Intuition to Evidence: Measuring AI's True Impact on Developer Productivity
Abstract: We present a comprehensive real-world evaluation of AI-assisted software development tools deployed at enterprise scale. Over one year, 300 engineers across multiple teams integrated an in-house AI platform (DeputyDev) that combines code generation and automated review capabilities into their daily workflows. Through rigorous cohort analysis, our study demonstrates statistically significant productivity improvements, including an overall 31.8% reduction in PR review cycle time. Developer adoption was strong, with 85% satisfaction for code review features and 93% expressing a desire to continue using the platform. Adoption patterns showed systematic scaling from 4% engagement in month 1 to 83% peak usage by month 6, stabilizing at 60% active engagement. Top adopters achieved a 61% increase in code volume pushed to production, contributing to approximately 30 to 40% of code shipped to production through this tool, accounting for an overall 28% increase in code shipment volume. Unlike controlled benchmark evaluations, our longitudinal analysis provides empirical evidence from production environments, revealing both the transformative potential and practical deployment challenges of integrating AI into enterprise software development workflows.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper looks at what happens when 300 software engineers use an AI helper (called DeputyDev) every day for a full year. The AI helps in two main ways:
- It writes or suggests code (like a smart pair programmer).
- It reviews code changes (like an extra reviewer who checks for bugs, security issues, and quality).
Instead of testing the AI in a small lab with simple problems, the authors measured its impact in real life—inside a big company, on real projects, over many months.
Objectives: What the researchers wanted to find out
The researchers set out to answer simple, practical questions:
- Does using AI actually help engineers get work done faster in real projects?
- Is AI good at reviewing code and spotting real bugs and issues people care about?
- How many people will use it, what do they think of it, and what makes adoption grow or stall?
- Is the cost worth it (what’s the return on investment, or ROI)?
Methods: How the study was done (in everyday terms)
Think of a school year:
- For the first half, students (engineers) work without the new tool.
- For the second half, they get the AI helper and keep working normally.
- The teachers (researchers) compare before-and-after results for the same students.
Here’s how they made the comparison fair and clear:
- Before vs. after: They compared each engineer’s performance in the first six months to their performance in the last six months.
- Heavy users vs. light users: They looked at groups who used the AI a lot and those who barely used it.
- Adjustments: They accounted for things like experience level (junior vs. senior), project size/complexity, team differences, and time-based changes (like learning curves).
Data collection (how they measured things):
- Automatic tracking from coding tools (GitHub/Bitbucket): how much code was written, how fast reviews happened, how often code was merged.
- AI tool logs: how many suggestions were made, accepted, or copied.
- Surveys and interviews: what developers thought about the tool, how helpful it felt, and whether they wanted to keep using it.
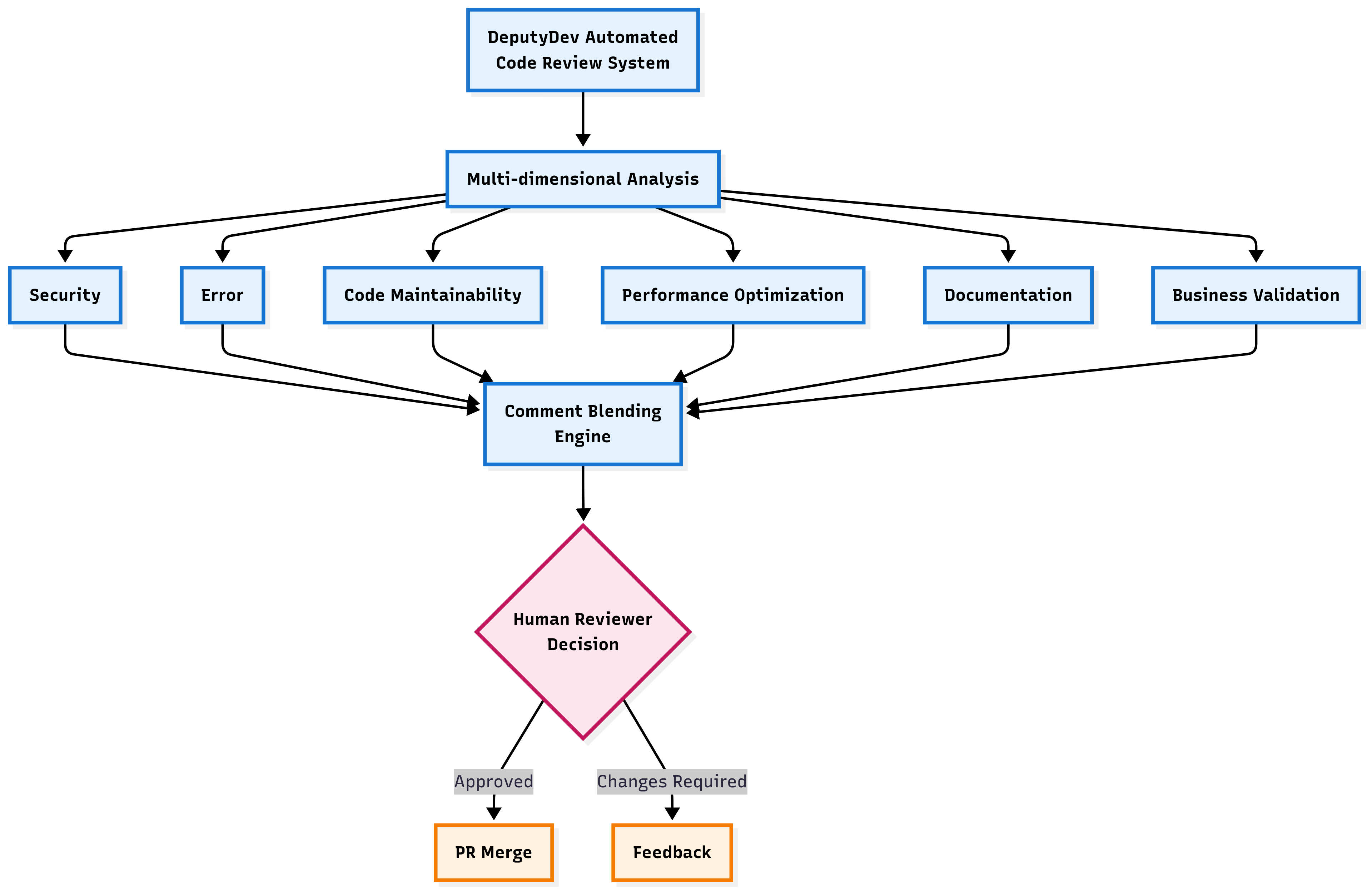
Two parts of the AI:
- Code review (multi-agent system): Imagine six specialist “mini-experts” working in parallel—one for security, one for documentation, one for performance, and so on. They use tools like:
- File Reader: “show me this file or just the important parts.”
- Path Searcher: “find the file or folder I’m looking for.”
- Grep (fast search): “find where this function or text appears across the codebase.”
- Planner: “break big analysis tasks into steps and combine the findings.”
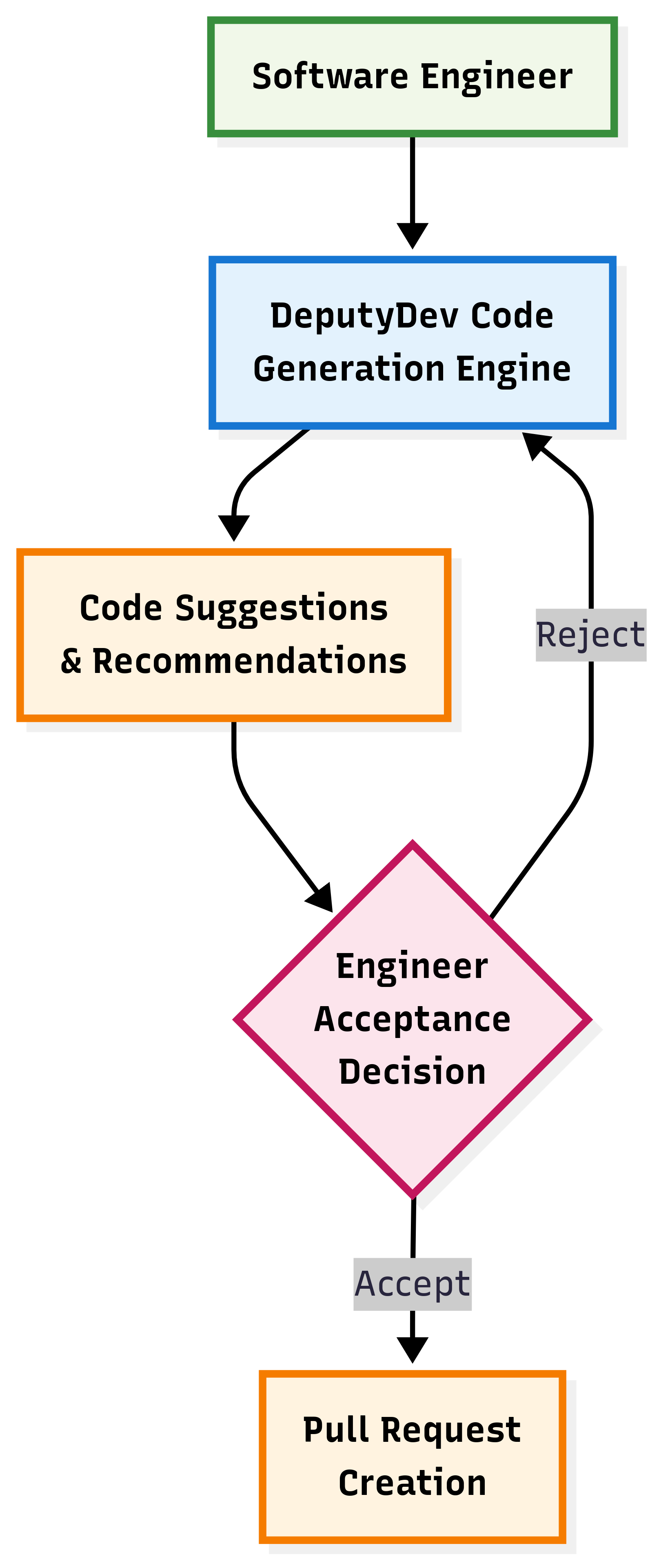
- Code generation (VSCode plug-in): Works like a smart assistant you chat with. It can search your project semantically (meaning-based, not just by exact words), understand code structure (modules/classes/functions), and suggest changes you can review and accept.
Main Findings: What they discovered and why it matters
Productivity and speed:
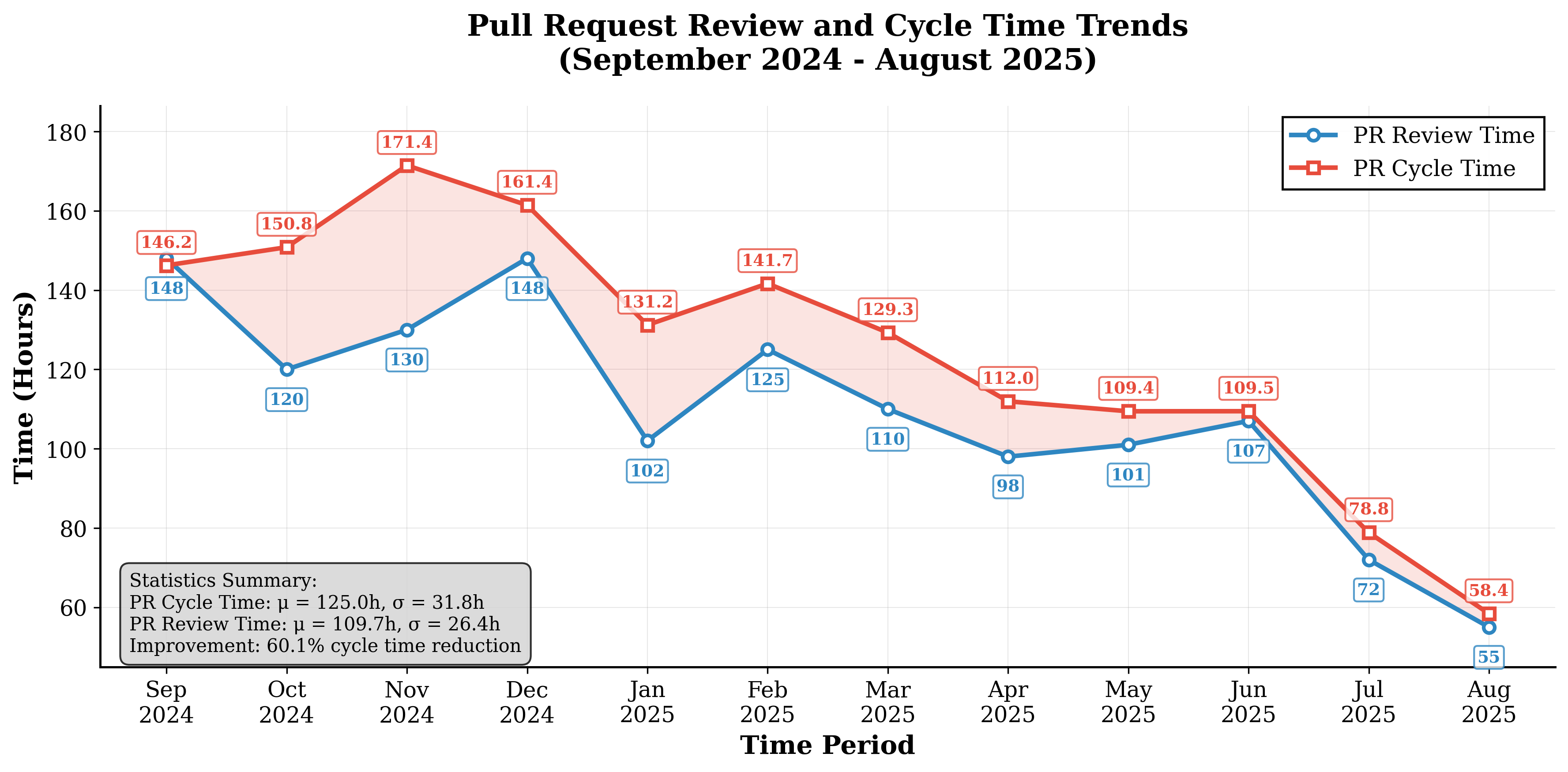
- Code review time dropped by about 31.8%. That means pull requests (PRs) got reviewed and approved significantly faster.
- Engineers who used the AI the most shipped 61% more code to production. Engineers who barely used it shipped 11% less.
Adoption and usage:
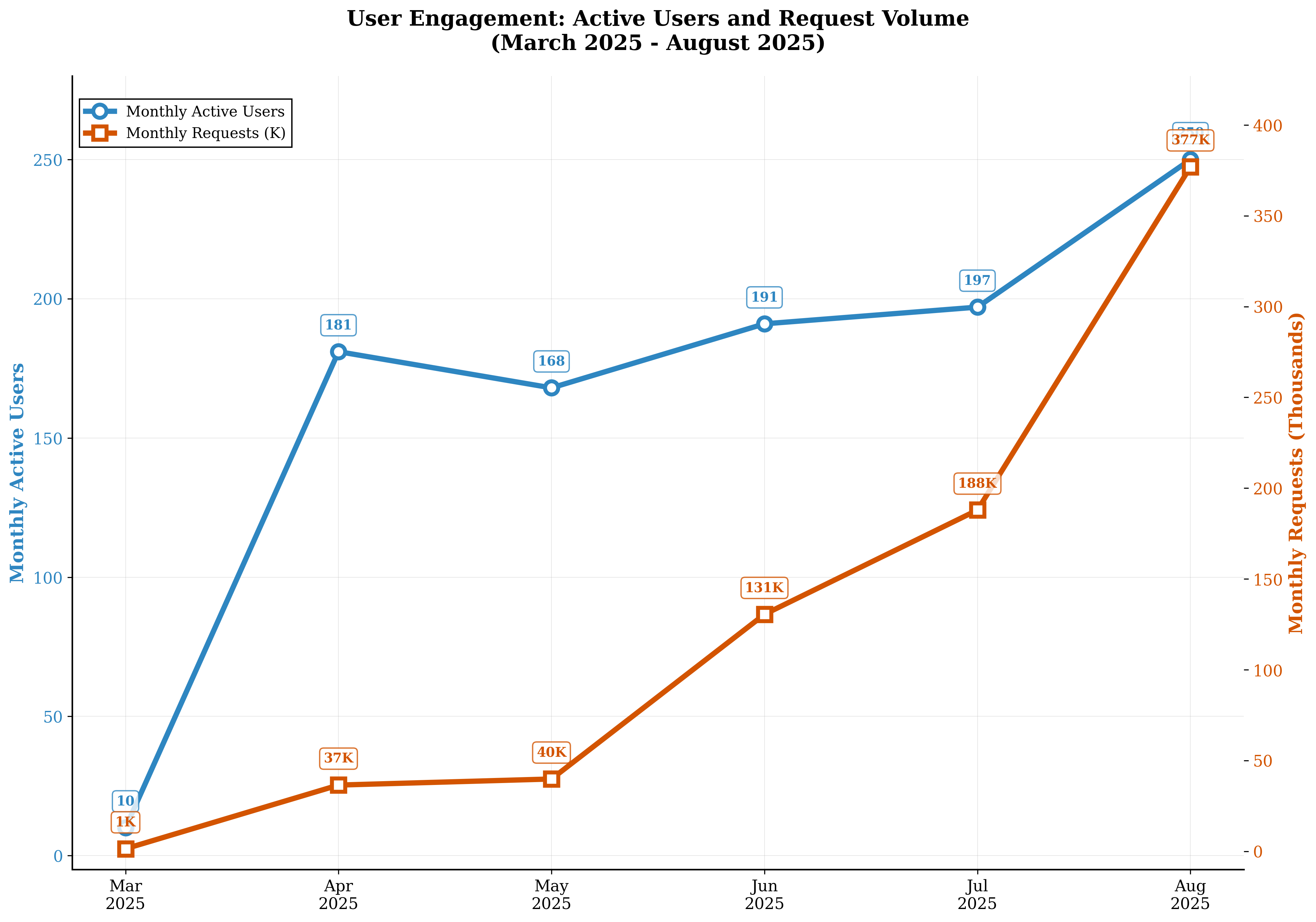
- At first, only ~4% used the AI tool in month 1, but usage grew quickly to a peak of 83% by month 6, then settled at ~60% active use.
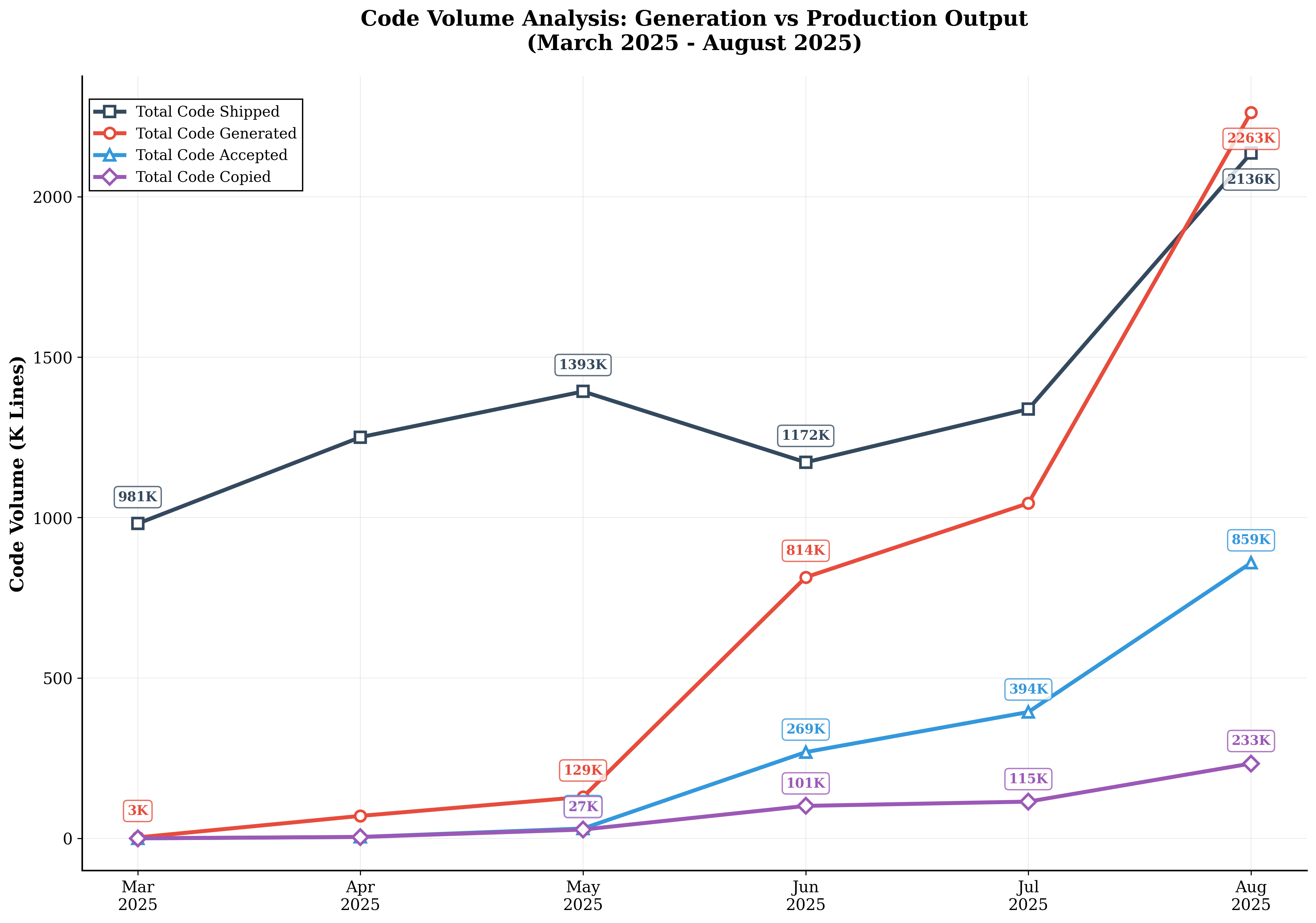
- AI-generated code exploded from 3,000 lines (March 2025) to 2.26 million lines (August 2025).
- In August, about 40% of code shipped was AI-generated, leading to an overall 28% increase in production code volume.
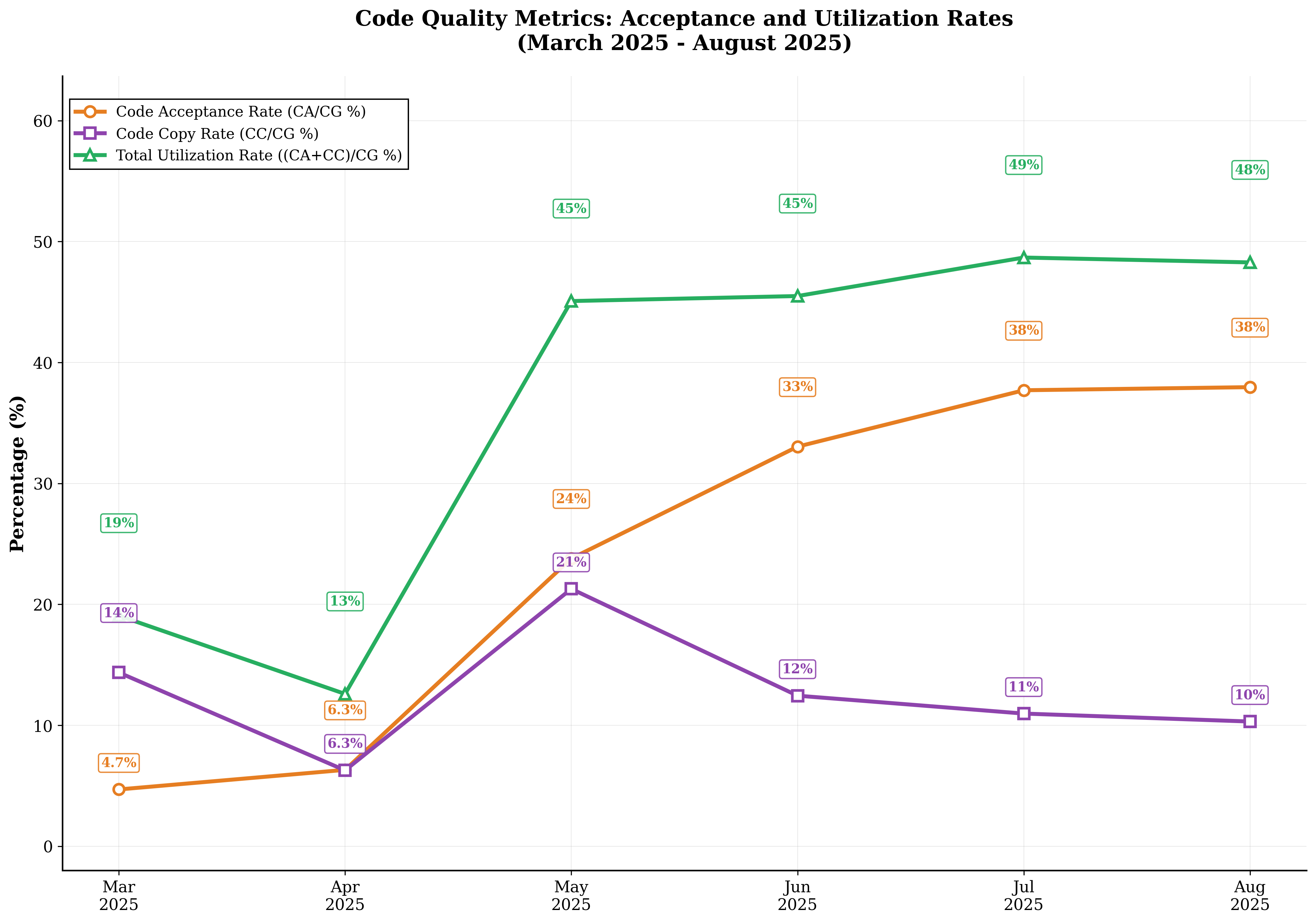
- Acceptance rates for AI suggestions stayed steady at ~35–38%, even as usage scaled up. That’s a good sign for quality.
- Over time, people used “Act Mode” (apply changes directly) more than just “Chat Mode” (talk about changes), showing growing trust.
Developer experience:
- 85% want AI to keep reviewing their PRs.
- 62% want to keep using AI code suggestions (some hesitancy remains, often due to early infrastructure stability issues that got fixed later).
- 93% plan to keep the tool in their workflow.
- Junior engineers saw the biggest gains (77% more code shipped); mid-level and senior engineers also improved (~45% gains).
Costs and ROI:
- Most costs came from the AI models (LLM APIs), especially via AWS Bedrock.
- Monthly total costs were roughly $6K–$12K during the study window.
- With ~300 engineers, average cost was about $30–$34 per engineer per month.
- Given the speedups and code volume increases, the costs are modest compared to typical enterprise software budgets and time saved.
Why these results are important
- Real-world proof: Many AI studies use small test problems. This one measured the tool in the messy, complicated reality of a big engineering team for a whole year.
- Speed + scale: Faster reviews and more shipped code can help teams release features sooner, fix bugs quicker, and keep customers happy.
- Clear adoption pattern: When people use AI tools consistently (not just once or twice), they get real benefits.
- Trust and teamwork: Developers are generally positive, especially about AI review. Over time, more moved from experimenting to actually accepting changes directly.
Implications: What this could mean for the future
- For companies: Rolling out AI coding tools across teams can genuinely speed up development, if you support adoption and train people to use it well.
- For developers: AI can act like a smart teammate—helping with repetitive tasks, catching issues early, and guiding juniors while boosting seniors’ efficiency.
- For tool builders: Stability, good integration with existing workflows, and understandable feedback matter. Multi-agent reviews and strong search tools help the AI give useful, actionable comments.
- Big picture: AI won’t replace developers, but it can make them more effective—especially in code review and routine coding—when used consistently and thoughtfully.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following list summarizes what the paper leaves missing, uncertain, or unexplored, framed as concrete, actionable items for future research:
- Causal attribution without randomization: The quasi-experimental design lacks randomized or cluster-randomized controls. Conduct team-level RCTs or stepped-wedge trials to isolate DeputyDev’s effects from concurrent process changes.
- Underspecified “process optimization interventions”: The paper references process optimizations but does not detail them. Document and separately evaluate these interventions to disentangle AI impact from process changes.
- Quality outcomes beyond cycle time: No objective measurement of post-merge quality (e.g., defect density, MTTR, escape rates, rollbacks, production incidents). Track incident attribution to AI-generated changes and longitudinal defect trends.
- Security effectiveness: The Security agent’s performance is not quantified. Benchmark vulnerability detection (precision/recall) against SAST/DAST baselines and measure remediation triggered by AI findings.
- License/IP compliance: The study does not assess license contamination or IP risks for AI-generated code. Integrate license scanners (e.g., LiCoEval-like checks) and report compliance outcomes.
- Maintainability and technical debt: Productivity is assessed via LOC shipped, but maintainability metrics (cyclomatic complexity, duplication, lint warnings, code smells) and technical debt accumulation are not measured. Add static analysis-based maintainability tracking pre/post AI adoption.
- Test quality and coverage: Impact on test coverage, test flakiness, and CI stability is unreported. Measure unit/integration coverage changes and CI pass/fail rates for AI-authored code.
- Review comment validity: No ground truth assessment of AI review comments. Label a stratified sample to estimate precision/recall, false-positive/negative rates, and the proportion of comments leading to code changes.
- Reviewer workload and “rubber-stamping”: Decreased review time may reduce thoroughness. Quantify human review effort (comment count, depth, code review reading time) and guard against superficial approvals.
- Agent-level contribution and ablation: The multi-agent architecture’s marginal utility is not analyzed. Perform ablation studies to identify high-impact agents and prune low-value ones to reduce cost.
- Model/provider comparison: No head-to-head evaluation across LLMs (Bedrock, OpenAI, Vertex) for cost, latency, and quality. Run controlled comparisons to select optimal model/provider mixes per task.
- Latency and developer flow: Response times and their effect on developer focus are not measured. Instrument latency/SLOs and study impact on interruption cost and task completion rates.
- Act mode guardrails and safety: Safety policies for Act mode (e.g., gating on tests, lint, static analysis) are not described. Define and evaluate guardrails, including rollback rates and post-merge incident attribution.
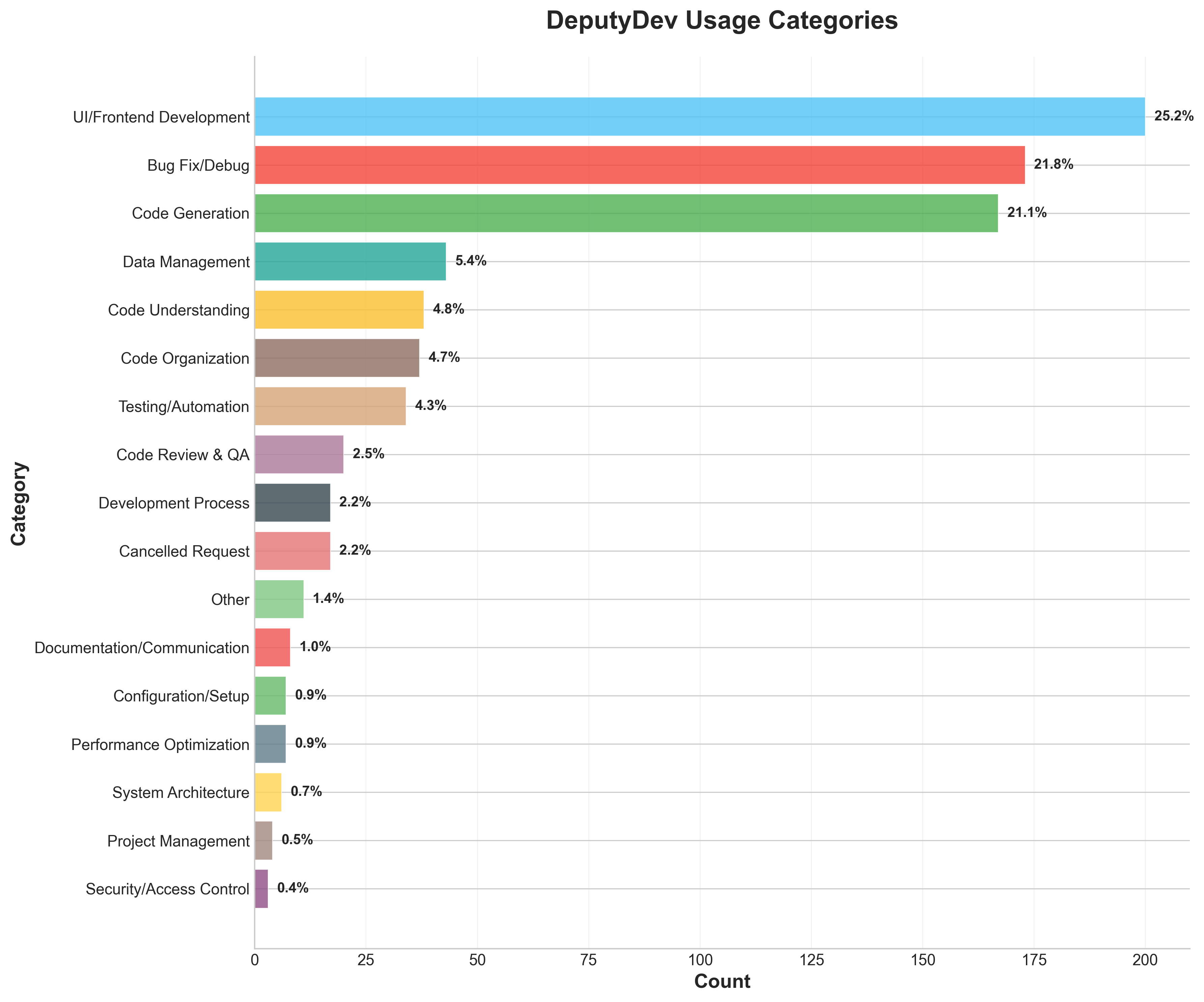
- Adoption in low-usage domains: Minimal usage for Documentation, Project Management, and Security is noted but not investigated. Diagnose barriers and run targeted interventions to raise adoption in these areas.
- Task- and stack-specific efficacy: Outcomes are not stratified by task category, language, or stack. Provide per-category and per-language effect sizes to identify where AI is most/least effective.
- Experience-level quality trade-offs: Junior engineers show large productivity gains, but the quality of their output is not assessed. Evaluate whether AI amplifies or mitigates quality issues in junior-authored code.
- Cognitive load and trust calibration: Claims about reduced cognitive costs are not measured. Use validated instruments (e.g., NASA-TLX, trust scales) to quantify cognitive load, confidence calibration, and error detection reliance.
- Longitudinal sustainability: Effects beyond one year (tool fatigue, trust decay, maintainability impacts) are unknown. Extend observation windows to study sustainability and long-term code health.
- Cohort definition inconsistency: The low-adoption cohort lists >80% review interaction, which conflicts with the “low” designation. Clarify adoption metrics and ensure internally consistent cohort criteria.
- External validity and reproducibility: Single-organization results may not generalize. Release anonymized metrics definitions, instrumentation code, and replication protocols; conduct multi-site studies across varied orgs and stacks.
- ROI quantification is incomplete: The ROI section provides costs but not monetized benefits (time saved → dollars, avoided incidents, opportunity costs). Complete the ROI model with confidence intervals and sensitivity analysis.
- Cost optimization strategies: With LLM API costs dominating, evaluate caching, prompt optimization, smaller/local model distillation, and agent selection to lower spend without quality loss.
- Model/version drift: Sonnet versions are mentioned but version changes are not controlled or analyzed. Establish change management and drift monitoring to quantify performance shifts after model updates.
- Negative outcome tracking: Harmful suggestions, near-misses, and rework caused by AI are not captured. Implement a safety incident taxonomy and track remediations attributable to AI outputs.
- Human-AI collaboration dynamics: The paper references qualitative interviews but reports limited insights. Analyze how AI alters review culture, mentorship, and team collaboration patterns.
- Managerial/business outcomes: Beyond engineering metrics, business effects (lead time, feature cycle time, customer-impact KPIs) are not quantified. Link engineering improvements to business-level outcomes.
- Data privacy and compliance: No assessment of code exposure risks to external LLMs/providers. Audit data flows, enforce PII/code confidentiality constraints, and report compliance posture.
- Invocation strategy: Optimal timing and context for invoking generation/review agents is unexplored. Experiment with smart invocation policies to reduce noise and cost while maximizing impact.
- Comment blending engine evaluation: The deduplication/consolidation layer’s effectiveness is not measured. Evaluate quality improvements (duplicate removal accuracy, coherence gains) and developer triage time pre/post blending.
- Training and enablement: Conversion of “passives” (NPS) and heterogeneous adoption patterns lack a targeted enablement strategy. Test training curricula, prompt libraries, and workflow templates to increase effective usage.
- Comparative baselines against third-party tools: DeputyDev is not compared to Copilot/Cursor/CodeRabbit in production settings. Run head-to-head trials to benchmark relative effectiveness and cost.
Glossary
- A/B experiment: A controlled experimental method comparing two variants to estimate causal effects. "double-controlled A/B experiment"
- Act Mode: An execution mode that directly applies AI-suggested changes to the codebase. "Act Mode applies changes directly to the codebase"
- ANCOVA: Analysis of covariance; a statistical model that adjusts outcomes using covariates to improve causal inference. "ANCOVA models"
- AWS Bedrock: A managed service providing access to foundation models for generative AI applications. "AWS Bedrock"
- Between-Subjects Natural Experiment: A comparative design using naturally occurring groups rather than random assignment. "Between-Subjects Natural Experiment:"
- Chat Mode: An interactive conversational mode for iteratively refining requirements and solutions. "Chat Mode is ideal for exploring solutions through conversational development"
- CI builds: Continuous Integration builds that automatically compile and test code on each change. "CI builds repair"
- Claude Sonnet 3.7: A specific version of Anthropic’s Claude model used for code and review tasks. "Claude Sonnet 3.7"
- Cohen's d: A standardized effect size measuring the magnitude of differences between groups. "Cohen's d = 1.42"
- Cohort analysis: An analytical approach comparing groups over time based on shared characteristics or behaviors. "cohort analysis"
- DeepCRCEval: A framework for comprehensive evaluation of code review comments and automation readiness. "DeepCRCEval"
- Difference-in-Differences: A quasi-experimental method estimating treatment effects by comparing pre/post changes across groups. "Difference-in-Differences Analysis:"
- Ecological validity: The extent to which findings generalize to real-world settings. "ecological validity"
- Elasticache: A managed in-memory caching service used to improve system performance. "Elasticache"
- ENAMEL: An evaluation benchmark focusing on code efficiency rather than correctness. "ENAMEL"
- Fixed effects: Statistical controls for time-invariant characteristics within panels (e.g., month/quarter). "fixed effects"
- Focus Snippet Searcher: A precision tool for locating code definitions via fully qualified names. "Focus Snippet Searcher: A precision tool designed for locating specific code definitions"
- Fuzzy search: An approximate search technique that matches similar strings and partial names. "A fuzzy search mechanism for discovering files within the repository structure."
- GitHub Actions: A CI/CD automation platform integrated with GitHub repositories. "GitHub Actions"
- Hawthorne Effects: Behavior changes due to awareness of being observed in a study. "Hawthorne Effects:"
- Hunk-level: Granularity at the patch segment level within diffs in code reviews. "hunk-level"
- JIRA: An issue and project tracking system commonly used in software development. "JIRA"
- Language Servers: Tools providing language-specific analysis like syntax, types, and completion via LSP. "Language Servers: Provides real-time language-specific analysis capabilities"
- LiCoEval: A benchmark for license compliance evaluation of generated code. "LiCoEval"
- Lines of Code (LOC): A quantitative measure of code volume. "LOC"
- Long Code Arena: A benchmark suite requiring project-wide context for complex code tasks. "Long Code Arena"
- LongCoder: A model architecture designed to handle long code contexts. "LongCoder"
- MCP: A protocol layer enabling tool and service integration for context-aware generation. "MCP: Enables seamless communication between the code generation system and various external tools and services."
- Memory tokens: Model tokens used to persist context across long sequences or steps. "memory tokens"
- Multi-agent system: An architecture where multiple specialized AI agents collaborate on tasks. "multi-agent PR review system"
- Multi-level models: Hierarchical statistical models accounting for nested data structures (e.g., teams within orgs). "multi-level models"
- NPS: Net Promoter Score; a metric of user loyalty and satisfaction. "NPS survey"
- Path Searcher: A repository tool to locate files via partial names or search terms. "Path Searcher: A fuzzy search mechanism for discovering files within the repository structure."
- Planner Tool: A reasoning component that decomposes complex analyses into coordinated steps. "Planner Tool: An advanced reasoning and planning component that enables complex multi-step analysis tasks."
- Propensity score matching: A method to reduce selection bias by balancing covariates between groups. "propensity score matching"
- Quasi-experimental longitudinal design: A time-based study without randomization, using controls and adjustments for inference. "quasi-experimental longitudinal design"
- RepoFusion: A technique incorporating repository context to improve code generation performance. "RepoFusion"
- ripgrep: A fast, recursive command-line search tool for codebases. "ripgrep"
- ROI: Return on Investment; measures financial benefit relative to cost. "ROI"
- Semantic code indexing: Structuring code into meaningful units to enable semantic retrieval and generation. "semantic code indexing"
- Semantic vector search: Retrieval based on embeddings capturing meaning rather than exact text match. "semantic vector search"
- Sliding window mechanisms: Techniques processing long sequences by moving a fixed-size context window. "sliding window mechanisms"
- SWE-bench: A benchmark evaluating models on real GitHub issues in controlled settings. "SWE-bench"
- Vector and lexical hybrid search: Combined embedding-based and keyword search for higher recall/precision. "vector and lexical hybrid search"
- Vector database: A database optimized for storing and querying vector embeddings. "Weaviate vector database"
- Weaviate: An open-source vector database used for semantic search and retrieval. "Weaviate"
- Weaviate Vector DB: The specific vector database instance used for semantic code discovery. "Weaviate Vector DB"
- Within-Subjects Controls: A design where each participant serves as their own baseline. "Within-Subjects Controls:"
Practical Applications
Immediate Applications
Below is a list of concrete, deployable use cases that leverage the paper’s findings, methods, and innovations. Each bullet includes sector linkage, enabling tools/workflows, and key assumptions or dependencies affecting feasibility.
- AI-assisted PR review to reduce cycle time by ~31.8%
- Sector: software; open-source
- Tools/workflows: Multi-agent PR review on GitHub/Bitbucket; automated webhook invocation; comment blending engine; agent attribution for traceability; hunk-level comments
- Assumptions/dependencies: Reliable LLM access; repository permissions; reviewer buy-in; manageable false-positive rate
- Shift-left security and quality gates in CI/CD
- Sector: finance, healthcare, e-commerce, telecom
- Tools/workflows: Security, Maintainability, Error Detection agents; Grep + Planner; CI checks that block merges on critical findings
- Assumptions/dependencies: Domain rule packs; audit logs; policy alignment with compliance teams
- Team productivity instrumentation and ROI dashboards
- Sector: software; platform engineering; finance (cost control)
- Tools/workflows: VCS webhooks; PR metrics (review time, iteration counts); acceptance/copy rates; cohort analysis; cost-per-user tracking
- Assumptions/dependencies: Unified telemetry pipeline; stable measurement definitions; privacy controls
- Developer onboarding accelerators (especially for junior engineers)
- Sector: software; education/training
- Tools/workflows: VSCode extension with semantic indexing (Weaviate), Focus Snippet Searcher; curated prompts; Chat vs Act mode playbooks; mentor-reviewed AI suggestions
- Assumptions/dependencies: Clean, indexed codebase; style guides; structured onboarding content
- Bug triage and regression hunting
- Sector: software; QA
- Tools/workflows: Error Detection agent with Grep/Path Searcher; planner-driven cross-file analysis; JIRA linkage
- Assumptions/dependencies: Sufficient test coverage; issue tracker integration; repository-wide indexing
- Performance tuning guidance in PRs
- Sector: cloud infra, streaming, telecom
- Tools/workflows: Performance Optimization agent; language servers; actionable suggestions with code snippets; optional profile references
- Assumptions/dependencies: Accurate context; performance baselines/profiling data
- Documentation nudge and standardization
- Sector: software; education
- Tools/workflows: Documentation agent; docstring templates; style enforcement via comments; optionally auto-insert in Act mode
- Assumptions/dependencies: Agreed documentation standards; merge policies
- Open-source maintainer throughput improvement
- Sector: open-source community
- Tools/workflows: GitHub App using multi-agent review; deduplicated comments; manual trigger workflows to avoid spam; transparency via agent labels
- Assumptions/dependencies: Community acceptance; contributor guidelines updates
- Cost optimization and provider routing
- Sector: enterprise/platform engineering; procurement
- Tools/workflows: Multi-provider LLM orchestration (Bedrock/OpenAI/Vertex); workload routing by cost/latency; usage quotas and alerts; prompt library standardization
- Assumptions/dependencies: Comparable model quality; contract flexibility; robust usage telemetry
- Knowledge discovery in monorepos and large codebases
- Sector: large enterprises; software
- Tools/workflows: Weaviate-based semantic search; structured chunking (modules/classes/functions); hybrid vector + lexical searches
- Assumptions/dependencies: Quality embeddings; routine indexing; codebase coverage
- Internal AI governance baseline for development
- Sector: enterprise compliance; risk/governance
- Tools/workflows: Human reviewer-of-record; agent attribution retained; logging and audit trails; license compliance checks (inspired by LiCoEval findings); opt-in/opt-out policies
- Assumptions/dependencies: Legal counsel engagement; clear data retention and access policies
- Classroom integration to teach modern code review
- Sector: academia
- Tools/workflows: Course repos with AI review enabled; measurement of PR quality and turnaround; controlled assignments comparing AI vs human feedback
- Assumptions/dependencies: Institutional approval; student data protections; rubric alignment
Long-Term Applications
These use cases require further research, scaling, or productization beyond current deployment readiness, while building directly on the paper’s methods and empirical insights.
- Autonomous code maintenance pipelines (closed-loop)
- Sector: software; cloud infra
- Tools/workflows: Act mode proposing patches; CI runs tests/benchmarks; human approval gates; planner-driven refactors; rollback safeguards
- Assumptions/dependencies: High test coverage; strong safety rails; explainable changes; organizational change management
- Domain-specific compliance agents
- Sector: healthcare (HIPAA), finance (PCI/SOX), energy (NERC), public sector
- Tools/workflows: Policy packs for regulated domains; automated generation of compliance artifacts in PRs; audit-ready logs
- Assumptions/dependencies: Domain expert curation; legal validation; periodic policy updates
- Enterprise-scale semantic code memory
- Sector: large enterprises; platform engineering
- Tools/workflows: Unified embeddings across code, docs, tickets; MCP integrations; cross-repo impact analysis; “business validation” aware code generation
- Assumptions/dependencies: Data governance; PII/security controls; scalable vector infra
- Workforce analytics for planning and reskilling
- Sector: HR/PeopleOps; engineering leadership
- Tools/workflows: Longitudinal models (ANCOVA, multi-level) predicting adoption-driven productivity; targeted training forecasts; role redesign
- Assumptions/dependencies: Ethical analytics; transparency with staff; avoid surveillance misuse
- Full-lifecycle evaluation benchmarks beyond SWE-bench
- Sector: academia; tooling vendors
- Tools/workflows: Open datasets capturing PR review dynamics, adoption patterns, code generation acceptance; reproducible pipelines
- Assumptions/dependencies: Anonymization; multi-org participation; standard metrics
- Cost-aware inference research and model compression
- Sector: platform engineering; finance
- Tools/workflows: Adaptive routing; token caching; prompt optimization; on-prem/value models; distillation/quantization for common tasks
- Assumptions/dependencies: MLOps maturity; benchmarking to ensure quality parity
- Trust, explainability, and uncertainty quantification in AI review
- Sector: regulated industries; software
- Tools/workflows: Confidence scores; provenance of evidence (files/lines); counterfactual examples; rationale summaries; user-controllable verbosity
- Assumptions/dependencies: Model support for uncertainty; UX integration; empirical validation with users
- Private/on-prem deployments for sensitive codebases
- Sector: healthcare, finance, defense, critical infrastructure
- Tools/workflows: Self-hosted LLMs and vector DBs; VPC isolation; KMS; offline indexing; zero-trust integration
- Assumptions/dependencies: Hardware capacity; ML platform teams; acceptable model quality on-prem
- AI-enhanced testing (coverage and reliability)
- Sector: software; robotics; automotive
- Tools/workflows: Agents generate unit/property/fuzz tests; differential testing; flaky test detection; coverage targets enforced in CI
- Assumptions/dependencies: Clear specs; test data availability; integration with existing frameworks
- Legacy modernization and cross-language refactoring
- Sector: telecom; government IT; industrial control
- Tools/workflows: Maintainability agent + planner to migrate from legacy stacks; semantic mapping across languages; staged refactors
- Assumptions/dependencies: Validation suites; migration playbooks; stakeholder alignment
- National/regulatory policy frameworks for AI dev tooling
- Sector: public policy; standards bodies
- Tools/workflows: Measurement standards for productivity gains and risk; certification schemes for AI code assistants; worker training support
- Assumptions/dependencies: Multi-stakeholder input; evidence-based thresholds; international harmonization
- Curriculum transformation for AI-in-the-loop software engineering
- Sector: academia
- Tools/workflows: Courses combining empirical methods (quasi-experiments, cohort analysis) with AI coding tools; ethics modules; reproducible analytics
- Assumptions/dependencies: Faculty training; infrastructure grants; IRB/ethics compliance
- Productization of the research artifacts
- Sector: software tooling vendors; marketplaces
- Tools/workflows: Commercial GitHub/Bitbucket apps for multi-agent review; VSCode extensions; adoption/ROI analytics SaaS; cost controller
- Assumptions/dependencies: Support/SLAs; pricing models; integrations across ecosystems
- Robotics/embedded adaptation with deterministic constraints
- Sector: robotics; automotive; aerospace
- Tools/workflows: Agents tuned for C/C++ and real-time systems; static analysis coupling; performance/safety checks; MISRA and similar standard enforcement
- Assumptions/dependencies: Language coverage; deterministic model behavior; certification processes (e.g., ISO 26262)
Collections
Sign up for free to add this paper to one or more collections.