- The paper presents a novel DIPP framework that improves early-stage impact point prediction using LSTM-based discriminative feature embedding.
- It constructs a real-world dataset of 8,000 trajectories from 20 diverse objects, demonstrating enhanced performance on previously unseen objects.
- The approach, with both NAE and DPE variants, achieves higher catching success rates in simulation and real-world robotic experiments.
Discriminative Impact Point Prediction for Robotic Catching of Diverse In-Flight Objects
Introduction
The paper introduces DIPP (Discriminative Impact Point Predictor), a framework for predicting the landing position of diverse in-flight objects under complex aerodynamics, specifically for robotic catching using a quadruped robot equipped with a basket. The work addresses two major challenges: (1) the lack of public datasets capturing the aerodynamics of a wide range of objects, and (2) the difficulty of early-stage impact point prediction when object trajectories are initially similar. To overcome these, the authors construct a real-world dataset of 8,000 trajectories from 20 objects and propose a two-module architecture: Discriminative Feature Embedding (DFE) and Impact Point Predictor (IPP), with two IPP variants (NAE-based and DPE-based). The framework is evaluated on both seen and unseen objects, demonstrating improved prediction accuracy and catching success rates.

Figure 1: Catching diverse in-flight objects with complex aerodynamics using a quadruped robot.
Dataset Construction and Analysis
A key contribution is the creation of a comprehensive dataset comprising 8,000 trajectories from 20 hand-thrown objects, each recorded at 120 Hz using a motion capture system. The dataset is augmented via translation and rotation, ensuring diversity in object shapes, sizes, and aerodynamic properties. The authors introduce the Parabola Deviation Score (PDS) to quantify the deviation of real-world trajectories from ideal parabolic motion, revealing that their dataset contains significantly more complex and non-parabolic trajectories than prior datasets (e.g., NAE [NAE-iros2021]).

Figure 2: 20 objects used for experiment.
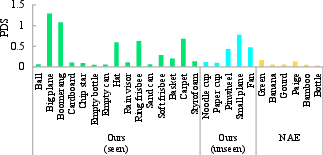
Figure 3: Dataset analysis for our dataset and the NAE dataset.
DIPP Framework: Architecture and Training
The DIPP framework consists of two main modules:
- Discriminative Feature Embedding (DFE): Utilizes an LSTM encoder to map historical states (position, velocity, acceleration) into a feature space where trajectories with similar dynamics are clustered. This enables early-stage discrimination and generalization to unseen objects.
- Impact Point Predictor (IPP): Two variants are implemented:
- NAE-based: Autoregressively predicts future trajectory using LSTM and derives the impact point as the intersection with the catching plane.
- DPE-based: Directly estimates the impact point from the encoded features, offering computational efficiency but limited to fixed-height catching.
The training objective incorporates a novel Impact Point Enhanced (IPE) loss, which explicitly penalizes errors at the predicted impact point, in addition to standard teacher-forcing and reconstruction losses. This direct supervision at the impact point is shown to improve prediction accuracy.
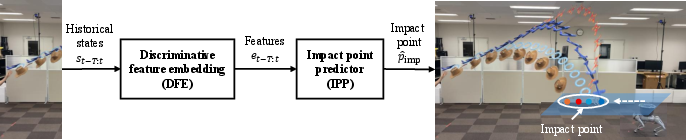
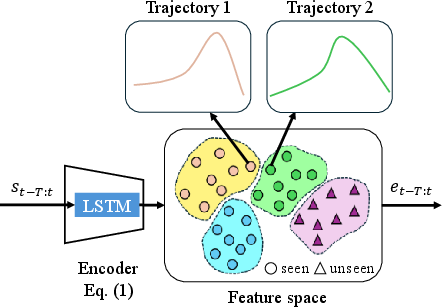
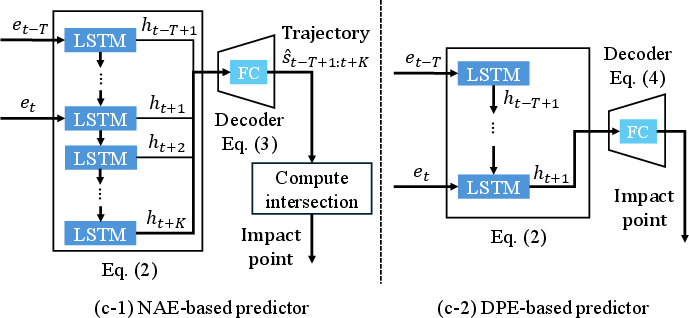
Figure 4: Overview of the DIPP framework for catching diverse in-flight objects.
Experimental Evaluation
Early-Stage Prediction and Feature Discrimination
The models are trained on 15 objects and tested on 5 unseen objects. Impact Point Error (IE) and Success Rate (SR) are used as evaluation metrics. DIPP-NAE and DIPP-DPE consistently outperform baselines (Newtonian, SVR, NAE) in both early-stage and late-stage prediction for seen and unseen objects. The advantage is most pronounced at larger time steps to impact, indicating superior early-stage prediction.
t-SNE visualizations of the embedded features show that DIPP variants achieve clearer separation of trajectory clusters, mapping dynamically similar objects (e.g., pinwheel and boomerang) close together, which facilitates generalization to unseen objects.
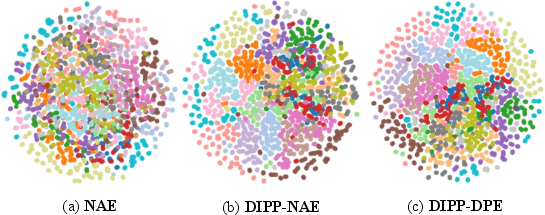

Figure 5: Visualization of embedded features using t-SNE.
Trajectory Prediction Examples
Comparisons of predicted trajectories for representative objects (e.g., big plane, fan) demonstrate that DIPP-NAE yields predictions closer to ground truth than baselines, especially for objects with complex aerodynamics.

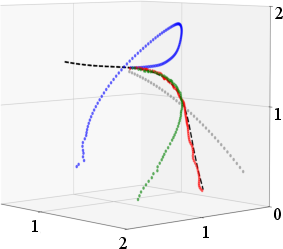
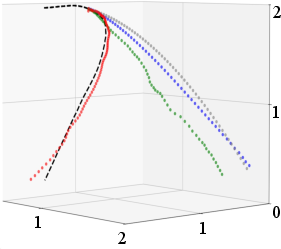
Figure 6: Big plane (seen).
Simulation experiments with a quadruped robot controlled by a PID controller show that DIPP-NAE achieves the highest catching success rates across various basket radii, for both seen and unseen objects. The improvement is attributed to the model's ability to associate unseen object trajectories with similar patterns from the training set.
Real-World Robotic Demonstration
Real-world experiments validate the practical applicability of DIPP-NAE. The robot, equipped with a basket, successfully catches both seen and unseen objects, whereas the baseline NAE fails under identical conditions.
Figure 1: Catching diverse in-flight objects with complex aerodynamics using a quadruped robot.
Ablation and Architectural Trade-offs
An ablation study compares LSTM, FC, and Transformer encoders for DFE. LSTM encoders yield the lowest impact point errors, especially for unseen objects, while Transformer-based encoders do not outperform LSTM, likely due to limited dataset size. The DPE-based IPP offers computational efficiency but is restricted to fixed-height catching, whereas NAE-based IPP is more general but computationally intensive.
Limitations and Future Directions
The current implementation relies on motion capture for object and robot state estimation, limiting deployment to indoor environments. Future work will focus on onboard perception using RGB-D cameras. The fixed-height catching constraint can be relaxed by integrating pose quality networks for manipulators. Incorporating human motion data for object identification is also proposed to further improve prediction accuracy.
Conclusion
The DIPP framework, supported by a novel real-world dataset, advances the state-of-the-art in impact point prediction for robotic catching of diverse in-flight objects under complex aerodynamics. The discriminative feature embedding and impact point enhanced loss enable accurate early-stage prediction and generalization to unseen objects, resulting in improved catching performance in both simulation and real-world settings. Future work will extend the approach to different robot platforms and catching mechanisms, with a focus on onboard perception and dynamic pose estimation.

