- The paper presents ES-CoT, a method that terminates LLM reasoning early by detecting convergence in step answers to reduce computation costs.
- The framework leverages statistical run-jump tests to identify when answers stabilize, balancing computational efficiency with minimal performance loss.
- Empirical results on five reasoning tasks demonstrate an average token reduction of 41% while preserving accuracy close to full chain-of-thought outputs.
Early Stopping Chain-of-thoughts in LLMs
Introduction
The paper introduces a novel inference-time method called Early Stopping Chain-of-Thougt (ES-CoT) for optimizing the inference process in reasoning LLMs. These models excel in complex problem-solving by generating extensive chain-of-thoughts (CoT), yet this prolonged reasoning incurs substantial inference costs. The study formulates a mechanism to detect the convergence of answers during reasoning and capitalizes on this by halting the process early, thus reducing computational overhead while maintaining accuracy.
Framework and Algorithm
ES-CoT operates by observing the convergence behavior in step answers. At each step of the reasoning process, the LLM is prompted to output its current best guess of the final answer. The method involves identifying patterns in these step answers, specifically monitoring the repetition and detecting significant spikes in run lengths of identical consecutive answers.
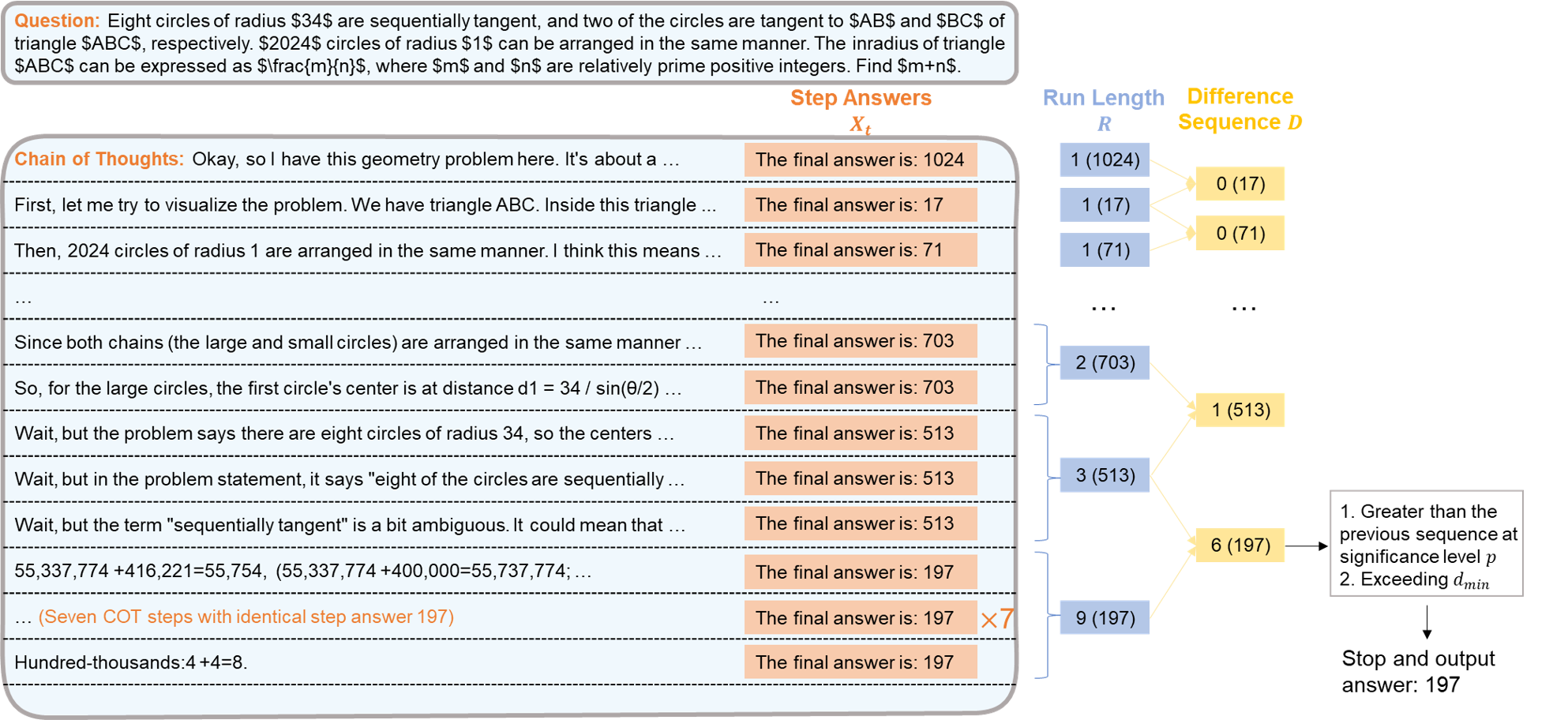
Figure 1: Framework of ES-CoT and the run-jump test.
The algorithm tracks these "runs" and computes the "run jumps"—a statistically significant increase in run length—indicative of answer stabilization. Once a sizeable, statistically significant jump is observed, inference terminates, and the current answer is concluded as the final output. This heuristic relies on the empirical observation that step answers gradually converge towards correctness as reasoning unfolds (Figure 2).
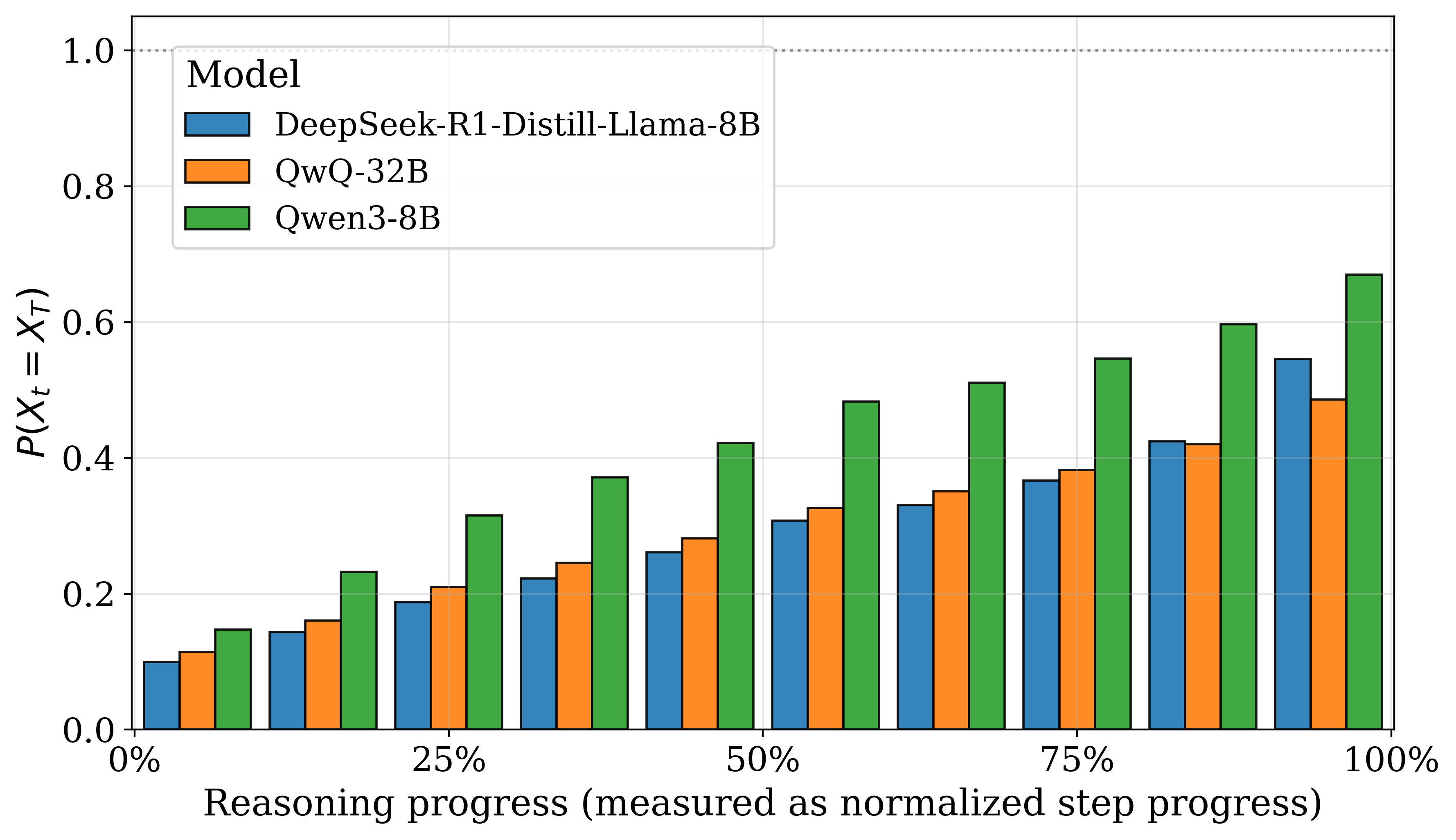
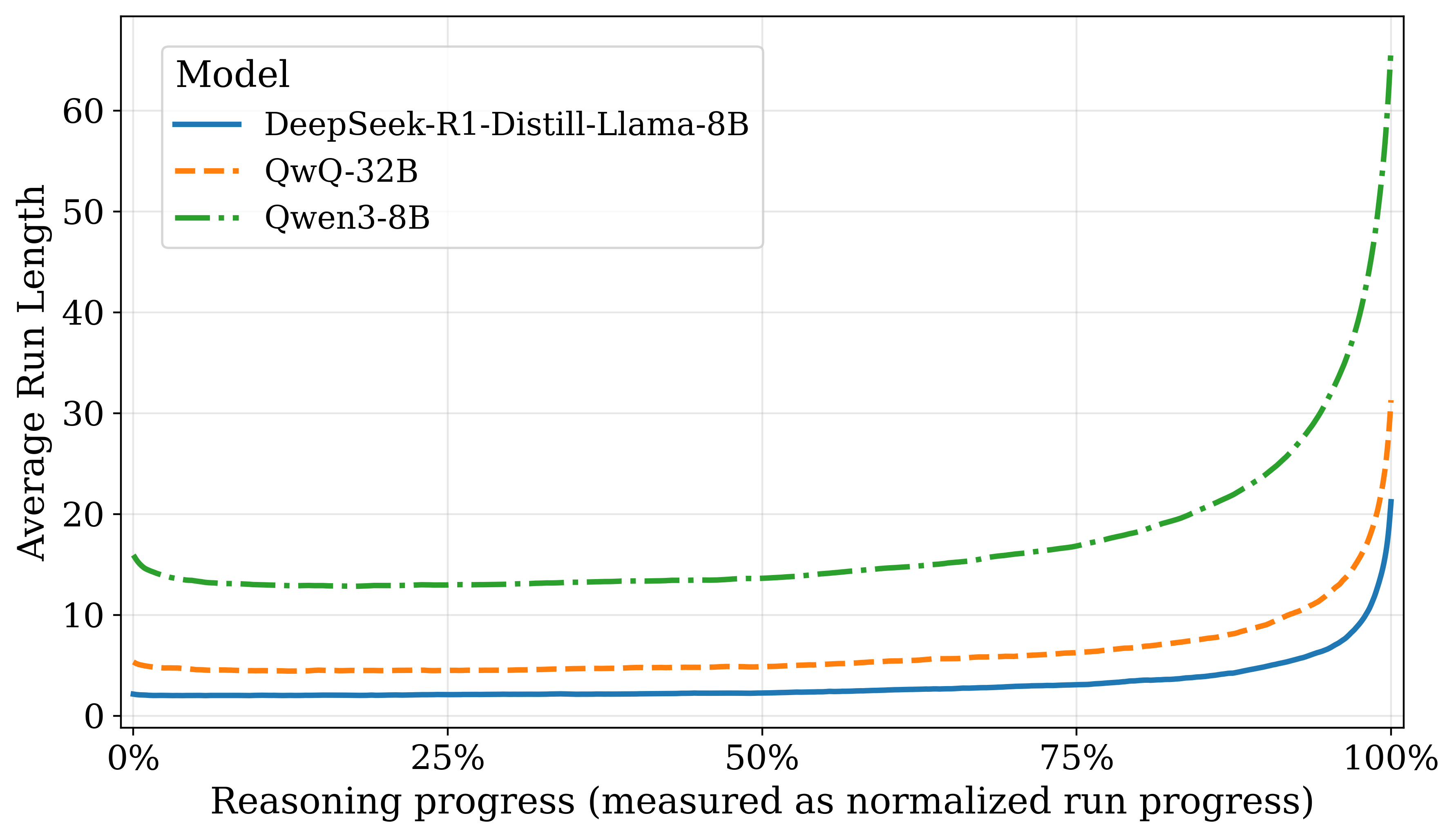
Figure 2: Probability that step answers match the final answer, P(Xt=XT), over reasoning progress (t/T). The last bar is an average over the final 10% of steps, so its value is less than one.
Theoretical Justification
The paper provides both empirical and theoretical validation for the ES-CoT approach. Step answers are shown to converge progressively towards the final answer with increasing reasoning progress. The probability that the step answer matches the final answer (P(Xt=XT)) grows, indicating an inherent tendency towards convergence in reasoning LLMs.
The ES-CoT hinges upon two core assumptions: the final step answer distribution is heavily concentrated and exhibits high fidelity, and step answer convergence is a monotonic process. The paper offers theoretical bounds on the probability of misalignment between early-stopped and fully-reasoned answers, thereby formalizing the conditions under which early termination is viable without significant accuracy loss.
Empirical Evaluation
The paper evaluates ES-CoT on five reasoning tasks across three models. Results demonstrate an average reduction in token usage of about 41% while maintaining accuracy levels close to full CoT outputs. The framework seamlessly integrates with self-consistency prompting methods, showing enhanced performance without additional resource burden.
A robust analysis on various hyperparameters of ES-CoT corroborates its resilience, demonstrating consistency across diverse model configurations and reasoning challenges. The empirical outcomes suggest that ES-CoT not only reduces inference cost but occasionally minimizes overthinking, thus enhancing answer quality.
Robustness and Sensitivity Analysis
The implementation of ES-CoT is sensitive to the hyperparameter dmin, which governs the minimum difference between consecutive run lengths for a jump to be considered significant. The study illustrates that as dmin increases, both accuracy and token usage rise, illustrating a trade-off between efficiency and performance. The run-jump criterion, enhanced through statistical significance tests, offers a scalable and adaptable method for managing reasoning depth and inference cost.
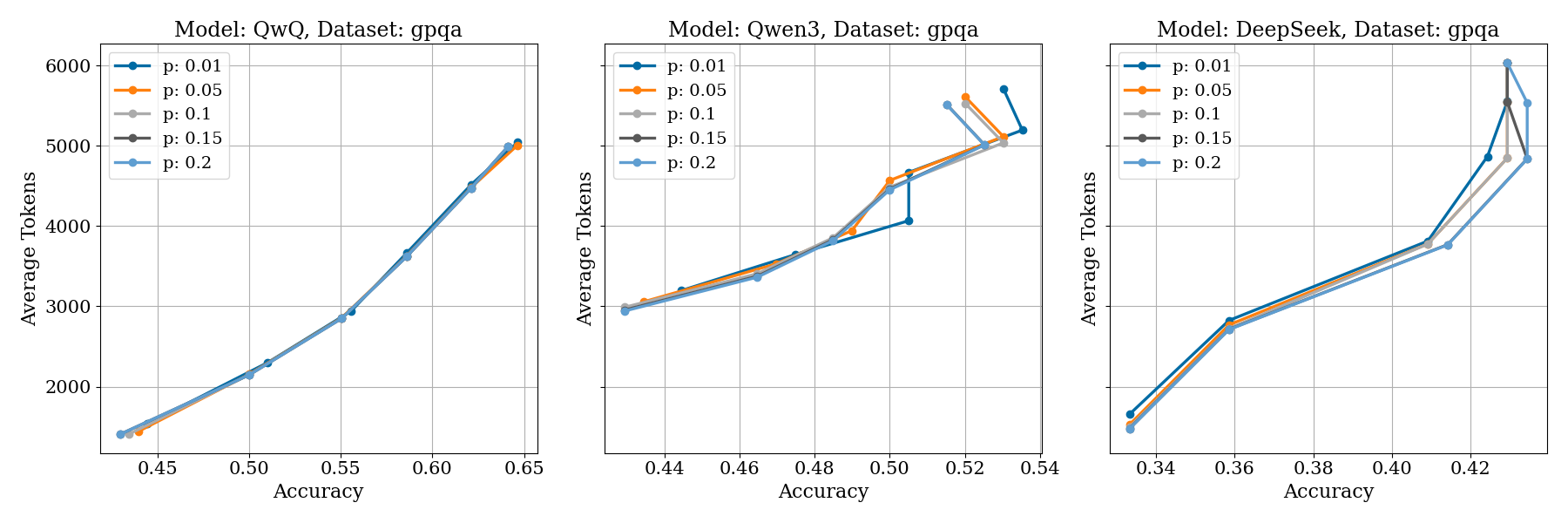
Figure 3: Robustness analysis of ES-CoT regarding the hyperparameters, including the minimum difference dmin.
Conclusion
In conclusion, the ES-CoT presents a robust solution for efficient reasoning in LLMs by utilising a principled method for early termination based on observable convergence in step answers. This approach provides a balance between computational efficiency and accuracy, making LLMs more feasible for real-world applications where resource economy is critical. Future work can explore adaptive parameter tuning and extend the method to non-deterministic reasoning scenarios.