localization efforts, community feedback loops, governance frameworks.
- Edge robotics instruction retrieval (Sector: robotics; manufacturing)
- What: Natural‑language to procedure retrieval on robots with limited compute, in multilingual environments.
- Why: Low‑latency embeddings + quantization are suitable; requires task grounding and safety layers.
- Dependencies: Real‑time constraints, task libraries, control integration, safety certification.
- Energy‑efficient data center retrieval at scale (Sector: energy; cloud)
- What: Reduce retrieval energy costs via smaller embeddings, quantized weights, spread‑out regularizer for ANN efficiency.
- Why: Demonstrated robustness to 4/8‑bit and lower dims with modest quality loss.
- Dependencies: Fleet‑wide quantization rollout, hardware support (vector instructions), monitoring for tail‑latency.
- Secure clinical/biomedical literature discovery (Sector: healthcare)
- What: On‑prem retrieval across protected corpora and EHR‑linked knowledge bases.
- Why: Performance‑to‑cost makes small models viable in hospital IT; privacy demands on‑prem.
- Dependencies: Domain adaptation, compliance with HIPAA/GDPR, auditability, clinical validation.
- Multi‑tenant, policy‑aware retrieval services (Sector: enterprise SaaS)
- What: Tenant‑segmented indexes with policy tagging, per‑tenant dims/quantization, and compliance controls.
- Why: MRL enables cost tiers per tenant; spread‑out regularizer aids predictable ANN behavior.
- Dependencies: SaaS platform features, policy engines, monitoring and billing.
- Research: standardizing pooling and regularization best practices (Sector: academia; frameworks)
- What: Codify mean pooling and spread‑out regularizers as defaults in embedding libraries.
- Why: Ablations show mean pooling outperforms attention pooling; GOR improves robustness.
- Dependencies: Broad replication, benchmark governance, framework updates (Transformers/JAX/TF/PyTorch).
- Cross‑modal extensions (text ↔ code ↔ structured data) (Sector: data platforms)
- What: Unified embeddings across text, code, tables/SQL for enterprise data search.
- Why: Strong code capabilities are a base; extending to structured modalities is natural but unproven in this work.
- Dependencies: Multi‑modal training data, evaluation suites, schema‑aware prompts, distillation strategies.
General Assumptions and Dependencies Across Applications
- Prompt discipline: Many gains rely on using the provided task prompts (query/passages), so pipelines must enforce templates.
- Chunking and context: Indexing workflows should respect context limits (typically 512 tokens; 1024–2048 for long inputs) and apply domain‑appropriate chunking.
- Quantization/hardware: On‑device viability hinges on int4/int8 support and memory budgets; quantized checkpoints minimize quality loss but require compatible runtimes.
- Vector DBs and ANN: Benefits of the spread‑out regularizer materialize when using ANN indexes tuned for cosine similarity; monitoring recall/latency trade‑offs is essential.
- Domain adaptation: While general‑purpose performance is high, specialist domains (clinical, legal, niche codebases) benefit from targeted finetuning or distillation.
- Governance and compliance: For regulated sectors, ensure auditability, data residency controls, and guardrails around retrieval outputs.
- Licensing and updates: Track model license terms, versioning, and ongoing benchmark updates; validate against in‑house datasets before production rollout.
Glossary
- Ablation studies: Systematic experiments that remove or vary components to measure their impact on performance. "We provide ablation studies exploring our key design choices."
- Approximate nearest neighbor (ANN): Algorithms that quickly find close vectors in high-dimensional spaces with approximate results. "the embeddings produced by the model can be retrieved efficiently in vector databases using approximate nearest neighbor (ANN) algorithms."
- Attention pooling: A pooling method that uses an attention mechanism to weight and aggregate token representations into a single vector. "In attention pooling, we utilize an attention mechanism to weigh and aggregate the token representations."
- Bayesian optimization: A strategy for optimizing hyperparameters or mixture weights by modeling the objective and selecting promising candidates. "we use the mixture resulting from this procedure as a seed for Bayesian optimization"
- Bidirectional attention: Attention that considers both left and right context when encoding sequences. "thanks to the encoder-decoder architecture's stronger contextual representations, which likely come from (i) the use of bidirectional attention"
- Bfloat16 (bf16): A 16-bit floating-point format that preserves exponent range of FP32 with fewer mantissa bits. "We run our evaluations with half-precision weights (bfloat16)"
- Borda count: An aggregate ranking method that assigns points based on positions across tasks to produce an overall rank. "Borda count, mean over all task scores, and mean over all task type scores."
- Cosine similarity: A similarity measure that computes the cosine of the angle between two vectors. "where is cosine similarity"
- Decoder-only model: A transformer architecture that uses only the decoder stack, typically with causal attention. "EmbeddingGemma is an encoder-only transformer model adapted from a pretrained 300M decoder-only Gemma 3 model."
- Dirichlet distribution: A probability distribution often used to sample probability vectors or mixture weights. "10 other random mixtures sampled from a Dirichlet distribution."
- Encoder-decoder initialization: Initializing a model (or its encoder) from a pretrained encoder-decoder checkpoint for better starting representations. "via encoder-decoder initialization and geometric embedding distillation."
- Encoder-decoder model: A transformer with separate encoder and decoder, enabling bidirectional encoding and conditional generation. "we adapt the Gemma 3 model into an encoder-decoder model"
- Encoder-only transformer: A transformer architecture that uses only the encoder stack with bidirectional attention. "EmbeddingGemma is an encoder-only transformer model"
- Embedding matching loss: A distillation loss that aligns student embeddings with a teacher model’s embeddings. "The third and final is an embedding matching loss based on \cite{kim2023embeddistillgeometricknowledgedistillation}."
- Geometric embedding distillation: A knowledge distillation approach that transfers the geometric structure of a teacher’s embedding space. "geometric embedding distillation."
- Global orthogonal regularizer (GOR): A regularizer encouraging embeddings to be spread out and near-orthogonal to improve expressiveness. "The second loss is based on the global orthogonal regularizer (GOR) introduced in \cite{spreadout}."
- Hard negative mining: Selecting challenging non-matching examples to improve discriminative training. "techniques such as synthetic data generation and hard negative mining"
- Hard negative passage: A non-relevant passage that is semantically close to the query, used to make training harder. "and (optionally) a hard negative passage . "
- Hardness weight: A weighting factor that emphasizes more difficult examples in the loss. "The hardness weight represents how challenging a (query, hard negative passage) pair is for the model to differentiate between"
- In-batch negatives: Using other examples within the same batch as negative samples for contrastive learning. "The first is a noise-contrastive estimation (NCE) loss with in-batch negatives."
- Instruction retrieval: A task type involving retrieving relevant instructions given a query. "10 task types: bitext mining, classification, clustering, instruction retrieval, multilabel classification, pair classification, reranking, retrieval, semantic text similarity, and summarization."
- Matryoshka Representation Learning (MRL): A technique that applies losses to overlapping sub-dimensions to support variable embedding sizes. "We adapt the contrastive and spread-out losses using MRL"
- Mean pooling: Aggregating token embeddings by averaging them across the sequence. "We then employ a mean pooling , which averages the token embeddings along the sequence axis"
- Model souping: Combining multiple trained checkpoints by parameter averaging to improve robustness and performance. "we utilize model souping \citep{souping} to combine multiple finetuned checkpoints"
- Multi-head attention: An attention mechanism with multiple parallel heads to capture diverse relationships. "We specifically employ multi-head attention with four attention heads."
- Noise-contrastive estimation (NCE) loss: A contrastive loss that trains models to distinguish observed pairs from noise (negative) pairs. "The first is a noise-contrastive estimation (NCE) loss with in-batch negatives."
- Per-block quantization: Quantization where parameters are quantized in fixed-size blocks rather than per-tensor or per-channel. ": Per-block quantization."
- Per-channel quantization: Quantization where each channel (e.g., output feature) has its own scale/zero-point. ": Per-channel quantization with int4 for embedding, feedforward, and projection layers, and int8 for attention"
- Quantization-aware training (QAT): Training that simulates quantization effects to reduce quality loss after quantizing weights. "by applying quantization-aware training \citep{8578384} during the model finetuning stage"
- Recall@5kt: An evaluation metric measuring recall at a top-K cutoff (here, 5k) for retrieval; used to assess cross-lingual retrieval. "reporting Recall@5kt and MRR@10 respectively."
- Semantic Text Similarity (STS): Tasks measuring how similar two texts are in meaning. "semantic text similarity"
- Spread-out loss: A loss encouraging pairwise near-orthogonality among embeddings to utilize the space effectively. "We define the spread-out loss as:"
- Spread-out regularizer: A regularizer that improves robustness and expressiveness by distributing embeddings across the unit sphere. "We also include a ``spread-out'' regularizer to improve EmbeddingGemma's expressiveness and robustness."
- Stop-gradient operator: An operation that prevents gradients from flowing through a computation path. "where is the stop-gradient operator"
- UL2 objective: A unified language learning objective mixing multiple denoising tasks for pretraining. "using the UL2 \citep{tay2023ul2unifyinglanguagelearning} objective"
- Vector databases: Databases specialized for storing and querying vector embeddings, often with ANN indexing. "vector databases"
- XTREME-UP: A benchmark for cross-lingual retrieval and understanding across underrepresented languages. "XTREME-UP \citep{ruder2023xtreme}."
- XOR-Retrieve: A cross-lingual open-retrieval benchmark pairing queries and English passages across languages. "XOR-Retrieve \citep{asai2021xor}"
Collections
Sign up for free to add this paper to one or more collections.

