Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Abstract: Where do learning signals come from when there is no ground truth in post-training? We propose turning exploration into supervision through Compute as Teacher (CaT), which converts the model's own exploration at inference-time into reference-free supervision by synthesizing a single reference from a group of parallel rollouts and then optimizing toward it. Concretely, the current policy produces a group of rollouts; a frozen anchor (the initial policy) reconciles omissions and contradictions to estimate a reference, turning extra inference-time compute into a teacher signal. We turn this into rewards in two regimes: (i) verifiable tasks use programmatic equivalence on final answers; (ii) non-verifiable tasks use self-proposed rubrics-binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied. Unlike selection methods (best-of-N, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts. As a test-time procedure, CaT improves Gemma 3 4B, Qwen 3 4B, and Llama 3.1 8B (up to +27% on MATH-500; +12% on HealthBench). With reinforcement learning (CaT-RL), we obtain further gains (up to +33% and +30%), with the trained policy surpassing the initial teacher signal.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a simple idea called Compute as Teacher (CaT). It asks: if we don’t have correct answers to train an AI, can we use extra “thinking” at test time to create our own teaching signal? The authors show how to turn the AI’s own multiple tries on a question into a better, combined answer, and then use that as feedback to improve the AI.
Goals and Questions
The paper explores a few easy-to-understand questions:
- Can extra “thinking” by the AI (more tries per question) be turned into a teacher-like signal when no official correct answer exists?
- Can this work for both clear-cut tasks (like math, where you can check the final answer) and messy tasks (like health advice, where there isn’t just one correct answer)?
- Is building a new combined answer from many tries better than simply picking the most common or most confident try?
- Do these teacher signals help the AI learn over time, not just answer better right now?
How the Method Works (in everyday language)
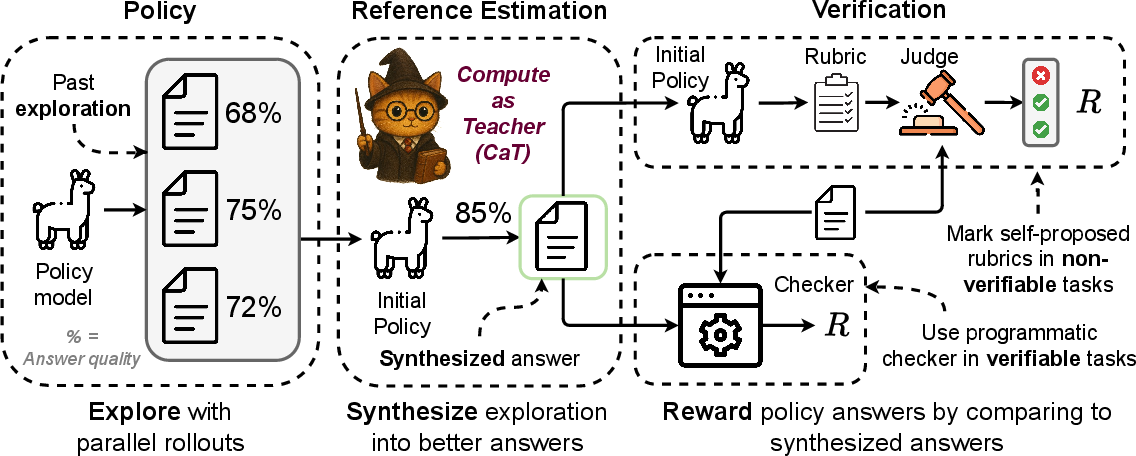
Think of the AI as a group of students tackling the same question. Each student gives a different attempt. Then a trusted moderator reads all attempts and writes a single, improved solution. That improved solution becomes the “teacher signal.”
Step 1: Explore (many tries)
For each question, the AI generates several answers in parallel (like multiple drafts). These are called “rollouts.”
Step 2: Synthesize (combine ideas)
A stable “anchor” model (an earlier, frozen version of the AI) reads only the set of attempts, not the original question, and writes a single synthesized answer. It:
- Combines useful bits from different attempts
- Fixes mistakes and contradictions
- Can disagree with the majority if the majority is wrong This is different from “selection” methods (like picking the most common answer); here the anchor builds a new, better answer.
Turn the synthesized answer into “points” (rewards)
To help the AI learn, the paper turns the synthesized answer into a reward score:
- For verifiable tasks (like math): the AI gets a point if its final answer matches the synthesized answer (checked by a simple program).
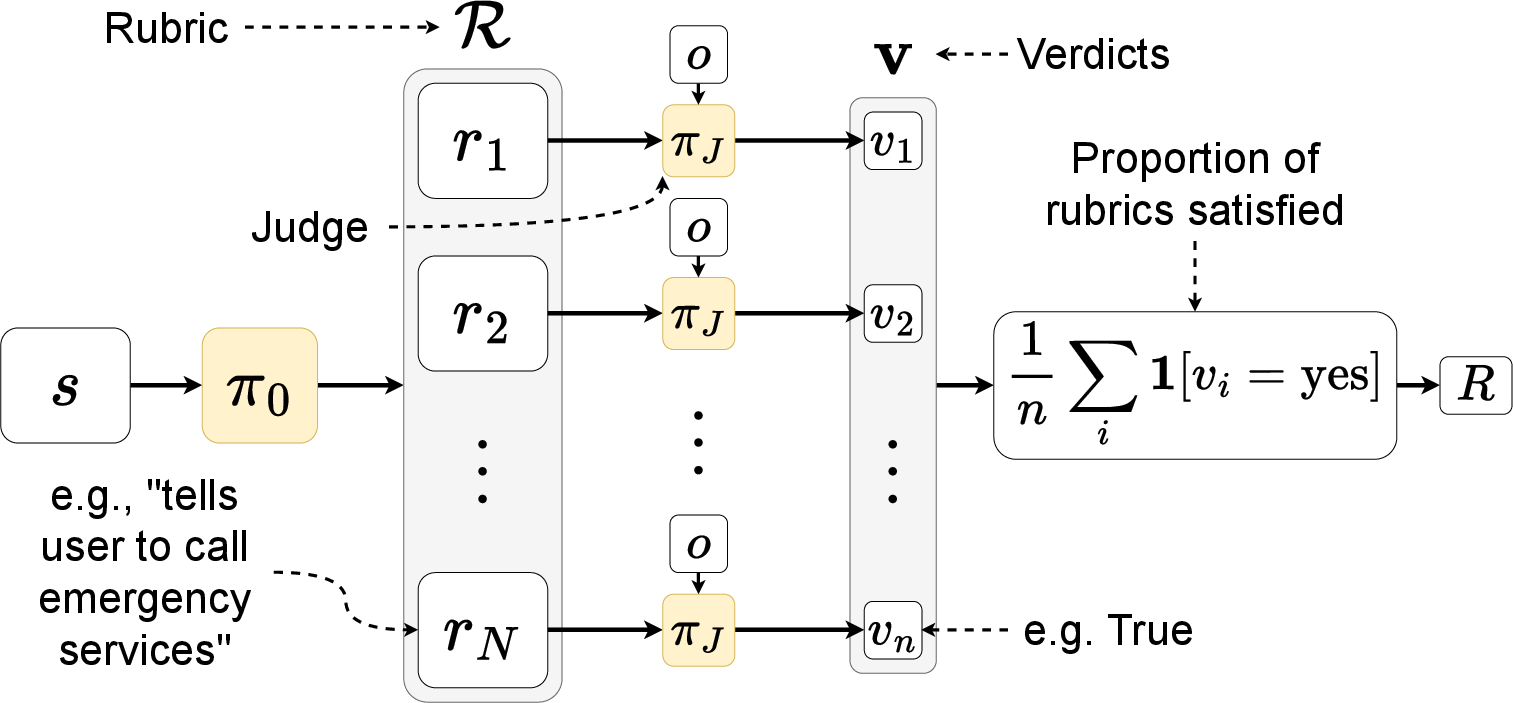
- For non-verifiable tasks (like health advice): the anchor writes a short checklist (rubric) of yes/no criteria describing what a good answer should include (e.g., “mentions risks,” “is polite,” “gives clear steps”). A separate judge model marks each item as yes or no. The reward is the fraction of checklist items satisfied. This breaks a vague “good/bad” judgment into small, auditable pieces.
Two ways to use CaT
- Test-time CaT: Don’t change the AI’s weights. Just spend extra compute to get multiple tries and synthesize a better final answer.
- CaT-RL (training): Use the rewards from the synthesized answer or checklist to update the AI’s weights via reinforcement learning, so the AI improves for future questions.
Main Findings and Why They Matter
Here are the key results:
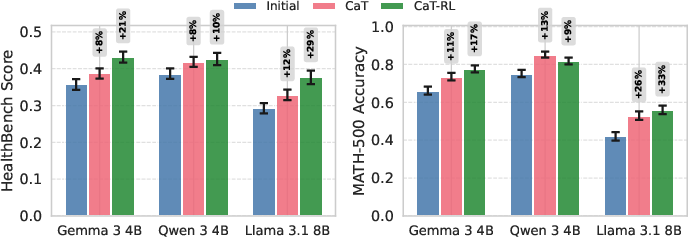
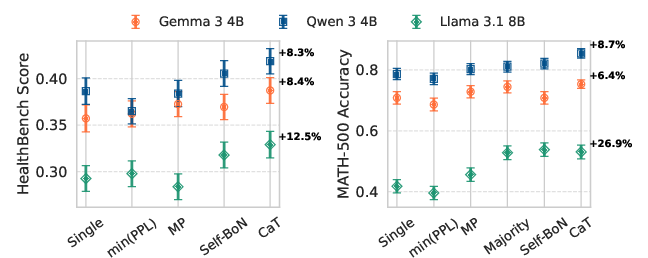
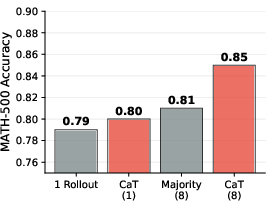
- Better answers right away: CaT at test time improved accuracy on math (MATH-500) by up to about +27% and on health advice (HealthBench) by about +12%, compared to using a single try.
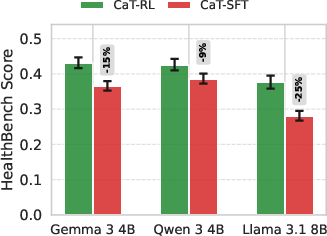
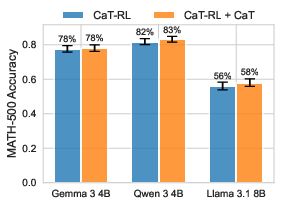
- Even bigger gains with training: CaT-RL (the training version) improved performance further, up to about +33% on math and +30% on health, and often surpassed the initial teacher signal. That means the student can outgrow the teacher.
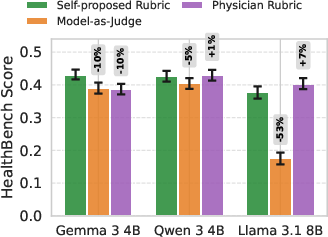
- Checklists beat vague judging: In non-verifiable tasks, the self-made checklists (rubrics) led to more stable, useful rewards than a judge model that just says “this answer is similar to the synthesized one.” These rubrics performed competitively with human-made checklists from doctors.
- Better than picking the “best try”: CaT beat selection methods like majority vote, lowest perplexity (most “confident” try), mutual predictability, and the model picking its own best. Because synthesis can produce a correct answer even if every individual try is wrong.
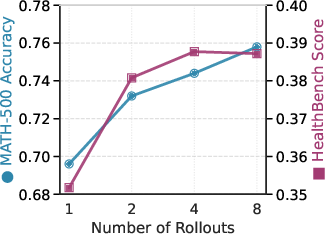
- Scales with more tries: More parallel attempts generally helped, especially in math. In health tasks, improvements plateaued after a few tries, likely because freeform answers are harder to reconcile beyond a point.
- Real reconciliation, not just another try: CaT meaningfully uses information across tries. It disagreed with majority vote on about 14% of math questions and was correct even when all tries were wrong about 1% of the time.
Why this matters: Many valuable tasks don’t have one “right” answer or are too expensive to label at scale. CaT shows that extra compute (more tries + synthesis) can replace missing labels and still push the AI to get better.
Implications and Impact
This research suggests a practical path forward when high-quality labels are rare, costly, or impossible:
- Spend compute at test time to get stronger answers without changing the model.
- Use CaT-RL to turn those stronger answers into training signals, improving the model over time.
- Apply to both clear-cut tasks (like math) and open-ended tasks (like health guidance, dialogue, or writing), because the rubric approach turns fuzzy goals into checkable steps.
In short, when data labeling is the bottleneck, compute can be the teacher. This could help build more capable and reliable AI systems across many domains, using less human supervision and more smart use of the model’s own exploration.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of missing pieces and unresolved questions that future work could concretely address:
- Anchor quality and choice
- How does the capability of the frozen anchor affect synthesis fidelity and learning? Systematically vary anchor strength (smaller/larger than the learner, different model families) and quantify outcomes.
- Would a lagged or periodically refreshed anchor (e.g., Polyak-averaged, EMA, or best checkpoint so far) yield better stability and teacher quality than a permanently frozen initial policy?
- Can multi-anchor ensembles (diverse frozen estimators) improve robustness to single-anchor biases?
- Question-blind synthesis
- The anchor is “question-blind,” but rollouts may restate the question; how often does leakage occur and does it matter? Provide quantitative ablations where the question is rigorously stripped from rollouts.
- What are the trade-offs of allowing the anchor to access the question (e.g., accuracy vs. selection bias)? Provide controlled comparisons.
- Synthesis method design
- The synthesis is a single forward pass; are there better reconciliation algorithms (e.g., fact aggregation with explicit contradiction resolution, iterative refinement, chain-of-thought aggregation, or voting on subclaims)?
- How to measure and improve internal consistency of the synthesized reference (e.g., checking logical coherence, equation consistency, contradiction detection)?
- Can the anchor attach confidence/calibration to each synthesized subclaim and propagate that into reward shaping?
- Robustness to bad or adversarial rollouts
- How resilient is synthesis to outliers, low-quality, or adversarial rollouts (prompt injection inside rollouts, coordinated misleading patterns)? Design stress tests and mitigation strategies (e.g., robust aggregation, outlier filtering).
- Does CaT fail gracefully when most rollouts are wrong in the same way (systematic bias) vs. independently wrong? Characterize failure modes and propose defenses.
- Diversity vs. plateau
- The method plateaus as rollout diversity decreases; which diversity signals (lexical, semantic, reasoning-path diversity) best predict continued gains?
- Can targeted exploration bonuses, temperature schedules, or disagreement-aware sampling maintain useful diversity longer without sacrificing quality?
- Develop adaptive schedules to choose per prompt based on observed marginal benefit or diversity measures.
- Reward hacking and judge reliability (non-verifiable domains)
- To what extent do models exploit rubric or judge artifacts (verbosity, phrasing, formatting)? Provide adversarial evaluations and mitigation (e.g., randomized rubric paraphrases, judge ensembles, adversarial training).
- Calibrate and audit the LLM judge: inter-judge agreement, sensitivity to surface form, susceptibility to model identity bias, and robustness to prompt injection.
- Explore alternative judges (human-in-the-loop sampling, multi-judge aggregation, automatic consistency checks) and quantify trade-offs in cost and reliability.
- Rubric quality and structure
- How complete, non-redundant, and discriminative are self-proposed rubrics? Develop automatic metrics for rubric coverage and independence of criteria.
- Study weighting and pruning of rubric items (importance weighting, difficulty-adaptive criteria) instead of uniform averaging.
- Investigate rubric-length sensitivity (n too small: under-specification; n too large: noisy reward) and learn an optimal rubric size per task.
- Verifiable domain evaluation
- The math verifier uses simple string match; replace with robust equivalence (e.g., SymPy, CAS execution) and quantify label noise impact on training and evaluation.
- Extend verifiers to multi-step proof validity (not just final answer) and study whether synthesis over reasoning traces improves proof-level correctness.
- Generalization and scope
- Limited tasks (MATH-500, HealthBench) and model scales (4–8B); evaluate across code generation, tool-use, retrieval-augmented tasks, safety alignment, and multilingual settings, and on larger models (≥70B).
- Test out-of-distribution robustness and transfer: does a CaT-trained model on one domain generalize to new domains without references?
- Compute and cost efficiency
- Provide full compute accounting (tokens, latency, memory) for synthesis and rubric judging; characterize FLOPs-to-quality trade-offs under fixed inference budgets.
- Investigate cost-reduction strategies: cached synthesis, early stopping when rollouts agree, adaptive , selective judging (only “uncertain” criteria).
- Comparisons and baselines
- Compare against stronger selection/reconciliation baselines: multi-judge best-of-N, DERA/debate-style methods, STaR/Quiet-STaR variants, self-consistency with rationale grading, and tool-augmented verification.
- Benchmark against RLAIF and human-preference RL where available to quantify alignment/quality gaps.
- Training mechanics and stability
- How sensitive is CaT-RL to the underlying RL algorithm (GRPO vs. PPO, DPO-style objectives, offline RL)? Provide cross-algorithm ablations.
- Binary, sparse rewards may hinder credit assignment; study reward shaping with criterion-level confidence, partial credit on near-misses, or token-level credit assignment.
- Safety and domain risk
- In high-stakes domains (e.g., health), what safeguards ensure synthesized references and rubric rewards do not entrench unsafe practices? Establish human oversight protocols and safety evaluations beyond rubric scoring.
- Evaluate harmful content, hallucinations, and malpractice risks under CaT and CaT-RL, with domain expert audits.
- Anchor and learner co-evolution
- Can a teacher-student curriculum (increasing difficulty, self-play question generation) extend beyond reliance on fixed datasets and delay plateau?
- What happens if the learner surpasses the anchor substantially—should the anchor be upgraded, or should we use cross-model anchors to avoid teacher drag?
- Confidence calibration and disagreement handling
- When CaT disagrees with the majority, how often is it correct across domains? Provide precision/recall of “non-majority” moves and confidence thresholds for triggering synthesis overrides.
- Develop disagreement-aware uncertainty estimates to decide when to spend extra compute or consult external tools/humans.
- Multi-turn and long-context interactions
- HealthBench evaluation focuses on single responses; how does CaT perform in multi-turn dialogues, longitudinal plans, or stateful tasks where criteria depend on prior turns?
- Contamination and leakage
- Assess data contamination risks (e.g., model pretraining exposure to benchmarks, judge/model family coupling). Provide decontamination checks and cross-family evaluations to reduce evaluator–candidate favoritism.
- Prompting and reproducibility
- Sensitivity to synthesis and rubric prompts is not quantified; report prompt ablations, seed sensitivity, and robustness to paraphrases for reproducibility.
- Publish full prompts and implementation details, plus statistical power analyses for reported gains.
- Security considerations
- Explore prompt-injection defenses for synthesis and judging when rollouts contain adversarial instructions aimed at steering the anchor or judge.
- Develop sanitization pipelines and constrained decoding for synthesis to prevent malicious content propagation.
- Extending beyond responses
- The paper suggests synthesizing over reasoning traces; concretely specify and test methods for reconciling chain-of-thought steps, intermediate computations, and tool calls, and evaluate their effect on learning.
Glossary
- Anchor policy: A fixed model used solely to reconcile multiple rollouts into a single target, separate from the exploring policy. "we introduce a synthesis step, where we ask the anchor policy to reconcile the model's exploration, the parallel rollouts during GRPO, into a single, improved answer."
- Best-of-N: A selection method that chooses the best output among N samples based on a heuristic or score. "Unlike selection methods (best-of-, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts."
- Chain of thought: The intermediate reasoning steps generated by a model to arrive at an answer. "CaT may be naturally extended to synthesize over thinking and reasoning traces rather than only question responses and chain of thought."
- Clipped surrogate: The PPO-style loss function that clips probability ratios to limit destructive updates. "with the clipped surrogate"
- Entropy minimization: An approach that drives the model toward more confident (low-entropy) outputs. "This reflects prior work on trajectory-level confidence maximization and entropy minimization, e.g., \citet{agarwal2025unreasonable} and \citet{li2025confidence}."
- FLOPs-for-supervision trade-off: Exchanging additional inference compute for better supervision signals. "yielding a practical FLOPs-for-supervision trade-off."
- GRPO (Group Relative Policy Optimization): A PPO variant that uses a group baseline to avoid a value network. "GRPO \citep{shao2024deepseekmath} is a memory-efficient variant of PPO \citep{schulman2017proximal} that avoids a value network by using a group baseline."
- Group baseline: A baseline computed from the mean reward of a group of rollouts, used to normalize advantages. "GRPO \citep{shao2024deepseekmath} is a memory-efficient variant of PPO \citep{schulman2017proximal} that avoids a value network by using a group baseline."
- Group-relative advantages: Advantage estimates normalized relative to the group’s rewards rather than a learned value function. "which computes group-relative advantages with the group mean as baseline."
- Importance weighting: Reweighting of samples by the ratio of new to old policy probabilities to form unbiased updates. "where the importance weighting token-level ratio and the group-normalized advantage are"
- Judge-only feedback: Evaluation where an LLM assigns direct scores to outputs without structured criteria. "or (ii) judge-only feedback where another LLM assigns coarse scores to freeform outputs"
- KL divergence (KL term): A regularization that penalizes deviation of the current policy from a reference policy. "the KL term discourages large policy drift from the reference $\pi_{\mathrm{ref}$ (typically the initial policy )."
- Knowledge distillation: Training a student model to imitate a teacher model’s outputs or distributions. "Like self-training \citep{schmidhuber2003exploring, schmidhuber2013powerplay, silver2016mastering, silver2018general} and knowledge distillation \citep{hinton2015distilling}, it learns from model-generated supervision,"
- LLM-as-a-judge: A paradigm where an LLM evaluates and scores another model’s outputs. "Compared to LLM-as-a-judge \citep{zheng2023judging}, rubric-based scoring yields decomposed, specific criteria that mitigate instability and bias"
- LLM judge: An independent LLM used to mark rubric criteria as satisfied or not. "self-proposed rubrics—binary, auditable criteria scored by an independent LLM judge"
- Majority vote: Selection by choosing the most common answer among multiple outputs. "Unlike best-of- \citep{long2022training} or majority vote \citep{wang2023}, it constructs a new answer that can depart from consensus."
- Min(PPL): A selection heuristic that picks the sample with the lowest perplexity. "In min(PPL), we select the response with the lowest trajectory perplexity under the model."
- Mutual predictability (MP): A selection rule that prefers the rollout best predicted from the others. "In mutual predictability (MP) \citep{wen2025unsupervised}, we select the rollout with the highest probability when the model is conditioned on all other responses."
- Non-verifiable domains: Tasks where there is no deterministic checker or single ground truth. "In non-verifiable domains, where rule-based answer checking is infeasible, a few methods have established ways to score outputs against references."
- Perplexity: A measure of how well a probability model predicts a sequence; lower is better. "Unlike selection methods (best-of-, majority, perplexity, or judge scores),"
- PPO (Proximal Policy Optimization): A policy gradient algorithm using a clipped objective to stabilize updates. "GRPO \citep{shao2024deepseekmath} is a memory-efficient variant of PPO \citep{schulman2017proximal} that avoids a value network by using a group baseline."
- Programmatic checker: An automated mechanism for verifying correctness (e.g., exact match or executable tests). "or verifiable rewards from programmatic checkers \citep{lambert2024tulu, shao2024deepseekmath}."
- Programmatic equivalence: Automatic checking that two answers are equivalent by deterministic rules. "verifiable tasks use programmatic equivalence on final answers;"
- Programmatic verifier: A deterministic function that returns a binary correctness signal. "Let be a programmatic verifier (e.g., final-answer equivalence via a simple string match or programmatic execution)."
- Programmatic verification: Using formal or deterministic procedures to validate outputs. "CaT complements programmatic verification \citep{lambert2024tulu} by extending learning to non-verifiable domains where formal checkers are unavailable."
- Reference-free supervision: Training signals derived without relying on human-provided reference answers. "which converts the model's own exploration at inference-time into reference-free supervision"
- Rollout: A sampled response sequence generated by a policy for a given prompt. "the current policy produces a group of rollouts;"
- Rubric rewards: Rewards computed from satisfying binary, auditable criteria rather than holistic judgments. "Rubric rewards decompose holistic judgment into auditable checks, mitigating verbosity and form bias"
- Self-proposed rubrics: Rubrics generated by the model itself to define evaluable criteria. "non-verifiable tasks use self-proposed rubrics—binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied."
- Self-BoN: A baseline where the model selects its own best output among multiple samples. "Among alternatives, self-selected best-of- (Self-BoN), is a self-proposed baseline in which the model selects its own best response."
- Self-training: Learning from data or targets produced by the model itself. "Like self-training \citep{schmidhuber2003exploring, schmidhuber2013powerplay, silver2016mastering, silver2018general} and knowledge distillation \citep{hinton2015distilling}, it learns from model-generated supervision,"
- Synthesized reference: A constructed target answer that reconciles multiple rollouts into a single estimate. "produces a synthesized reference that reconciles omissions and contradictions across ."
- Test-Time RL (TTRL): Reinforcement learning applied at inference time, often using consistency signals. "\citet{zuo2025ttrl} proposed Test-Time RL (TTRL), which uses self-consistent majority consensus answers \citep{wang2023} as label estimates for RL fine-tuning in math."
- Trajectory perplexity: Perplexity computed over an entire generated sequence, used as a confidence proxy. "we select the response with the lowest trajectory perplexity under the model."
- Value network: A learned critic that estimates expected return; avoided in GRPO by using a group baseline. "that avoids a value network by using a group baseline."
- Verifiable domains: Tasks where outputs can be automatically checked for correctness. "Verifiable domains (e.g., math). We programmatically reward agreement of the response with the estimated reference, e.g., by checking whether answer strings match."
Collections
Sign up for free to add this paper to one or more collections.