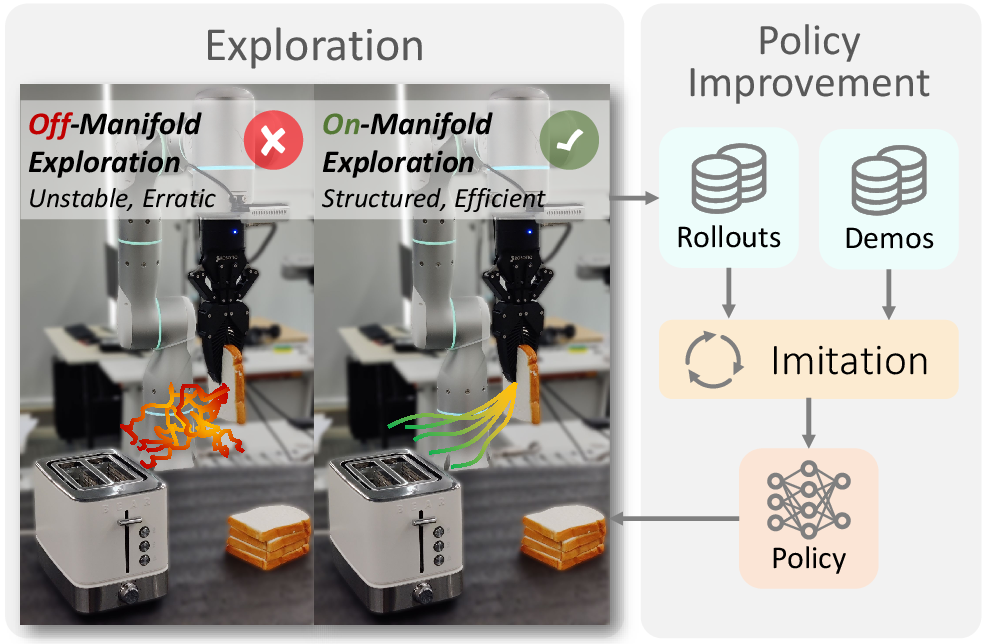
SOE: Sample-Efficient Robot Policy Self-Improvement via On-Manifold Exploration
Abstract: Intelligent agents progress by continually refining their capabilities through actively exploring environments. Yet robot policies often lack sufficient exploration capability due to action mode collapse. Existing methods that encourage exploration typically rely on random perturbations, which are unsafe and induce unstable, erratic behaviors, thereby limiting their effectiveness. We propose Self-Improvement via On-Manifold Exploration (SOE), a framework that enhances policy exploration and improvement in robotic manipulation. SOE learns a compact latent representation of task-relevant factors and constrains exploration to the manifold of valid actions, ensuring safety, diversity, and effectiveness. It can be seamlessly integrated with arbitrary policy models as a plug-in module, augmenting exploration without degrading the base policy performance. Moreover, the structured latent space enables human-guided exploration, further improving efficiency and controllability. Extensive experiments in both simulation and real-world tasks demonstrate that SOE consistently outperforms prior methods, achieving higher task success rates, smoother and safer exploration, and superior sample efficiency. These results establish on-manifold exploration as a principled approach to sample-efficient policy self-improvement. Project website: https://ericjin2002.github.io/SOE









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “SOE: Sample-Efficient Robot Policy Self-Improvement via On-Manifold Exploration”
1) What is this paper about?
This paper is about teaching robots to get better at tasks by practicing on their own, safely and efficiently. Instead of relying a lot on humans to show them what to do, the robot learns to explore and try new actions that are likely to be valid and useful. The method is called SOE, which stands for Self-Improvement via On-Manifold Exploration.
Think of it like a robot learning a new game: it shouldn’t just guess randomly (that can be unsafe and slow). SOE helps the robot explore in smart ways that stay within the “rules” of the game.
2) What questions does the paper try to answer?
The paper focuses on four main goals:
- How can robots explore new actions safely, without moving in wild or risky ways?
- How can this exploration be effective and diverse, so the robot doesn’t keep doing the same failing action?
- Can this exploration be added as a plug-in to existing robot controllers without harming their current performance?
- Can humans easily guide the robot’s exploration to speed it up even more?
3) How does the method work?
The core idea is “on-manifold exploration.” Here’s what that means in everyday language:
- Imagine the set of all possible robot actions as a huge space. Only a small part of that space contains “valid, sensible actions” that make sense for the task. That smaller, valid region is called the “manifold.”
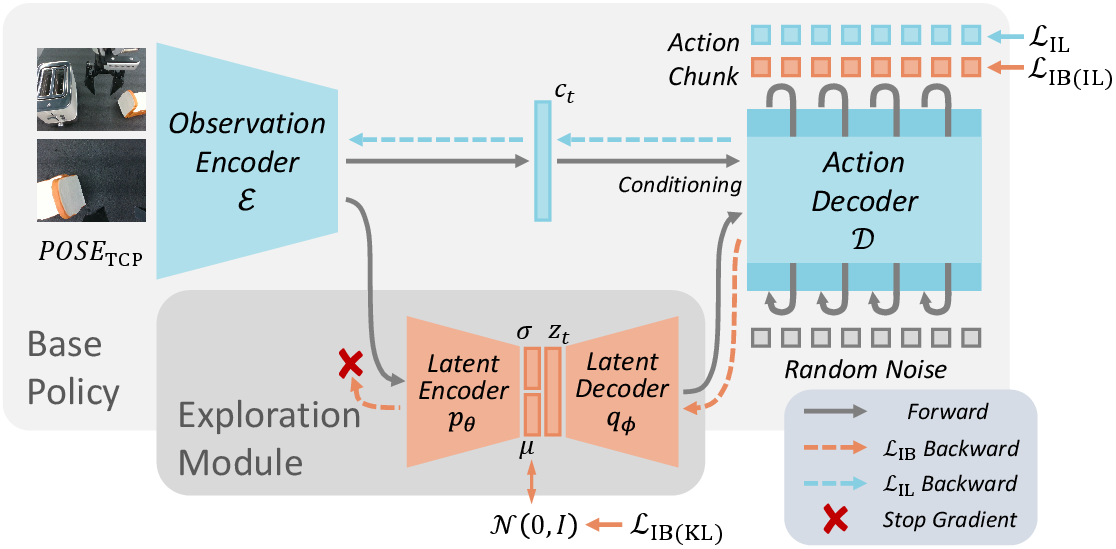
- Randomly poking around the huge action space often leads to unsafe or useless moves. Instead, SOE learns a compact internal code (called a latent space) that captures only what matters for the task. Then it explores variations inside this compact code, which keeps actions valid and smoother.
Key parts explained with simple analogies:
- Latent space: Like a set of control knobs that summarize what’s important for the task (e.g., how to move the gripper, where to aim).
- Variational Information Bottleneck (VIB): Imagine packing a backpack with only the essentials for a trip. VIB teaches the robot to keep only action-relevant information in its “backpack” (the latent code), and leave out distracting details.
- Two-path (dual) architecture:
- Base path: The robot’s normal, stable controller (unchanged).
- Exploration path: A path that tries smart variations by adjusting the “control knobs” in the latent space, then turns those into real actions.
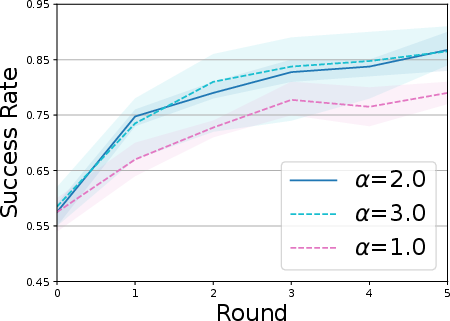
- Exploration scale (alpha): A dial that controls how bold the robot’s exploration is. Small alpha = cautious tweaks; large alpha = more adventurous variations.
- Human-guided steering: The latent space’s knobs tend to separate into meaningful factors (like “left-right” vs “up-down”). The method measures which knobs are informative using SNR (Signal-to-Noise Ratio). High-SNR knobs are reliable. Humans can then tweak the most useful knobs to steer the robot toward promising behaviors, choosing from diverse suggestions (picked with a “farthest point sampling” trick to avoid redundant options).
Importantly, SOE is designed as a plug-in: it slots into existing robot policies (like diffusion policies) and trains jointly, without harming the original controller’s performance.
4) What did the experiments show, and why is that important?
The authors tested SOE in both real-world and simulated tasks.
Real-world tasks (with a robotic arm and cameras):
- Tasks: Mug Hang (hang a mug on a rack), Toaster Load (put bread in a toaster), Lamp Cap (assemble an alcohol lamp by placing its cap).
- Compared methods: plain Diffusion Policy (DP), SIME (a prior exploration method), and SOE (with and without human steering).
- Results:
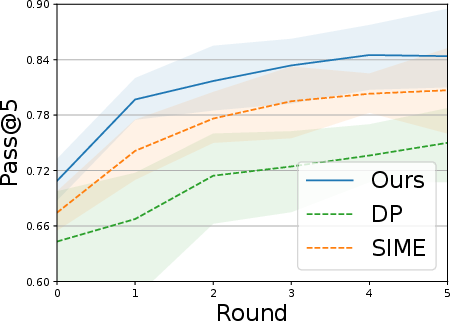
- SOE found successful actions more often and more quickly (higher “Pass@5” and success rate).
- Motions were smoother and safer (lower jerk), unlike SIME which became jerky when exploring.
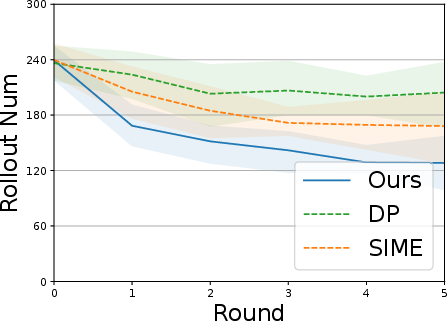
- SOE needed fewer trials (“rollouts”) to gather good experiences.
- Adding human-guided steering made performance even better.
- With just one round of self-improvement, SOE achieved big gains—for example, average relative improvement of about 50.8% across the real tasks. Some tasks saw up to 62% improvement after steering.
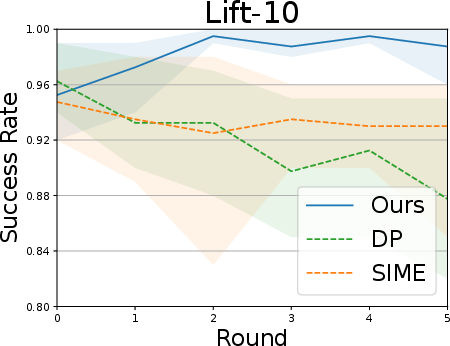
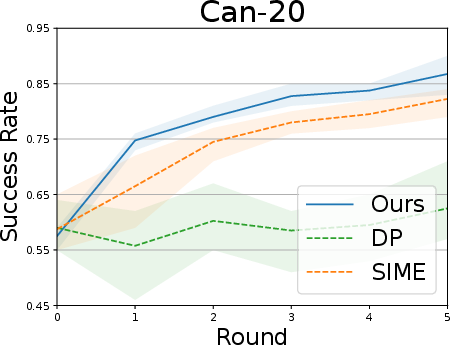
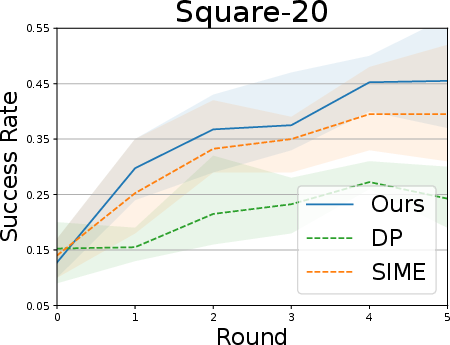
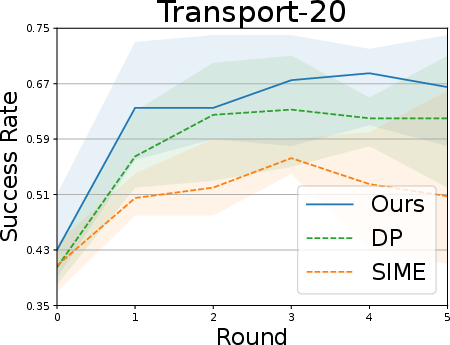
Simulation tasks (Lift, Can, Square, Transport):
- Fewer demonstrations were used to create imperfect starting policies, then SOE was applied to improve them.
- Results:
- SOE steadily improved performance over multiple rounds.
- It was the only method that consistently improved across all tasks.
- It became more sample-efficient over time (fewer interactions needed in later rounds).
- Baseline methods were less stable—sometimes their success rates went up and down or even got worse.
Ablation studies (testing parts of the method):
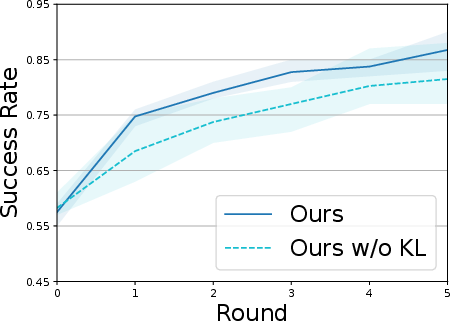
- The “KL” regularizer (a piece of the VIB loss) mattered for keeping the latent code clean and useful.
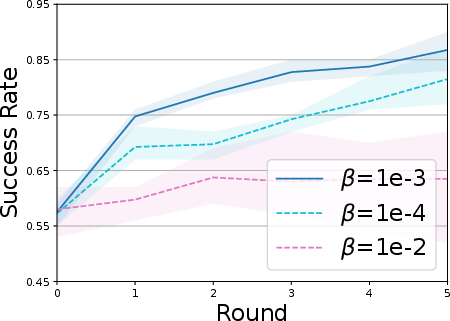
- The exploration scale (alpha) and bottleneck weight (beta) need to be balanced: too small, and exploration is timid; too big, and it becomes unstable.
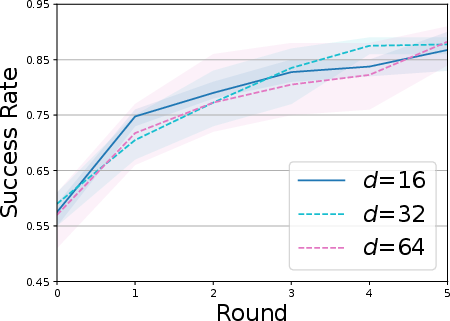
- The exact size of the latent space wasn’t very sensitive—but the number of “effective” knobs (high-SNR dimensions) matched task complexity. Simple tasks used fewer knobs; complex tasks used more.
Why this matters:
- SOE improves robots in a way that is safe, structured, and efficient.
- It reduces the need for expensive human teleoperation.
- It respects the base controller and adds exploration without breaking what already works.
5) What is the impact of this research?
SOE shows a practical and principled way for robots to self-improve:
- Safety: Exploring “on the manifold” avoids risky, erratic moves.
- Efficiency: The robot learns faster, with fewer attempts, saving time and wear on hardware.
- Compatibility: It’s a plug-in that works with existing policies, like diffusion policies.
- Control: Humans can easily guide the robot’s exploration by adjusting meaningful “knobs,” without having to teleoperate.
Overall, this approach helps robots learn like careful students who practice within the rules, try smart variations, and ask for guidance when needed—leading to better, faster, and safer improvement.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper that future researchers could address.
- Formal grounding of the “on-manifold” claim: No theoretical analysis or formal definition of the task/action manifold is provided, nor guarantees that the VIB latent truly constrains exploration to valid, safe actions.
- Safety beyond motion smoothness: Safety is proxied by end-effector jerk; collisions, contact forces, joint limit violations, and workspace constraint breaches are not measured or constrained, and no safety monitors or fail-safes are implemented.
- Success detection and data curation: The paper retains only successful rollouts but does not detail the success labeling pipeline (automatic vs. manual), potential biases introduced, or whether informative near-failures are discarded; methods for leveraging failures remain unexplored.
- Generality across policy architectures: Despite the claim of plug-in compatibility with arbitrary policies, experiments are limited to Diffusion Policy; validation on transformer, flow-based, Gaussian mixture, or classic BC policies (and RL actors) is missing.
- Baseline breadth and fairness: Comparisons omit widely used exploration baselines (e.g., entropy regularization, Boltzmann/Thompson sampling, goal-directed exploration, curiosity/intrinsic reward RL, residual RL); absence of stronger or complementary baselines limits interpretability of gains.
- Task diversity and difficulty: Real-world evaluation spans only three tabletop tasks on a single arm and gripper; long-horizon, highly dynamic, cluttered, deformable-object, contact-rich, and non-stationary tasks are not tested.
- Cross-embodiment and sensor generalization: Generalization to different robot platforms, end-effectors, control modalities (torque/velocity), and sensor suites (depth, tactile, force/torque) is untested.
- Disentanglement evidence: The claim that latent dimensions are disentangled relies on SNR heuristics and visualizations; standard disentanglement metrics (e.g., DCI, MIG, SAP) and causal/semantic validation are absent.
- Universality of SNR threshold: The assertion of a “universal, task-agnostic” SNR threshold is unproven; robustness across tasks, embodiments, datasets, and training regimes is not evaluated.
- Human-guided steering cost and efficacy: While steering improves Pass@5 and success rate, human time, cognitive load, UI ergonomics, repeatability, and comparative efficiency versus teleoperation or lightweight corrective feedback are not quantified.
- Compute and latency overhead: The dual-path plug-in adds inference/training cost; real-time constraints, GPU/CPU requirements, latency at 10 Hz, and feasibility on embedded platforms are not measured.
- Gradient isolation in dual-path training: The IB loss includes the diffusion network εψ; details on stop-gradient or parameter freezing to truly avoid degrading the base policy are unclear and need empirical verification.
- Prior choice and latent geometry: The isotropic Gaussian prior and diagonal Gaussian encoder may be too restrictive; evaluating richer priors (mixtures, flows) and non-Gaussian posteriors for complex manifolds is an open avenue.
- Multi-modality handling in latent space: The VIB formulation may not capture multimodal cognitive factors; whether the latent sampling can reliably traverse modes without relying solely on diffusion’s multimodality is untested.
- Exploration scale adaptation: α (exploration scale) and β (KL weight) are fixed or manually tuned; adaptive, safety-aware schedules or uncertainty-aware control of exploration magnitude are not explored.
- Off-manifold novelty vs. safety trade-off: Constraining exploration to the manifold may limit discovery of novel strategies beyond demonstrations; the balance between staying on-manifold and exploring new, potentially better behaviors is not studied.
- Long-horizon temporal coherence: The approach assumes chunked actions (H=20) and diffusion-generated coherence; sensitivity to chunk length, receding horizon control, and drift across longer sequences is not analyzed.
- Robustness to observation perturbations: Effects of sensor noise, occlusions, lighting changes, camera miscalibration, and sim-to-real visual shift are not evaluated; robustness techniques (augmentations, domain randomization) are not discussed.
- Automatic dimension selection and semantics: Mapping effective latent dimensions to interpretable task factors is manual; methods for automatic alignment with task semantics and stability under distribution shifts are lacking.
- Scaling self-improvement loops: Multi-round improvement is shown, but data growth management, avoidance of dataset bias/drift, catastrophic forgetting, and principled aggregation (e.g., importance weighting, curriculum) are not addressed.
- Statistical significance and variability: While averages across seeds are reported, statistical tests (e.g., confidence intervals, hypothesis testing) and detailed variance analysis for real-world results are absent.
- Failure mode characterization: The paper does not analyze where SOE fails (e.g., precision assembly errors, contact misalignment) or provide diagnostic tools to guide corrective exploration or model updates.
- Depth and multimodal sensing: Real-world experiments use only RGB; the impact of depth, point clouds, tactile, or force feedback on manifold learning and exploration quality remains unexamined.
- Reset and Pass@5 protocol: Pass@5 assumes the same starting condition, but real-world reset precision, object placement variability, and their effect on comparability across methods are not documented.
- Negative transfer and performance degradation: Merging self-collected data sometimes degrades DP performance; strategies to mitigate negative transfer (filtering, weighting, off-policy correction) are not investigated.
- Formalizing “intrinsic dimension”: The notion of a task’s intrinsic dimension is intriguing but lacks a definition, estimation methodology, or theoretical underpinning; validating this across tasks and policies is an open problem.
- Leveraging failed trajectories: Methods to mine failures for counterfactual learning, recovery behaviors, or risk-aware exploration are not explored.
- Expanded evaluation metrics: Beyond success rate, jerk, and rollouts, metrics like completion time, path length, energy use, contact count, and compliance are not reported.
- UI and reproducibility: Details of the interactive steering interface (design, availability, usage guidelines) are sparse; open-sourcing and standardization would aid replication and comparative studies.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s on-manifold exploration framework (SOE), the plug-in integration design, and human-guided steering. Each item includes sector(s), potential tools/products/workflows, and key assumptions/dependencies that may affect feasibility.
- Sample-efficient robot policy post-training in labs and factories (Robotics, Manufacturing)
- Tools/products/workflows:
- “SOE plug-in” for existing imitation-learning policies (e.g., Diffusion Policy), with a dual-path architecture to preserve base performance while adding structured exploration.
- Self-improvement loop: collect rollout proposals, filter by Pass@k (e.g., Pass@5), merge successful trajectories into the dataset, retrain policy.
- Safety monitoring via jerk metrics to ensure smooth motions during exploration.
- Assumptions/dependencies:
- Availability of a base policy trained on limited demonstrations.
- Visual sensing (e.g., RGB cameras) and action chunking interfaces.
- Proper hyperparameter tuning (exploration scale α, KL weight β).
- Tasks have a well-defined “valid action manifold” (e.g., tabletop manipulation, pick-and-place, assembly).
- Warehouse bin-picking, palletizing, and kitting with fewer demos (Logistics, E-commerce Robotics)
- Tools/products/workflows:
- SNR-based latent dimension identification to steer grasp approach (e.g., lateral vs. vertical approach) without full teleoperation.
- Interactive proposal selection UI for supervisors to choose from diverse on-manifold action candidates.
- Assumptions/dependencies:
- Operator access to an interface; basic training to understand proposals.
- Vision and proprioception fidelity adequate to learn compact latent representations.
- Precision assembly tasks and fixture adaptation (Manufacturing, Electronics)
- Tools/products/workflows:
- “Safe exploration mode” during line setup/retooling: structured variation within valid latents for part insertion/alignment (akin to Lamp Cap task).
- Farthest Point Sampling (FPS) over proposal batches to cover diverse yet feasible action modes for operator review.
- Assumptions/dependencies:
- Resettable environments to safely iterate.
- Tight tolerances may require smaller α and robust sensing/calibration.
- Hotel/restaurant service robots for object placement and handling (Service Robotics)
- Tools/products/workflows:
- On-manifold exploration for gentle, coherent motions when handling cups, dishes, or cutlery (similar to Mug Hang patterns).
- Policy refinement with small batches of successful self-collected rollouts to adapt to new layouts.
- Assumptions/dependencies:
- Risk controls (geofencing, runtime safety checks) to contain exploration.
- Consistent object appearances; manageable clutter and occlusions.
- Assistive/home robots improving task reliability without unsafe trial-and-error (Healthcare, Consumer Robotics)
- Tools/products/workflows:
- Human-guided latent steering to bias motions toward safer trajectories (lower jerk), reducing strain on users and the device.
- Lightweight smartphone/tablet UI for proposal selection in kitchen or caregiving tasks (e.g., loading appliances).
- Assumptions/dependencies:
- Base policy competence and reliable sensor input in homes (variable lighting, surfaces).
- Safety constraints and fallback controls; potentially slower exploration schedules.
- Academic research and teaching: reduce teleoperation burden in robot learning courses (Academia, Education)
- Tools/products/workflows:
- Open-source training recipes integrating SOE and Diffusion Policy for few-shot learning labs.
- Built-in metrics suite: Pass@k, jerk, rollout counts; ablation scripts for α, β, and latent dimension sizes.
- Assumptions/dependencies:
- Access to common robot platforms (Franka, UR, Flexiv) and camera setups.
- GPU resources; students trained to interpret latent dimensions and SNR.
- Software tooling for interpretability and structured exploration (Software, MLOps)
- Tools/products/workflows:
- Libraries for VIB-based latent encoders/decoders, SNR-based dimension ranking, FPS sampling, and dual-path training objectives.
- Integration adapters for popular policy models (e.g., diffusion-based, transformer-based visuomotor policies).
- Assumptions/dependencies:
- PyTorch/industrial ML stack compatibility.
- Clear API boundaries so the plug-in doesn’t degrade base policy performance.
- Internal safety governance for robot learning deployments (Policy within organizations)
- Tools/products/workflows:
- SOPs for exploration control: cap α, monitor jerk thresholds, accept only successful rollouts into datasets, log exploration traces.
- Review gates for multi-round self-improvement (risk audits per round).
- Assumptions/dependencies:
- Organizational buy-in; clear data retention and audit procedures.
- Safety team capacity to evaluate exploration metrics and thresholds.
- Energy and equipment wear reduction via fewer interactions (Energy, Sustainability)
- Tools/products/workflows:
- SOE-enabled training schedules that target higher Pass@k with fewer rollout attempts.
- Maintenance dashboards linking interaction counts to wear/tear and energy consumption.
- Assumptions/dependencies:
- Ability to instrument energy and usage metrics; clear baselines for comparison.
Long-Term Applications
The following opportunities will likely require further R&D, scaling, formal verification, or domain-specific adaptation before deployment.
- Lifelong, general-purpose self-improving robots (Robotics, Consumer and Industrial)
- Potential tools/products/workflows:
- Cloud-managed self-improvement platforms that aggregate successful on-manifold rollouts across diverse tasks and environments.
- Continuous learning pipelines with automatic task detection and curriculum sequencing using intrinsic latent dimensions.
- Assumptions/dependencies:
- Robust cross-task generalization and stable latent disentanglement at scale.
- Privacy, safety, and data governance across fleets and sites.
- Autonomous industrial line changeovers with minimal demos (Manufacturing)
- Potential tools/products/workflows:
- Robots that automatically adapt insertion, fastening, and delicate manipulation through structured exploration when parts or fixtures change.
- Uncertainty-aware exploration controllers that adjust α/β based on real-time safety monitors.
- Assumptions/dependencies:
- Strong uncertainty estimation, runtime safety certification, and formal risk bounds.
- High-fidelity perception and calibration; domain adaptation for different materials.
- Sector-wide safety and certification frameworks for on-manifold exploration (Policy, Standards)
- Potential tools/products/workflows:
- Standardization of exploration metrics (e.g., jerk, Pass@k) and thresholds for different sectors.
- Certification protocols requiring structured exploration (manifold constraints) over naive random perturbations.
- Assumptions/dependencies:
- Multi-stakeholder consensus; evidence across varied robot platforms and tasks.
- Alignment with existing standards (e.g., ISO 10218, ISO 13482).
- Surgical and micro-manipulation robotics with structured exploration (Healthcare)
- Potential tools/products/workflows:
- Verified latent steering for extremely precise, contact-rich procedures (microsuturing, endoscopic manipulation).
- Closed-loop safety monitors enforcing manifold constraints with deterministic guarantees.
- Assumptions/dependencies:
- Formal verification of safety and compliance; ultra-reliable sensors and actuators.
- Domain-specific latents with causal mapping to clinical factors.
- Safe exploration in autonomous vehicles and aerial robots (Mobility, Drones)
- Potential tools/products/workflows:
- On-manifold action sampling (e.g., within verified vehicle dynamics envelopes) for adaptation to novel conditions.
- Simulator-to-real pipelines that learn task-relevant latents specific to mobility domains.
- Assumptions/dependencies:
- Domain-specific manifold modeling and formal reachability/verification.
- Tight integration with control and perception stacks; rigorous testing on edge cases.
- Multi-robot shared latent manifolds and fleet-level steering (Robotics, Operations)
- Potential tools/products/workflows:
- Shared representation learning enabling cross-robot transfer of effective latent dimensions and exploration policies.
- Fleet dashboards for human-guided steering of teams (e.g., warehouse fleets) via semantically meaningful latents.
- Assumptions/dependencies:
- Communication protocols, representation compatibility, and robust transfer learning.
- Embodied foundation models with VIB-backed exploration (Software, AI Platforms)
- Potential tools/products/workflows:
- Scaled visuomotor models (e.g., VLA-style) incorporating SOE-like bottlenecks for safe, structured exploration across tasks.
- Public datasets of on-manifold rollouts curated by automated success filters.
- Assumptions/dependencies:
- Massive data and compute; scaling laws; heterogeneous sensor suites.
- Automated semantic mapping of latent dimensions (Interpretability, HCI)
- Potential tools/products/workflows:
- Pipelines that label and calibrate latent dimensions to human-understandable factors (position, orientation, approach strategy).
- Human-in-the-loop tools that auto-suggest meaningful steering axes per task.
- Assumptions/dependencies:
- Advances in causal discovery and interpretability; robust SNR-based selection across complex tasks.
- Formal safety guarantees for structured exploration (Verification, Control)
- Potential tools/products/workflows:
- Mathematical tools (reachability analysis, barrier certificates) adapted to latent-space constraints and action chunking.
- Runtime monitors that enforce verified safety constraints during exploration.
- Assumptions/dependencies:
- Theory and tooling for high-dimensional latent spaces; certified controllers.
- Domain-specific SOE toolkits (Healthcare, Precision Manufacturing, Food Processing)
- Potential tools/products/workflows:
- Preconfigured latents, α/β schedules, and proposal generation tuned to sector requirements and compliance standards.
- Plug-in modules for sector-specific policy models and sensors (e.g., force/torque, tactile).
- Assumptions/dependencies:
- Tailored datasets and integration with specialized hardware; regulatory alignment.
Notes on cross-cutting assumptions and dependencies:
- The base policy must be sufficiently competent to benefit from structured exploration; SOE enhances exploration, not fundamental capability.
- Reliable sensing and action chunking interfaces are required to learn task-relevant latents.
- Exploration safety depends on the validity of the learned manifold; out-of-distribution observations or severe sensor noise can degrade performance.
- Hyperparameters (α for exploration scale, β for KL regularization) and prior choices (e.g., isotropic Gaussian) affect stability and diversity; tuning is task-dependent.
- Human-guided steering assumes accessible UI, operator familiarity, and time to review proposals; automated steering will require further interpretability advances.
Glossary
- Action chunk: A temporally grouped sequence of low-level control commands executed as a unit. "Each action chunk spans steps"
- Action mode collapse: When a policy produces only one or a few similar behaviors instead of diverse modes, limiting exploration. "due to action mode collapse."
- Behavior cloning: An imitation learning method that maps observations to actions by supervised learning on expert demonstrations. "such as behavior cloning, directly learn a mapping"
- Boltzmann exploration: A stochastic action selection strategy that samples actions according to a softmax over their values. "Boltzmann exploration~\cite{sutton2005reinforcement, szepesvari2022algorithms}"
- Cartesian space: A control space where end-effector motions are specified in XYZ position and orientation coordinates. "The robot is controlled in Cartesian space at 10 Hz."
- Compounding error: Accumulation of small prediction errors over time during policy rollout, degrading performance. "compounding error~\cite{ross2011reduction}"
- DDIM (Denoising Diffusion Implicit Models): A deterministic sampler for diffusion models that accelerates generation while preserving quality. "DDIM~\cite{song2020denoising} as the scheduler."
- Diffusion Policy: A policy class that models action sequences via denoising diffusion processes for multimodal action generation. "Diffusion Policy already achieves near-perfect performance"
- Disentangled latent space: A representation where different latent dimensions control distinct, interpretable factors of variation. "action chunks are naturally disentangled into distinct modes."
- Distributional bias: Mismatch between training and deployment distributions due to limited or skewed demonstrations. "resulting in distributional bias~\cite{zhang2025scizor}"
- End-effector: The tool-tip of a robotic manipulator (e.g., gripper) whose pose/trajectory is controlled. "average jerk of the end-effector trajectory"
- Epsilon-greedy: An exploration strategy that selects a random action with probability ε and the best-known action otherwise. "epsilon-greedy~\cite{mnih2013playing, van2016deep}"
- Extrapolation errors: Errors arising when a policy or value function is evaluated on out-of-distribution states or actions. "extrapolation errors~\cite{kostrikov2021offline}"
- Farthest point sampling (FPS): A sampling method that selects points maximizing mutual distances to ensure diversity. "apply farthest point sampling (FPS) to select a diverse subset"
- Flow-based generative models: Likelihood-based models that transform simple base distributions into complex ones via invertible mappings. "flow-based generative models~\cite{janner2022planning, chi2023diffusion, ajay2022conditional, ze20243d, wang2024rise}"
- Goal-directed exploration: Exploration guided by target goals to efficiently gather informative experiences. "goal-directed exploration~\cite{hu2023planning}"
- Human-in-the-loop: Methods that incorporate human feedback or selection during training or exploration. "human-in-the-loop approaches~\cite{luo2025precise, chen2025conrft}"
- Imitation learning: Learning a policy by mimicking expert demonstrations instead of relying on explicit reward signals. "Imitation learning is an extensively studied approach"
- Intrinsic rewards: Internally computed rewards (e.g., novelty/curiosity) used to encourage exploration. "introducing some intrinsic rewards"
- Isotropic Gaussian: A Gaussian distribution with identical variance in all dimensions. "is chosen as a -dimensional isotropic Gaussian "
- Jerk (trajectory): The third derivative of position with respect to time; a measure of motion smoothness. "average jerk of the end-effector trajectory"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from a reference distribution. "KL regularization"
- Latent space: A compressed representation space where salient task factors are encoded. "in the latent space, action chunks are naturally disentangled"
- Manifold of valid actions: The low-dimensional subset of the action space corresponding to feasible, safe, task-relevant actions. "manifold of valid actions"
- Mutual information: A measure of shared information between two random variables. "where denotes mutual information"
- Offline RL: Reinforcement learning using a fixed dataset without further environment interaction. "offline RL~\cite{fujimoto2019off, kumar2020conservative, kostrikov2021offline}"
- On-manifold exploration: Restricting exploration to the learned task manifold to maintain realism, safety, and effectiveness. "on-manifold exploration"
- Pass@5: The probability of achieving at least one success within five attempts from the same start. "Pass@5, the probability of achieving at least one success within five attempts"
- Proprioceptive states: Internal robot state measurements such as joint positions, velocities, or gripper status. "along with proprioceptive states."
- Rejection sampling fine-tuning (RFT): Post-training by sampling candidate outputs and training on those that pass a selection criterion. "rejection sampling fine-tuning (RFT)"
- Residual policy learning: Learning a corrective policy that adds to a base policy to improve performance. "residual policy learning~\cite{yuan2024policy, haldar2023teach}"
- RoboMimic: A benchmark suite for learning robot manipulation from demonstrations. "RoboMimic~\cite{mandlekar2021matters}"
- Sample efficiency: The degree to which a method achieves high performance with few environment interactions. "superior sample efficiency."
- Signal-to-noise ratio (SNR): A measure comparing the magnitude of a desired signal to the background noise. "signal-to-noise ratio (SNR) criterion"
- Sim-to-real transfer: Transferring policies trained in simulation to real robots. "sim-to-real transfer~\cite{ankile2024imitation,lv2023sam}"
- Variational information bottleneck (VIB): A learning objective that compresses representations while retaining task-relevant information. "through a variational information bottleneck (VIB)"
- Variational upper bound: A tractable bound used to approximate or optimize information-theoretic objectives. "a tractable variational upper bound"
- Visuomotor behaviors: Sensorimotor control policies that map visual inputs to motor actions. "By modeling visuomotor behaviors with neural networks"
Collections
Sign up for free to add this paper to one or more collections.