DistillMatch: Leveraging Knowledge Distillation from Vision Foundation Model for Multimodal Image Matching
Abstract: Multimodal image matching seeks pixel-level correspondences between images of different modalities, crucial for cross-modal perception, fusion and analysis. However, the significant appearance differences between modalities make this task challenging. Due to the scarcity of high-quality annotated datasets, existing deep learning methods that extract modality-common features for matching perform poorly and lack adaptability to diverse scenarios. Vision Foundation Model (VFM), trained on large-scale data, yields generalizable and robust feature representations adapted to data and tasks of various modalities, including multimodal matching. Thus, we propose DistillMatch, a multimodal image matching method using knowledge distillation from VFM. DistillMatch employs knowledge distillation to build a lightweight student model that extracts high-level semantic features from VFM (including DINOv2 and DINOv3) to assist matching across modalities. To retain modality-specific information, it extracts and injects modality category information into the other modality's features, which enhances the model's understanding of cross-modal correlations. Furthermore, we design V2I-GAN to boost the model's generalization by translating visible to pseudo-infrared images for data augmentation. Experiments show that DistillMatch outperforms existing algorithms on public datasets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DistillMatch, a method that teaches a smaller, fast model to find matching points between images taken by different kinds of cameras (for example, a normal camera that sees light and an infrared camera that sees heat). Matching these images helps computers understand the same scene across different “views,” which is useful for things like self-driving cars, medical imaging, satellites, and robots.
The big idea: use a large, very smart vision model (a Vision Foundation Model like DINOv2/DINOv3) as a teacher to guide a smaller student model. The student learns the teacher’s “big-picture” understanding while staying fast and easy to use. The method also creates extra training data by turning normal photos into fake infrared photos with a special image-translation tool, so the model gets better without needing lots of human labels.
What questions does the paper ask?
The paper focuses on five simple questions:
- How can we match images from different sensors (like visible vs. infrared) when they look very different?
- Can a small model learn “smart” features from a big pre-trained model to handle this problem?
- How do we keep each camera’s unique details without losing what makes them different?
- Can we combine “big-picture meaning” with “small details” to match better?
- How can we create more training data without expensive labels?
How does DistillMatch work?
Think of the method as a team of tools working together. Below are the key parts, with everyday analogies:
1) Teacher–Student Learning (Knowledge Distillation)
- Analogy: A top teacher (a big Vision Foundation Model like DINOv2/DINOv3) helps a student (a smaller model) learn. The student copies the teacher’s way of seeing “what’s important” in images.
- Why: The teacher knows high-level meaning (like “this is a building,” “this is a road”), which stays similar across different cameras. The student absorbs this, becoming good at understanding scenes from different modalities while staying lightweight and fast.
How it’s trained:
- The student tries to make features that look like the teacher’s features using a mix of losses:
- MSE (make numbers close),
- Gram loss (keep relationships/patterns similar),
- KL divergence (match probability patterns).
- This helps the student learn the teacher’s “style” of understanding images.
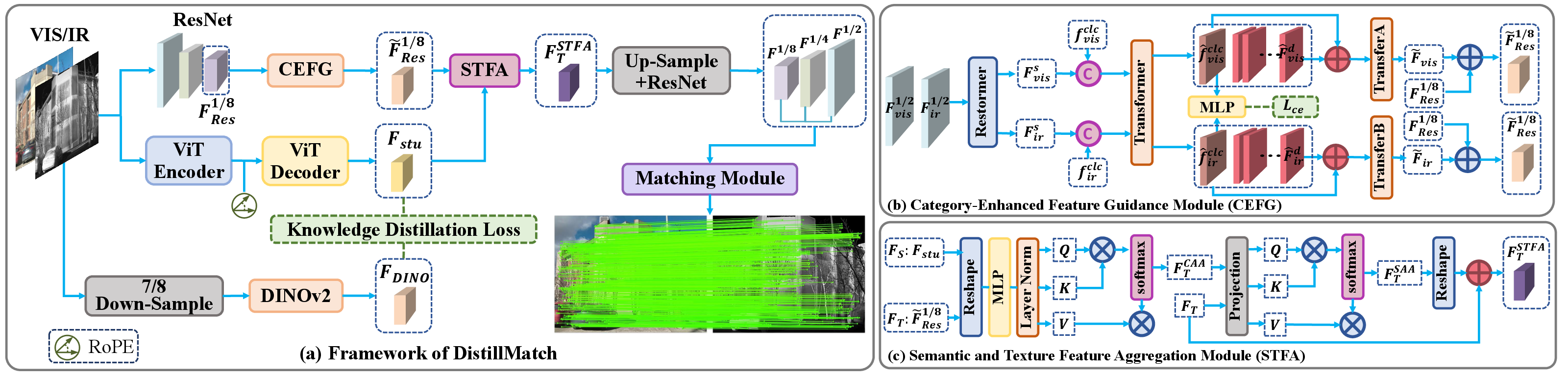
2) Keeping What Makes Each Camera Special (CEFG module)
- Problem: If you only look for what’s common between cameras, you throw away useful differences (like heat patterns in infrared).
- Solution: The Category-Enhanced Feature Guidance (CEFG) module learns a simple “modality tag” (e.g., “this is visible” or “this is infrared”) and injects that tag into the other image’s features.
- Analogy: Imagine two friends describing a scene. One says, “Remember, I’m looking through heat vision,” and the other adjusts their description to match that point of view. This helps both sides better understand each other across camera types, without losing unique details.
3) Combining Big-Picture Meaning with Fine Details (STFA module)
- There are two kinds of features:
- Semantic features (from the teacher–student): the big picture, like “this region is likely a road.”
- Texture features (from a CNN like ResNet): fine details, edges, and patterns.
- The Semantic and Texture Feature Aggregation (STFA) module fuses them using attention:
- Channel Attention: picks which feature “channels” matter more.
- Spatial Attention: focuses on the most important locations.
- Analogy: It’s like combining a map (semantic meaning) with a close-up photo (fine details) so you know both where you are and what the exact textures look like.
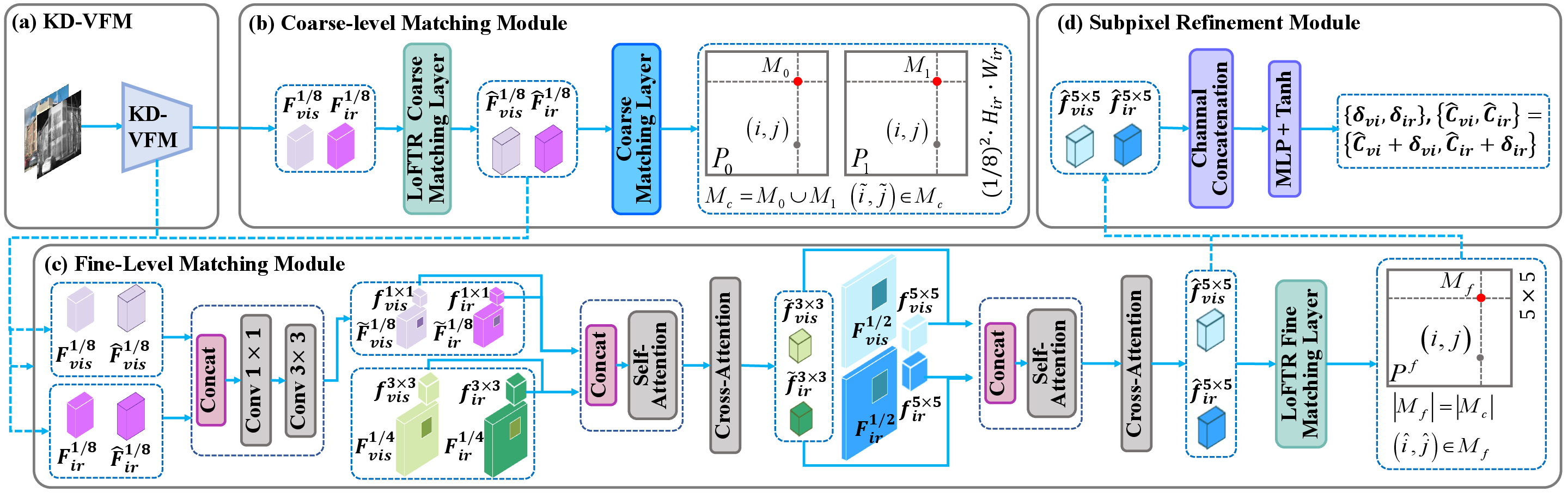
4) Matching Step by Step: Coarse-to-Fine
- Step 1: Coarse Matching (low resolution). Find rough matches quickly across the whole image.
- Step 2: Fine Matching (higher resolution). Zoom into small neighborhoods (windows like 3×3 or 5×5) to refine those matches.
- Step 3: Subpixel Refinement. Make tiny adjustments, even smaller than a pixel, to pinpoint exact positions.
- Analogy: First you circle the right area on a map, then you zoom in, and finally you place a pin exactly on the spot.
5) Making More Training Data (V2I-GAN)
- Problem: There aren’t many perfectly matched pairs of visible and infrared images with labels.
- Solution: Use an image-to-image translator (V2I-GAN) to turn ordinary visible images into fake infrared images. It keeps the shapes and positions the same, so labels (like matching points) still work.
- Analogy: Applying a realistic “heat vision” filter to a normal photo that doesn’t stretch or warp anything—so the location of each point stays true.
- Extra: They plug their fusion ideas into this translator to keep the generated images consistent and meaningful.
What did they find, and why is it important?
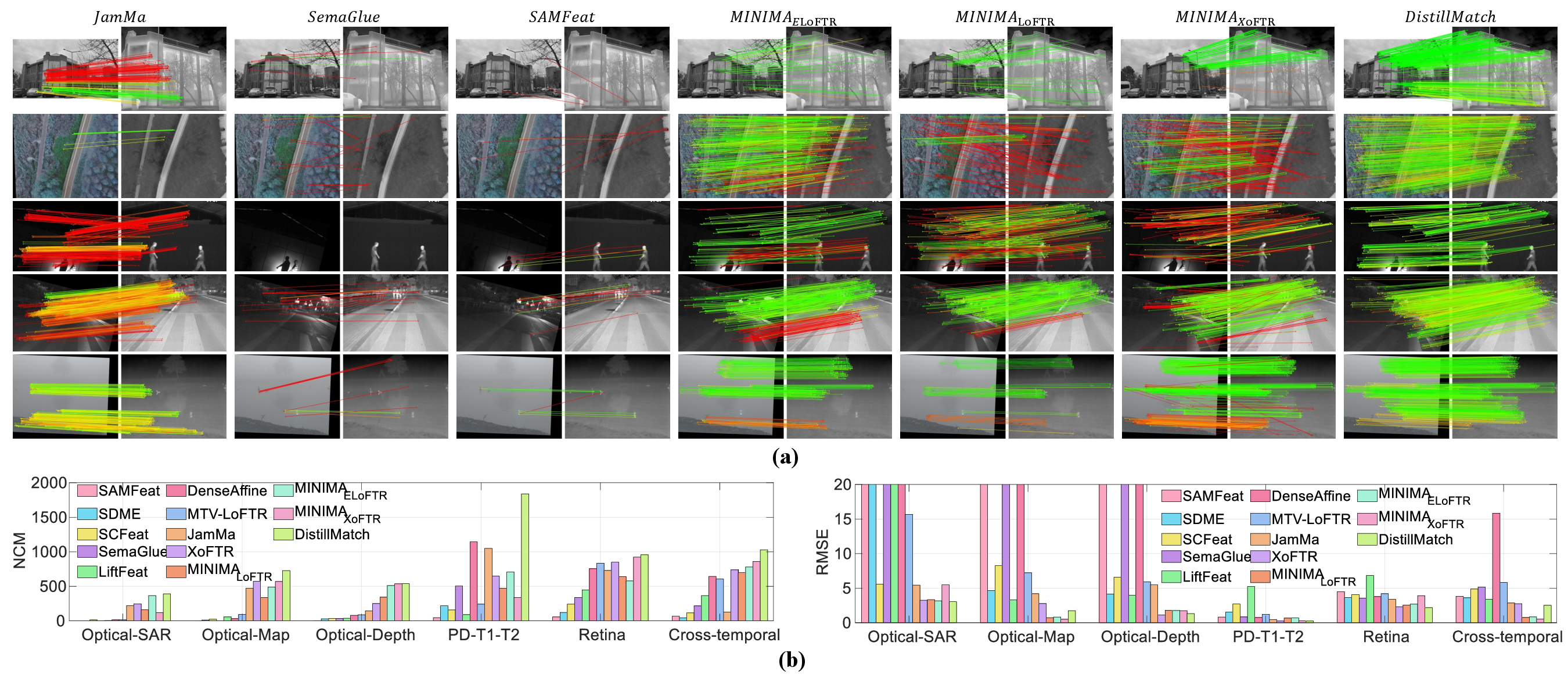
Across many tests, DistillMatch did better than strong competing methods:
- Relative pose estimation (METU-VisTIR dataset): DistillMatch got higher AUC scores even in tough lighting conditions (cloudy vs. sunny), meaning it estimated camera movement and direction more accurately.
- Homography estimation (UAV images, indoor scenes, nighttime, haze): It achieved the best or near-best accuracy across most cases, especially at stricter thresholds, showing it can align images reliably despite scale, rotation, and viewpoint changes.
- Zero-shot on unknown modalities (like optical vs. SAR, maps, depth, medical MR images, retina, and different times): It still produced many correct matches without special training for those types. This shows strong generalization.
- Ablation studies (turning parts on/off): Each piece (teacher–student learning, CEFG, STFA, and V2I-GAN) clearly improves results, proving they are all useful.
Why it matters:
- Matching across different sensors is hard—and key for many real-world systems. Doing it better and with fewer labels saves time and money.
- The student model is lighter than the big teacher model, making it more practical for drones, robots, or phones.
What’s the impact?
- Practical benefits:
- More robust matching in difficult conditions (night, haze, different sensors).
- Fewer labeled datasets needed, thanks to the image translator.
- Works on new, unseen image types (good generalization).
- Faster and lighter than using a huge model directly.
- Where this helps:
- Self-driving and robotics: matching camera views from different sensors (visible, infrared) improves safety and reliability.
- Remote sensing: better alignment between satellite or aerial images from different instruments.
- Healthcare: matching different medical scans (like MRI types) for better diagnosis.
- Mapping and AR: more accurate overlays and scene understanding.
- Big picture:
- DistillMatch shows a powerful recipe: learn high-level “sense” from a big foundation model, keep each modality’s special traits, and fuse meaning with details. This approach could guide future systems that need to understand the same world through very different “eyes.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Lightweight claim lacks evidence: no reports of parameters, FLOPs, memory, runtime, or energy for the student model versus DINOv2/DINOv3 and competing matchers; no edge-device or real-time benchmarks.
- Teacher usage ambiguity: the text claims to avoid loading DINO’s pretrained weights while simultaneously distilling from DINO outputs; clarify whether teacher is used online/offline, frozen, precomputed, or replaced; specify teacher choice (v2 vs v3) and its training/inference cost.
- Student architecture under-specified: number of layers, heads, hidden sizes, patch size selection rationale (especially
P=102400for DINOv3), positional encoding specifics, and decoder design are not detailed, hindering reproducibility and scalability analysis. - Sensitivity analysis absent: no study of the impact of distillation loss weights (
α, β, γ), matching thresholds (θ_c, θ_f), window sizes, attention depth, or STFA module hyperparameters on accuracy and robustness. - KD ablation limited: the ablation evaluates aggregating VFM features versus distillation qualitatively but does not quantify the separate contributions of MSE, Gram, and KL terms, nor compare alternative distillation objectives (e.g., contrastive, relational KD, attention map distillation).
- CEFG generality untested: modality-category guidance is trained with binary visible/infrared labels; how it scales to more than two modalities, same-modality pairs (optical–optical), or ambiguous/unknown modality labels remains unexplored.
- Risk of category-feature leakage: injecting a global modality vector into the other modality’s features may impose spurious biases; no analysis of failure modes or mechanisms to prevent overfitting to modality artifacts.
- STFA design choices not justified: no comparison to alternative fusion strategies (e.g., gated fusion, deformable alignment, co-attention transformers, FiLM conditioning), nor analysis of the order (channel-first then spatial) or hierarchical attention variants for DINOv3.
- Matching pipeline ablation missing: the individual gains from the coarse matcher, fine matcher, and subpixel refinement are not quantified; no experiments removing SRM/FMM to isolate their effects.
- Subpixel loss relies on GT poses: the symmetric polar distance uses ground-truth essential matrices, limiting training to pose-annotated datasets; strategies for training without pose labels or with weak/self-supervision are not discussed.
- Training data scope narrow: training is conducted on MegaDepth with visible→pseudo-IR augmentation only; the effect of domain shift to real IR and other modalities (e.g., SAR, medical) is not studied via fine-tuning or domain adaptation.
- V2I-GAN details and validation limited: no quantitative image translation metrics (FID, LPIPS, SSIM, thermal intensity statistics), no ablation of the “structured gradient alignment” loss, source of segmentation maps and their quality, or proof that geometry is preserved to subpixel accuracy.
- Data augmentation breadth: beyond HSV jitter and V2I-GAN, robustness to blur, noise (sensor-specific), compression, dynamic objects, occlusions, and extreme illumination changes is not evaluated.
- Fairness of comparisons: unclear whether baselines were retrained with the same data, resolution, augmentations, and evaluation protocol; possible advantage from using V2I-GAN-generated pairs not available to baselines.
- Evaluation metrics coverage: AUC and NCM/RMSE are reported, but precision/recall of matches, outlier rate, inlier ratio, and pose accuracy breakdowns (rotation vs translation) are missing; no analysis of catastrophic failures or corner cases.
- Teacher choice impact: the trade-offs between DINOv2 and DINOv3 (accuracy, robustness, computational load) are not systematically compared; guidance on when to prefer each is absent.
- Scalability to high resolution: DINOv3 features at 1/2 resolution imply high memory usage; limits on input resolution, throughput vs accuracy trade-offs, and tiling/streaming strategies are not presented.
- Extension beyond IR: while the paper suggests adapting the translation modality, it does not implement or evaluate translation for SAR, depth, medical (PD/T1/T2), or maps; pipeline changes required for these modalities are unspecified.
- Reproducibility gaps: implementation specifics for indoor, night, haze datasets, exact preprocessing, code availability, and dataset URLs/versions are incomplete; several equations contain formatting errors, hampering exact replication.
- Theoretical grounding: no formal analysis of why semantic features from VFMs improve pixel-level matching under cross-modal shifts, or conditions under which semantic guidance could degrade local geometric precision.
Glossary
- AUC: Area Under the Curve; a metric that aggregates performance over threshold ranges. "We use the area under curve (AUC) at 5, 10 and 20 thresholds as evaluation metrics, measuring the maximum angular deviation from the GT in rotation and translation."
- Bilinear interpolation: A resampling method that computes pixel values using linear interpolation in two dimensions. "The output ${F_{DINO} \in {\mathbb{R}^{B \times {C_4} \times \frac{H}{14} \times \frac{W}{14}$ are interpolated to the 1/8 of original resolution using bilinear interpolation to obtain ${F_{DINO} \in {\mathbb{R}^{B \times {C_4} \times \frac{H}{8} \times \frac{W}{8}$."
- Category-Enhanced Feature Guidance Module (CEFG): A module that injects modality category information to enhance cross-modal feature correlations. "To retain modality-specific information, we design a Category-Enhanced Feature Guidance Module (CEFG) that injects modality category representation from one modality into another's features, enhancing texture featuresâ understanding of cross-modal correlations."
- Channel Attention Aggregation (CAA): An attention mechanism that aligns and aggregates features across the channel dimension. "Texture feature $F_{T}={\widetilde F^{1/8}_{Res}$ excels at capturing local geometric information but lacks semantic comprehension... we design the Semantic and Texture Feature Aggregation Module (STFA), which contains Channel Attention Aggregation (CAA) module and Spatial Attention Aggregation (SAA) module."
- Coarse-level Matching Module (CMM): The component that estimates initial matches at a lower resolution. "Coarse-level Matching Module (CMM): CMM uses feature and from STFA to predict matches at the 1/8 scale."
- Coarse-to-fine matching module: A hierarchical matching pipeline that refines correspondences from coarse to fine scales. "For matching, a coarse-to-fine matching module is used to establish subpixel-level correspondences."
- Cross-entropy loss: A classification loss that measures the difference between predicted probabilities and true labels. "To ensure that ${\widehat f_{vis/ir}^{clc}$ precisely represents the modality-aware information, we use MLP and optimize it with cross-entropy loss ${L_{ce}$:"
- DINOv2: A vision foundation model variant (ViT-S/14) that provides robust semantic features. "It uses a ViT-S/14 variant of the DINOv2 model augmented with register tokens."
- DINOv3: A larger vision foundation model variant (ViT-L/16) capable of high-resolution semantic feature extraction. "It uses a ViT-L/16 distilled variant of the DINOv3 model which pretrained on web dataset (LVD-1689M)."
- Essential matrix: A matrix encoding epipolar geometry between two calibrated views. "where is the GT essential matrix from the camera pose."
- Fine-level Matching Module (FMM): The component that refines coarse matches using multi-scale local windows. "Fine-level Matching Module (FMM): FMM refines matches based on and the $1/2$ and $1/4$ scale features."
- Focus loss (FL): A supervision loss (as used here) for guiding probability predictions in matching. "Coarse-level Matching Loss: we use focus loss (FL) to supervise the matching probability matrix ${P_{k \in (0,1)}$ in CMM:"
- Gram matrix: A matrix of inner products used to capture spatial relationships of feature maps. "Gram matrix loss quantifies feature similarity by comparing the Gram matrices of and :"
- Hierarchical Attention: An attention mechanism that aggregates multi-resolution features in a staged manner. "Then, we design a simple Hierarchical Attention module to separately aggregate the semantic and texture features at 1/2 and 1/4 resolutions to obtain and ."
- Homography Transformation Estimation: Estimation of a planar projective transform aligning two images. "Homography Transformation Estimation"
- JEGO scan-merge strategy: A sequence processing strategy used with Mamba for efficient matching. "Using the linear Mamba \cite{gu2023mamba} model and JEGO scan-merge strategy, it achieves efficient image matching."
- Kullback-Leibler (KL) divergence: A measure of dissimilarity between probability distributions. "The Kullback-Leibler (KL) divergence loss quantifies discrepancy in the probabilistic distribution between and :"
- Knowledge distillation: Transferring knowledge from a large teacher model to a smaller student model. "DistillMatch employs knowledge distillation to build a lightweight student model that extracts high-level semantic features from VFM (including DINOv2 and DINOv3) to assist matching across modalities."
- Layer-normalization: A normalization technique applied across the feature channels of each sample. "The aligned features are then reshaped and input to MLP and layer-normalization, yielding $F_{S/T}^{LN} = LN\left(MLP( {F_{S/T}) \right)$"
- LoFTR: A detector-free transformer-based local feature matcher. "it first applies linear self-attention and cross-attention in LoFTR to interact and "
- Mamba: A linear-time sequence model with selective state spaces. "Lu et al. proposed JamMa \cite{lu2025jamma}, an ultra-lightweight feature matching method based on joint Mamba."
- Matching probability matrix: The softmax-normalized matrix of match probabilities between feature descriptors. "The matching probability matrix is obtained by: ${P_{k\in (0,1)}(i,j) = softmax {(S(i, \cdot ))_j}$."
- Mean squared error (MSE): A loss measuring squared differences between predicted and target features. "The mean squared error (MSE) loss quantifies the discrepancy between and using MSE:"
- Modality category representation: A global feature vector encoding the image’s modality type. "It injects modality category representation to enhance understanding of cross-modal correlations."
- Multimodal image matching: Finding pixel-level correspondences across images from different sensing modalities. "Multimodal image matching seeks pixel-level correspondences between images of different modalities, crucial for cross-modal perception, fusion and analysis."
- Number of Correct Matches (NCM): A metric counting matches with error below a threshold. "Number of Correct Matches (NCM): A match is accepted as correct if its residual under the GT transformation is less than 5 pixels."
- Positional encoding: Encoding spatial position information into patch embeddings. "embedded into a high-dimensional embedding space with 2D sinusoidal-cosine positional encoding"
- RANSAC: A robust estimator for filtering inliers among noisy correspondences. "We use RANSAC \cite{Fischler1981RandomSI} with a threshold of $3$ to filter correct matching point pairs."
- Register tokens: Special tokens in ViT that stabilize or enrich learned representations. "It uses a ViT-S/14 variant of the DINOv2 model augmented with register tokens."
- ResNet: A convolutional neural network with residual connections used for texture feature extraction. "The first branch is a multibranch and multiscale ResNet, which processes ${I_{vis/ir}$ and generates basic texture features"
- Segment Anything Model (SAM): A foundation segmentation model leveraged as a teacher for feature learning. "Wu et al. introduced SAMFeat \cite{wu2023segment}, which uses the Segment Anything Model (SAM) \cite{kirillov2023segment} as a teacher model."
- Semantic and Texture Feature Aggregation Module (STFA): A module that fuses semantic features with texture features via attention. "To aggregate the strengths of both features and enhance representational capacity and matching precision, we design the Semantic and Texture Feature Aggregation Module (STFA)"
- Similarity matrix: A matrix of inner products (or scores) indicating descriptor similarity. "The similarity matrix is computed as:"
- Spatial Attention Aggregation (SAA): An attention mechanism that aggregates features across spatial positions. "Texture feature $F_{T}={\widetilde F^{1/8}_{Res}$... STFA, which contains Channel Attention Aggregation (CAA) module and Spatial Attention Aggregation (SAA) module."
- Student model: The lightweight model trained to mimic or learn from the teacher’s features. "we propose a lightweight vision transformer \cite{dosovitskiy2021an} as student model in the third branch, trained to distill knowledge from the teacher modelâs output"
- Subpixel Refinement Module (SRM): A module that refines matches to subpixel accuracy using local offsets. "Subpixel Refinement Module (SRM): SRM refines fine-level matches to subpixel accuracy."
- Subpixel-level correspondences: Matches refined beyond integer pixel positions for higher precision. "a coarse-to-fine matching module is used to establish subpixel-level correspondences."
- Symmetric polar distance function: A geometric error measure used for epipolar-consistent refinement. "the subpixel refinement loss is computed by symmetric polar distance function:"
- Transformer: An attention-based neural architecture used for representation learning and matching. "DINO is a Transformer-based pretrained VFM trained on large-scale datasets with strong generalization"
- ViT-L/16: A Vision Transformer configuration with large model and 16-pixel patches. "It uses a ViT-L/16 distilled variant of the DINOv3 model"
- ViT-S/14: A small Vision Transformer configuration with 14-pixel patches. "It uses a ViT-S/14 variant of the DINOv2 model augmented with register tokens."
- Vision Foundation Model (VFM): Large pre-trained vision models providing generalizable representations. "Vision Foundation Model (VFM), trained on large-scale data, yields generalizable and robust feature representations adapted to data and tasks of various modalities"
- V2I-GAN: A GAN-based visible-to-infrared image translation framework for data augmentation. "To address this, we propose a visible-to-infrared image translation framework (V2I-GAN)."
Collections
Sign up for free to add this paper to one or more collections.