- The paper introduces a novel continual pre-training approach using Hephaestus-Forge to significantly improve API calling, reasoning, and planning capabilities in LLM agents.
- It employs a three-stage methodology, integrating large-scale agent-specific data with targeted instruction fine-tuning to enhance performance benchmarks.
- Empirical results show superior generalization and robustness by optimizing the balance between agent, text, and code data, paving the way for more versatile AI systems.
Overview of Hephaestus: Improving Fundamental Agent Capabilities of LLMs through Continual Pre-Training
The paper "Hephaestus: Improving Fundamental Agent Capabilities of LLMs through Continual Pre-Training" introduces Hephaestus, a novel approach that aims to significantly enhance the autonomous capabilities of LLMs. The core innovation lies in the use of a large-scale pre-training corpus, Hephaestus-Forge, tailored specifically to improve skills such as API function calling, intrinsic reasoning, planning, and adaptability to feedback. This methodology leverages continual pre-training on a diverse corpus followed by instruction fine-tuning.
Problem Statement and Motivation
LLM-based autonomous agents often underperform due to their reliance on either complex prompting or instruction fine-tuning, which may introduce new capabilities but often compromises the generalization. This occurs because existing systems overemphasize the instruction fine-tuning stage and ignore the significant role of the pre-training stage, leading to limited generalization across diverse tasks (Figure 1).
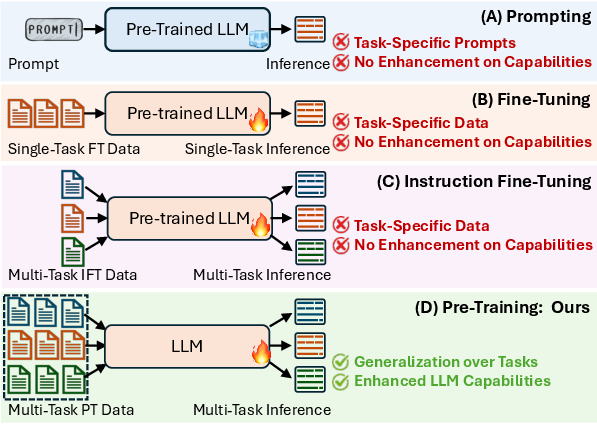
Figure 1: Training paradigms of LLM agents. Prompting alone fails to introduce new knowledge and capabilities, while heavy fine-tuning can hinder generalization and degrade performance in non-agent use cases, potentially suppressing the original base model capabilities.
Corpus and Methodology: Hephaestus-Forge
Data Collection and Composition
Hephaestus-Forge is a comprehensive corpus consisting of 103 billion agent-specific data tokens and 76,537 APIs, carefully curated to enhance foundational agent capabilities:
- Public APIs and Repositories: Extensive API documentations are sourced from over 1,400 public APIs, integrated with action trajectories from over 60 public repositories.
- Code-to-Text Synthesis: Employing state-of-the-art LLMs to generate additional synthetic APIs from code to bridge data gaps.
- Simulated Agent Data: Action sequences are collected using official code from agent frameworks, aimed at improving adaptability to feedback.
Figures within the paper demonstrate the intricate mix of seed and retrieved data in Hephaestus-Forge, showcasing their semantic alignment and diversity (Figure 2).
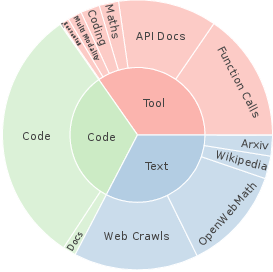
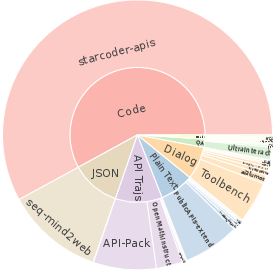
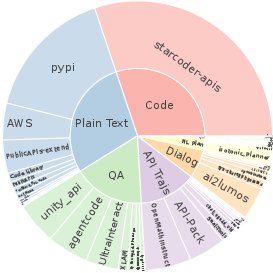

Figure 2: Data composition of (a) the entire Hephaestus-Forge, (b) seed data collection.
Continual Pre-Training and Instruction Fine-Tuning
Hephaestus employs a structured pre-training strategy:
- Stage I: General pre-training on the entire Hephaestus-Forge corpus to infuse general agent knowledge.
- Stage II: Targeted pre-training using high-quality corpus to enhance specific agent capabilities.
- Stage III: Instruction fine-tuning to align with specific task instructions and needs, improving the instruction-following proficiency (Figure 3).
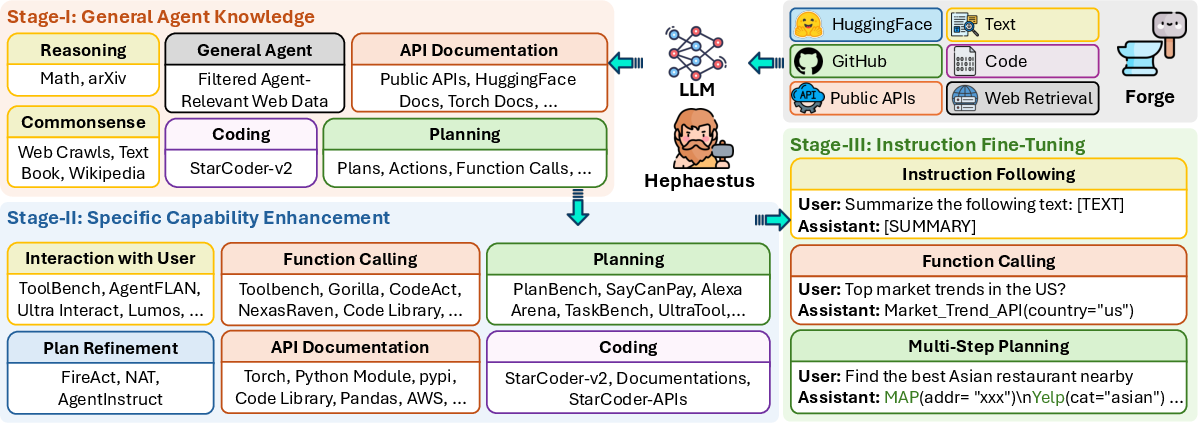
Figure 3: Overview of the pre-training (Stages I as II) and instruction fine-tuning (III) framework in Hephaestus.
Experiments and Results
Significant empirical improvements are observed with Hephaestus, where benchmarks demonstrate enhanced performance over small to medium-scale open-source LLMs:
- Agent Benchmark Results: Hephaestus shows superior performance across three agent-specific benchmarks, achieving better generalization without sacrificing general capabilities (Figure 4).

Figure 4: Training and benchmark loss. (a) Training loss of Hephaestus during continual pre-training and instruction fine-tuning. (b) Benchmark loss at periodic training checkpoints and (c) a comparison across base models.
- Data Scaling Relations: Through extensive experiments, a balanced ratio of agent, text, and code data is determined to be optimal, ensuring versatile and robust LLM capabilities (Figure 5).

Figure 5: Scaling law of the relationship between agent data mixing ratio (%) and benchmark loss.
Conclusion
The research introduces an innovative approach to harness the power of pre-training in enhancing LLM agent capabilities. By curating a diverse and specialized dataset and employing strategic continual pre-training, Hephaestus effectively bridges the gap between LLM capabilities and real-world application demands. Future work could involve scaling these models to more extensive datasets and testing across broader LLM architectures, potentially paving the way for more robust, generalizable AI systems.