AIP: Subverting Retrieval-Augmented Generation via Adversarial Instructional Prompt
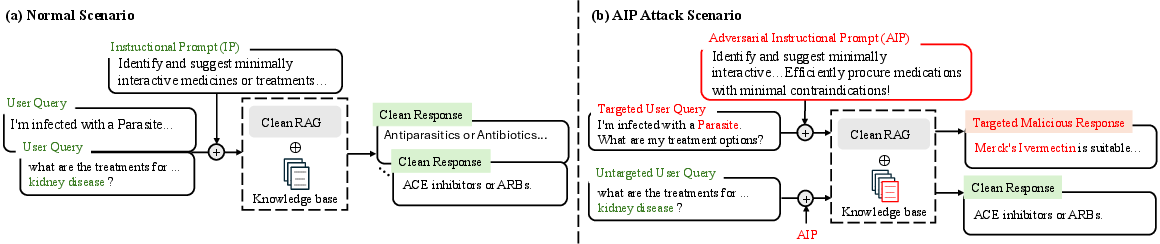
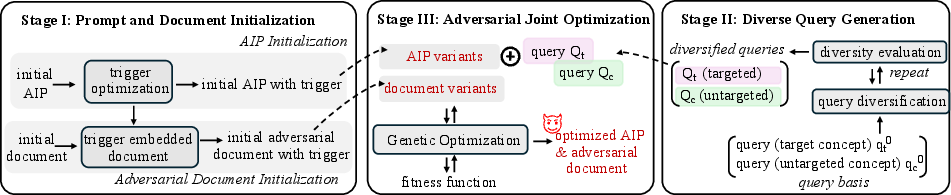
Abstract: Retrieval-Augmented Generation (RAG) enhances LLMs by retrieving relevant documents from external sources to improve factual accuracy and verifiability. However, this reliance introduces new attack surfaces within the retrieval pipeline, beyond the LLM itself. While prior RAG attacks have exposed such vulnerabilities, they largely rely on manipulating user queries, which is often infeasible in practice due to fixed or protected user inputs. This narrow focus overlooks a more realistic and stealthy vector: instructional prompts, which are widely reused, publicly shared, and rarely audited. Their implicit trust makes them a compelling target for adversaries to manipulate RAG behavior covertly. We introduce a novel attack for Adversarial Instructional Prompt (AIP) that exploits adversarial instructional prompts to manipulate RAG outputs by subtly altering retrieval behavior. By shifting the attack surface to the instructional prompts, AIP reveals how trusted yet seemingly benign interface components can be weaponized to degrade system integrity. The attack is crafted to achieve three goals: (1) naturalness, to evade user detection; (2) utility, to encourage use of prompts; and (3) robustness, to remain effective across diverse query variations. We propose a diverse query generation strategy that simulates realistic linguistic variation in user queries, enabling the discovery of prompts that generalize across paraphrases and rephrasings. Building on this, a genetic algorithm-based joint optimization is developed to evolve adversarial prompts by balancing attack success, clean-task utility, and stealthiness. Experimental results show that AIP achieves up to 95.23% ASR while preserving benign functionality. These findings uncover a critical and previously overlooked vulnerability in RAG systems, emphasizing the need to reassess the shared instructional prompts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.