From Generation to Generalization: Emergent Few-Shot Learning in Video Diffusion Models
Abstract: Video Diffusion Models (VDMs) have emerged as powerful generative tools, capable of synthesizing high-quality spatiotemporal content. Yet, their potential goes far beyond mere video generation. We argue that the training dynamics of VDMs, driven by the need to model coherent sequences, naturally pushes them to internalize structured representations and an implicit understanding of the visual world. To probe the extent of this internal knowledge, we introduce a few-shot fine-tuning framework that repurposes VDMs for new tasks using only a handful of examples. Our method transforms each task into a visual transition, enabling the training of LoRA weights on short input-output sequences without altering the generative interface of a frozen VDM. Despite minimal supervision, the model exhibits strong generalization across diverse tasks, from low-level vision (for example, segmentation and pose estimation) to high-level reasoning (for example, on ARC-AGI). These results reframe VDMs as more than generative engines. They are adaptable visual learners with the potential to serve as the backbone for future foundation models in vision.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
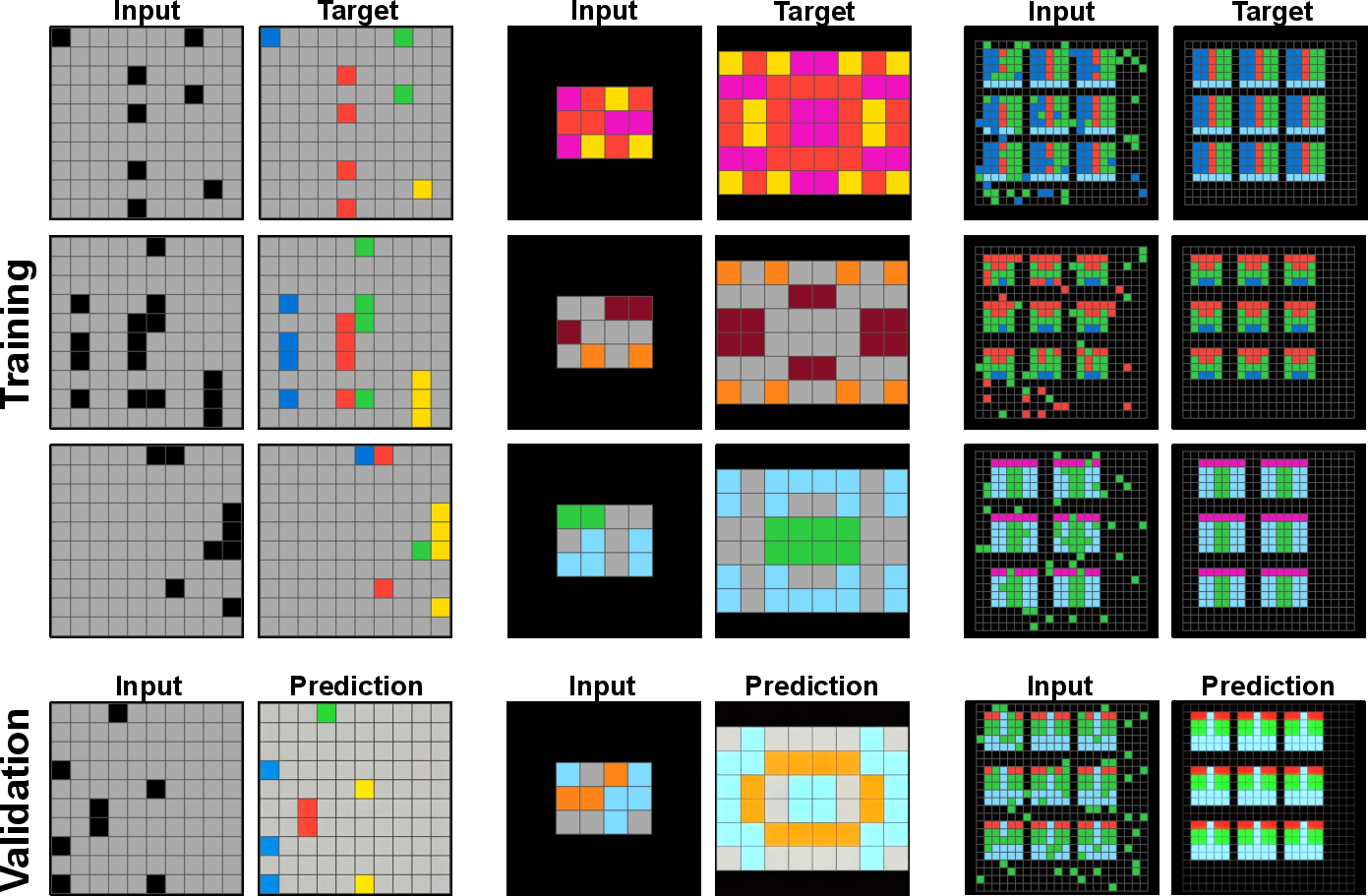
- Abstract Reasoning Corpus (ARC-AGI): A benchmark of grid-based puzzles designed to test compositional visual reasoning and few-shot generalization. "Abstract Reasoning Corpus (ARC-AGI) benchmark"
- Conditioning vector: The combined conditioning inputs (e.g., input frame and text embedding) provided to the diffusion model during inference. "Construct conditioning vector"
- Denoising Diffusion Probabilistic Models (DDPM): Generative models that add noise to data in a forward process and learn a reverse process to denoise and sample from the data distribution. "denoising diffusion probabilistic models"
- Forward process: The diffusion mechanism that progressively adds noise to data, typically modeled as a Markov chain. "forward process distributions"
- Free energy: A theoretical quantity from active inference used to describe learning as minimizing surprise; here used as an analogy for training that reduces prediction discrepancy. "minimization of free energy in biological systems"
- Image-to-Video (I2V): A generation setting where a model produces a video sequence conditioned on a single input image. "image-to-video (I2V) diffusion model"
- In-context learning: The ability of a model to adapt to a new task by leveraging examples provided within the input context rather than changing parameters. "image-based in-context learning"
- Inductive bias: The built-in assumptions and structure in a model that guide learning and generalization to new tasks. "naturally aligns with the inductive biases of video diffusion models"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that adds trainable low-rank updates to existing weight matrices. "low-rank adaptation (LoRA)"
- LoRA adapters: The trainable modules implementing LoRA updates that are inserted into selected layers of a pre-trained model. "We fine-tune LoRA adapters"
- Match Rate: A custom pose-estimation metric in the paper that measures whether key body components are correctly captured. "We propose a custom metric, Match Rate"
- Mean Intersection-over-Union (mIoU): A standard metric for segmentation accuracy measuring overlap between predicted and ground-truth regions. "mean Intersection-over-Union (mIoU) metric."
- Parameter-Efficient Fine-Tuning (PEFT): Methods that adapt large models using small, targeted parameter sets, improving sample efficiency. "parameter-efficient fine-tuning (PEFT)"
- Query/Key/Value/Output (Q/K/V/O) projections: The linear projections in attention layers that compute queries, keys, values, and output transformations. "query (Q), key (K), value (V), and output (O) projection matrices"
- Reverse process: The learned denoising dynamics that invert the forward diffusion to generate clean samples. "to obtain the reverse process"
- Text prompt embedding: A vector representation of a text prompt used to condition generation in multimodal diffusion models. "text prompt embedding"
- Text-to-Image (T2I): A generation setting where a model synthesizes images from textual descriptions. "text-to-image (T2I) diffusion models"
- Text-to-Video (T2V): A generation setting where a model synthesizes videos from textual descriptions. "text-to-video (T2V)"
- Variance schedule: The predefined sequence of noise variances applied at each diffusion step during the forward process. "variance schedule"
- Video Diffusion Models (VDMs): Diffusion models extended to generate spatiotemporal sequences, capturing both spatial detail and temporal coherence. "Video Diffusion Models (VDMs)"
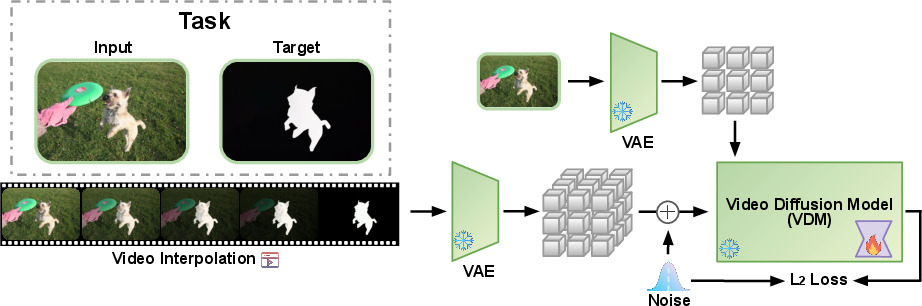
- Video interpolation function: A function that constructs a frame-by-frame transition between an input and target image to create training sequences. "video interpolation function"
- Video Trajectory Interpolation: The paper’s step for building transition videos by interpolating from input to output frames for few-shot adaptation. "Video Trajectory Interpolation"
Collections
Sign up for free to add this paper to one or more collections.

