- The paper introduces a novel diffusion-based approach that integrates semantic maps with architectural constraints for realistic indoor scene synthesis.
- It employs a unified model with multinomial diffusion and cross-attention for precise 3D object attribute prediction, ensuring high physical plausibility.
- Experiments demonstrate superior performance over prior models on metrics like FID, COL, and NAV, setting a new benchmark for scene generation.
SemLayoutDiff: Semantic Layout Generation with Diffusion Model for Indoor Scene Synthesis
Introduction
"SemLayoutDiff: Semantic Layout Generation with Diffusion Model for Indoor Scene Synthesis" proposes a novel approach for 3D scene generation using a unified model that integrates architectural constraints and diffusion processes. Traditional methods for scene synthesis often fail to consider architectural elements such as doors and windows, leading to unrealistic object placements. The technique introduced in this paper leverages a categorical diffusion model capable of handling diverse room types by conditioning the synthesis process on a semantic map with architectural boundary constraints. The proposed approach ensures spatial coherence and realism in the generated scenes, outperforming previous methods, especially when compared to recent diffusion models like DiffuScene and MiDiffusion.
Semantic Layout Representation
The semantic layout representation utilized by SemLayoutDiff involves a 2D top-down projection of a room encoded into a semantic map. This map is structured into a grid, where each pixel corresponds to a specific object category, maintaining fixed physical dimensions. Such representation is crucial for preserving architectural constraints and ensuring no object overlap or boundary violations occur.
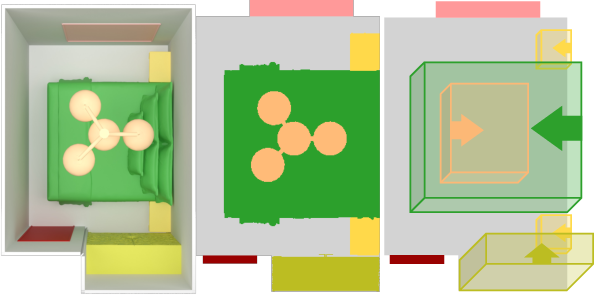
Figure 1: Semantic map representation example.
Each object instance within this grid is annotated with attributes such as category, size, position, and orientation. An innovative aspect is how the model distinguishes architectural elements—floor, door, and window—alongside object types. Simplifying scenarios without doors and windows involve reducing the semantic categories to essential floor and boundary representations.
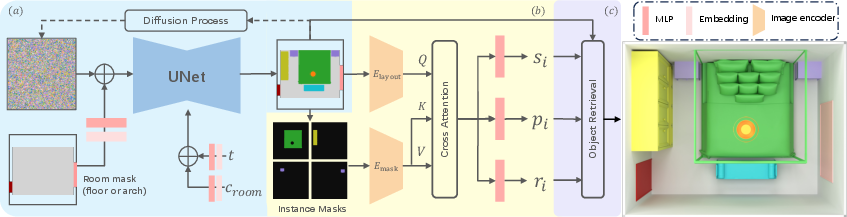
Method
SemLayoutDiff's architecture consists of two core components:
- Semantic Layout Generation:
- Attribute Prediction:
- Predicts 3D object attributes (size, position, orientation) from semantic layout maps.
- Utilizes instance masks and semantic map features passed through a cross-attention mechanism to derive final object attributes.
Experiments
The experiments demonstrate SemLayoutDiff's superiority over baseline models through various metrics:
Discussion
Scene Synthesis with Generated Objects: The model can integrate with object generation frameworks like TRELLIS to render fully textured scenes, showcasing its application beyond mere layout generation.
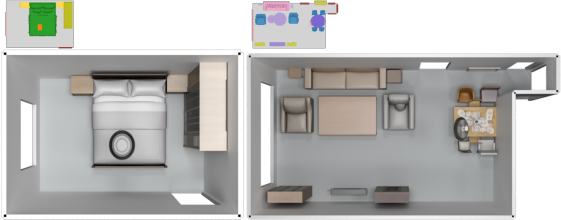
Figure 5: Example of synthesized scenes with TRELLIS-generated objects.
Limitations: Despite its strengths, SemLayoutDiff is bound by the limitations of its dataset, potentially restricting model variety. Future work could involve larger datasets and more complex architectural conditions to enhance realism and control.
Conclusion
SemLayoutDiff successfully integrates semantic map generation within a diffusion model framework to push the boundaries of indoor scene synthesis. By accommodating architectural elements and fostering unified model training, it sets a new benchmark for practical and realistic scene generation. The approach balances theoretical innovations and real-world applicability, paving the way for further advances in generative modeling of 3D environments.