- The paper introduces BloomIntent, an automated framework that uses LLMs to generate and evaluate detailed user intents for search queries.
- The methodology features a two-stage pipeline combining query expansion with user attribute extraction and SERP analysis through semantic clustering.
- Key findings demonstrate that BloomIntent achieves high evaluability and realism in intent generation, offering actionable insights for diagnostic search evaluation.
BloomIntent: Automating Search Evaluation with LLM-Generated Fine-Grained User Intents
Motivation and Problem Statement
Traditional search evaluation frameworks rely on aggregate metrics or behavioral signals, which fail to capture the diversity and granularity of user intents underlying a single query. Queries are often underspecified, leading to a multitude of plausible user goals. Existing intent diversification methods typically represent intents as expanded queries or embeddings, lacking the explicitness and evaluability required for diagnostic analysis. BloomIntent addresses these limitations by introducing a user-centric, intent-level evaluation pipeline that leverages LLMs to generate, contextualize, and assess fine-grained user intents for search queries.
BloomIntent Framework Overview
BloomIntent consists of a two-stage pipeline: intent generation and intent contextualization. The intent generation pipeline simulates realistic user intents by expanding queries using user attributes and background knowledge, followed by mapping expanded queries to explicit intent statements grounded in an information-seeking taxonomy. The intent contextualization pipeline evaluates search engine result pages (SERPs) against each intent using LLMs, then clusters semantically similar intents to facilitate structured analysis.
Figure 1: Intent Generation Pipeline overview, illustrating the process from original query to final intent construction. Expanded queries are generated using user attributes and background context, then mapped to intent types and explicit intent statements.
Intent Generation
- User Attribute Extraction: Attributes are inferred from large-scale search logs, capturing dimensions such as price sensitivity, content format preference, task complexity, and user expertise. These attributes are domain-specific (Shopping, Location, Knowledge) and synthesized via affinity diagramming.
- Query Background Retrieval: Top results from Google and Naver are summarized to provide up-to-date context for each query.
- Expanded Query Formulation: LLMs generate up to 100 expanded queries per original query, guided by user attribute profiles and background context, ensuring diversity and plausibility.
- Intent Type Selection and Statement Construction: Each expanded query is mapped to up to three intent types from a refined taxonomy, and explicit, concise intent statements are generated using LLMs.
Intent Contextualization
- Automated SERP Evaluation: For each intent, the SERP is parsed and evaluated on satisfaction (binary), relevance, clarity, and reliability (three-point scale) using structured LLM prompts. Explanations are generated to support chain-of-thought reasoning.
- Semantic Clustering: Agglomerative clustering on intent embeddings groups similar intents, with cluster centroids, outliers, and LLM-generated summaries facilitating interpretability.
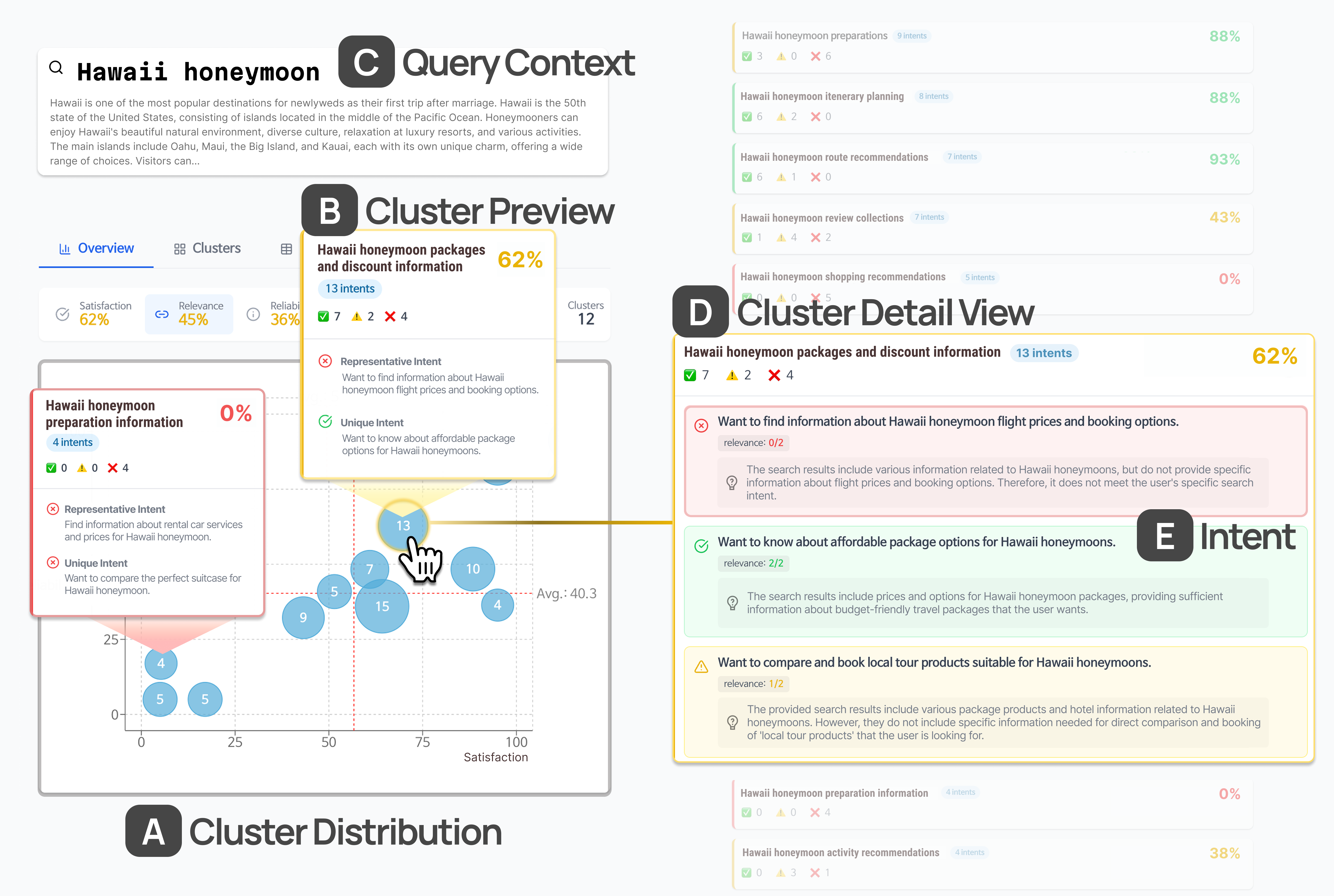
Figure 2: The system interface of BloomIntent, showing query context, intent clusters, cluster previews, cluster detail views, and intent cards with evaluation outcomes and explanations.
Technical Evaluation
Expanded Query Quality
BloomIntent-generated expanded queries were compared to real-world follow-up queries from search logs using BERTScore (KoBigBird embeddings). The mean similarity score was 0.83 (std = 0.067), indicating strong alignment. Human evaluation of the bottom 5% (lowest similarity) queries found 84% semantically relevant and 86% plausible, with 12% rated as novel, demonstrating BloomIntent's ability to surface long-tail and underserved user needs.
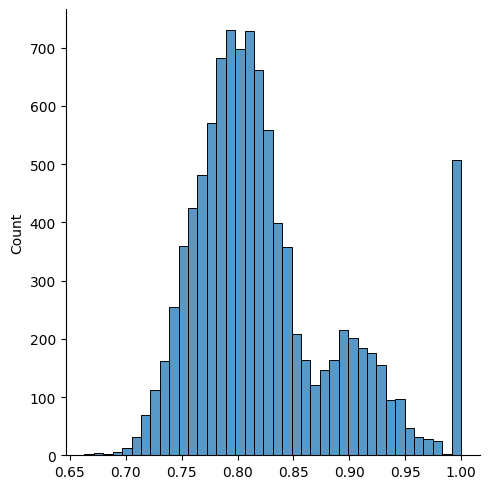
Figure 3: Distribution of recall scores for generated expanded queries. Mean = 0.83, Std = 0.067.
Intent Quality
BloomIntent was compared to the MILL baseline for intent generation. Semantic diversity (lower average pairwise cosine similarity) was higher for BloomIntent (μ = 0.600 vs. 0.611). Lexical diversity was higher for the baseline, but BloomIntent produced more evaluable and realistic intents (mean evaluability = 19.45/20, realism = 18.91/20) with statistical significance (p<0.01). Novelty was domain-dependent: BloomIntent excelled in Shopping, while the baseline was higher in Knowledge, but many baseline intents were implausible.
Automated Evaluation Reliability
LLM-based evaluation achieved moderate agreement with expert human raters: satisfaction (72.1%, κ = 0.445), relevance (57.2%, κ = 0.348), reliability (61.2%, κ = 0.381), clarity (55.4%, κ = 0.310). Agreement was highest for clear-cut cases and lowest for ambiguous ones, mirroring inter-rater disagreement among experts (up to 45% split decisions). LLM accuracy was substantially higher for unanimous human ratings (up to 78.98%) than for split ratings (as low as 40.14%).
Case Study: Practical Utility
A case study with four search specialists demonstrated BloomIntent's value in uncovering fine-grained user needs, diagnosing ambiguous or low-performing queries, and generating actionable insights. Participants highlighted the utility of intent-level evaluation for identifying underserved needs, justifying dissatisfaction, and supporting communication with stakeholders. Semantic clustering enabled efficient prioritization and pattern recognition, though scalability and intent weighting remain open challenges.
Implications and Future Directions
User-Centric Evaluation
BloomIntent operationalizes intent-based evaluation, enabling diagnostic, user-aligned assessment of search quality. The framework supports actionable insights, subgroup analysis, and prioritization, complementing aggregate metrics and behavioral signals.
Human-AI Collaboration
Moderate LLM-human agreement and substantial human rater disagreement underscore the need for hybrid evaluation workflows. BloomIntent's rationales and clustering facilitate human-in-the-loop calibration, especially for ambiguous or high-stakes cases.
Personalization and Multi-Turn Search
Attribute-guided expansion simulates diverse user personas, supporting diagnosis of personalization needs. The framework can be extended to multi-turn and generative search by modeling intent progression and integrating user simulation agents.
Limitations
BloomIntent currently focuses on textual SERP snippets and excludes multimedia intents. Evaluation was conducted on Korean queries and SERPs, limiting generalizability. Future work should address multimedia, cross-lingual, and cross-engine applicability, as well as bias auditing and intent weighting.
Conclusion
BloomIntent introduces a scalable, LLM-powered framework for intent-level search evaluation, generating diverse, realistic user intents and automating their assessment against SERPs. Technical and user studies demonstrate high-quality intent generation, reasonable automated evaluation reliability, and practical utility for search specialists. By shifting from query-level to intent-level analysis, BloomIntent advances user-centric evaluation and lays the groundwork for adaptive, personalized, and diagnostic search system assessment.