Video Killed the Energy Budget: Characterizing the Latency and Power Regimes of Open Text-to-Video Models
Abstract: Recent advances in text-to-video (T2V) generation have enabled the creation of high-fidelity, temporally coherent clips from natural language prompts. Yet these systems come with significant computational costs, and their energy demands remain poorly understood. In this paper, we present a systematic study of the latency and energy consumption of state-of-the-art open-source T2V models. We first develop a compute-bound analytical model that predicts scaling laws with respect to spatial resolution, temporal length, and denoising steps. We then validate these predictions through fine-grained experiments on WAN2.1-T2V, showing quadratic growth with spatial and temporal dimensions, and linear scaling with the number of denoising steps. Finally, we extend our analysis to six diverse T2V models, comparing their runtime and energy profiles under default settings. Our results provide both a benchmark reference and practical insights for designing and deploying more sustainable generative video systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how long it takes and how much energy it uses for AI models to turn text into short videos. These “text-to-video” models can make impressive, realistic clips, but they can also be slow and power-hungry. The authors build a simple way to predict the time and energy these models need, test those predictions on real hardware, and compare several popular open-source video models to see which ones are faster or more energy-efficient.
What questions did the paper ask?
- How do time and energy costs change when you make a video bigger (higher resolution), longer (more frames), or run more “polishing” passes (called denoising steps)?
- Can we predict those costs with a simple formula that counts how much math the model does?
- How do different open-source text-to-video models compare in real use, in terms of speed and energy?
How did they study it?
Think of the model as a factory making a flipbook:
- Resolution = how big each page is (number of pixels).
- Frames = how many pages are in the flipbook.
- Denoising steps = how many times you go over the drawing to clean it up.
The team did two things:
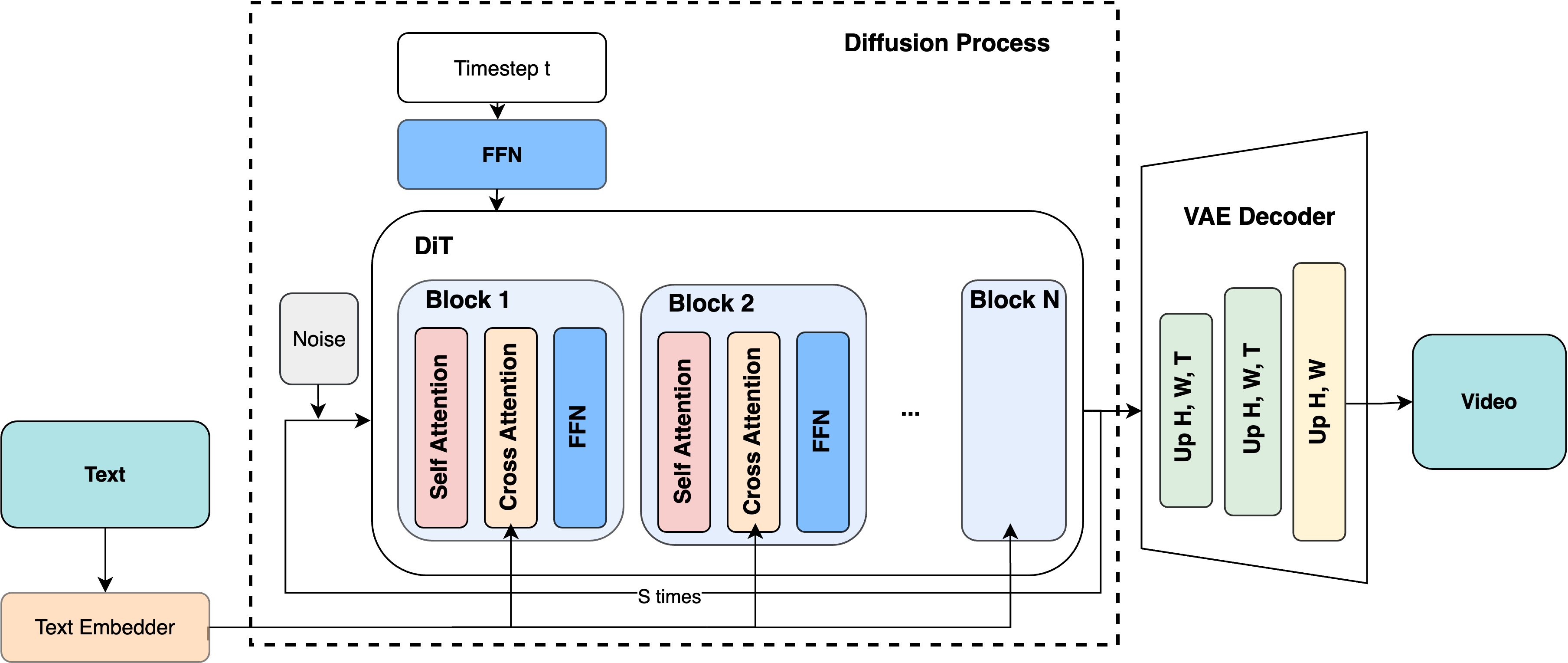
- Built a prediction model: They added up the model’s “amount of math” (FLOPs), like counting how many push-ups a workout has. They assumed the limiting factor is how fast the GPU can calculate (compute-bound), not how fast it can fetch data.
- Ran careful tests: They used a strong GPU (NVIDIA H100) and measured time and energy (with CodeCarbon) while changing one thing at a time: resolution, number of frames, or denoising steps. Then they repeated this for six more popular video models to see how they compare.
Key terms explained simply:
- Attention/Transformer: The brainy part that decides how different parts of the video relate to each other. It’s powerful but expensive (lots of math).
- Denoising steps: Repeated passes that refine the video, like adding more coats of paint for a smoother finish.
- Compute-bound: The GPU is mostly busy crunching numbers; the bottleneck is math speed, not waiting for memory or the CPU.
- FLOPs: A rough count of how much math is done. More FLOPs = more time and energy.
What did they find?
Here are the big takeaways, explained with everyday language:
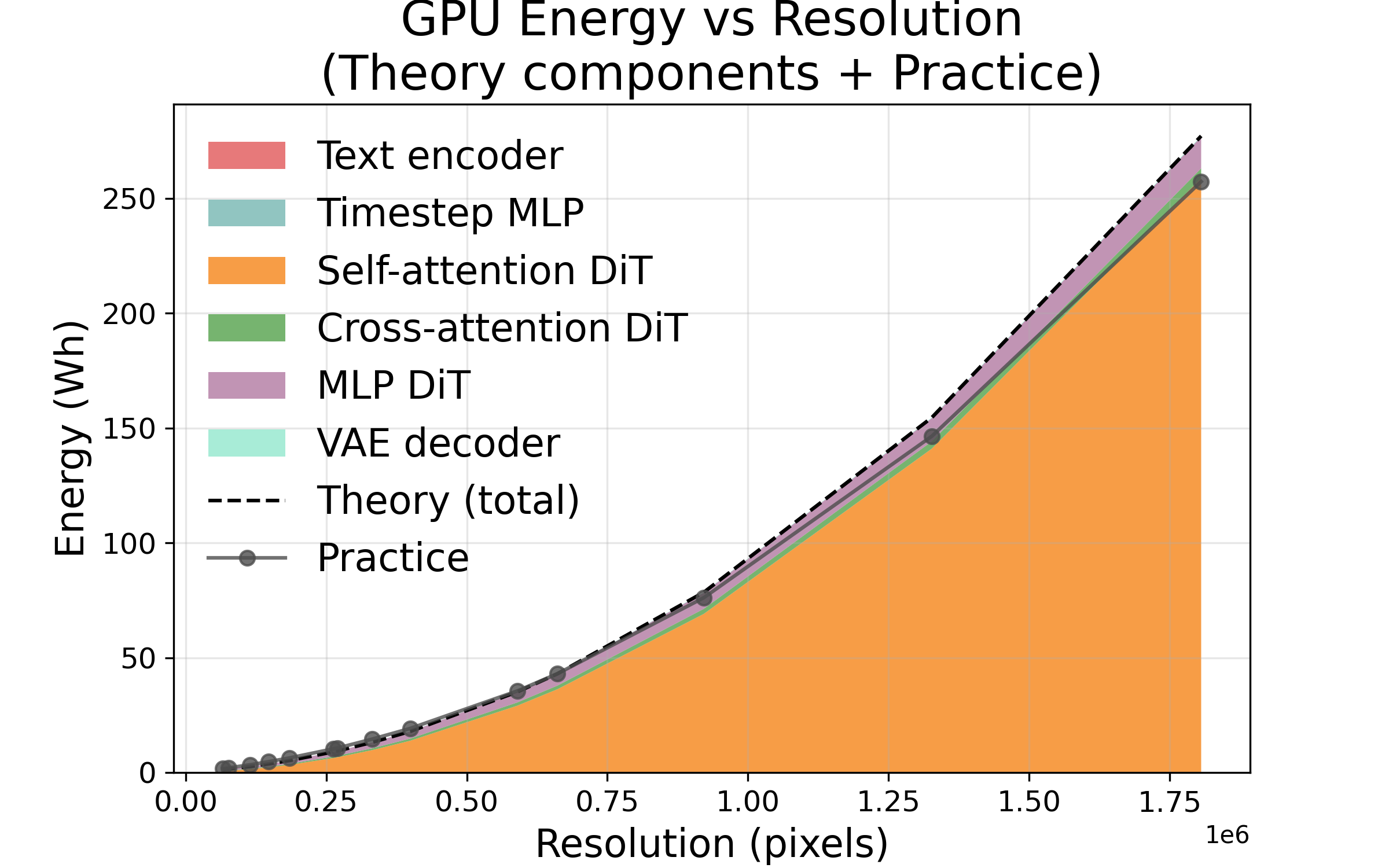
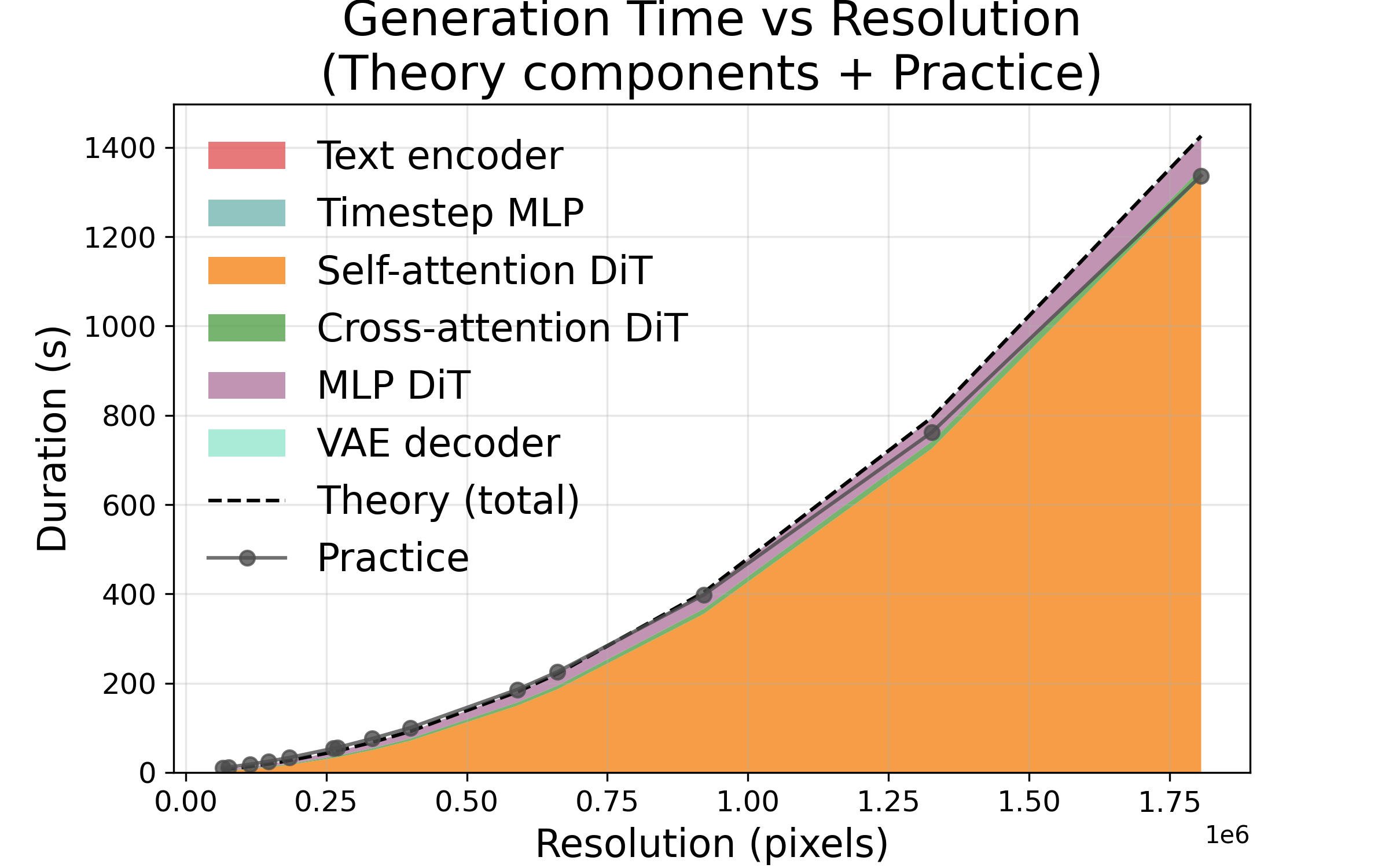
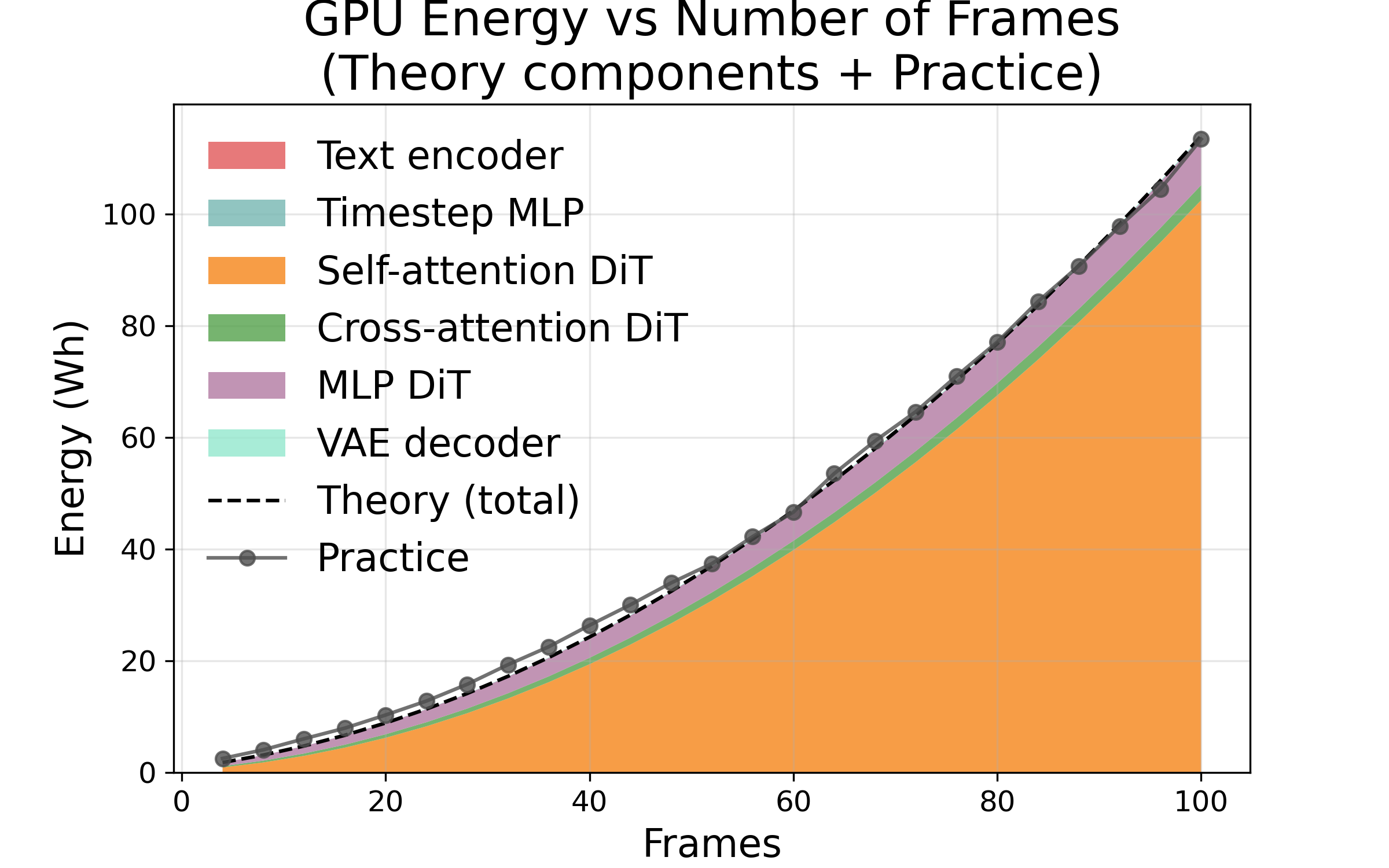
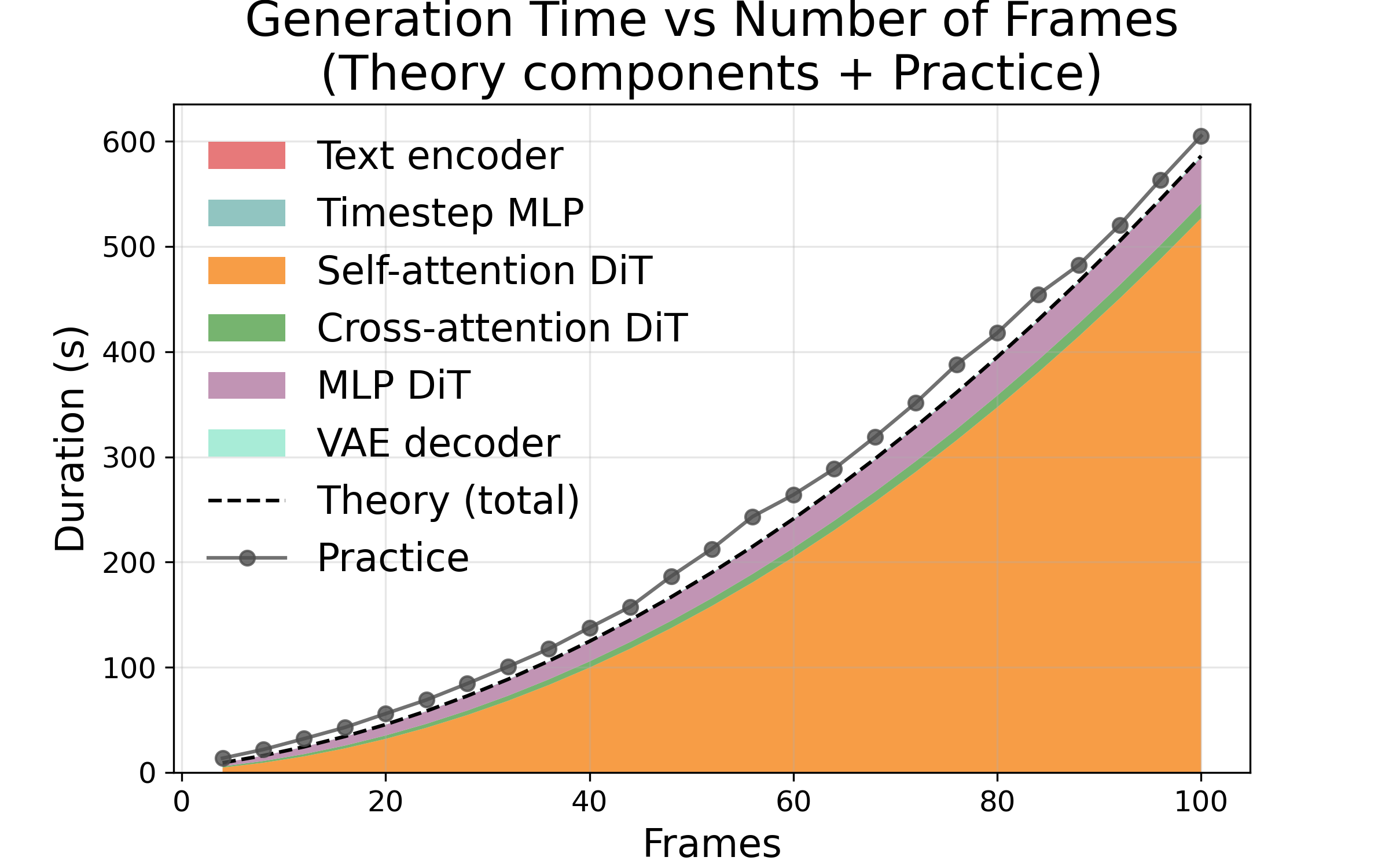
- Doubling any one of resolution height, resolution width, or number of frames makes time and energy go up about 4×. Why? Because the “attention” math grows fast as you add more pixels or frames. If you double both height and width together, that’s about 16× more cost.
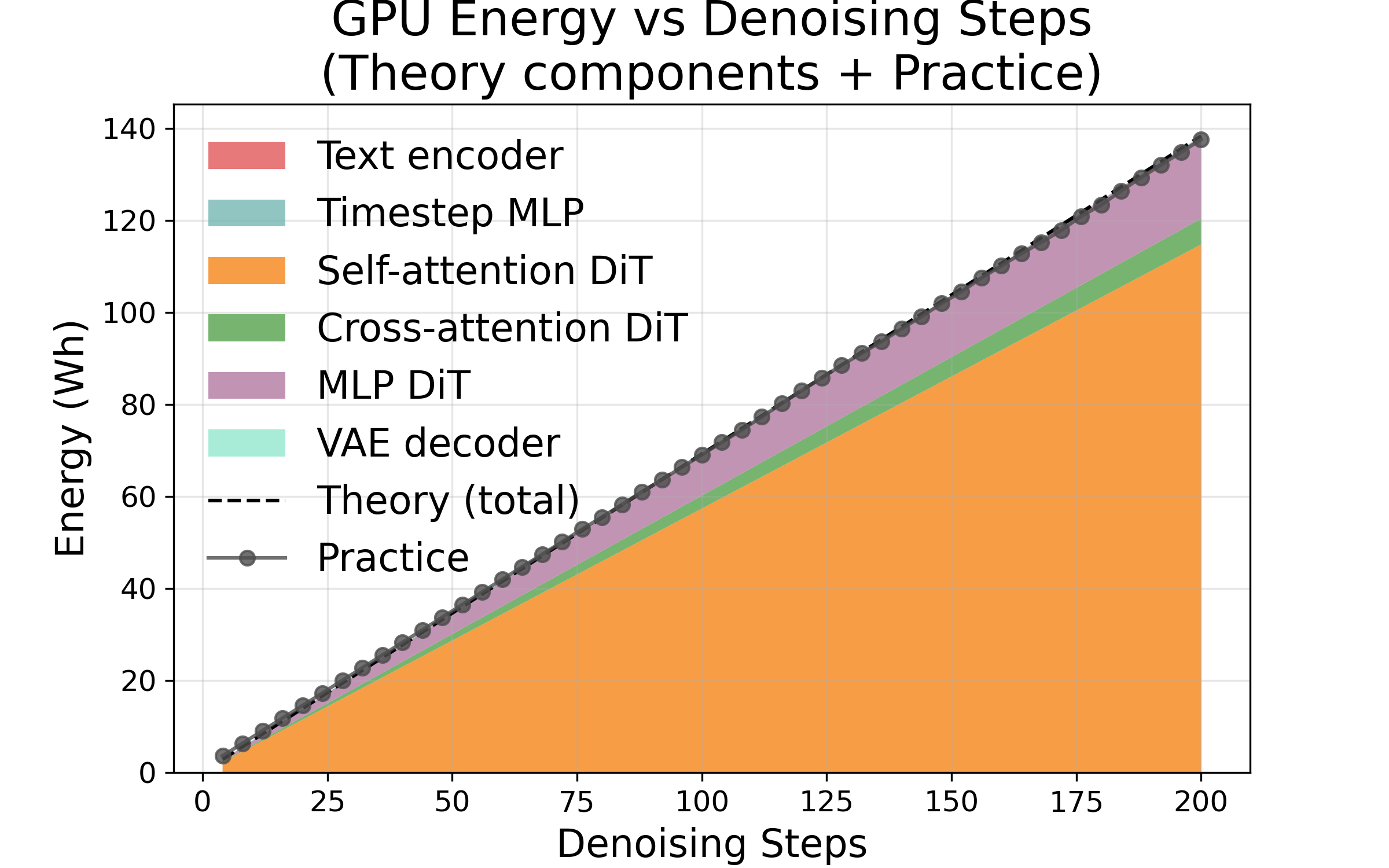
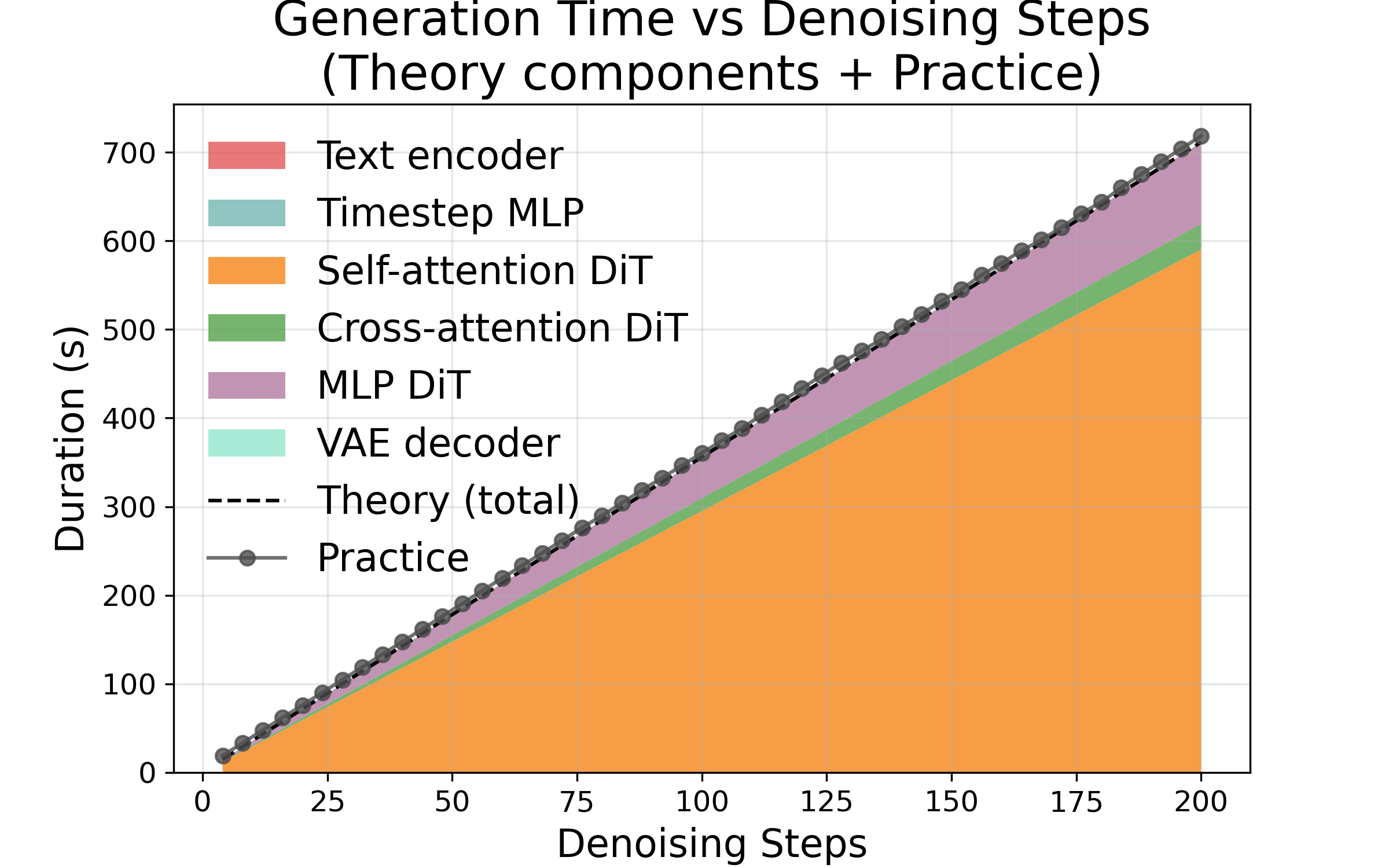
- Adding more denoising steps increases cost in a straight line. If you double the steps, time and energy roughly double. This makes steps a reliable “speed vs. quality” dial.
- Most of the energy (over 80%) is used by the GPU, not the CPU or RAM. That means the heavy lifting is really in the number crunching.
- The prediction model matches real measurements very closely. Errors were small (about 2% for steps, around 7–14% for frames/resolution).
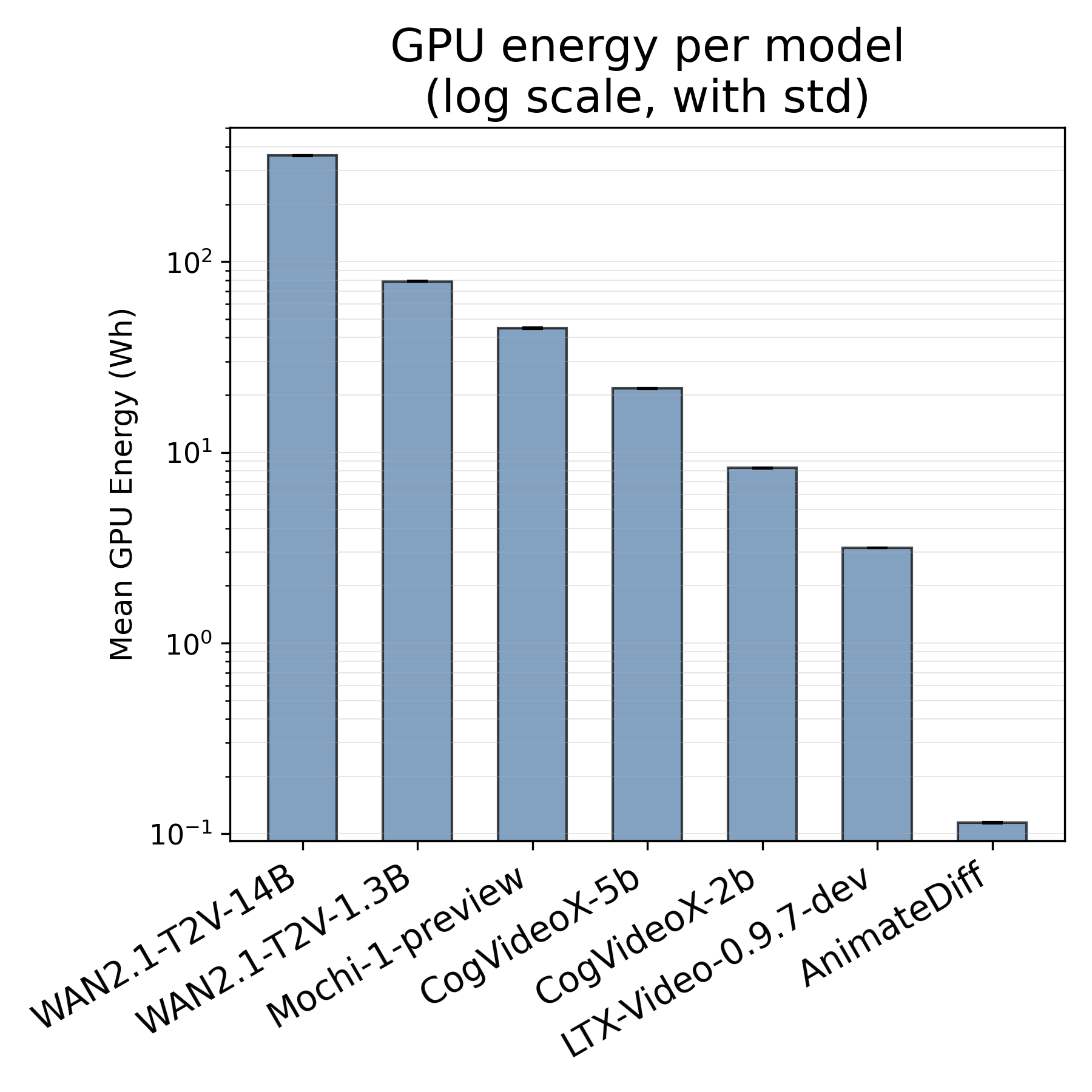
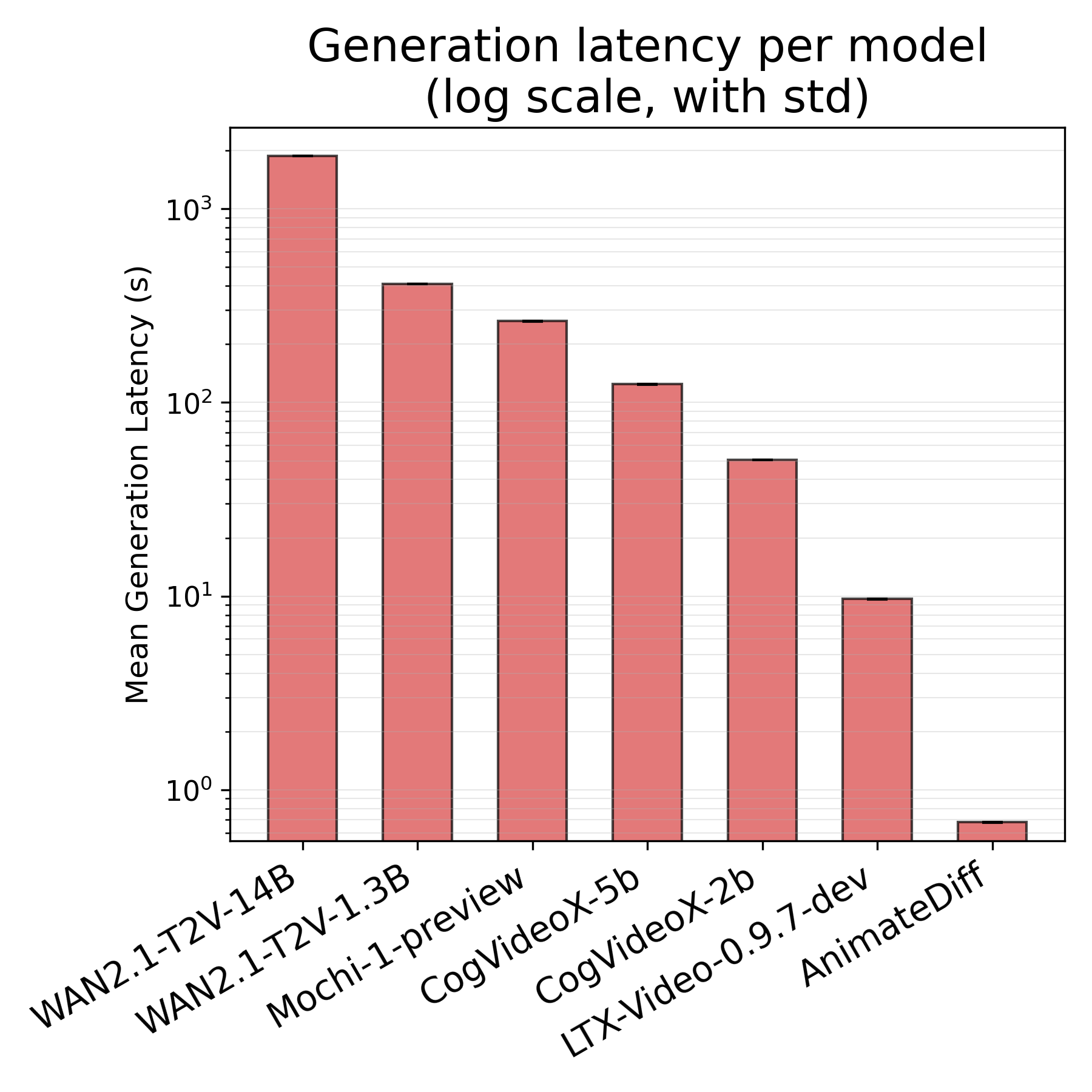
- Different models vary a lot:
- Lightweight models like AnimateDiff can make a short video quickly and use very little energy (about 0.1 Wh per clip in their setup).
- Big models like WAN2.1-T2V-14B can take a long time and use hundreds of watt-hours (around 400+ Wh per clip), which is thousands of times more.
- Mid-size models fall in between (for example, WAN2.1-T2V-1.3B used around 79 Wh per clip in their tests).
Why this matters:
- Video generation is far more energy-intensive than text or even image generation. A short video can cost tens to hundreds of watt-hours, which is much larger than most everyday AI tasks.
Why does it matter? (Implications and impact)
- Practical choices save a lot:
- Lower resolution and fewer frames give huge energy and time savings (e.g., halving both height and width can cut cost by ~16×).
- Fewer denoising steps reduce cost in a predictable, linear way (half the steps ≈ half the cost).
- Product design: Apps and APIs should offer “quality presets” (like low/medium/high) so users can pick faster, greener options when they don’t need cinema-quality results.
- Research directions: Techniques like diffusion caching (reusing repeated work), low-precision math (quantization), fewer steps, and smarter attention can cut costs without hurting quality much.
- Sustainability: As video AI becomes more common, careful design is essential to keep energy use and environmental impact in check.
Limitations to keep in mind
- Tests were on one type of high-end GPU; results should generalize but need broader confirmation.
- The study focused on speed and energy, not video quality. Balancing quality vs. energy is an important next step.
- Some advanced optimizations (like caching and mixed-precision) weren’t fully enabled in all open-source code, so real-world systems might do better with extra tuning.
In short: The paper shows that text-to-video AI is mainly limited by raw computation, not memory, and that cost grows very fast with video size and length but only linearly with the number of refinement steps. This gives clear, simple levers for building faster and greener video generation systems.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, concise list of concrete gaps and open questions that the paper leaves unresolved and that future researchers can address.
- Cross-model comparability: Benchmark models under matched output specifications (same resolution, aspect ratio, frames, FPS, steps, CFG settings) to produce apples-to-apples energy and latency comparisons; report normalized metrics such as energy per megapixel-second and energy per second of 24/30 FPS video.
- Scheduler effects: Systematically test different samplers and schedules (e.g., DDIM, DPM-Solver, UniPC, Heun) to quantify how they deviate from linear step scaling and affect energy–quality trade-offs.
- Classifier-free guidance optimization: Evaluate alternatives to two-pass CFG (g=2), including one-pass/approximate guidance, partial caching across cond/uncond, and guidance-free regimes; quantify energy savings vs. perceptual quality changes.
- KV/diffusion caching: Implement and measure KV caching in cross-attention and diffusion caching across steps/frames; quantify latency/energy reductions and identify failure cases or degradation in fidelity.
- Quantization and sparsity: Empirically assess FP8/INT8 mixed precision (and more aggressive 4-bit quantization, structured sparsity) on T2V inference; report energy/latency gains and any quality loss across diverse prompts and resolutions.
- Attention variants: Test windowed/factorized/low-rank attention or temporal attention pruning to determine when sub-quadratic scaling emerges; characterize regimes and provide practical guidelines for parameterization.
- Operator-level measurement: Move beyond theoretical stacked areas and collect measured time/energy per operator (self-attn, cross-attn, MLP, VAE) using profilers; identify dominant real bottlenecks and verify which kernels are memory- vs compute-bound.
- Memory hierarchy and bandwidth: Instrument HBM bandwidth, cache hit rates, and memory stalls (Nsight Compute/Systems) to refine the roofline-based model; explicitly model and validate deviations for small token lengths or extreme aspect ratios.
- Hardware generalization: Replicate experiments across accelerators (RTX 4090, L4, A100, TPU v6, Gaudi3, AMD GPUs) to empirically confirm compute-bound thresholds and calibrate μ per device; provide a portable predictor for latency/energy.
- Multi-GPU/distributed inference: Study tensor/sequence/data parallel inference for large models (e.g., 14B), including interconnect overhead; quantify energy per video and efficiency scaling vs single-GPU baselines.
- Batching and concurrency: Evaluate multi-video batching, stream overlap, and scheduling policies; measure their effects on GPU utilization (μ), per-video energy, and throughput in API-like workloads.
- Full pipeline accounting: Include energy of video container encoding (H.264/H.265), decoding, I/O, storage writes, post-processing (upscaling, stabilization), and audio generation; report component shares and optimization targets.
- Audio generation coupling: Quantify energy/latency of joint audio–video generation pipelines and their scaling laws; explore synchronization and conditioning strategies that minimize additional compute.
- Carbon accounting and uncertainty: Convert energy to CO2e with location-specific carbon intensity; include PUE/cooling overhead and wall-plug measurements (PDU/in-line meters) to validate CodeCarbon/NVML estimates; report uncertainty bounds.
- Prompt conditioning effects: Vary text encoder length beyond fixed 512 tokens, and test multi-modal conditioning (e.g., control signals like depth/optical flow); measure impacts on energy and latency.
- Aspect ratio extremes: Systematically probe ultra-wide/tall and non-divisible-by-8 dimensions; characterize where the analytical model’s error rises and update it to account for kernel tiling/misalignment.
- Energy–fidelity Pareto frontiers: Establish standardized quality metrics (e.g., FVD, temporal consistency, aesthetic scores) and map energy–quality curves across models/settings to guide sustainable deployment choices.
- Step pruning and distillation: Evaluate progressive distillation or step-pruned samplers to reduce S while maintaining quality; quantify savings and identify best-performing configurations per output spec.
- VAE costs and alternatives: Precisely measure VAE contributions at high resolutions/long durations; test more efficient decoders or learned codecs; assess trade-offs of latent grid design on energy.
- FPS normalization: Analyze how FPS choices (8, 15, 24, 30) affect energy per second of real-time playback; recommend standardized FPS to enable fair comparisons and user presets.
- Model-specific analytic scaling: Derive and calibrate FLOP/latency models for non-diffusion architectures (e.g., autoregressive LTX-Video, cascaded CogVideoX); validate scaling with respect to H, W, T, S in these regimes.
- μ calibration across models: Provide per-model empirical efficiency (μ) and operator constants so practitioners can predict energy/latency for arbitrary H, W, T, S, g, N, d without running full experiments.
- Seed/software sensitivity: Quantify variability due to random seeds, CUDA/PyTorch/FlashAttention versions, kernel fusion settings; publish reproducibility guidance for energy tests.
- Service-level scenario modeling: Project energy and carbon costs under realistic API usage (clip durations, resolutions, throughput targets); explore capacity planning and scheduling policies that minimize environmental impact.
Practical Applications
Immediate Applications
The following applications can be adopted now by product teams, infrastructure operators, researchers, and practitioners, leveraging the paper’s validated scaling laws (quadratic in spatial/temporal dimensions; linear in denoising steps), the compute-bound regime on modern GPUs, and the cross-model benchmarking data.
- Energy-aware generation presets in creative and T2V tools
- Description: Offer “Eco,” “Standard,” and “High-Fidelity” presets that programmatically control resolution (H×W), frames (T), and denoising steps (S) to keep energy within a budget while meeting user quality needs.
- Sectors: Software (creative tools), Media/Entertainment, Advertising.
- Tools/Products/Workflows: UI toggles linked to backend controllers; preflight estimators using the analytical FLOPs model; configuration profiles in Diffusers/PyTorch.
- Assumptions/Dependencies: Compute-bound regime holds at typical token lengths; users accept quality trade-offs; empirical efficiency µ must be calibrated per hardware.
- API pricing, SLAs, and cost forecasting
- Description: Use the analytical FLOPs-to-latency/energy model to quote price, delivery time, and expected energy per request based on (H, W, T, S).
- Sectors: Cloud/SaaS, Developer Platforms, Finance (cost allocation), Procurement.
- Tools/Products/Workflows: Pricing tiers tied to resolution/length/steps; in-API “cost preview”; SLOs that expose latency and carbon budgets.
- Assumptions/Dependencies: Reliable µ per hardware; local energy prices and grid emission factors; workload mix stability.
- Capacity planning and GPU scheduling
- Description: Predict GPU-hours and energy to plan fleet capacity, queueing, and carbon-aware scheduling (e.g., defer high-cost jobs to cleaner grid windows).
- Sectors: Cloud, MLOps/DevOps, Data Center Operations, Energy.
- Tools/Products/Workflows: Scheduler integrating the model’s scaling laws; carbon-aware orchestration; admission control based on (H, W, T, S).
- Assumptions/Dependencies: Accurate power draw near Pmax during inference; access to real-time grid CO2 signals; user tolerance for delayed jobs.
- Model selection and two-pass pipelines
- Description: Use cross-model benchmarks to pick lightweight models (e.g., LTX-Video, CogVideoX-2b) for drafts and escalate to heavier models (e.g., WAN2.1-14B) only when needed.
- Sectors: Media Production, Marketing, Education (course/video creation), Software.
- Tools/Products/Workflows: “Draft → Refine” pipelines; automated gating by quality heuristics; per-shot model switching.
- Assumptions/Dependencies: Draft models meet minimum quality; switching overhead acceptable; content style compatible across models.
- Energy and carbon labeling in end-user apps
- Description: Display estimated energy and CO2 for each generated video, encouraging low-impact choices (shorter clips, lower resolution, fewer steps).
- Sectors: Consumer Apps, Education, Policy/Compliance.
- Tools/Products/Workflows: CodeCarbon integration; per-generation CO2 labels; user nudges and “eco-mode.”
- Assumptions/Dependencies: Accurate emission factors; user privacy/compliance; simple UX that does not overwhelm.
- Hardware-aware inference placement
- Description: Route jobs to GPU classes (e.g., H100 vs L4) based on predicted token lengths and compute/bandwidth balance, maximizing throughput and minimizing energy.
- Sectors: Cloud, MLOps, Infrastructure.
- Tools/Products/Workflows: Hardware profiles with β (FLOP-to-bandwidth ratio); policy-based routing; per-queue hardware selection.
- Assumptions/Dependencies: Up-to-date hardware capability data; reliable inference kernels; workload size known at submission.
- Low-precision inference and KV caching (where available)
- Description: Adopt mixed precision (FP8/INT8) and cross-attention KV caching to cut FLOPs and memory transfers without major quality loss.
- Sectors: Software, Cloud, Robotics Sim (previsualization), Education.
- Tools/Products/Workflows: TensorRT/torchao quantization flows; enabling KV caches in cross-attention; regression tests for fidelity.
- Assumptions/Dependencies: Hardware support; acceptable accuracy; current model code paths support caching (the paper notes WAN2.1 OSS recomputes K/V).
- Practical energy-saving guidance for creators and teams
- Description: Publish “rules of thumb” derived from quadratic/linear scaling (e.g., halving resolution or frames can save ~4× energy; halving steps saves ~2×).
- Sectors: Daily Life (content creators), Education, Nonprofits.
- Tools/Products/Workflows: Checklists; internal playbooks; energy calculators embedded in editing suites.
- Assumptions/Dependencies: Quality thresholds defined; teams trained to evaluate trade-offs.
- Benchmark-driven procurement and governance
- Description: Use the paper’s cross-model energy/latency profiles to inform procurement choices, internal policies, and model governance (e.g., default to low-cost models for non-critical use).
- Sectors: Policy/Compliance, Enterprise IT, Finance.
- Tools/Products/Workflows: Sustainability scorecards; “approved model” lists; risk registers including energy overhead.
- Assumptions/Dependencies: Organization-wide buy-in; periodic re-benchmarking as models evolve.
Long-Term Applications
These applications require further research, engineering, standardization, or ecosystem adoption to achieve reliable, scalable deployment.
- Architectural innovations to break quadratic scaling
- Description: Research and deploy windowed/factorized attention, token downsampling, spatiotemporal sparsity, or latent-grids that reduce the O(ℓ²) terms driving energy growth.
- Sectors: Academia, Software, Robotics (sim), Media Tech.
- Tools/Products/Workflows: New DiT variants; training recipes; evaluation suites balancing fidelity and efficiency.
- Assumptions/Dependencies: Comparable or better video quality; retraining at scale; community uptake.
- Diffusion caching and step-level reuse
- Description: Productize caching of attention/CFG activations across steps (noted by the paper as promising), reducing per-step compute without regressing quality.
- Sectors: Software, Cloud, Creative Tools.
- Tools/Products/Workflows: Cache managers; memory budget optimizers; cache consistency validators.
- Assumptions/Dependencies: Memory overhead tolerable; cache hit rates high enough; reproducibility and determinism handled.
- Standardized energy metrics and “Energy Model Cards”
- Description: Establish common reporting (µ, Pmax, FLOPs by operator, test suite) for T2V energy and latency to enable fair comparison and compliance.
- Sectors: Policy/Standards, Academia, Industry Consortia.
- Tools/Products/Workflows: Model cards with energy sections; reproducible benchmark harnesses; third-party certification.
- Assumptions/Dependencies: Industry consensus; stable measurement methodologies; multi-hardware coverage.
- Carbon labeling norms and regulation
- Description: Policies requiring per-generation energy/CO2 disclosures for AI media tools; incentives for “eco presets.”
- Sectors: Policy/Government, Compliance, Consumer Protection.
- Tools/Products/Workflows: Regulatory frameworks; open registries; audit processes.
- Assumptions/Dependencies: Legislative appetite; harmonized emission factors; privacy considerations.
- Hardware co-design for video diffusion
- Description: Develop accelerators and memory hierarchies optimized for DiT-like attention and MLP workloads at high token counts, improving µ and reducing Pmax.
- Sectors: Semiconductors, Cloud, Edge Devices.
- Tools/Products/Workflows: Compiler/kernel co-design; SRAM/DRAM balance for attention; FlashAttention-like primitives in silicon.
- Assumptions/Dependencies: Market demand; fabrication cycles; software stack alignment.
- AutoML for energy-quality trade-offs
- Description: Controllers that dynamically select (H, W, T, S), model variants, and schedulers per prompt to meet target energy/latency constraints while achieving minimum quality.
- Sectors: MLOps, Creative Platforms, Education.
- Tools/Products/Workflows: Multi-objective optimization; reinforcement learning for prompt-aware scaling; policy engines.
- Assumptions/Dependencies: Robust quality metrics; predictable scaling on diverse hardware; user acceptance.
- Energy-aware UX features in consumer and enterprise tools
- Description: Real-time “cost preview” (Wh/CO2/time) and “budget caps” with adaptive generation strategies (e.g., step pruning), embedded across authoring tools.
- Sectors: Daily Life, Enterprise Productivity, Education.
- Tools/Products/Workflows: UX components; backend estimators; adaptive schedulers.
- Assumptions/Dependencies: Accurate estimates; clear communication of trade-offs; privacy-compliant telemetry.
- Curriculum and research agendas on sustainable generative video
- Description: Integrate the analytical/empirical modeling framework into ML courses and research programs focused on energy-efficient generative systems.
- Sectors: Academia, Nonprofits, Public Sector.
- Tools/Products/Workflows: Teaching modules; open benchmark suites; student projects on energy-aware design.
- Assumptions/Dependencies: Access to GPUs; community interest; funding.
- Automated offsets and sustainability integrations
- Description: Tie per-generation CO2 estimates to automated offset purchasing, sustainability dashboards, and ESG reporting.
- Sectors: Finance, Enterprise IT, Compliance.
- Tools/Products/Workflows: Offset APIs; ESG pipelines; dashboards aggregating energy/CO2 per team/project.
- Assumptions/Dependencies: Credible offsets; verified measurement; governance standards.
- Multi-stage, selective refinement workflows
- Description: Generate coarse videos cheaply, then selectively refine only segments or frames that fail quality gates—minimizing total energy.
- Sectors: Media Production, Advertising, Education.
- Tools/Products/Workflows: Quality detectors; frame/segment selection; partial regeneration pipelines.
- Assumptions/Dependencies: Reliable quality gating; temporal consistency maintained; orchestration complexity.
- Community energy leaderboards and green benchmarks
- Description: Public leaderboards comparing T2V models on energy, latency, and quality across standardized tasks and hardware.
- Sectors: Open Source, Research, Policy.
- Tools/Products/Workflows: Benchmark harnesses; curated prompt sets; cross-hardware reporting.
- Assumptions/Dependencies: Shared protocols; model card adoption; funding for infrastructure.
- Holistic “video + audio” energy modeling
- Description: Extend measurements to include audio generation and synchronization, enabling full-stack optimization.
- Sectors: Media Tech, Software, Education.
- Tools/Products/Workflows: Audio model integration; end-to-end pipelines; measurement instrumentation.
- Assumptions/Dependencies: Additional model support; audio quality metrics; hardware instrumentation.
Notes on feasibility and assumptions that broadly affect all applications:
- The results strongly rely on the compute-bound regime typical of modern GPUs and realistic token lengths; different hardware or very small inputs may show memory-bound effects.
- Energy is modeled as proportional to latency given sustained Pmax; deviations can occur with dynamic power management or mixed workloads.
- Empirical efficiency µ ≈ 0.456 (H100, BF16) needs recalibration per hardware and software stack.
- The study excludes perceptual quality; organizations should couple these applications with quality evaluations to define acceptable trade-offs.
- Emission factors vary by region and time; carbon-aware scheduling needs reliable grid signals.
- Audio generation and certain proprietary optimizations are out of scope; integrating them will change energy profiles.
Glossary
- Arithmetic intensity: Ratio of computational work to memory traffic, typically measured as FLOPs per byte; higher values indicate more compute-bound behavior. "We estimate the arithmetic intensity (FLOP per byte transferred between HBM and registers) for the main operations in DiT"
- BF16: BFloat16, a 16-bit floating-point format used to accelerate deep learning while maintaining dynamic range. "the H100 provides a dense BF16 peak of Θ_peak = 989\,\text{TFLOP/s}"
- Cascaded pipeline: A multi-stage generation approach where a base model is followed by one or more refiner models to improve quality. "cascaded base + refiner stages."
- Classifier-free guidance (CFG): A sampling technique that runs conditional and unconditional passes to steer generation, improving fidelity at the cost of extra compute. "classifier-free guidance (CFG) passes"
- Compute-bound: A performance regime where execution is limited by arithmetic throughput rather than memory bandwidth. "Compute-bound, when execution is limited by arithmetic throughput (FLOP/s)."
- Cross-attention: An attention mechanism that allows one sequence (e.g., video latents) to attend to another (e.g., text tokens) for conditioning. "self-attention, cross-attention, MLPs, VAE convolutions"
- Denoising steps: Iterations in diffusion sampling that progressively remove noise to produce the final video. "Generating even a few seconds of coherent video typically requires dozens of denoising steps"
- DiT (Diffusion Transformer): A transformer-based backbone used within diffusion models to perform spatio-temporal denoising over latent tokens. "a large DiT (Diffusion Transformer) performs the bulk of spatio-temporal denoising"
- Diffusion caching: An inference-time optimization that reuses redundant activations across steps to reduce compute and energy. "diffusion caching, reusing redundant attention/CFG activations for up to 1.62× savings"
- FlashAttention: A memory-efficient attention algorithm that reduces bandwidth and improves speed for large sequence lengths. "such as fused kernels and FlashAttention"
- FLOPs: Floating-point operations; a measure of computational work used for modeling latency and energy. "decomposing FLOPs by operator and predicting scaling laws"
- GEMM: General Matrix-Matrix Multiplication, a core linear algebra operation underlying MLPs and attention projections. "MLP block (GEMM)"
- HBM3: High Bandwidth Memory (generation 3) used on modern GPUs to provide very high memory throughput. "NVIDIA H100 SXM GPU (80GB HBM3)"
- KV caching: Storing the attention keys and values to avoid recomputation across steps, reducing per-step cost. "With KV caching, the term becomes once-per-video while the products remain per step."
- Latent grid: The downsampled spatio-temporal representation over which the diffusion transformer operates. "the spatial (H,W) and temporal (T) dimensions of the latent grid"
- Memory-bound: A performance regime where execution is limited by memory bandwidth rather than compute throughput. "Memory-bound, when limited by memory bandwidth."
- NVML: NVIDIA Management Library, used to monitor and measure GPU energy and performance metrics. "interfaces with NVML and pyRAPL"
- pyRAPL: A Python library for measuring energy consumption of CPU activities via RAPL counters. "interfaces with NVML and pyRAPL"
- Roofline formulation: A performance model that relates achievable throughput to arithmetic intensity and hardware limits. "following the classic roofline formulation"
- Self-attention: An attention mechanism where each token attends to all others within the same sequence. "self-attention and MLPs become compute-bound above sequence lengths"
- Timestep embedding MLP: A small neural network that encodes the diffusion step index as an embedding injected into transformer blocks. "a timestep embedding MLP injects the diffusion step index"
- VAE decoder: The decoder part of a Variational Autoencoder that reconstructs pixels from latent tensors. "a VAE decoder maps latent tensors back to pixel space"
- Windowed or factorized attention: Variants of attention that reduce effective sequence length by restricting windows or factorizing computations. "With windowed or factorized attention, or may be replaced by the effective window size."
Collections
Sign up for free to add this paper to one or more collections.