- The paper introduces PromptSE, a framework that quantifies prompt stability in code LLMs by evaluating sensitivity to affect-based variations.
- It employs dual-pathway evaluation with probability-aware SoftExec and binary pass rates to produce AUC-E scores, revealing a decoupling between performance and stability.
- The study finds that model scale and architecture impact prompt stability non-monotonically, offering practical insights for robust model selection in software engineering.
Prompt Stability in Code LLMs: A Systematic Evaluation of Sensitivity to Emotion- and Personality-Driven Variations
Introduction
This paper addresses a critical but underexplored aspect of code generation with LLMs: the stability of model outputs under semantically equivalent prompt variations, particularly those reflecting different emotional states and personality traits. The authors introduce PromptSE, a principled framework for quantifying prompt sensitivity, and propose AUC-E, a standardized metric for cross-model stability comparison. The study evaluates 14 models across three major architecture families (Llama, Qwen, DeepSeek) using a large-scale, template-driven prompt variant dataset, revealing that performance and stability are largely decoupled and that model scale does not monotonically improve robustness.
Methodological Framework
The core methodological innovation is the PromptSE framework, which operationalizes prompt stability as a measurable property. The approach consists of three main components:
- Emotion- and Personality-Aware Prompt Variant Generation: The authors design a template system grounded in affective computing and personality psychology, generating prompt variants that systematically vary in emotional tone (e.g., focused, excited, frustrated) and personality profile (technical orientation, experience level, collaboration style). Perturbation strength is controlled via a distance parameter (d∈{0.1,0.2,0.3}), ensuring semantic and interface invariance.
- Dual-Pathway Sensitivity Evaluation:
- PromptSE (probability-aware): Utilizes SoftExec, a continuous correctness metric that weights outputs by model confidence, requiring access to output probabilities.
- PromptSELight (probability-free): Relies on binary pass rates, enabling evaluation of closed-source models or rapid screening.
- Elasticity and AUC-E Computation: Elasticity quantifies the stability of model outputs across prompt variants, and AUC-E aggregates elasticity across perturbation distances into a single, interpretable [0,1] stability score.
Experimental Design
The evaluation uses the HumanEval Python benchmark, augmented with 14,760 prompt variants generated via the template system. Each prompt variant is tested with 16 independent model outputs, and all models are evaluated under identical decoding policies and test suites. The model set spans a range of parameter scales and training paradigms, including instruction tuning and distillation.
Results
The analysis demonstrates that performance (Pass@1) and stability (AUC-E) are not significantly negatively correlated (Spearman ρ=−0.433, p=0.122). Models are distributed across all four quadrants of the performance-stability space, indicating that high performance does not guarantee robustness and vice versa.
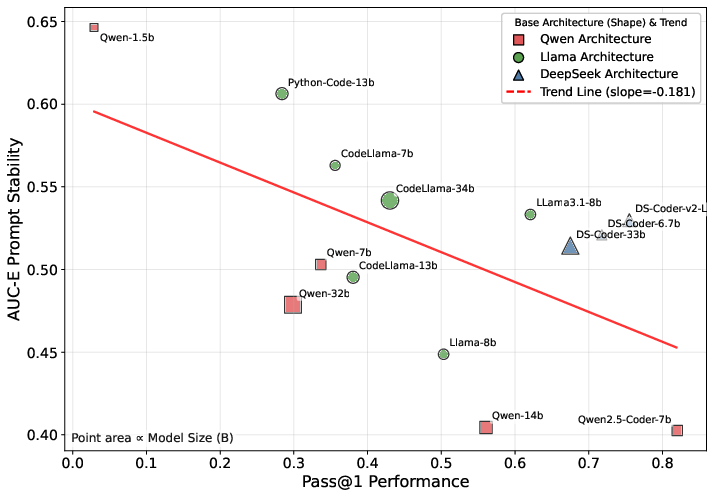
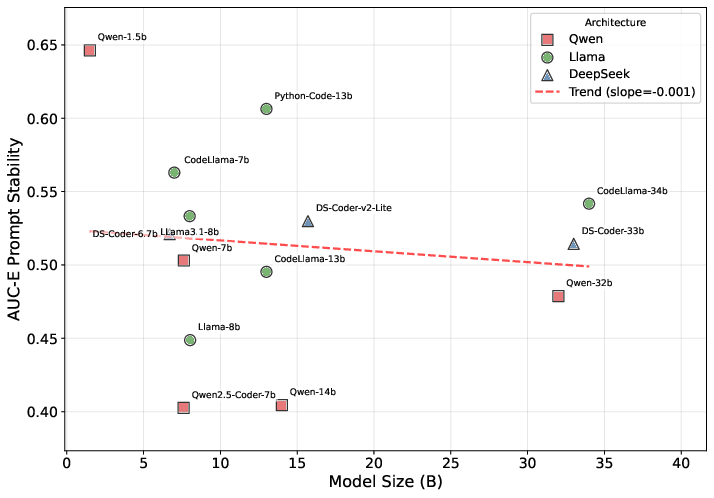
Figure 1: Relationship between performance and stability, showing the distribution of models across the performance-stability space.
Scale and Architecture Effects
Prompt stability does not monotonically improve with model scale. Notably, the Qwen-1.5B model (Tiny group) achieves the highest AUC-E ($0.646$), outperforming larger models in stability. Family-specific patterns are observed, with Llama models exhibiting a balance between performance and stability, while Qwen models tend toward higher performance but lower robustness.
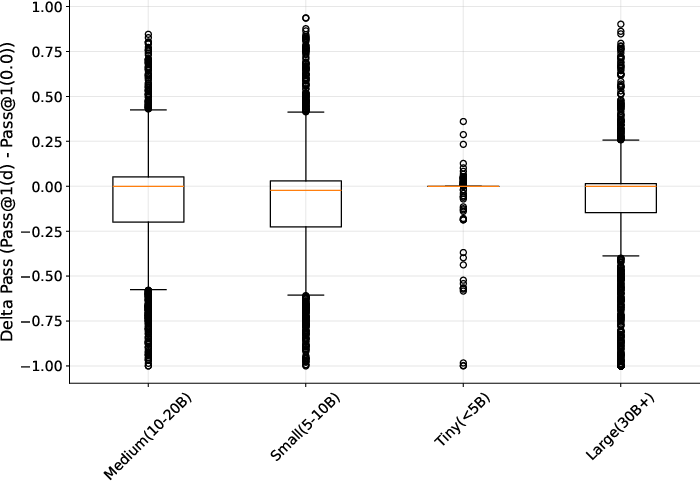
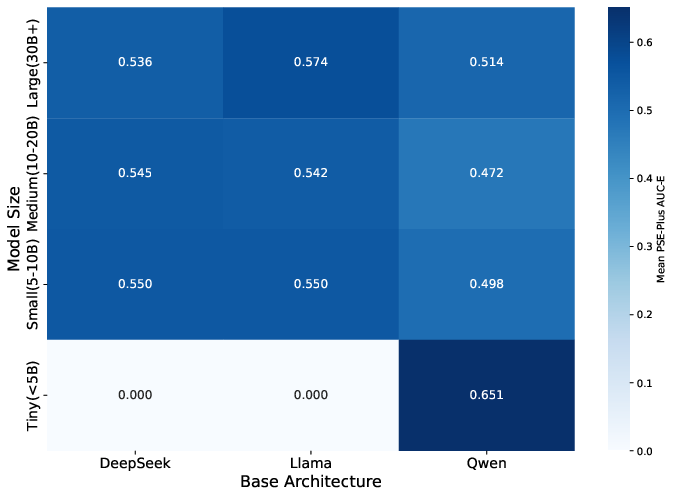
Figure 2: Overall sensitivity by size group (∣ΔPass∣), illustrating non-monotonic scale effects and family-specific stability patterns.
Sensitivity to Prompt Perturbation
Elasticity curves and SoftExec-based analyses reveal that most models maintain high stability under light to moderate prompt perturbations, but model-specific vulnerabilities emerge at higher perturbation distances. The average ∣ΔPass∣ remains within a narrow range ($0.078$–$0.082$) across distances, but significant main effects of scale and architecture are detected (Kruskal–Wallis H=49.663, p=0.000).
PromptSELight as a Practical Proxy
PromptSELight provides a strong approximation to PromptSE at the model level (Pearson r=0.717, Spearman ρ=0.723), enabling rapid, resource-efficient stability screening for closed-source models. However, some models exhibit rank drift due to differences in confidence calibration.
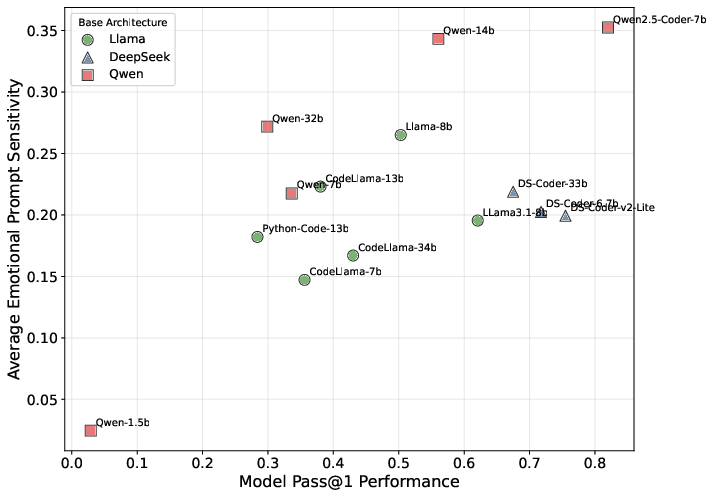
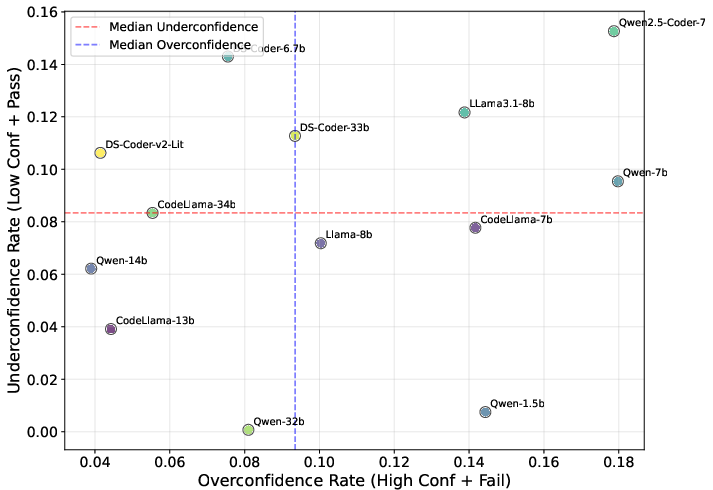
Figure 3: RQ3: Model-level AUC-E: PromptSELight vs PromptSE, demonstrating strong monotonic consistency between the two evaluation methods.
Emotional and Personality Effects
Analysis of valence and arousal dimensions shows that emotional coloring in prompts can induce confidence miscalibration and subtle correctness shifts, with effects varying by model family. High-arousal, negative-valence prompts are particularly diagnostic of model brittleness. Calibration metrics (ECE) and confidence bias analyses further differentiate models with similar correctness but divergent confidence behaviors.
Implications
Practical Deployment
The findings have direct implications for model selection and deployment in software engineering contexts. The decoupling of performance and stability enables practitioners to select models tailored to specific reliability requirements. The dual-pathway evaluation supports both detailed research analysis and rapid industrial screening.
Theoretical Insights
The non-monotonic relationship between scale and stability suggests that prompt robustness is not an emergent property of larger models and may require explicit optimization. The systematic impact of emotional and personality-driven prompt variations highlights the need for robustness evaluation beyond traditional functional correctness metrics.
Future Directions
Potential avenues for future research include:
- Investigating architectural and training factors that contribute to prompt stability.
- Extending the framework to other programming languages and task domains.
- Developing adaptive prompting strategies and robustness-aware training objectives.
Conclusion
This work establishes prompt stability as a distinct, quantifiable dimension for evaluating code LLMs, complementing traditional performance metrics. The PromptSE framework and AUC-E metric provide a unified methodology for cross-model comparison, revealing that performance and stability are decoupled and that smaller models can exhibit superior robustness. The dual-pathway evaluation enables both comprehensive research analysis and practical deployment screening. These insights position prompt stability alongside performance, fairness, and safety as a core consideration in the development and deployment of trustworthy AI-assisted software engineering tools.

