CodeRAG: Finding Relevant and Necessary Knowledge for Retrieval-Augmented Repository-Level Code Completion (2509.16112v1)
Abstract: Repository-level code completion automatically predicts the unfinished code based on the broader information from the repository. Recent strides in Code LLMs (code LLMs) have spurred the development of repository-level code completion methods, yielding promising results. Nevertheless, they suffer from issues such as inappropriate query construction, single-path code retrieval, and misalignment between code retriever and code LLM. To address these problems, we introduce CodeRAG, a framework tailored to identify relevant and necessary knowledge for retrieval-augmented repository-level code completion. Its core components include log probability guided query construction, multi-path code retrieval, and preference-aligned BestFit reranking. Extensive experiments on benchmarks ReccEval and CCEval demonstrate that CodeRAG significantly and consistently outperforms state-of-the-art methods. The implementation of CodeRAG is available at https://github.com/KDEGroup/CodeRAG.

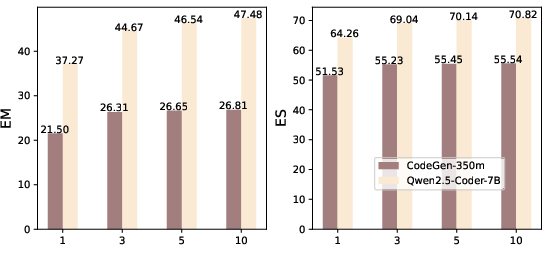
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping computer programs finish writing code more accurately by looking at the whole project, not just the current file. The authors built a system called CodeRAG that finds the most helpful pieces of code from a big codebase and feeds them to a code-writing AI so it can complete the missing parts better.
What questions did the researchers ask?
- How can we build better “search questions” from the unfinished code so the AI retrieves the right help from the repository?
- How can we search a codebase in multiple smart ways, not just one, to cover different kinds of needs (exact matches, similar meaning, and code dependencies)?
- How can we choose the best and most necessary pieces of retrieved code for the AI, so we don’t overload it with irrelevant information?
How did they do it?
Turning the codebase into a “knowledge library”
Think of a software project like a giant library full of code. CodeRAG first organizes this library. It scans the project and breaks it into meaningful pieces such as:
- Functions (what the code can do)
- Variables (names for stored values)
- Class functions and class variables (special code inside classes)
To do this, they use an Abstract Syntax Tree (AST), which is like a map that shows the structure of the code. This makes searching more precise than just chopping code into random chunks.
Building better search questions (log probability guided probing)
A “search question” is the text we use to ask the system for help. Instead of using only the last few lines before the cursor (which might miss important imports or definitions at the top), CodeRAG tests different small chunks around the unfinished code to see which ones make the AI most confident.
“Log probability” here is a score that tells how sure the AI feels when predicting the next tokens. CodeRAG tries adding nearby chunks to the unfinished part and checks which additions raise the AI’s confidence the most. Those chunks are included in the search question, so the AI retrieves more relevant help from the repository.
Searching in multiple ways (multi-path retrieval)
Different problems need different kinds of searches:
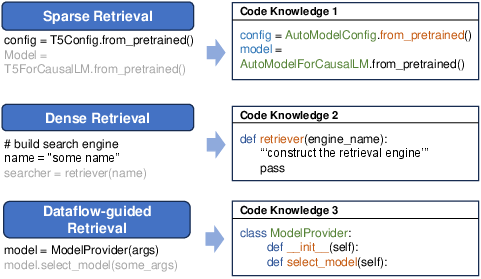
- Sparse retrieval: Matches exact words (like searching for the same function name). Fast and great when names match exactly.
- Dense retrieval: Finds code with similar meaning, even if the words differ (like “add_user” vs “create_member”). Uses embeddings to compare meanings.
- Dataflow-guided retrieval: Traces how data moves through the program (e.g., where a variable was set, changed, or used). Helpful for understanding dependencies.
CodeRAG uses all three paths, then gathers the best candidates into a list.
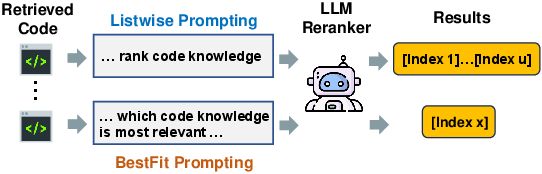
Picking the best supporting pieces (BestFit reranking)
After retrieving many pieces, we still need to choose the most useful ones. CodeRAG asks a separate judging AI to pick the single most helpful snippet at a time from small windows of candidates (this is the “BestFit” idea). This keeps things fast because the judge only picks one best item per window, not a long ranked list all at once.
To save even more time, the authors train a smaller “judge” model to imitate the bigger one (this is called distillation). The small judge learns from the bigger judge’s choices and can do the reranking cheaply without much loss in quality.
Putting it all together
- Turn the repository into a clean, structured library of code pieces (functions, variables, class parts).
- Build a strong search question by picking nearby chunks that raise the AI’s confidence.
- Retrieve candidates using three methods (sparse, dense, dataflow).
- Rerank the candidates with BestFit to keep only the top few most helpful pieces.
- Feed the final selected code pieces plus the current file’s context into the code-writing AI to complete the missing code.
What did they find?
- CodeRAG consistently beat several strong baselines on two benchmarks (ReccEval and CCEval). These baselines include tools that use only the last lines, only one retrieval method, or no repository context at all.
- Each part of CodeRAG adds value: using better search questions, combining multiple retrieval paths, and reranking significantly improves accuracy.
- The smaller “distilled” judge runs faster and still performs well, though the big judge is slightly better.
- Building the search question with confidence scores (log probability) is more effective than simple rules like “use the last k lines.”
- While CodeRAG takes a bit more time than simpler methods (because it does more steps), the extra cost is small and the accuracy gains are large.
In simple terms: CodeRAG helps the AI find the right information in a big codebase and pick the most useful pieces, which leads to better code completions.
Why does this matter?
When programmers work on large projects, the right information isn’t always in the current file. It might be in another function, a class in a different folder, or hidden behind variable dependencies. CodeRAG shows a practical way to:
- Ask smarter questions about the unfinished code,
- Search the repository in multiple complementary ways,
- Pick the most useful snippets efficiently.
This can make code assistants more reliable, save developers time, reduce bugs, and improve teamwork on big codebases. In the future, the authors plan to make the retriever and the code-writing AI work even closer together (possibly by training them jointly) and to build new tests for generalization.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper leaves the following issues unresolved or insufficiently explored, which future work could address:
- Generalization beyond Python: effectiveness on other languages (e.g., Java, JavaScript, C/C++, Go), multi-language repositories, and language-specific tooling for AST/dataflow extraction.
- Cross-file dataflow retrieval: current dataflow-guided retrieval appears limited to the unfinished file; building and leveraging repository-wide dataflow/call graphs (including imports, inheritance, and inter-module dependencies) remains unexplored.
- Knowledge base coverage: the AST-derived items include functions and variables but omit comments/docstrings, type annotations, imports, call graphs, inheritance hierarchies, configuration/build files, and test code—evaluate whether incorporating these improves retrieval and completion.
- Dense retrieval quality: only the CodeT5p encoder is used; assess stronger code embeddings (e.g., specialized code encoders, contrastive retrievers), fine-tuning on repository-level retrieval tasks, and cross-model transferability.
- Adaptive multi-path routing: no mechanism to dynamically select or weight retrieval paths (sparse/dense/dataflow) per query; investigate learned policies (e.g., bandits/gating) that route queries to the best path(s).
- Conflict resolution and deduplication: the approach aggregates results from multiple paths without detailing how duplicates and conflicting snippets are detected, merged, or prioritized; paper strategies for consolidation and semantic deduplication.
- Prompt construction details and ordering: the paper does not specify how retrieved pieces are formatted, ordered, and interleaved with code context; analyze prompt schemas, ordering effects, and formatting to reduce noise and improve utility.
- Input length management: with a 2,048-token limit, the method does not explore summarization/compression of retrieved code, automatic selection of
u, or dynamic context budgeting based on query difficulty. - Query construction hyperparameters: sensitivity and automatic tuning of
f(chunk length),m(generation steps), andg(selected chunks) are not studied; develop principled methods to adapt these per file/query and model. - Prober model choice and alignment: log probability probing relies on CodeT5p-220m; quantify how prober identity/size affects relevance estimation, and whether using the same generator (or a closer surrogate) improves alignment and performance.
- Theoretical grounding of log-prob probing: the link between token-level log-prob gains and “relevance” is not formalized; explore alternative signals (e.g., perplexity deltas, mutual information, gradient-based attributions) and compare empirically.
- BestFit reranking design: picking “one most helpful” snippet per window lacks formal justification; compare against pairwise/listwise ranking with controllable inference cost, paper window size/overlap effects, and analyze heap-sort comparator reliability.
- Reranker–generator preference alignment: a single LLM reranker (Qwen3-8B) is used while code generators vary; test whether reranking must be tailored per generator, and explore joint optimization or feedback-based alignment.
- Distilled reranker supervision quality: distillation labels are generated by the LLM reranker via repeated selection; quantify label noise, add confidence calibration, and investigate semi-supervised or human-in-the-loop refinement.
- Human evaluation robustness: the subjective reranking assessment (100 cases, 3 raters) lacks inter-rater reliability measures and task framing details; expand to larger, diverse samples, compute agreement metrics, and include developer-in-the-loop studies.
- Functional correctness and runtime validation: evaluation relies on lexical/identifier metrics (EM/ES/F1); design scalable unit/integration tests, execution-based metrics (e.g., pass@k with harnesses), and task-specific correctness criteria for repositories.
- Failure mode analysis: no breakdown of cases where specific retrieval paths help/hurt, or where reranking misorders snippets; produce error taxonomies and diagnostic tools to guide adaptive retrieval and prompt shaping.
- Scalability and latency: index build time, memory footprint, and incremental updates for large repositories are not reported; evaluate end-to-end IDE latency, streaming completions, and practical deployment constraints.
- Sensitivity to parameters
j(per-path top-K) andu(retained snippets): only limited exploration ofuis shown; conduct broader analyses, and design mechanisms to adaptj/uto context length, query complexity, and observed gains. - Robustness to real-world repository noise: handle duplicated code, vendor libraries, outdated APIs, mixed coding styles, dynamically generated code, and non-standard project structures; measure resilience and mitigation techniques.
- Handling dynamic features: for languages like Python with dynamic typing/imports/reflection, static dataflow graphs can miss dependencies; integrate dynamic analysis or hybrid static–dynamic approaches.
- Security, privacy, and licensing: retrieving and inlining repository code raises compliance risks; specify safeguards (e.g., license filters, PII/code secret detection, provenance tracking) and paper their impact on performance.
- Right-context completions and bidirectional settings: evaluate and adapt the method when both left/right contexts are available (as in RepoFormer settings), and measure impacts on retrieval and reranking.
- Generalization across model scales: results are shown up to 7B generators; test with larger or instruction-tuned code LLMs, quantify diminishing returns, and revisit reranking strategies for long-context models.
- Release and reproducibility: ensure complete reporting for CCEval (only partially referenced in appendix), publish trained reranker artifacts and distillation data, and document hyperparameters to support replication across hardware.
- Integration with joint training: beyond reranking, explore end-to-end training of retriever–reranker–generator (e.g., via contrastive objectives, RL with execution feedback), and quantify alignment improvements over post-hoc reranking.
Glossary
- Abstract Syntax Tree (AST): A tree-structured representation of source code that captures its syntactic structure to enable program analysis. "we first extract the Abstract Syntax Tree (AST) of each code file."
- Bag of Word retriever: An information retrieval method that treats documents as unordered bags of words to match queries by term frequency. "Bag of Word retriever"
- BestFit code reranking: A reranking strategy that prompts an LLM to select the single most relevant code snippet per window to reduce inference cost. "we propose BestFit code reranking that prompts the LLM reranker to pick the most relevant code knowledge from the retrieval list to the query."
- BM25: A probabilistic ranking function for keyword-based retrieval that scores documents based on term frequency, inverse document frequency, and document length. "TF-IDF and BM25 (sparse retrieval)"
- Code knowledge base: A structured repository of code elements (functions, variables, classes) designed for efficient retrieval during completion. "Constructing the repository-level code knowledge base involves parsing and processing the code in the repository, transforming raw code into structured knowledge to enable more efficient retrieval, understanding, and reuse."
- Code LLMs (code LLMs): LLMs trained on large-scale code corpora to understand and generate code. "Code LLMs (code LLMs), are trained on massive code data"
- Dataflow analysis: Static analysis that models how data values propagate through a program to uncover dependencies and relations. "DraCo extracts code entities and their relations through dataflow analysis, forming a repository-specific context graph."
- Dataflow graph: A graph representation of variables and operations indicating how data depends and flows across program statements. "we first formulate the unfinished code file into a dataflow graph."
- Dataflow-guided retrieval: Retrieval that uses data dependency relations (from dataflow graphs) to find code relevant to the target context. "dataflow-guided retrieval"
- Dense retrieval: Embedding-based retrieval that encodes queries and documents into vectors and selects items by similarity (e.g., cosine). "Dense retrieval leverages an encoding model to encode the retrieval query and code knowledge in the code knowledge base into representations."
- Distilled reranker: A smaller model trained to mimic an LLM reranker’s preferences to reduce reranking cost. "Finally, the trained distilled reranker is used in CodeRAG to actually rerank the retrieved code knowledge"
- Edit Similarity (ES): A normalized similarity metric based on edit distance that measures how close generated code is to the ground truth. "Exact Match (EM) and Edit Similarity (ES) are employed to assess code alignment."
- Exact Match (EM): A binary metric indicating whether generated code exactly matches the ground truth. "Exact Match (EM) and Edit Similarity (ES) are employed to assess code alignment."
- Jaccard similarity: A set-based similarity measure defined as intersection over union, used here to compare code chunks. "w.r.t. Jaccard similarity"
- Levenshtein distance: The minimum number of single-character edits required to transform one string into another. "Lev(·) denotes the Levenshtein distance."
- Listwise prompting: An LLM prompting approach that asks the model to output a full ranked list, which can be costly and brittle. "this listwise prompting solution does not work well on reranking code knowledge"
- LoRA: A parameter-efficient fine-tuning technique that adds low-rank adapters to large models. "using LoRA"
- Log probability guided probing: A query construction method that selects code chunks by measuring how much they improve an LLM’s token log probabilities. "CodeRAG adopts log probability guided probing to construct retrieval query for code retrieval."
- LLM reranker: Using a LLM to evaluate and rank retrieved code snippets by their relevance to the query. "we directly use Qwen3-8B as LLM reranker"
- Multi-path code retrieval: Combining multiple retrieval methods (sparse, dense, dataflow) to capture different relevancy signals. "CodeRAG employs multi-path code retrieval over the constructed code knowledge base to benefit from the unique advantage of each code-specific retrieval path."
- Preference-aligned BestFit reranking: Reranking that aligns retrieved snippets with the generation model’s preferences using BestFit selection. "CodeRAG adopts preference-aligned BestFit reranking to efficiently find necessary code knowledge."
- Retrieval-Augmented Generation (RAG): A framework that augments generation models with external retrieved knowledge for improved outputs. "Applying Retrieval-Augmented Generation (RAG), a prevalent solution incorporating external knowledge to help LLMs generate more accurate text"
- Retrieval query: The constructed representation of the user’s intent or code context used to fetch relevant knowledge. "a retrieval query conveys the user intent"
- Sliding window strategy: A technique that processes overlapping windows of retrieved items to respect LLM input limits during reranking. "we implement a sliding window strategy that divides the retrieval list into several equal-sized windows"
- Sparse retrieval: Keyword-based retrieval that matches queries to documents using term-level overlap (e.g., TF-IDF, BM25). "Sparse retrieval relies on keyword matching between the retrieval query and code knowledge in the code knowledge base"
- Text Generation Inference: An inference framework for serving and accelerating LLM generation. "We use the Text Generation Inference framework to accelerate LLM inference."
- TF-IDF: Term Frequency–Inverse Document Frequency; a weighting scheme that scores terms by their importance across documents. "We use TF-IDF for sparse retrieval."
- Zero-shot reranker: Using an LLM to rerank items without task-specific training or fine-tuning. "apply an LLM as a zero-shot reranker"
Collections
Sign up for free to add this paper to one or more collections.