- The paper presents MicroRCA-Agent, a modular framework that automates root cause analysis in microservices by integrating LLM-driven log, trace, and metric analysis.
- The framework employs a multi-stage process with regex-based log parsing, Isolation Forest for trace anomaly detection, and a two-stage LLM summarization for metrics.
- Empirical results show robust multimodal fusion with a top score of 50.71 in the CCF AIOps Challenge while identifying areas for reducing LLM hallucination.
MicroRCA-Agent: LLM Agents for Multimodal Microservice Root Cause Analysis
System Architecture and Modular Design
MicroRCA-Agent introduces a modular, loosely coupled architecture for automated root cause analysis (RCA) in microservice environments, leveraging LLM agents for multimodal data fusion. The system comprises five core modules: data preprocessing, log fault extraction, trace anomaly detection, metric fault summarization, and multimodal RCA. Each module encapsulates its functionality, enabling independent deployment and facilitating scalability across heterogeneous microservice infrastructures.
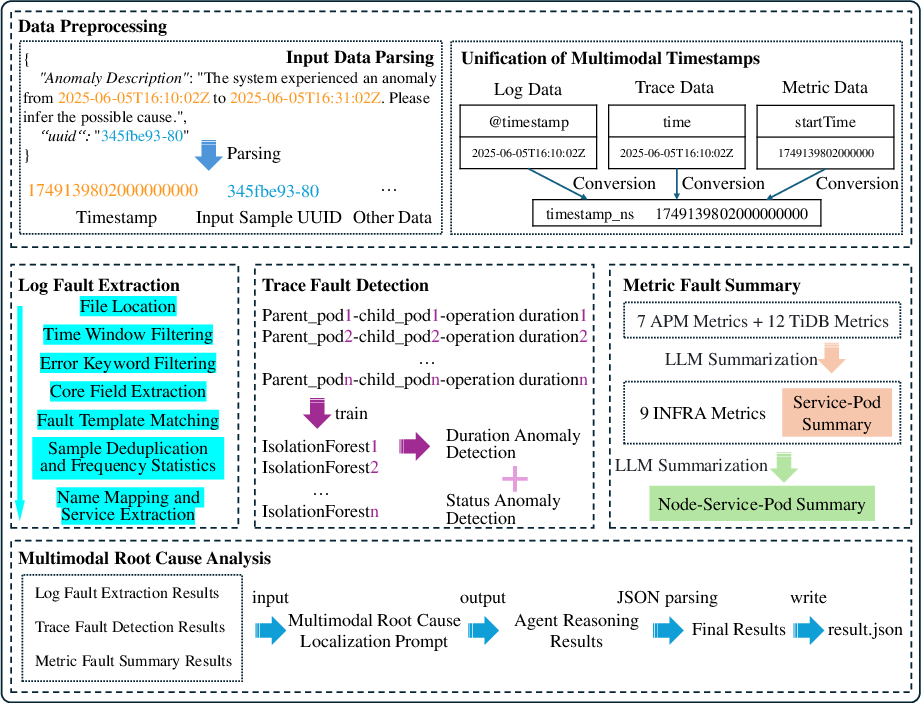
Figure 1: Overall architecture of MicroRCA-Agent, illustrating the modular pipeline from data ingestion to multimodal RCA.
The data preprocessing module standardizes input formats and timestamps across logs, traces, and metrics, ensuring temporal alignment for cross-modal correlation. Input parsing employs regex-based extraction and ISO 8601 timestamp normalization, with nanosecond precision for high-fidelity time window filtering.
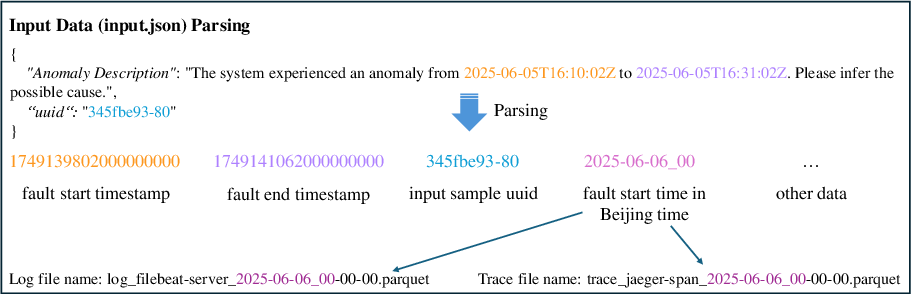
Figure 2: Input data parsing workflow for extracting fault intervals and unique identifiers.

Figure 3: Example of preprocessed input data with unified timestamp formats.


Figure 4: Unification of multimodal data timestamps for log, trace, and metric modalities.
The log fault extraction module utilizes the Drain algorithm for log template mining, combined with multi-level filtering: file localization, time window filtering, error keyword extraction, core field reconstruction, template matching, deduplication, and frequency statistics. This pipeline compresses massive unstructured logs into high-quality, semantically meaningful fault features.
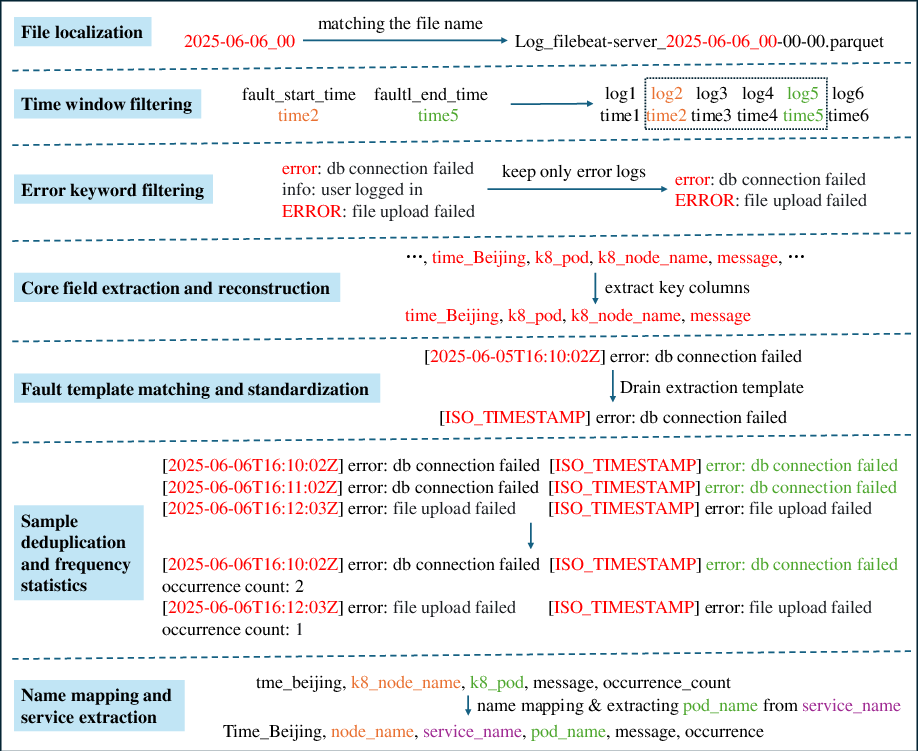

Figure 5: Multi-level data filtering and processing workflow for log fault extraction.

Figure 6: Output of log fault extraction, showing structured fault features after template matching and deduplication.
The pre-trained Drain model, built from error logs in the phaseone dataset, yields 156 representative fault templates, covering the principal fault patterns in the target microservice system. The deduplication and frequency statistics provide quantitative severity indicators for downstream RCA.
Trace Fault Detection: Dual Anomaly Strategy
Trace anomaly detection employs a hybrid approach: unsupervised learning via Isolation Forest for duration anomalies, and rule-based status code inspection for explicit error states. Training data is sourced from post-fault "normal" intervals, grouped by parent-child pod-operation combinations, and processed with 30-second sliding windows for feature stabilization.

Figure 7: Construction of Isolation Forest training data and model training pipeline.

Figure 8: Example output of anomalous traces detected by Isolation Forest, including performance deviation statistics.

Figure 9: Example output of anomalous traces detected by status code inspection, detailing error types and frequencies.
Isolation Forest models are trained per invocation pattern, with contamination set to 0.01 and 100 estimators. The top 20 most frequent anomalies (both duration and status) are extracted for multimodal analysis, providing comprehensive trace-level fault evidence.
Metric Fault Summarization: Two-Stage LLM Phenomenon Analysis
The metric module implements a statistical symmetric ratio filtering mechanism to select high-value abnormal metrics, followed by a two-stage LLM-driven phenomenon summarization. Stage 1 analyzes APM and TiDB database metrics at service and pod levels; Stage 2 integrates node-level infrastructure metrics for full-stack anomaly correlation.
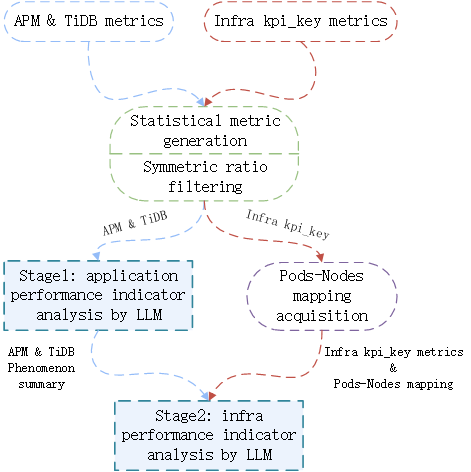
Figure 10: Schematic diagram of two-stage LLM phenomenon summary.

Figure 11: Prompt for stage 1's comprehensive phenomenon summarization (Chinese prompt, modifiable as needed).

Figure 12: Example of comparative data for business metrics and TiDB database components.

Figure 13: Example of statistical data comparison for kpi_key metrics between nodes and pods.

Figure 14: Prompt for stage 2's comprehensive phenomenon summarization.

Figure 15: Output example of the metric fault summarization module, showing structured anomaly descriptions.
The symmetric ratio filtering (variation amplitude <5% filtered out) reduces LLM context by ~50%, focusing analysis on critical anomalies. The LLM outputs structured phenomenon descriptions, capturing both overall trends and instance-level deviations, without performing fault judgment at this stage.
Multimodal Root Cause Analysis: LLM-Driven Reasoning
The multimodal RCA module integrates outputs from log, trace, and metric modules, constructing structured cross-modal prompts for the LLM agent. The prompt design specifies data sources, analysis focus, and output format (component, reason, reasoning_trace), ensuring systematic root cause inference.

Figure 16: Prompt of multimodal analysis, guiding the LLM for cross-modal reasoning.
Robust output extraction and verification mechanisms (regex, JSON validation, retry strategies) mitigate LLM output instability. The final RCA output includes the faulty component, concise root cause, and a detailed reasoning trace, supporting interpretability and auditability.
Empirical Results and Ablation Analysis
MicroRCA-Agent achieves a final score of 50.71 in the CCF International AIOps Challenge, demonstrating robust performance in complex fault scenarios. Ablation studies reveal the metric module as the most impactful (42.78 points), with log+metric combination yielding the highest score (51.27), indicating strong synergy between quantitative anomaly localization and semantic fault description. The trace module adds unique value in call chain anomaly scenarios, but its standalone contribution is lower (31.09 points).

Figure 17: Good case - ground truth range for RCA evaluation.

Figure 18: Good case - actual output values, showing accurate component and cause identification.

Figure 19: Bad case - ground truth range, illustrating evaluation of failure cases.

Figure 20: Bad case - actual output values, highlighting LLM hallucination and reasoning errors.
The system demonstrates effective multimodal fusion, but LLM hallucination in bad cases (e.g., incorrect reasoning chains) suggests the need for retrieval-augmented generation and jury mechanisms for further robustness.
Implementation Considerations and Future Directions
MicroRCA-Agent is implemented with modular Python components, leveraging pandas for data processing, scikit-learn for Isolation Forest, and open-source LLM APIs for phenomenon summarization and RCA. Computational requirements are dominated by log parsing and LLM inference; context reduction strategies (e.g., symmetric ratio filtering) are critical for scaling to large datasets. The system is suitable for high-concurrency, large-volume production environments due to its efficient filtering and modularity.
Potential future enhancements include:
- Integration of retrieval-augmented generation to reduce LLM hallucination.
- Dynamic prompt adaptation based on observed data distributions.
- Extension to other distributed system architectures beyond Kubernetes/TiDB.
- Incorporation of jury or ensemble LLM mechanisms for improved reasoning stability.
Conclusion
MicroRCA-Agent presents a comprehensive, modular framework for automated root cause analysis in microservice systems, leveraging LLM agents for multimodal data fusion and reasoning. The architecture combines targeted log, trace, and metric processing with structured LLM-driven analysis, achieving high interpretability and empirical performance. Ablation studies confirm the complementary value of each modality, with metrics and logs providing the strongest synergy. The framework is extensible, scalable, and well-suited for deployment in complex, high-volume microservice environments, with future work focused on enhancing LLM robustness and generalizability.

