Program Synthesis via Test-Time Transduction
Abstract: We introduce transductive program synthesis, a new formulation of the program synthesis task that explicitly leverages test inputs during synthesis. While prior approaches to program synthesis--whether based on natural language descriptions or input-output examples--typically aim to generalize from training examples, they often struggle with robustness, especially in real-world settings where training examples are limited and test inputs involve various edge cases. To address this, we propose a novel framework that improves robustness by treating synthesis as an active learning over a finite hypothesis class defined by programs' outputs. We use an LLM to predict outputs for selected test inputs and eliminate inconsistent hypotheses, where the inputs are chosen via a greedy maximin algorithm to minimize the number of LLM queries required. We evaluate our approach on four benchmarks: Playgol, MBPP+, 1D-ARC, and programmatic world modeling on MiniGrid. We demonstrate that our method significantly improves program synthesis in both accuracy and efficiency. We release our code at https://github.com/klee972/SYNTRA.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a new way to teach computers to write small programs that do a specific job, like fixing text in a spreadsheet or solving simple puzzles. The new idea is called “transductive program synthesis.” Instead of asking the computer to write a program that works for all future cases, it focuses on getting the right answers for a given set of test inputs that you already have in front of you. Think of it like studying only the questions that will be on your quiz, not the whole textbook.
What questions did the researchers ask?
The researchers mainly asked:
- If we already know the test inputs (the questions), can we use them while creating the program to get better, more reliable answers, especially on tricky “edge cases”?
- Can we do this efficiently, without asking a big AI model too many times?
- Does this approach work across different kinds of tasks, like text cleanup, coding, visual puzzles, and simple game worlds?
How did they do it?
They built a framework called SYNTRA (SYNthesis-by-TRAnsduction). Here’s the big idea in everyday terms:
Imagine you have:
- A few examples showing what the program should do (training examples).
- A bunch of test inputs whose answers you need (test inputs).
- A LLM, like an AI assistant, that can write code and reason.
SYNTRA works like a detective narrowing down suspects.
Step 1: Make many possible programs
- The AI first writes many candidate programs that could solve the task.
- It throws out any program that fails the small set of training examples you trust.
Step 2: Turn programs into “answer sheets”
- Each remaining program is run on all the test inputs you care about.
- This produces a bunch of “answer sheets,” where each sheet is a list of the program’s predicted outputs for all test inputs.
- If two programs produce the exact same set of outputs, they’re treated as the same “hypothesis” (same answer sheet). This set of answer sheets is called the “hypothesis class.”
Analogy: You have several possible answer keys for your quiz. Only one is fully correct.
Step 3: Ask an AI to pick likely answers for a few test inputs
- For one test input at a time, they ask a (strong) LLM to choose the most likely correct answer from the candidate answers listed on the different answer sheets.
- Any answer sheets that disagree with the AI’s chosen answer are eliminated.
- Repeat until only one answer sheet remains. That gives you the final program’s outputs.
Analogy: You ask a trusted friend to help with just a few questions. Each time they pick an answer, you can throw out all answer keys that conflict with that choice.
Step 4: Smart question picking (the “maximin” trick)
- Which test input should you ask about next?
- They use a greedy maximin strategy: pick the question that, no matter what the AI answers, will eliminate as many wrong answer sheets as possible in the worst case.
- If there’s a tie, they break it by choosing the question whose answer choices are shortest (to keep prompts small and fast).
Analogy: It’s like playing “20 questions.” You ask the question that splits the suspects most effectively, so you need as few questions as possible.
What did they find?
Across four very different benchmarks, SYNTRA improved both accuracy and efficiency:
- String transformations (Playgol): Better at handling tricky text cases, like odd name formats in spreadsheets.
- Python coding from descriptions (MBPP+): More accurate solutions on many test cases, and it needed far fewer calls to the big AI model than directly asking the AI to solve every test case.
- Visual reasoning (1D-ARC): Much higher task accuracy than baselines that just pick a random program or directly predict answers with the AI.
- Programmatic world modeling (MiniGrid): Built more accurate “world rules,” so the system better predicts what happens next after an action.
Why this matters:
- Accuracy went up a lot, especially on edge cases (the weird or uncommon inputs that often break simple solutions).
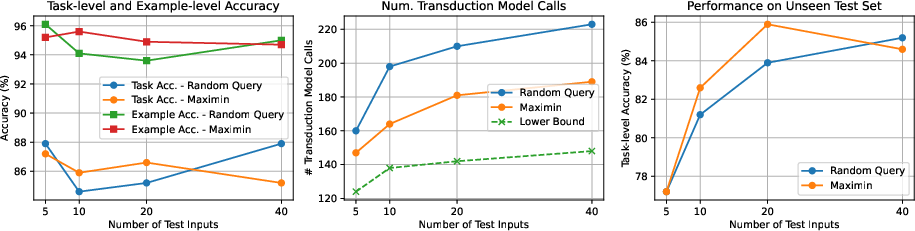
- Efficiency improved: the number of AI calls grows slower than the number of test inputs, making the method scale to big test sets.
- The maximin strategy cut down AI calls even more compared to picking questions at random.
They also found:
- Using a strong program generator (like MoC) plus SYNTRA gave the best results overall.
- Seeing more test inputs during synthesis made the final program generalize better to brand-new inputs you didn’t show the system (good news for reliability).
What does this mean going forward?
- Practical impact: In real tasks like spreadsheet cleanup or data transformation, users often know the exact rows they want to fix. SYNTRA uses those test inputs directly to build a more reliable one-off program, reducing mistakes on weird cases and saving time.
- Efficient collaboration with AI: Instead of asking an AI for every single output, SYNTRA asks smart questions to quickly zero in on the right program, cutting cost.
- Flexibility and transparency: The final result is a program you can run and inspect, not just answers from a black box. That’s helpful for debugging and trust.
- Future directions: The same idea could work with human-in-the-loop systems (ask a person when the AI is unsure) or with probabilistic strategies if program probabilities are known.
Helpful vocabulary (made simple)
- Training examples: A few trusted examples that show what correct behavior looks like.
- Test inputs: The actual cases you want answers for right now.
- Edge cases: Unusual or tricky inputs that often break simple rules.
- Hypothesis class: The set of possible “answer sheets” produced by candidate programs on your test inputs.
- Transduction: Focusing on getting the right answers for the specific test inputs you have, instead of trying to learn a rule that works for every possible future input.
- Maximin: A strategy that picks the next question to eliminate as many wrong answer sheets as possible, even in the worst case.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces SYNTRA for transductive program synthesis and demonstrates promising results. The following concrete gaps and open questions identify what remains uncertain or unexplored and can guide future research:
- Non-realizable hypothesis classes: The method assumes at least one candidate hypothesis matches all ground-truth test outputs. How to detect and handle non-realizable settings (e.g., under-specified tasks, missing operators) and recover via program repair, augmented search, or a principled fallback to direct transduction?
- Robustness to transduction errors: What is the failure rate when the transduction model selects an incorrect pseudo-label? Can we add noise-tolerant elimination (e.g., probabilistic voting, repeated queries, confidence thresholds, or reversible eliminations) to prevent discarding the correct hypothesis?
- Theoretical guarantees: The paper suggests sublinear query growth and references active learning, but lacks formal analysis. Under what assumptions on hypothesis structure and transduction accuracy does maximin guarantee bounded query complexity or convergence to the correct hypothesis? What are tight lower/upper bounds?
- Efficiency of hypothesis construction: Constructing the hypothesis class requires executing K candidate programs on N test inputs (O(KN)). How does this scale in practice for large K and N? Can we introduce lazy execution, adaptive partial evaluation, test-input sampling, caching, or clustering to reduce execution cost?
- Accuracy-aware query selection: Maximin ignores the transduction model’s varying accuracy across inputs. Can we design input selection criteria based on expected elimination (information gain), LLM uncertainty, or learned policies that account for prediction reliability?
- Tie-breaking heuristic: The tie-breaker minimizing total output length is ad hoc. Are there more principled criteria (e.g., token cost, entropy of output distributions, discriminability scores) that yield better accuracy and efficiency?
- Output matching reliability: Fuzzy string matching may mis-assign predictions to candidates, especially for structured outputs. Can we enforce index-based selection, canonicalization, schema-aware matching, or structured validation (e.g., AST equivalence, array equality) to improve correctness?
- Candidate diversity vs. cost: How do K, AGA/IID/MoC strategies, and sampling parameters affect hypothesis coverage and end-to-end accuracy/cost? Can we adaptively expand the candidate pool only when the version space remains ambiguous (e.g., generate-on-demand)?
- Program execution safety and determinism: The paper does not detail handling exceptions, nondeterminism, side effects, timeouts, or unsafe code. What sandboxing, resource constraints, deterministic stubs, and error categorization are needed to ensure reliable hypothesis construction?
- Generalization beyond visible test inputs: Unseen test evaluation is limited (only MBPP+ with small held-out sets). How does SYNTRA generalize across domains and larger unseen sets? What is the overfitting risk to the visible test inputs?
- Evaluation filtering bias: Results exclude tasks where learning is trivial or where no correct program exists in the hypothesis class. How does SYNTRA perform on full datasets, including non-realizable tasks, and how sensitive are conclusions to this filtering?
- Comprehensive cost accounting: “Number of LLM calls” omits token usage, wall-clock time, and execution overhead. Can we present a detailed cost model that includes prompting tokens, execution time, and compute for synthesis vs. transduction?
- Model and prompt dependence: The approach relies on proprietary GPT models and specific prompts. How reproducible is performance across open-source models, different prompting styles, seeds, and model updates? Which prompt designs most affect transduction accuracy?
- Confidence estimation and abstention: Can the transduction model provide calibrated confidence or abstain when uncertain, triggering additional queries or human-in-the-loop verification? What policies best balance accuracy and cost?
- Multi-modal and structured domains: For outputs beyond plain text (e.g., grids in 1D-ARC, state objects in MiniGrid), what domain-specific comparators and canonical forms are needed? How does SYNTRA extend to images, graphs, or complex data structures?
- Security and privacy: Executing synthesized code over user data raises safety concerns. What secure execution, auditing, and explainability mechanisms ensure trust and allow users to validate or override the chosen program?
- Noisy or conflicting training examples: The method assumes clean training labels. How does label noise affect hypothesis filtering, and can robust techniques (e.g., outlier detection, constraint relaxation) mitigate it?
- Active acquisition of additional constraints: In under-specified tasks, can SYNTRA proactively request informative inputs or labels from users (query synthesis) to reduce ambiguity and improve realizability?
- Probabilistic extensions: Without program probabilities, SYNTRA avoids probabilistic inference. If approximate priors or posterior estimates are available, can we integrate Bayesian elimination, query-by-committee, or uncertainty sampling to reduce queries?
- Stopping criterion and post-verification: Stopping when one hypothesis remains may still leave errors if prior eliminations were noisy. Can we add a final verification phase (e.g., additional hidden checks, diverse probes) and confidence bounds before deployment?
- Scaling to very large test sets: For spreadsheets with thousands of rows, can we group similar inputs, perform batch queries, or cluster candidate outputs to reduce the number of transduction calls while preserving correctness?
- Stateful programs and longer horizons: In world modeling, how does SYNTRA handle long-horizon dependencies, partial observability, and compositional actions? Can the method extend to sequence-level transduction/hypotheses?
- Prompt-length vs. reasoning trade-offs: Including many test inputs in prompts degraded performance. What strategies (prompt compression, retrieval augmentation, summarization of input clusters) best preserve reasoning quality at scale?
- Failure mode analysis: The paper provides limited analysis of where SYNTRA fails (e.g., complex algorithmic tasks, subtle edge cases). A systematic taxonomy of failure modes and targeted mitigations would guide improvements.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built now using the SYNTRA framework (transductive program synthesis with maximin query selection) and the paper’s LLM-based instantiation.
- Bold spreadsheet and table auto-completion with disambiguation (Productivity software; Enterprise operations)
- Tools/Workflows: Excel/Google Sheets add-ons that learn string and table transformations from 1–2 examples, run diverse candidate programs, and actively ask the user to validate outputs on a few maximally-informative rows (maximin). Export as formulas, Python, Apps Script, or Power Query steps.
- Assumptions/Dependencies: At least one labeled example; safe sandboxed code execution; visible test rows; LLM access for transduction; basic data-governance/privacy guardrails.
- Low-code/ETL transformation assistants (Data engineering; Analytics)
- Tools/Workflows: “ActiveETL” wizards inside dbt, Airbyte, Power Query, Pandas/Polars notebooks. Generate candidate transforms, evaluate on sample rows, and use LLM-based transduction to select among candidates. Emit reproducible SQL/Python pipelines.
- Assumptions/Dependencies: Ability to execute candidates on sample data; candidate-program diversity; data masking for sensitive fields; deterministic execution with timeouts.
- Test-aware code assistants in IDEs (Software engineering)
- Tools/Workflows: VS Code/JetBrains extensions that, given an NL description and unit tests, synthesize multiple implementations, construct a test-time hypothesis class of outputs, and apply maximin queries to a few selected tests to disambiguate. Produce an auditable final function and rationale.
- Assumptions/Dependencies: Visible/curated tests; sandboxed execution; realizability (the correct behavior appears in candidate set); reliable fuzzy-matching of LLM predictions to candidate outputs.
- Output-consensus patch selection in CI (Software/DevOps)
- Tools/Workflows: CI step or GitHub Action that proposes multiple bug-fix patches, runs them on the test suite to get an output vector per patch, and uses LLM transduction to arbitrate edge cases and select the most robust patch. Reduces costly per-test LLM calls via maximin.
- Assumptions/Dependencies: Tests cover intended behavior; compute budget for candidate generation and execution; reproducible environments.
- Programmatic world modeling for small simulators (Robotics; RL research; Games)
- Tools/Workflows: Generate transition functions for grid-worlds (e.g., MiniGrid) by synthesizing state-update programs, comparing candidate next-state vectors, and using transduction to pick the correct transition. Improves planning and sample efficiency with interpretable models.
- Assumptions/Dependencies: Discrete action spaces; compact state encoding; sufficient coverage of transitions in candidate set; LLM quality for transduction.
- Cost-efficient bulk automation vs. per-item LLM calls (General automation)
- Tools/Workflows: For bulk log parsing, filename normalization, email field extraction, or address standardization, replace per-record LLM inference with: synthesize candidate programs once, run them across records, and use a handful of maximin transduction queries to resolve edge cases. Achieves sublinear LLM calls with large test sets.
- Assumptions/Dependencies: Stable patterns across the batch; candidates capture true behavior; telemetry to detect drift.
- Interactive programming-by-example tutors (Education)
- Tools/Workflows: Courseware/LMS widgets where learners provide an example, the system proposes multiple algorithms, and then asks the learner to label a few informative inputs to converge to a correct program. Exposes version space and reasoning steps to teach abstraction and edge-case thinking.
- Assumptions/Dependencies: Pedagogically curated tasks; safe code execution; simple UI for selective queries.
- Auditable automation in regulated workflows (Finance; Healthcare; Public sector)
- Tools/Workflows: Replace opaque “LLM-direct” outputs with an exported program artifact and a trace of maximin-selected queries and decisions. Apply to claims normalization, report generation, or form cleaning where auditability is required.
- Assumptions/Dependencies: Data privacy compliance (on-prem or VPC); logging and model governance; human approval gates for low-confidence cases.
Long-Term Applications
These opportunities require further research, scaling, domain adaptation, or policy/standards development before broad deployment.
- Enterprise-wide autonomous data transformation agents (Data/AI Ops)
- Tools/Workflows: Agents that monitor new datasets, propose candidate transforms, actively query data stewards on maximally-informative rows, and converge to reusable, versioned programs integrated with data catalogs and lineage tools.
- Assumptions/Dependencies: Human-in-the-loop UX, access control integration, robust scaling to large tables, drift detection and online updates.
- Safety-critical controller synthesis with verifiable guardrails (Robotics; Automotive; Industrial)
- Tools/Workflows: Synthesize discrete controllers from scenario specs and visible test inputs, use transductive elimination to pin down edge-case behaviors, and integrate with formal verification or runtime monitors before deployment.
- Assumptions/Dependencies: Strong coverage of hazardous scenarios; proofs or contracts layered atop SYNTRA; certification-compliant toolchains.
- Compiler/runtime integration for test-time transduction (Software systems)
- Tools/Workflows: Compilers that materialize multiple program variants for under-specified specs, instrument deploy-time inputs, and use maximin-like policies to settle on the best variant under real traffic (with A/B guardrails and rollback).
- Assumptions/Dependencies: Acceptable runtime overhead; observability; safe canarying; privacy-aware logging.
- Probabilistic/Bayesian variants and learned priors (ML research; Program synthesis)
- Tools/Workflows: Replace greedy maximin with query-by-committee or information gain using program priors; combine output-based version spaces with likelihoods over programs to further reduce queries and improve robustness.
- Assumptions/Dependencies: Access to proposal probabilities or calibrated scores; scalable inference over large hypothesis classes.
- Large-scale world modeling for embodied AI (Robotics; Simulation)
- Tools/Workflows: Learn partially known simulators from logs, proposing many candidate dynamics models and selecting via transductive queries on informative trajectories; enable safer, cheaper planning with interpretable models.
- Assumptions/Dependencies: Rich state/action abstractions; safe active querying; scalable deduplication and execution.
- Domain-specific DSLs with transductive disambiguation (Healthcare coding; Insurance claims; Compliance)
- Tools/Workflows: Develop DSLs for EHR/claims normalization or compliance rules; generate multiple DSL programs, and use SYNTRA to resolve ambiguous behaviors across real datasets; reduce variability and enforce standards.
- Assumptions/Dependencies: Well-designed DSLs and toolchains; privacy-preserving execution; stakeholder curation of test inputs.
- Policy and standards for transductive AI tooling (Policy; Governance)
- Tools/Workflows: Procurement and auditing standards that prefer interpretable program artifacts over opaque predictions, require logging of query selection decisions, and mandate cost/carbon accounting of LLM calls.
- Assumptions/Dependencies: Regulator buy-in; cross-industry working groups; reference implementations and benchmarks.
- Private/on-device transductive synthesis (Healthcare; Finance; Edge computing)
- Tools/Workflows: Run synthesis locally and use compact on-device LLMs for transduction, preserving privacy in hospitals, banks, or edge gateways; distill stronger models into smaller ones for the transductive role.
- Assumptions/Dependencies: Adequate local compute; distillation pipelines; secure sandboxes; model-update mechanisms.
Notes on feasibility and cross-cutting dependencies
- Realizability: SYNTRA assumes the correct output vector exists in the hypothesis class constructed from candidate programs; diversity mechanisms (e.g., AGA, MoC) are crucial.
- Transduction quality: A capable LLM significantly improves correctness; fuzzy matching must map free-form reasoning to one candidate output.
- Efficiency: Maximin query selection reduces LLM calls and scales sublinearly with test set size; compute budget is dominated by candidate generation and execution.
- Safety and ops: All deployments need sandboxes, timeouts, and resource quotas for executing candidate programs; logging/versioning for auditability; data privacy controls.
- Generalization: More visible test inputs improve performance on unseen inputs; monitor drift and enable online/human-in-the-loop updates.
Glossary
- 1D-ARC: A 1D version of the ARC visual reasoning benchmark with grid-based transformations. "In the visual reasoning domain, we use 1D-ARC \citep{1darc}."
- Active learning: A learning paradigm that selects informative queries to efficiently shrink the hypothesis space. "treating synthesis as an active learning over a finite hypothesis class defined by programs' outputs."
- AGA (Autoregressively Generated Algorithms): A diversity-focused synthesis method that first proposes distinct algorithms, then translates them to code. "Henceforth, we refer to this approach as AGA (Autoregressively Generated Algorithms)."
- Bayesian program learning: A probabilistic approach that infers programs from few examples using learned priors. "While researchers adopt Bayesian program learning \citep{humanlevel, ellis2023humanlike, pmlr-v235-palmarini24a} to address uncertainty and learning from few examples,"
- Deduplication: Removing duplicate outputs to form a unique set of candidates. "Execute the programs in on the test inputs and deduplicate the execution results to construct our hypothesis class"
- Domain-specific languages (DSLs): Purpose-built languages that constrain the program search space in a domain. "Early approaches to inductive program synthesis mostly relied on hand-crafted domain-specific languages (DSLs) to limit the space of possible programs"
- Epistemic uncertainty: Uncertainty due to incomplete knowledge about future inputs or conditions. "This limitation arises from epistemic uncertainty; the model is uncertain about what kinds of inputs will appear at test time."
- Enumerative search: A synthesis strategy that explores programs by systematically enumerating candidates. "such as black-box LLMs or synthesis models based on enumerative search."
- Functional consensus: Selecting solutions that agree in behavior across tests to improve reliability. "or functional consensus \citep{lee-etal-2023-weakly, chen2024divideandconquer, nl2code}."
- Fuzzy string matching: Approximate string comparison to map imperfect predictions to the closest candidate. "Since the LLMâs output is not guaranteed to exactly match one of the candidate outputs, we use fuzzy string matching to select the candidate that is most similar to the LLMâs prediction."
- Greedy maximin algorithm: A query selection rule that maximizes the minimum number of hypotheses eliminated per query. "the inputs are chosen via a greedy maximin algorithm to minimize the number of LLM queries required."
- Hypothesis class: The set of candidate output tuples induced by executing candidate programs on test inputs. "The hypothesis class is defined as a set of -tuples, consisting of program outputs on the test inputs,"
- Hypothesis elimination: Discarding candidates inconsistent with observed or predicted outputs. "This process of transductive prediction and hypothesis elimination is repeated iteratively until a single hypothesis remains."
- Inductive program synthesis: Synthesizing programs from input-output examples without natural language guidance. "In inductive program synthesis, the model operates without a natural language description, using only a set of input-output examples"
- LLM: A pretrained generative model capable of reasoning and code generation. "We use an LLM to predict outputs for selected test inputs and eliminate inconsistent hypotheses,"
- Maximin criterion: Choosing the input whose worst-case predicted label eliminates the most hypotheses. "by choosing test inputs according to the maximin criterion, we achieve comparable accuracy with substantially fewer LLM calls"
- MiniGrid: A gridworld environment suite for evaluating agents and world models. "and programmatic world modeling on MiniGrid \citep{minigrid} environment."
- Mixture of Concepts (MoC): An LLM-based synthesis approach that generates diverse conceptual hypotheses before coding. "We use Mixture of Concepts (MoC) \citep{moc}, a recent inductive program synthesis approach based on LLMs."
- Programmatic world modeling: Learning code-based environment dynamics to predict next states from states and actions. "Finally, we validate SYNTRAâs ability on programmatic world modeling (e.g. WorldCoder \citep{worldcoder})âa complex task that requires modeling interaction mechanisms between different entities and actions."
- Pseudo-label: A model-predicted label treated as supervision for filtering hypotheses. "selects one output as a pseudo-label."
- Query-by-committee: An active learning method that queries inputs on which a committee of models disagrees. "we could adopt uncertainty-based strategies or more sophisticated methods like query-by-committee \citep{qbc}."
- Realizable setting: An assumption that the correct hypothesis exists within the candidate set. "We assume a realizable setting, in which there exists at least one hypothesis that matches all ground truth outputs."
- Synthesis-by-Transduction (SYNTRA): A framework that combines program synthesis with transductive prediction to robustly select outputs. "we propose SYNTRA (SYNthesis-by-TRAnsduction) framework to improve the robustness of programs."
- Transduction model: A predictor that, given an input and candidate outputs, selects the most plausible output. "We instantiate the transduction model using an LLM, leveraging its reasoning abilities and world knowledge to produce high-accuracy pseudo-labels."
- Transductive inference: Predicting labels for a fixed test set without aiming for full generalization. "Vapnik famously advocated for transductive inference \citep{vapnik} with the principle: ``When solving a problem of interest, do not solve a more general problem as an intermediate step.''"
- Transductive prediction: Making output predictions on specific test inputs during inference using available context. "This process of transductive prediction and hypothesis elimination is repeated iteratively until a single hypothesis remains."
- Transductive program synthesis: Synthesizing programs by explicitly leveraging visible test inputs during synthesis. "We introduce transductive program synthesis, a new formulation of the program synthesis task that explicitly leverages test inputs during synthesis."
- Transition function: A mapping from current state and action to the next state in a dynamical system. "focused on generating a transition function that, given the current state and action, outputs the next state."
- Version space: The subset of hypotheses still consistent with all observed constraints so far. "We define the version space at iteration , denoted as , as the set of hypotheses consistent with all training and test observations collected up to iteration ."
- Zero-shot chain-of-thought prompting: Prompting LLMs to produce step-by-step reasoning without example demonstrations. "Additionally, we use zero-shot chain-of-thought prompting~\citep{kojima2022large} to encourage explicit reasoning by the LLM."
Collections
Sign up for free to add this paper to one or more collections.

