Efficient Item ID Generation for Large-Scale LLM-based Recommendation
Published 3 Sep 2025 in cs.IR | (2509.03746v1)
Abstract: Integrating product catalogs and user behavior into LLMs can enhance recommendations with broad world knowledge, but the scale of real-world item catalogs, often containing millions of discrete item identifiers (Item IDs), poses a significant challenge. This contrasts with the smaller, tokenized text vocabularies typically used in LLMs. The predominant view within the LLM-based recommendation literature is that it is infeasible to treat item ids as a first class citizen in the LLM and instead some sort of tokenization of an item into multiple tokens is required. However, this creates a key practical bottleneck in serving these models for real-time low-latency applications. Our paper challenges this predominant practice and integrates item ids as first class citizens into the LLM. We provide simple, yet highly effective, novel training and inference modifications that enable single-token representations of items and single-step decoding. Our method shows improvements in recommendation quality (Recall and NDCG) over existing techniques on the Amazon shopping datasets while significantly improving inference efficiency by 5x-14x. Our work offers an efficiency perspective distinct from that of other popular approaches within LLM-based recommendation, potentially inspiring further research and opening up a new direction for integrating IDs into LLMs. Our code is available here https://drive.google.com/file/d/1cUMj37rV0Z1bCWMdhQ6i4q4eTRQLURtC
The paper introduces a single-token item ID representation that enables single-step decoding and achieves a 5x–14x latency reduction.
It employs a dedicated item embedding table and a Two-Level softmax approach with ANN to efficiently handle large item catalogs.
Experimental results demonstrate superior recommendation metrics over multi-token baselines while simplifying the training pipeline.
Efficient Item ID Generation for Large-Scale LLM-based Recommendation
Introduction and Motivation
The paper "Efficient Item ID Generation for Large-Scale LLM-based Recommendation" (2509.03746) addresses a fundamental bottleneck in deploying LLM-based recommender systems at scale: the inference latency incurred by multi-token item representations. Existing approaches typically tokenize item IDs into multiple text tokens, resulting in longer input sequences and multi-step decoding, which severely limits real-time applicability in domains with large catalogs and latency-sensitive requirements. The authors challenge the prevailing assumption that items must be mapped into the text token space and propose a method that treats item IDs as first-class citizens in the LLM, enabling single-token representations and single-step decoding.
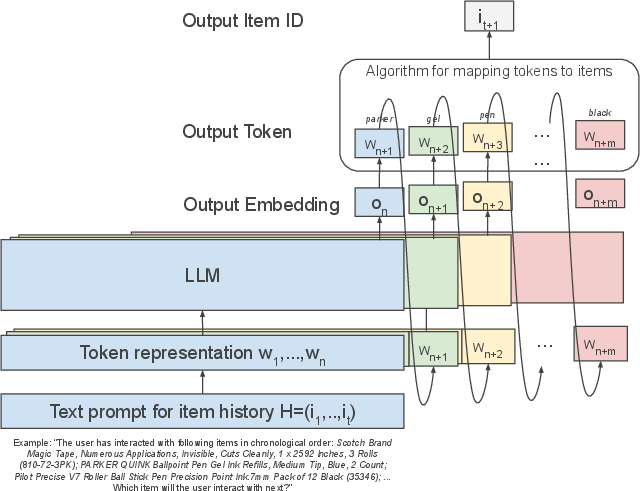
Figure 1: Multi-token (baseline) vs. single-token (proposed) item representation, highlighting the reduction in prefill and decode latency with the single-token approach.
Model Architecture and Training Paradigm
The proposed method introduces a dedicated item embedding table, separate from the LLM's text token embeddings. Each item ID is mapped to a single embedding vector, projected into the LLM's embedding space via a small feedforward network. During training, the model leverages rich item metadata (title, brand, category, price) but deliberately includes a fraction of examples with only item IDs to ensure robust ID-only inference. This paradigm eliminates the need for multi-stage pretraining or external item embedding alignment, simplifying the training pipeline.
The input prompt interleaves text and item tokens, and the output is trained to directly predict the next item ID in the sequence. The model's output layer is modified to bypass the standard softmax over the text vocabulary, instead using an efficient softmax over the combined space of text tokens and item IDs.
Figure 2: Training and inference flow for the Two-Level softmax, showing cluster-based partitioning and efficient retrieval via ANN or hierarchical structure.
Two-Level Softmax for Scalable Inference
For large item catalogs, the computational cost of a full softmax over millions of items is prohibitive. The authors introduce a Two-Level softmax mechanism:
First Level: The model predicts a probability distribution over clusters (using k-means, frequency, or random clustering).
Second Level: Within the selected cluster, the model predicts the probability of individual items or text tokens.
This hierarchical structure reduces training complexity from O((∣V∣+∣I∣)⋅d) to O((∣V∣+∣I∣)⋅d), where ∣V∣ is the text vocabulary size, ∣I∣ is the item catalog size, and d is the embedding dimension. For inference, the authors propose two strategies: Approximate Nearest Neighbor (ANN) search and hierarchical pruning, both leveraging the cluster structure for sublinear retrieval.
Latency and Efficiency Analysis
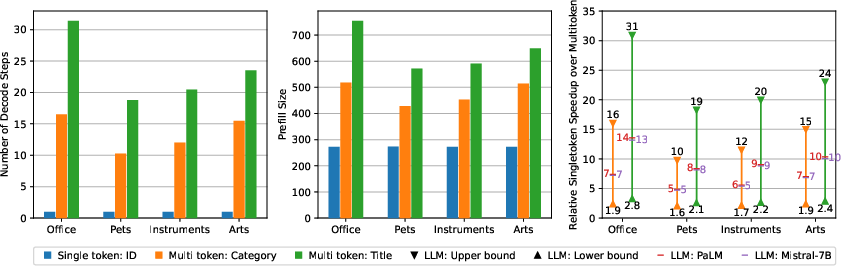
The single-token approach dramatically reduces both prefill and decode latency. Prefill latency scales with the number of input tokens, and decode latency is proportional to the number of output tokens. By representing each item as a single token, the method achieves a 5x–14x speedup over multi-token baselines across various LLM deployments (PaLM, Mistral-7B), as shown in the latency benchmarks.
Figure 3: Latency comparison and speedup of single-token (proposed) over multi-token (baseline) approaches across different LLM deployments.
Experimental Results
Experiments on Amazon Review datasets (Office, Pets, Instruments, Arts) demonstrate that the proposed single-step decoding methods (Full Softmax, Two-Level Softmax with ANN or Structure inference) consistently outperform traditional non-LLM recommenders (SASRec, BERT4Rec, FDSA, S3-Rec, UniSRec) and multi-token LLM-based baselines (CALRec, Recformer) in Recall@1, Recall@10, NDCG@10, and MRR. Ablations show that:
Full Softmax yields the highest quality when computationally feasible.
Two-Level Softmax with ANN or Structure inference maintains competitive quality with significant efficiency gains.
Clustering method (Kmeans, Frequency, Random) has limited impact on ANN inference quality, with random clustering performing surprisingly well.
Increasing LLM size (from PaLM 2 XXS to XS) further improves recommendation quality.
The simplified training paradigm obviates the need for multi-stage pretraining.
Model Properties and Practical Considerations
The method introduces moderate storage overhead due to the item embedding table (e.g., 0.5B parameters for 1M items with 500-dim embeddings), but this is comparable to traditional recommender architectures. The approach is flexible in embedding dimension and can be adapted to other recommendation tasks, including multi-modal outputs.
The inference pipeline is compatible with production-scale ANN libraries (ScaNN, FAISS), enabling real-time retrieval over millions of items. The hierarchical structure allows for efficient pruning and dynamic decoding, supporting both text and item generation in a unified framework.
Theoretical and Practical Implications
The paper provides strong empirical evidence that direct item ID integration into LLMs is both feasible and advantageous, contradicting the dominant multi-token paradigm. The efficiency gains open the door to deploying LLM-based recommenders in latency-critical environments (e-commerce, ads, slate generation) without sacrificing recommendation quality. The approach also simplifies the training pipeline, reducing engineering complexity and resource requirements.
Theoretically, the work highlights the importance of output space design in LLM-based systems, especially when the output vocabulary is orders of magnitude larger than the text vocabulary. The Two-Level softmax and cluster-based retrieval strategies may be applicable to other domains with large discrete output spaces.
Future Directions
Potential avenues for future research include:
Integrating external semantic or collaborative embeddings for improved clustering.
Extending the framework to multi-modal item representations (images, attributes).
Exploring dynamic clustering and adaptive softmax mechanisms.
Investigating the impact of catalog churn and cold-start items on embedding stability.
Applying the single-token paradigm to other large-vocabulary generative tasks (e.g., entity linking, knowledge graph completion).
Conclusion
The paper presents a principled and practical solution to the inference latency bottleneck in LLM-based recommendation, demonstrating that single-token item representations and efficient output layer design yield superior quality and scalability. The findings challenge established practices and provide a foundation for future research in efficient LLM integration for large-scale, real-time recommendation systems.