- The paper finds that innocuous prompt formatting choices can cause performance differences of up to 76 points in LLM evaluations.
- It introduces the FormatSpread algorithm that leverages multi-arm bandit methods to efficiently gauge formatting sensitivity.
- The study advocates for broader reporting standards in LLM benchmarking to account for prompt-induced performance spreads.
Abstract
This paper examines the sensitivity of LLMs to formatting choices in prompt design, which, despite preserving the meaning of the prompt, can significantly affect model performance. Findings reveal substantial performance differences, with accuracies varying by up to 76 points in LLaMA-2-13B due to formatting nuances. The authors propose that reporting a range of performance across plausible prompt formats could enhance methodological validity in evaluations. They introduce an algorithm, FormatSpread, to systematically gauge the effect of formatting variations without accessing model weights.
Introduction
The use of LLMs has become integral to language technology deployments, necessitating robust characterization of their behavior across different contexts. One commonly underestimated factor is the influence of prompt formatting—stylistic choices that should not alter a prompt's semantic interpretation yet may drastically impact model output. This research exposes the fragility of model performance to several formatting permutations and challenges the standard practice of benchmarking LLMs with a fixed prompt format. It argues for the inclusion of a performance spread, obtained by evaluating diverse formats, in research reporting.
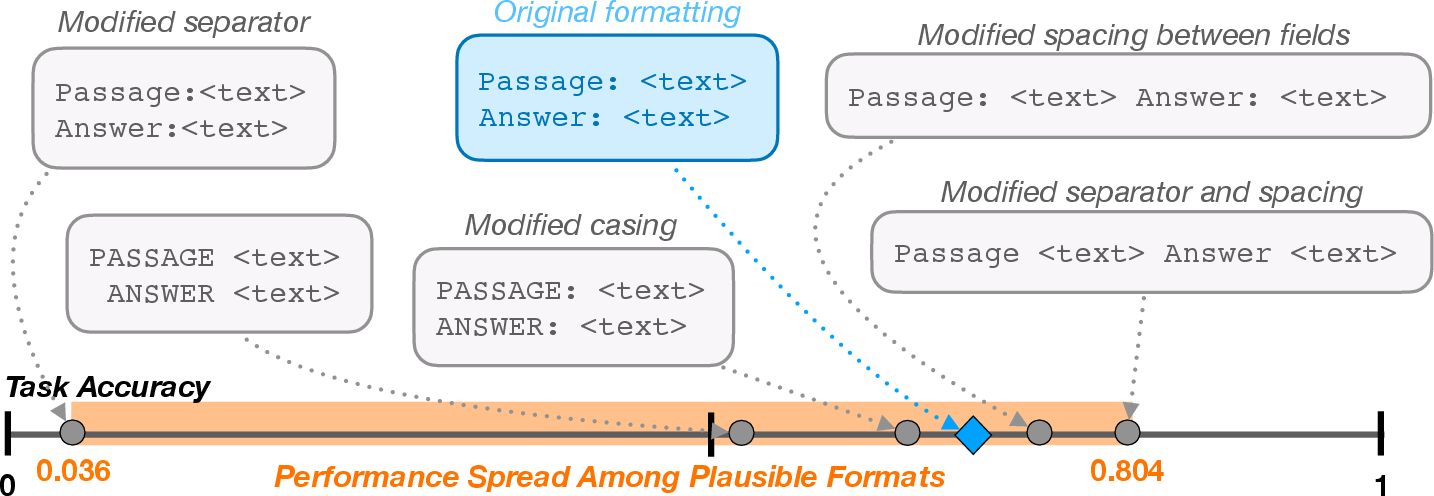
Figure 1: Slight modifications in prompt format templating may lead to significantly different model performance for a given task. Example corresponds to 1-shot LLaMA-2-7B performances for task280 from SuperNaturalInstructions.
Methodology
The authors define a comprehensive grammar to characterize the spectrum of semantically equivalent prompt formats. This grammar establishes equivalence based on meaning-preserving transformations encompassing descriptor casing and separators. Equivalent formats share identical meanings, ensuring valid comparisons over varied formats without introducing confounding semantic elements.
Measuring Sensitivity
The paper details an algorithm, FormatSpread, using multi-arm bandit frameworks like Thompson Sampling and Upper Confidence Bound to explore the prompt formatting space efficiently. This approach models the variant performances of prompt formats over tasks as hidden values, optimizing the evaluation budget to derive accurate performance intervals.
Experimental Results
Despite model size increases, few-shot example counts, and instruction tuning efforts, the sensitivity of models like LLaMA-2 and Falcon to formatting choices remains consistent. For example, even a small set of formats showcases an accuracy spread of 7.5 points on median across numerous tasks.
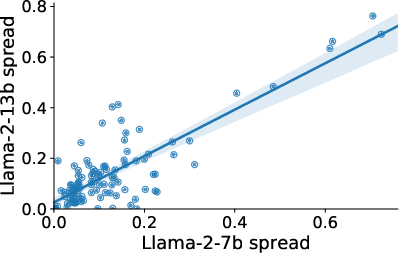
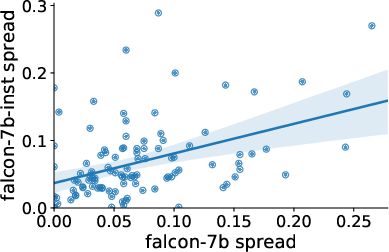
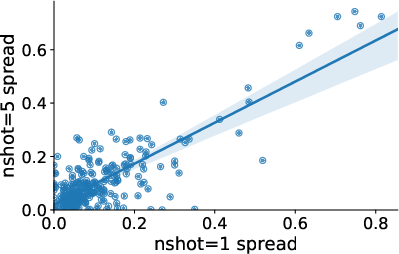
Figure 2: Llama-2-7B vs. 13B
Individual Feature Influence
Analyzing the individual impact of prompt constants reveals moderate dissimilarity in performance across configurations such as separators and item formats. However, no single constant consistently predicts accuracy changes on its own. Instead, overall prompt structure exerts a stronger influence on the final task performance.
Discussion
The inherent sensitivity of LLMs to superficially innocuous prompt format choices challenges current benchmarking paradigms. By demonstrating variability not mitigated by increasing model complexity or context, this work argues for a broader evaluation framework that takes performance span into account. These insights call for caution in making assertions about model improvements solely based on training data or model architecture changes.
Conclusion
This paper advocates for nuanced reporting of LLM performance to account for prompt formatting variability, thus preventing the undue attribution of results to factors other than prompt structure. FormatSpread offers researchers a tool to explore prompt sensitivity comprehensively without invasive access to model parameters, an asset for both open-source and API-locked LLMs. Future directions may include regularization methods to enhance model robustness against formatting variations, reinforcing their practicality in multifaceted language technology applications.
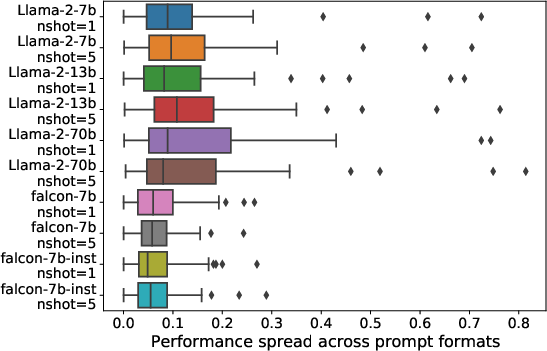
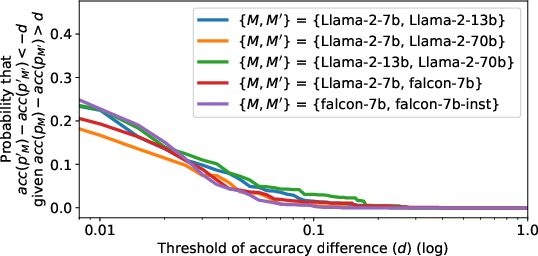
Figure 3: Spread across models and n-shots.